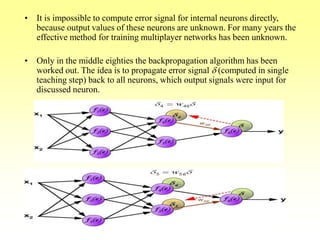
The document provides an overview of backpropagation, a common algorithm used to train multi-layer neural networks. It discusses:
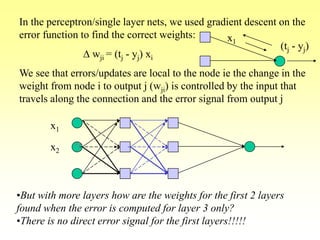
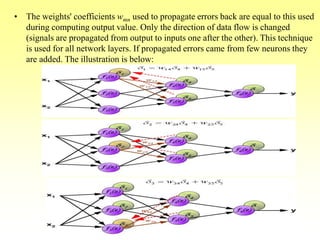
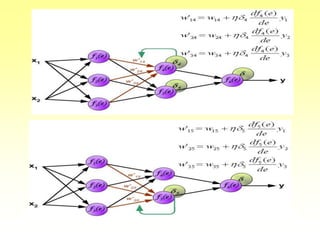
- How backpropagation works by calculating error terms for output nodes and propagating these errors back through the network to adjust weights.
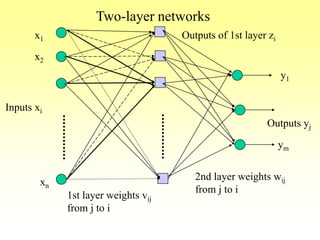
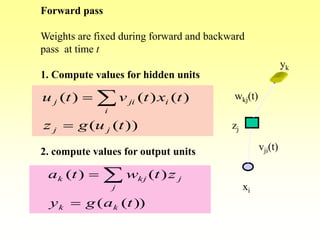
- The stages of feedforward activation and backpropagation of errors to update weights.
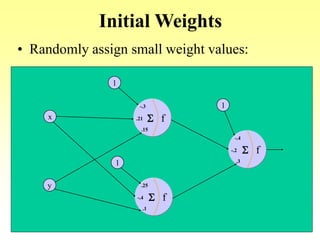
- Options like initial random weights, number of training cycles and hidden nodes.
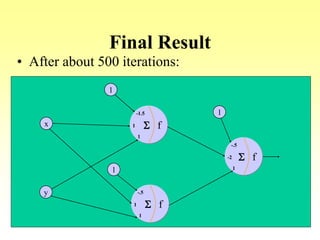
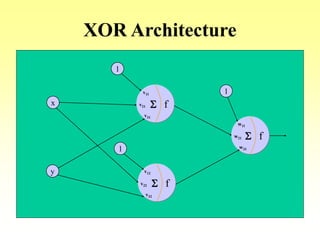
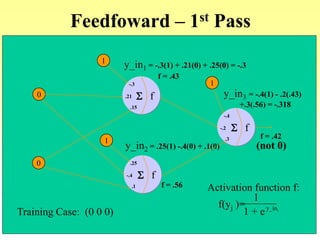
- An example of using backpropagation to train a network to learn the XOR function over multiple training passes of forward passing and backward error propagation and weight updating.












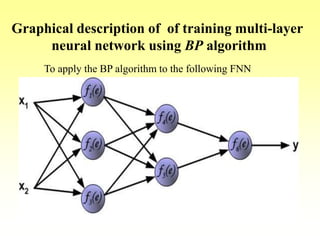

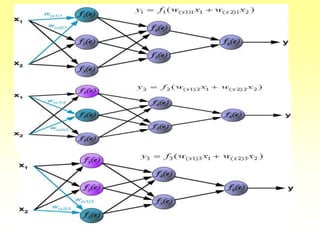
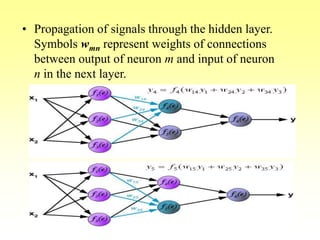
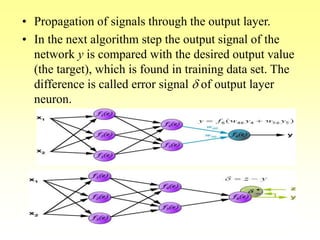


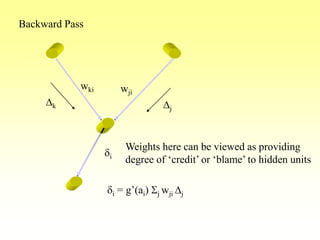
![Training Algorithm 3
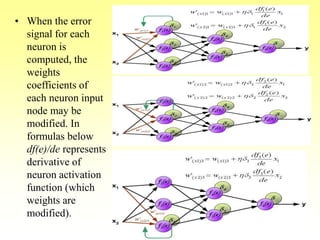
• Step 4: Propagate the delta terms (errors) back
through the weights of the hidden units where
the delta input for the jth hidden unit is:
d_inj =
dkwjk
Sk=1
m
The delta term for the jth hidden unit is:
dj = d_injf’(z_inj)
where
f’(z_inj)= f(z_inj)[1- f(z_inj)]](https://image.slidesharecdn.com/lec-6-bp-200207114550/85/Lec-6-bp-26-320.jpg)



![Backpropagate
0
0
f.21 S
-.3
.15
f-.4 S
.25
.1
f-.2 S
-.4
.3
1
1
1
d3 = (t3 – y3)f’(y_in3)
=(t3 – y3)f(y_in3)[1- f(y_in3)]
d3 = (0 – .42).42[1-.42]
= -.102
d_in1 = d3w13 = -.102(-.2) = .02
d1 = d_in1f’(z_in1) = .02(.43)(1-.43)
= .005
d_in2 = d3w12 = -.102(.3) = -.03
d2 = d_in2f’(z_in2) = -.03(.56)(1-.56)
= -.007](https://image.slidesharecdn.com/lec-6-bp-200207114550/85/Lec-6-bp-33-320.jpg)
![Update the Weights – First Pass
0
0
f.21 S
-.3
.15
f-.4 S
.25
.1
f-.2 S
-.4
.3
1
1
1
d3 = (t3 – y3)f’(y_in3)
=(t3 – y3)f(y_in3)[1- f(y_in3)]
d3 = (0 – .42).42[1-.42]
= -.102
d_in1 = d3w13 = -.102(-.2) = .02
d1 = d_in1f’(z_in1) = .02(.43)(1-.43)
= .005
d_in2 = d3w12 = -.102(.3) = -.03
d2 = d_in2f’(z_in2) = -.03(.56)(1-.56)
= -.007](https://image.slidesharecdn.com/lec-6-bp-200207114550/85/Lec-6-bp-34-320.jpg)