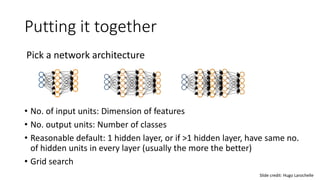
This document provides an overview of neural networks, including:
- The origins and basic structure of artificial neurons and neural networks with multiple layers.
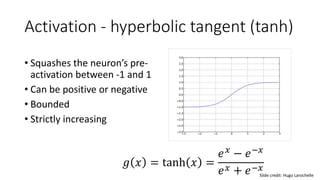
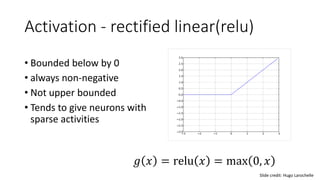
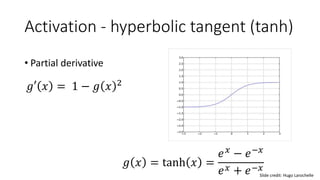
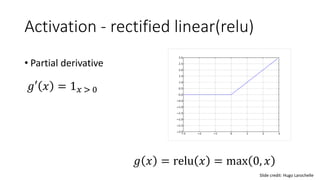
- Common activation functions like sigmoid, tanh, ReLU, and softmax.
- The universal approximation theorem which states neural networks can approximate continuous functions.
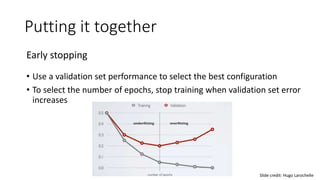
- How neural networks perform forward and backward propagation to compute gradients and update weights during training. Techniques like initialization, early stopping, and dropout help optimize training.



















![Initialization
• For bias
• Initialize all to 0
• For weights
• Can’t initialize all weights to the same value
• we can show that all hidden units in a layer will always behave the same
• need to break symmetry
• Recipe: U[-b, b]
• the idea is to sample around 0 but break symmetry
Slide credit: Hugo Larochelle](https://image.slidesharecdn.com/lec10-230321091734-2dc28fe6/85/Lec10-pptx-24-320.jpg)