





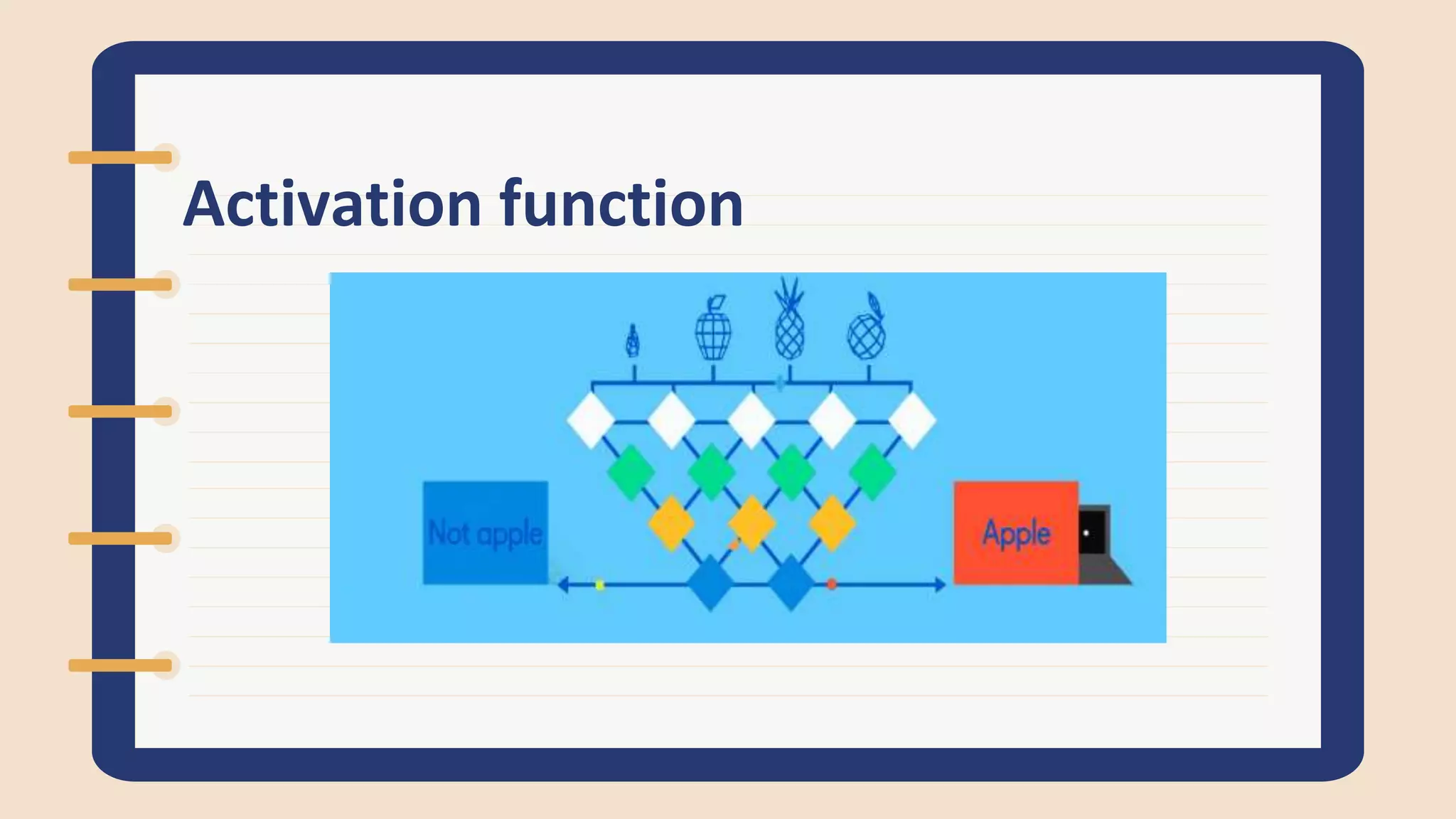












The document discusses various activation functions used in neural networks including Tanh, ReLU, Leaky ReLU, Sigmoid, and Softmax. It explains that activation functions introduce non-linearity and allow neural networks to learn complex patterns. Tanh squashes outputs between -1 and 1 while ReLU sets negative values to zero, addressing the "dying ReLU" problem. Leaky ReLU allows a small negative slope. Sigmoid and Softmax transform outputs between 0-1 for classification problems. Activation functions determine if a neuron's output is important for prediction.
