Downloaded 99 times













The document outlines the fundamentals of artificial neural networks (ANN), including key components like dendrites, axons, and synapses, and compares biological neuron functions to computer processing. It details mathematical functions of ANN, activation functions, and the backpropagation algorithm used for weight updates in supervised learning. Additionally, it explains the concept of gradient descent and stochastic gradient descent for optimizing neural network training.
Introduction to presenter and topic of Artificial Neural Networks.
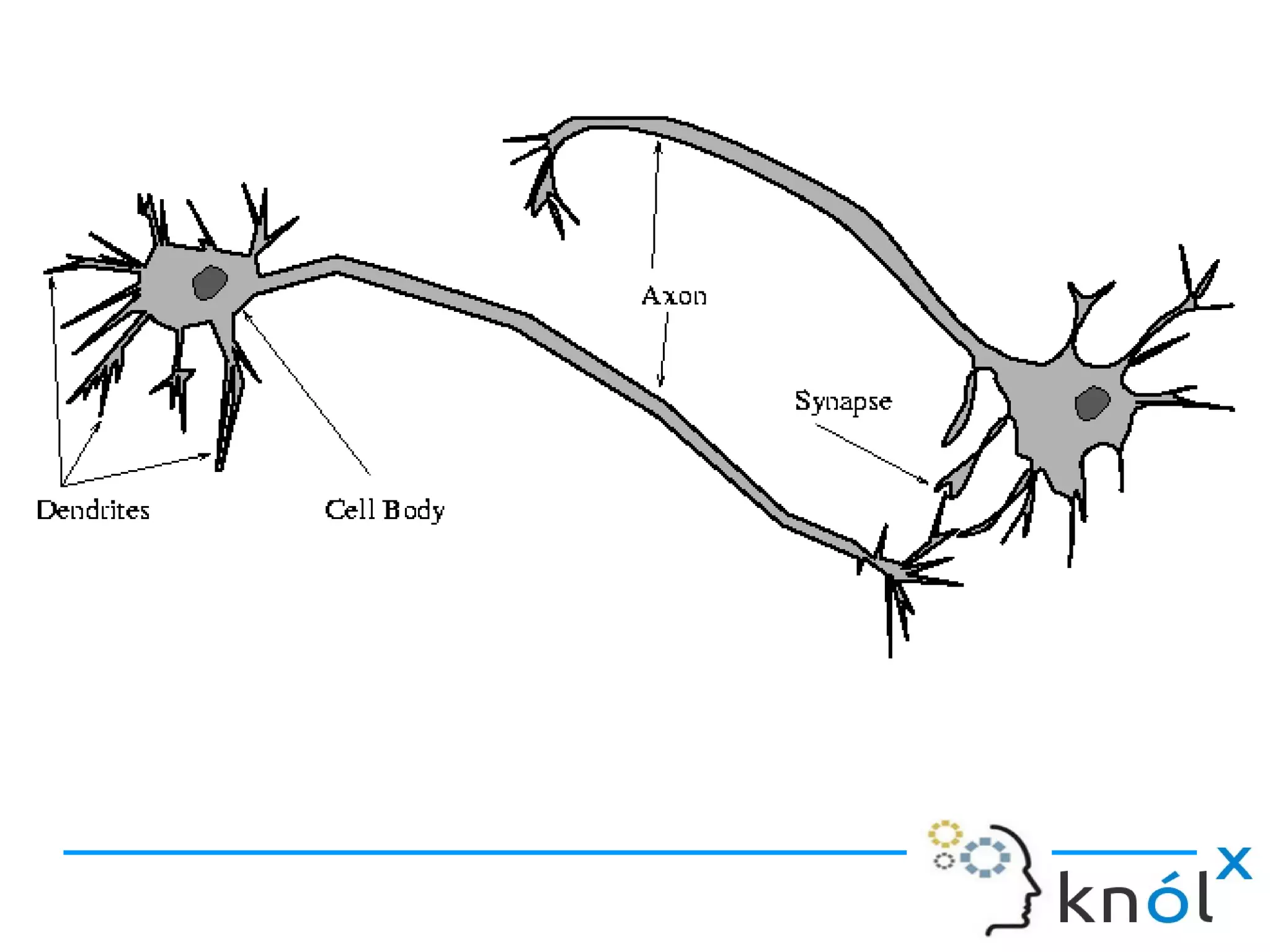
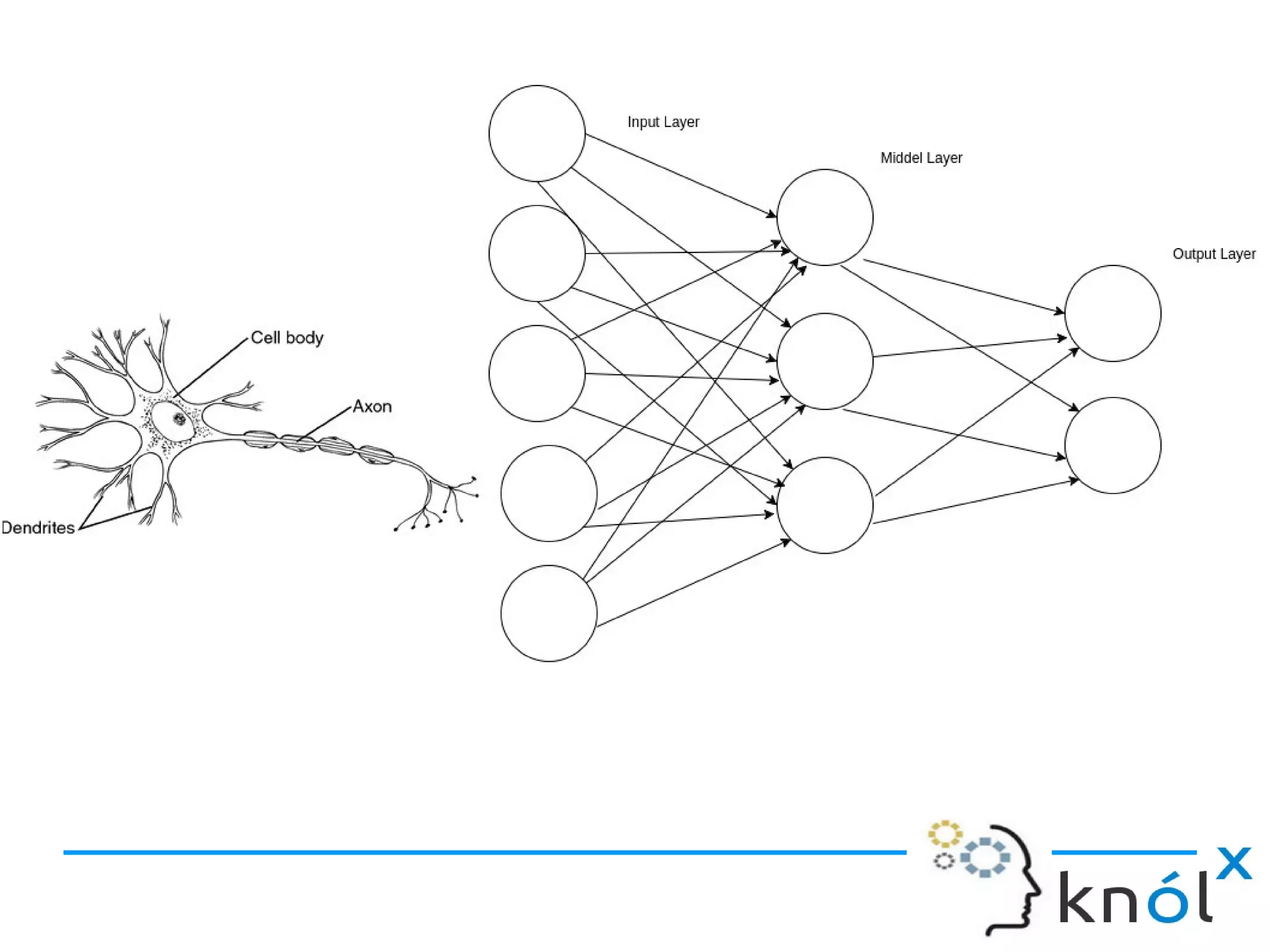
Overview of neuron components: dendrites, axon, synapse, cell body, and nucleus.
