Download as PDF, PPTX





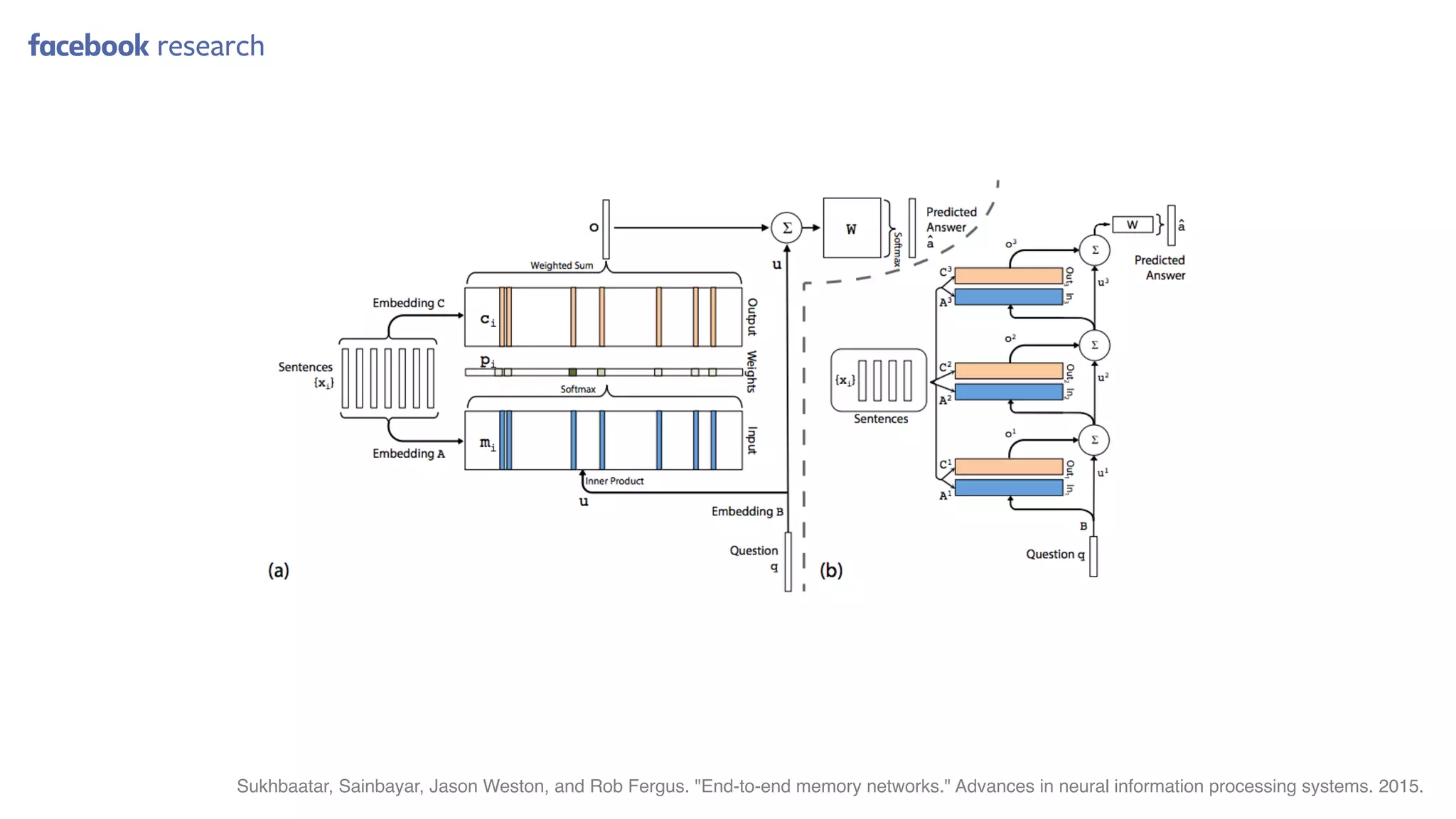



















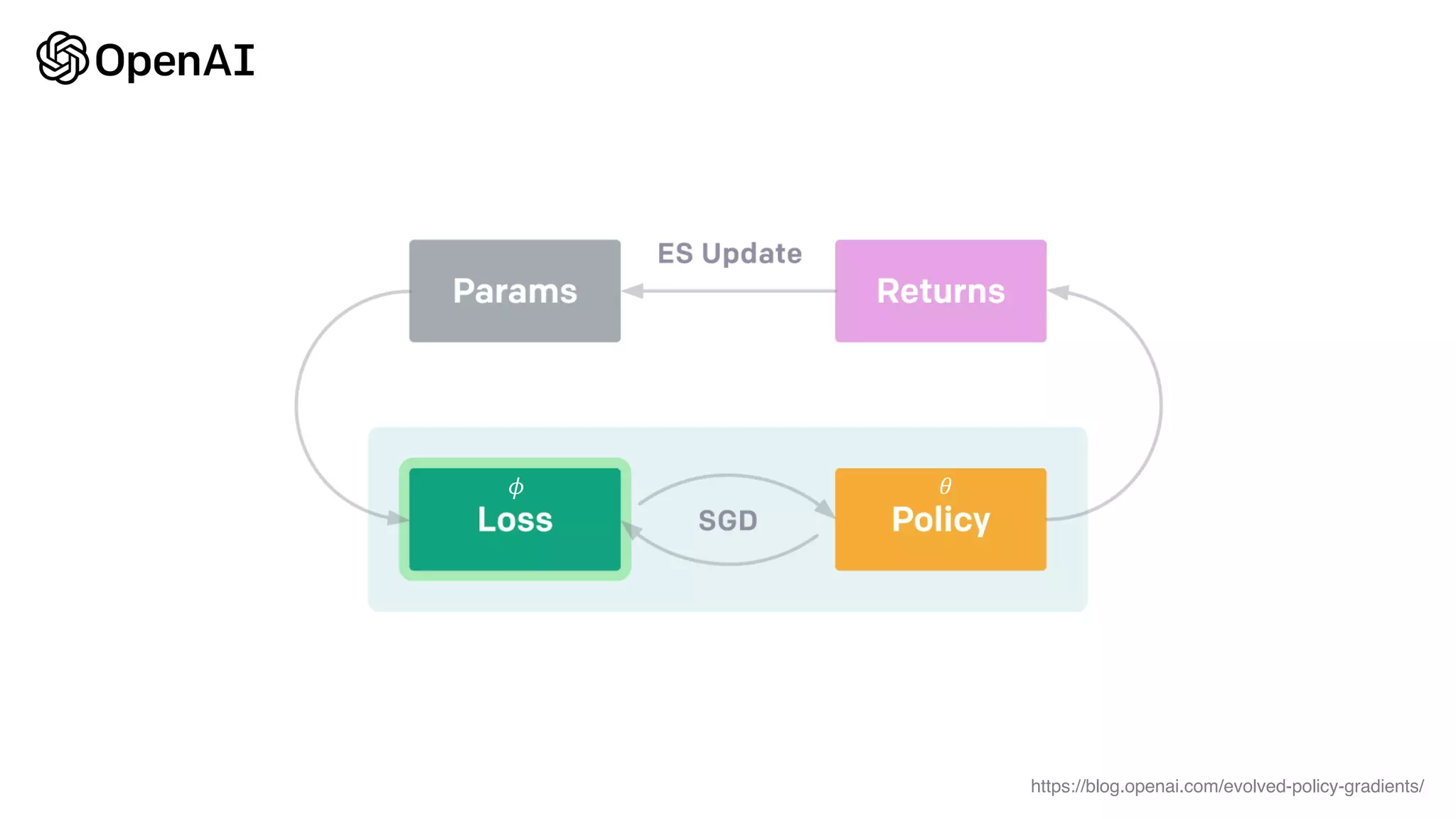



