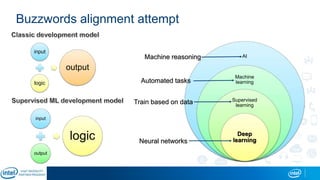
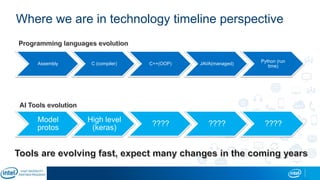
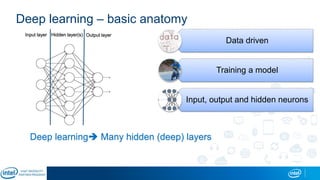
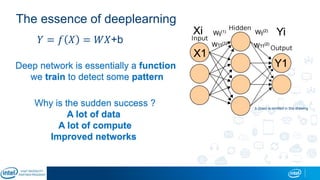
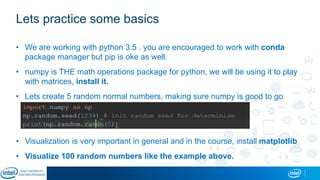
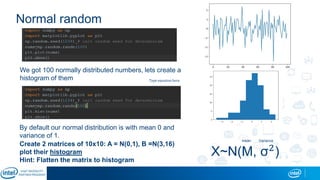
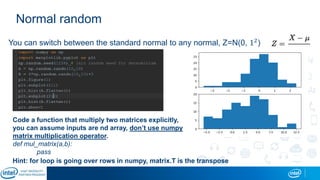
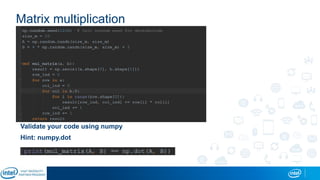
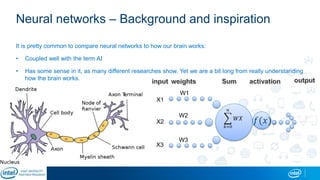
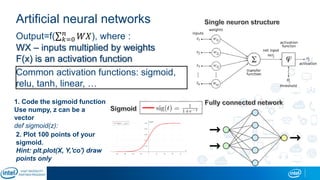
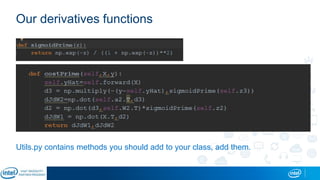
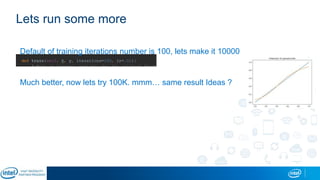
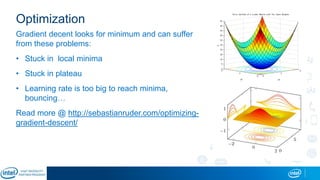
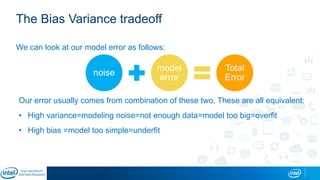
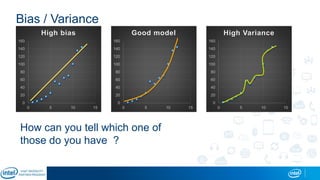
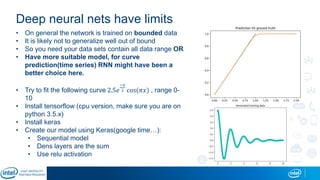
Eran Shlomo, a tech lead at Intel, outlines a deep learning course agenda focusing on theory, practical coding, and hands-on exercises using Python and relevant libraries. Participants will learn basic deep learning concepts and tools, but won't gain practical problem-solving experience or expert-level math skills. The document emphasizes the importance of data handling, model training, and understanding bias-variance tradeoff in developing effective neural networks.