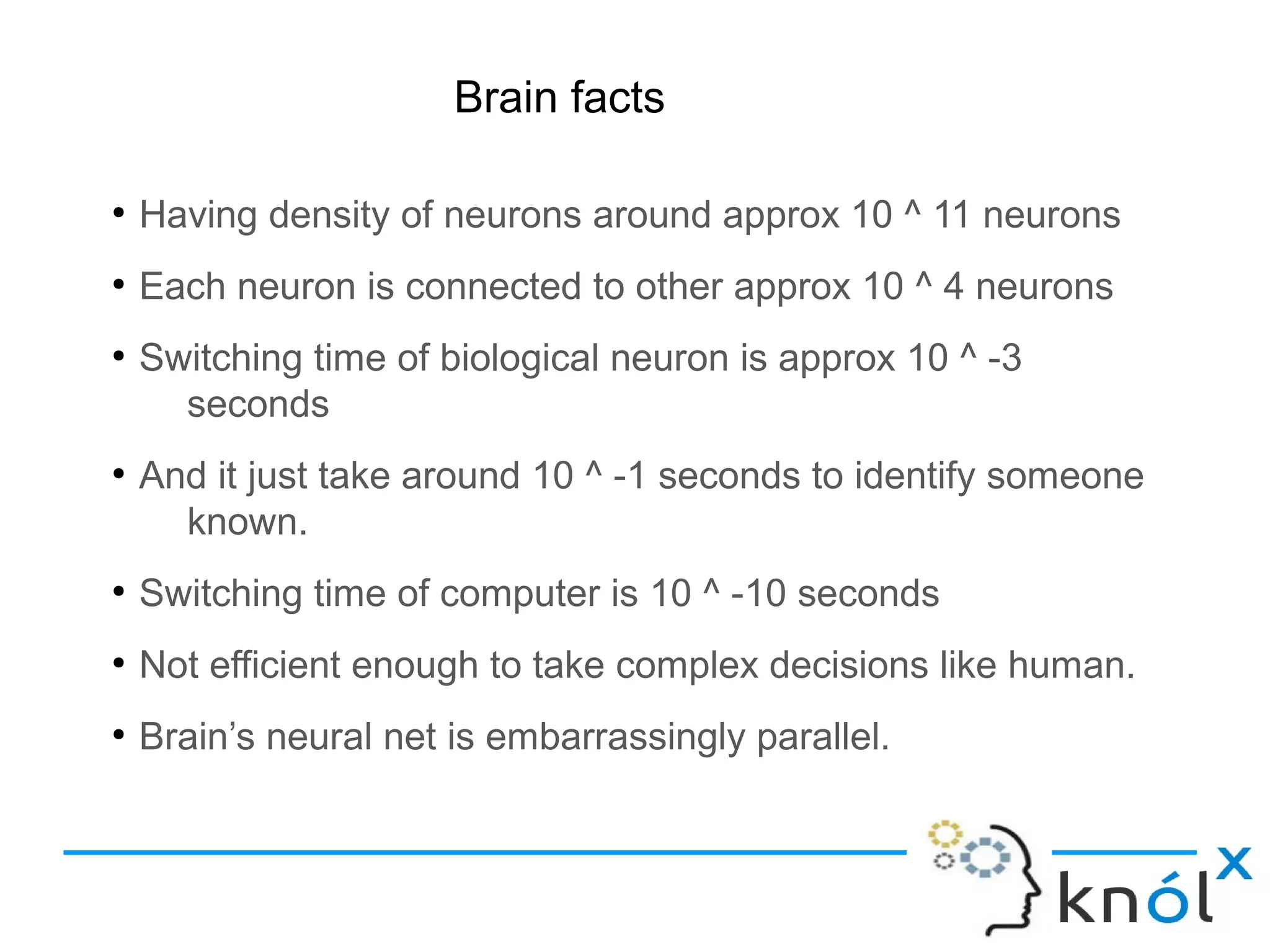
Statistics on neurons: approx 10^11 neurons, each connected to ~10^4, biological vs computer switching speeds.