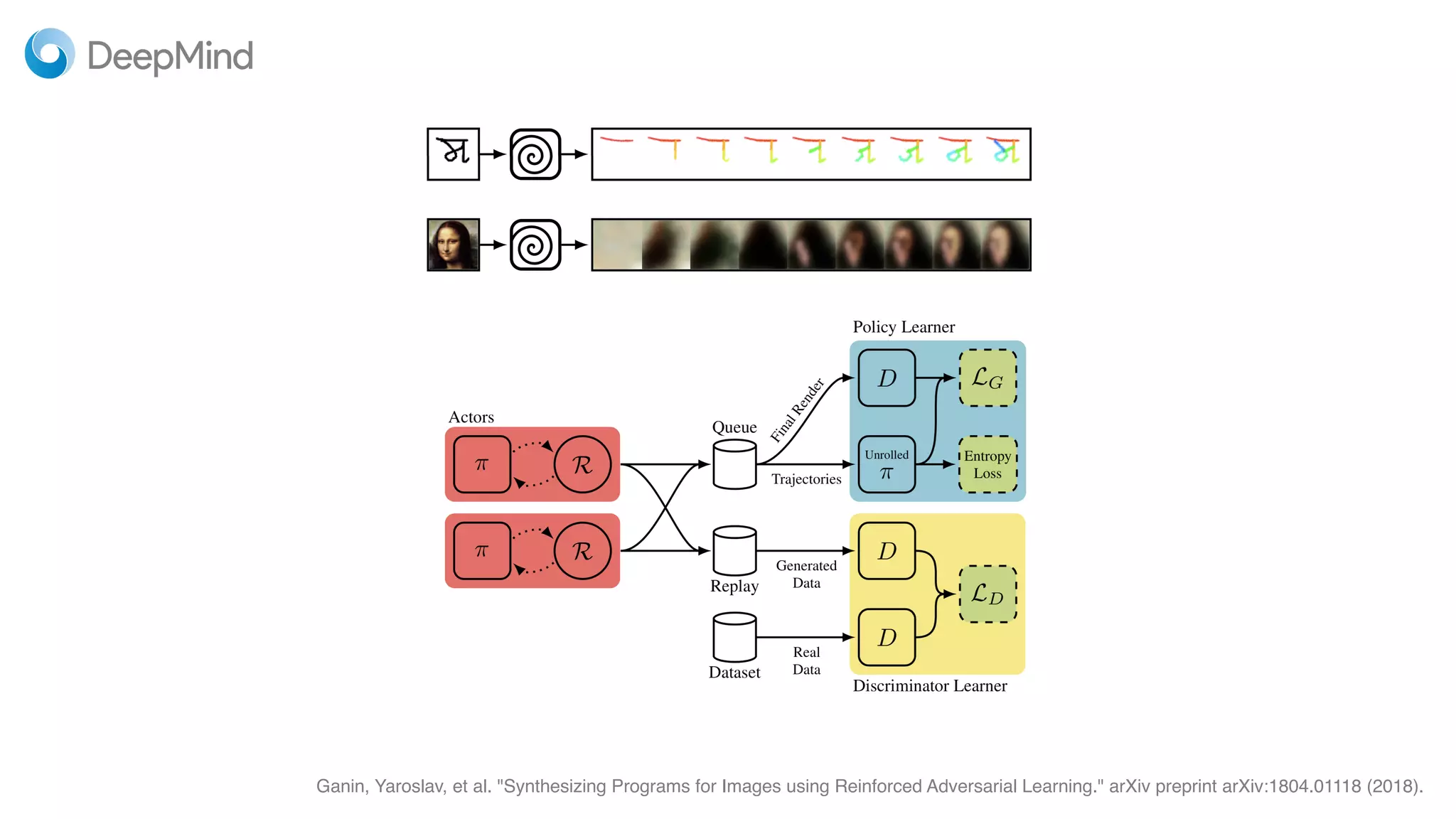
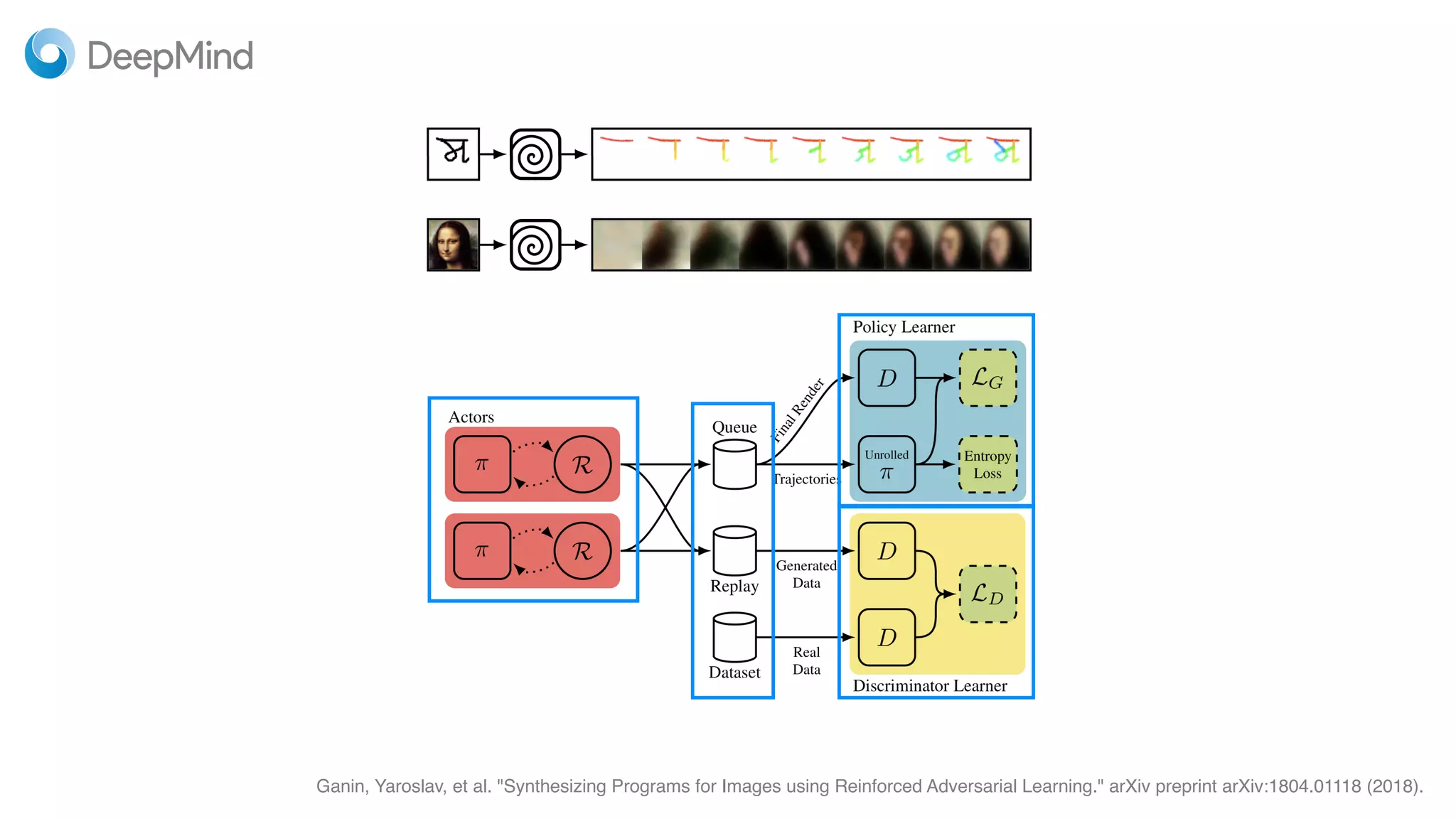





















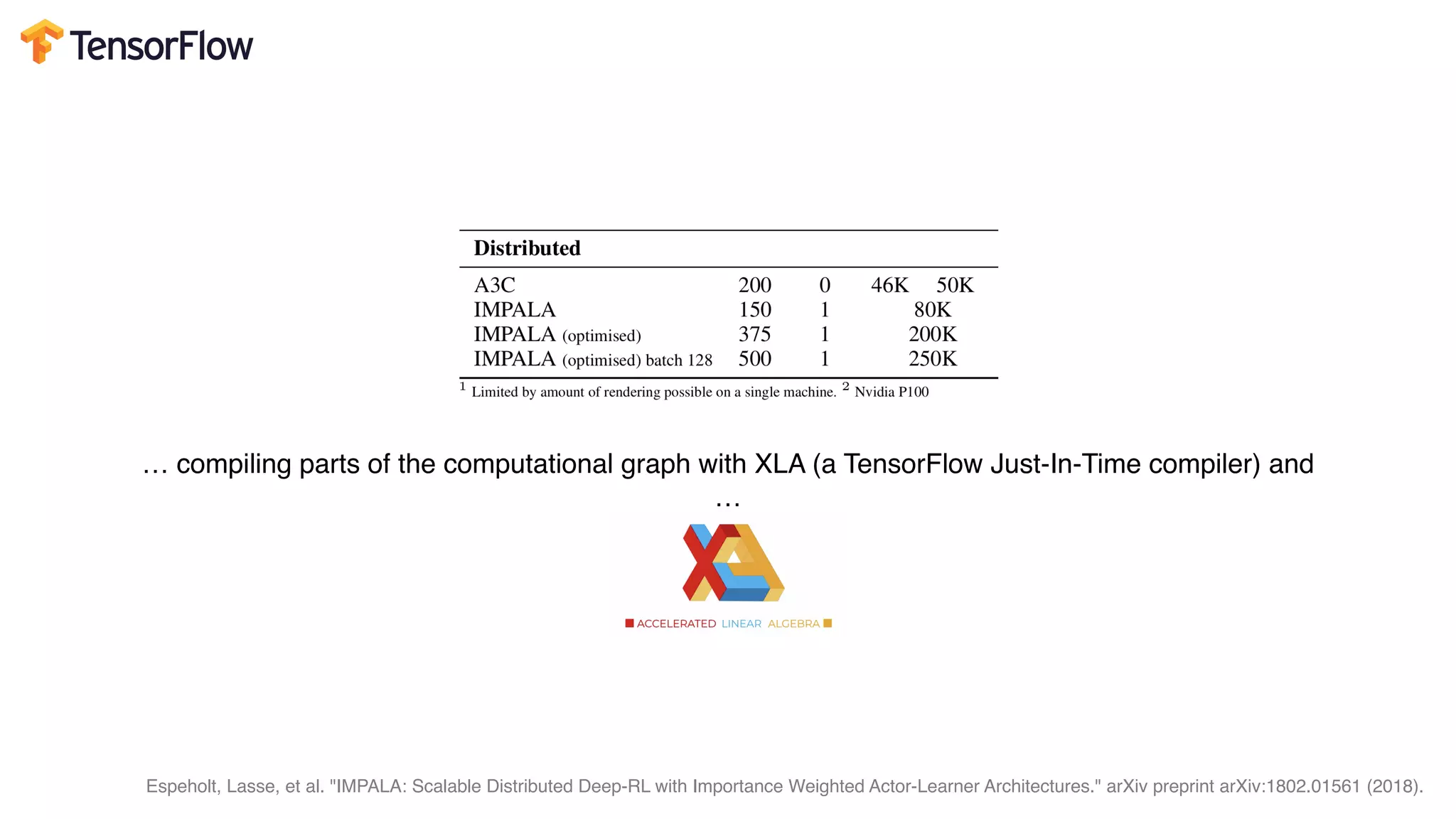