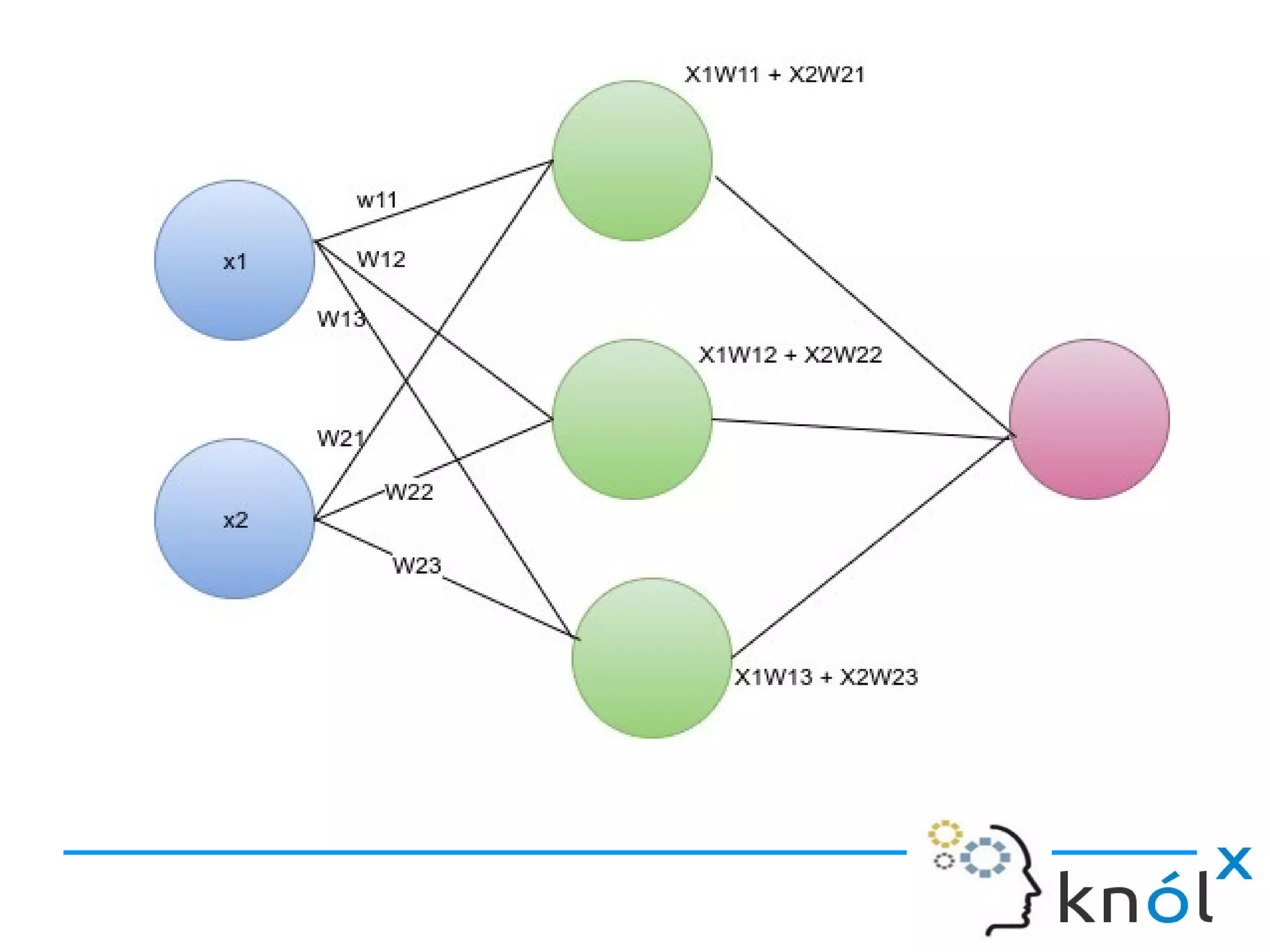
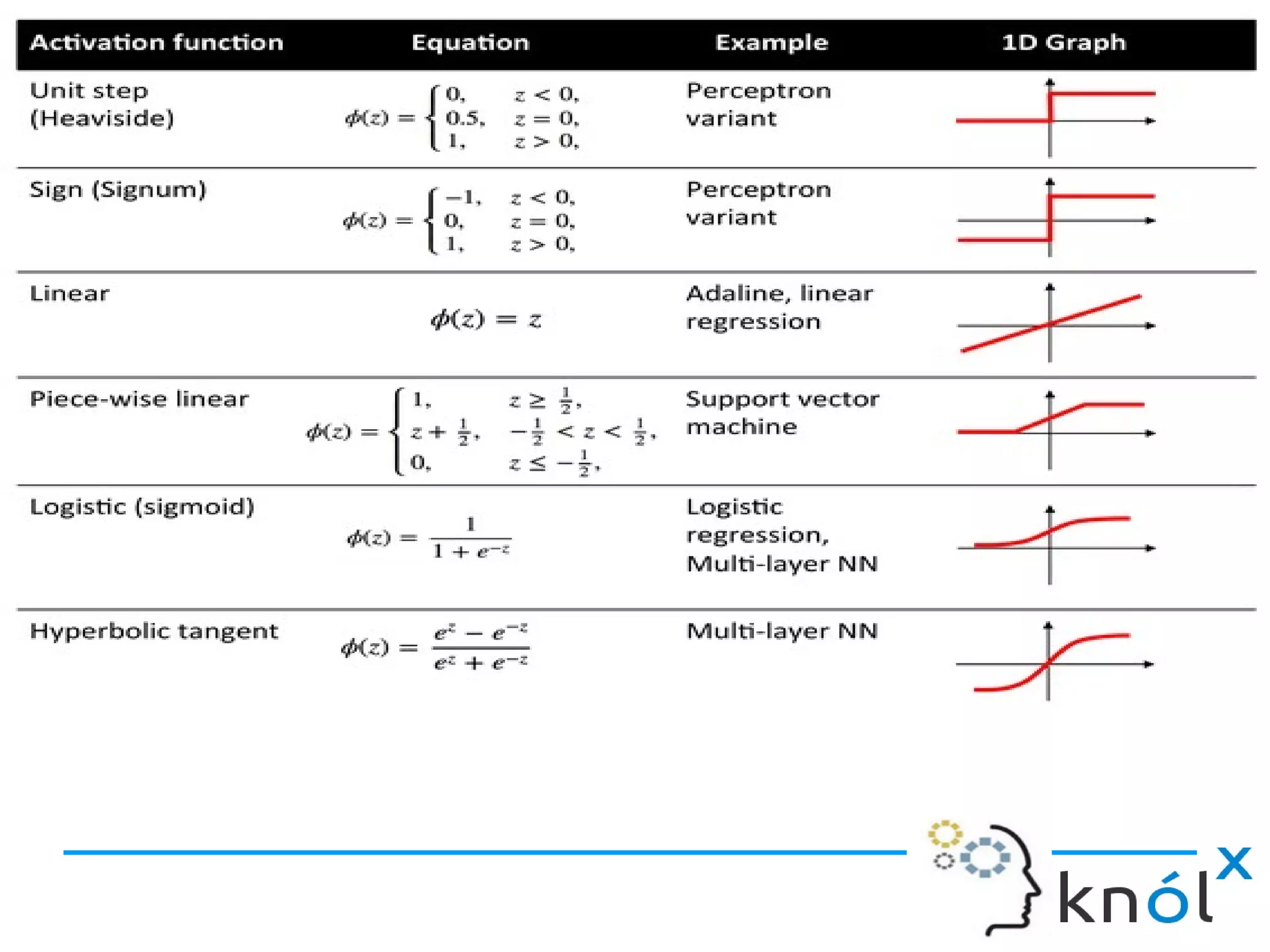
Definition of ANN and how artificial neurons function, including inputs, outputs, and activation functions.
Input weights, the sigmoid function, and predicted output computations in neural networks.
Definition of learning in computing as performance improvement with experience, according to Tom Mitchell.
Explanation of backpropagation in neural networks, utilizing error propagation adapted from biology.