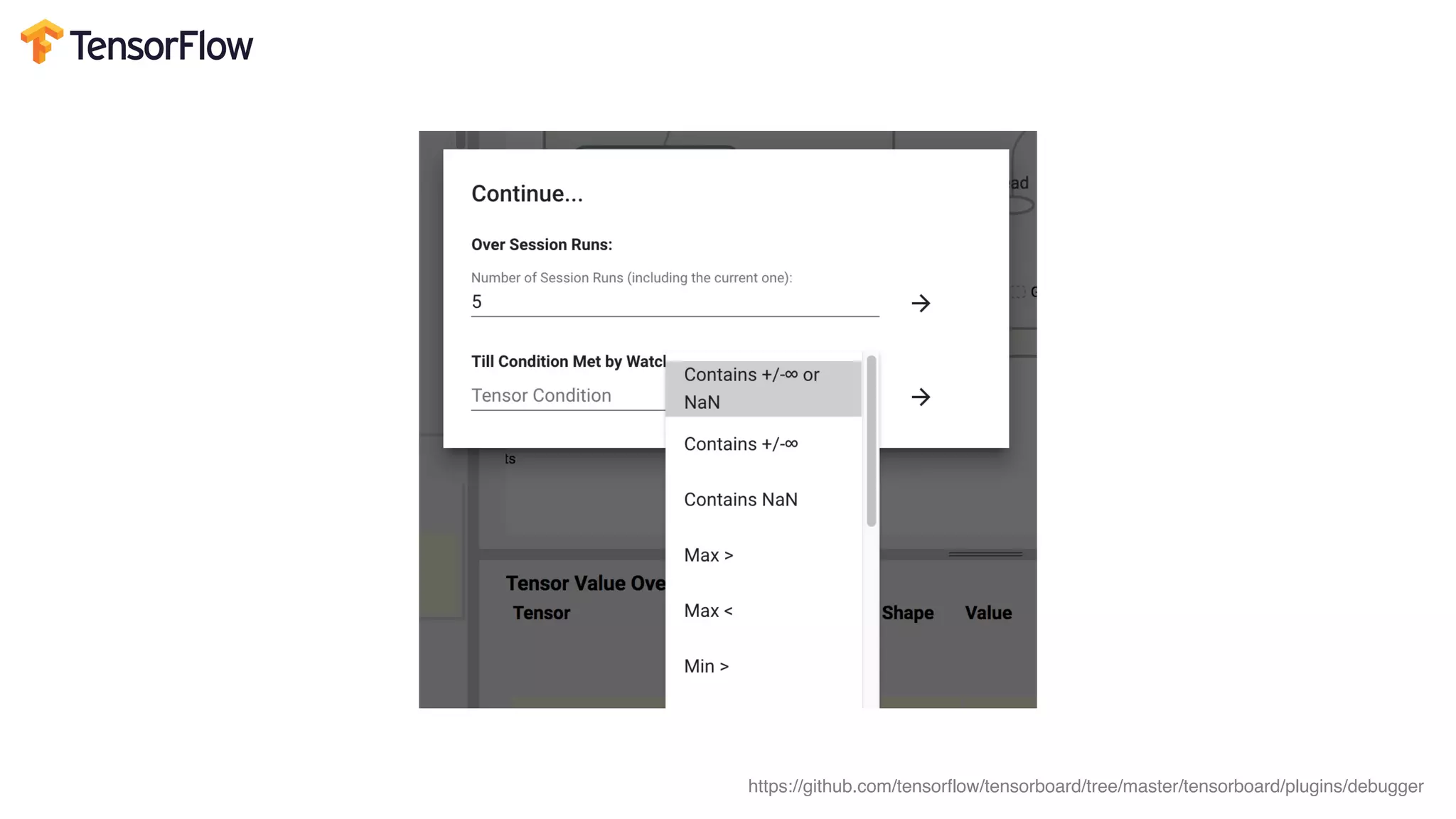









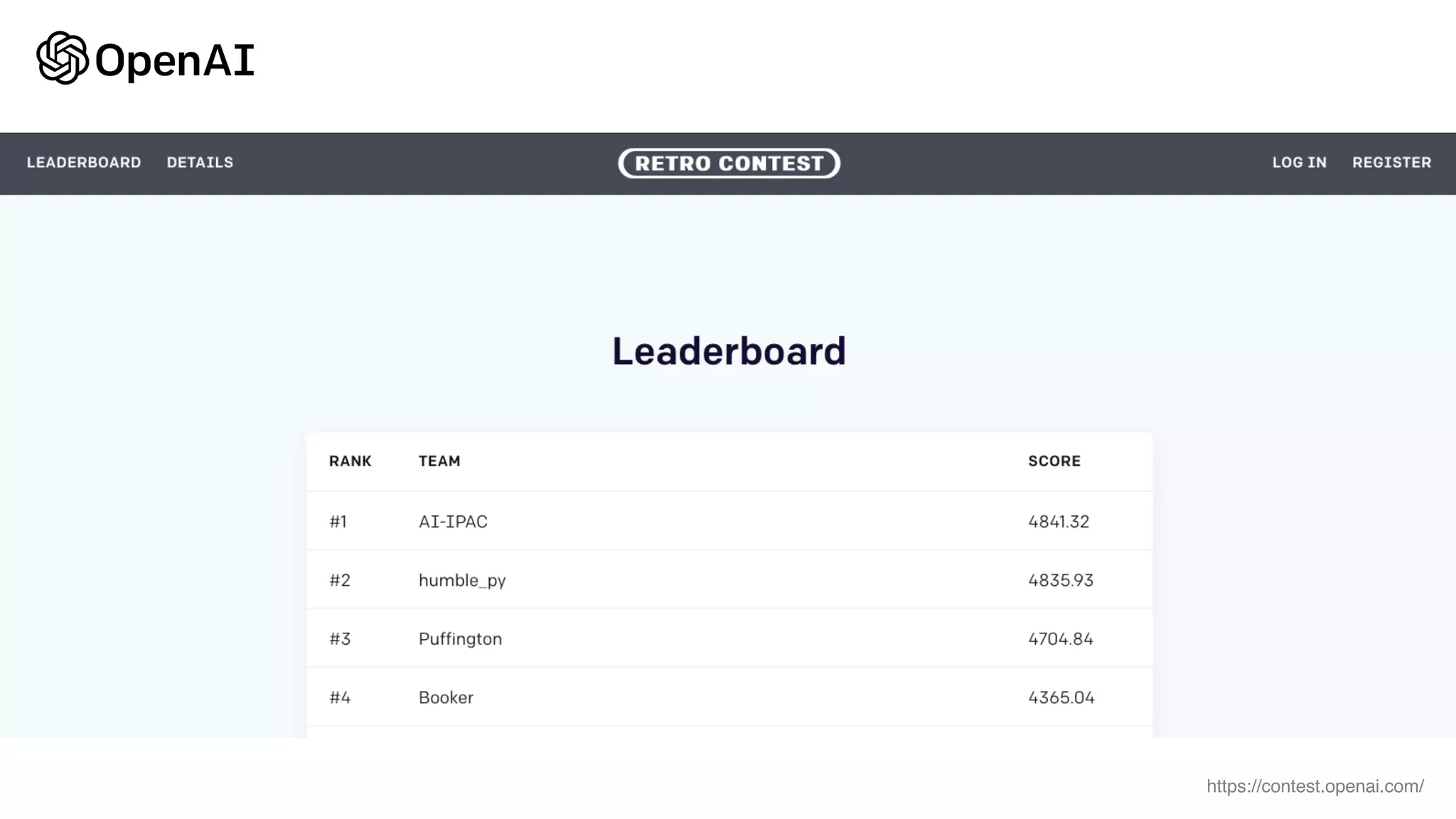
























This document provides random thoughts on implementing machine learning papers. It discusses what types of papers to implement, including computer vision, NLP, reinforcement learning and more. It recommends specific papers and code repositories. It also discusses whether to use TensorFlow or PyTorch and mentions grants and competitions for implementing papers.


![Deep learning for fun and profit [pyconde 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningforfunandprofitpyconde2018-181029150851-thumbnail.jpg?width=640&height=640&fit=bounds)














































