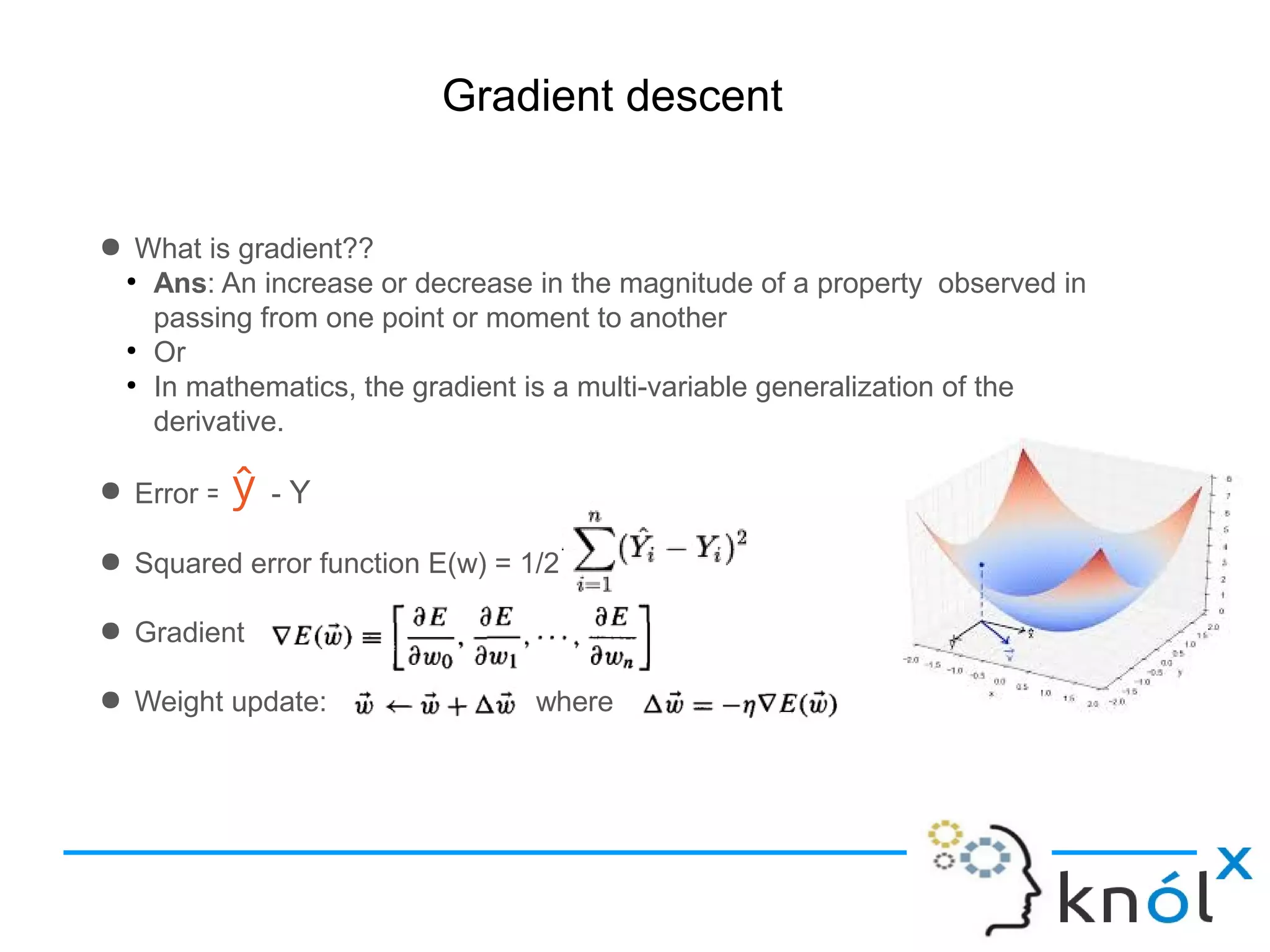
Definition of gradient and its use in minimizing error in machine learning context.
Further explanation of weight update and error derivatives in gradient descent.
Continuing discussion on gradient descent derivatives and their implications for learning.
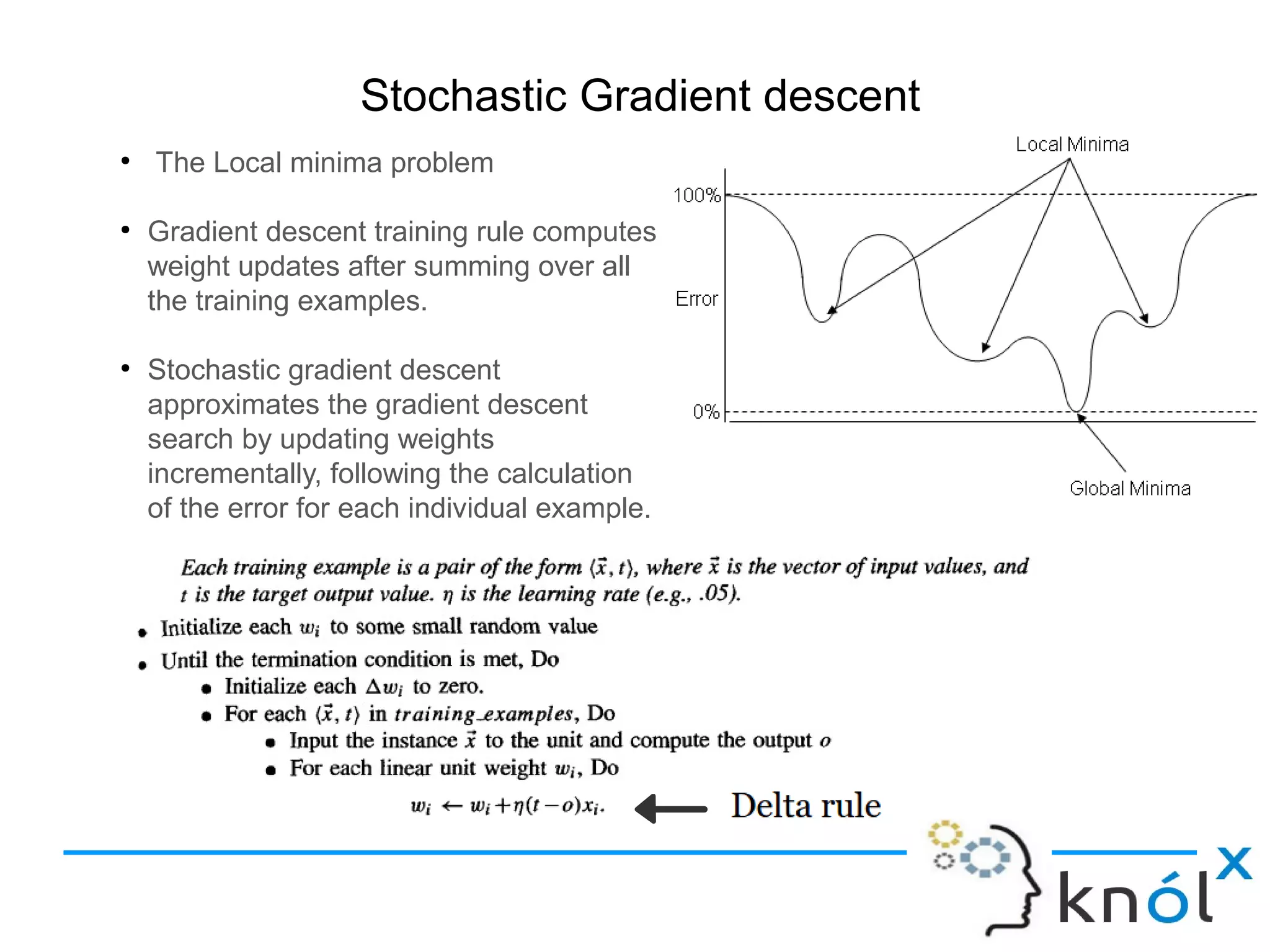
Explanation of stochastic gradient descent as a method to adjust weights incrementally to avoid local minima.
Closing remarks and thank you.






















































