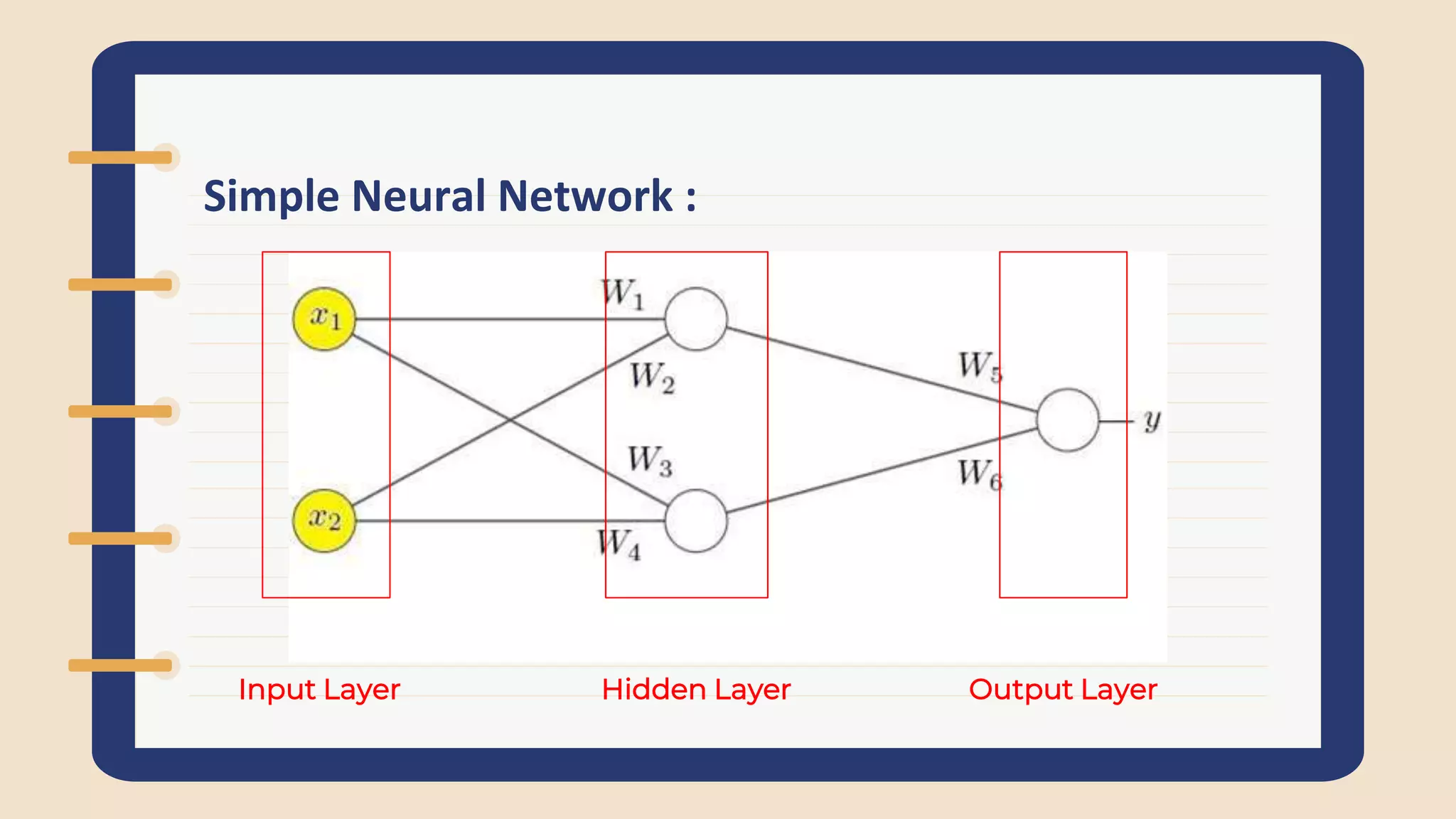
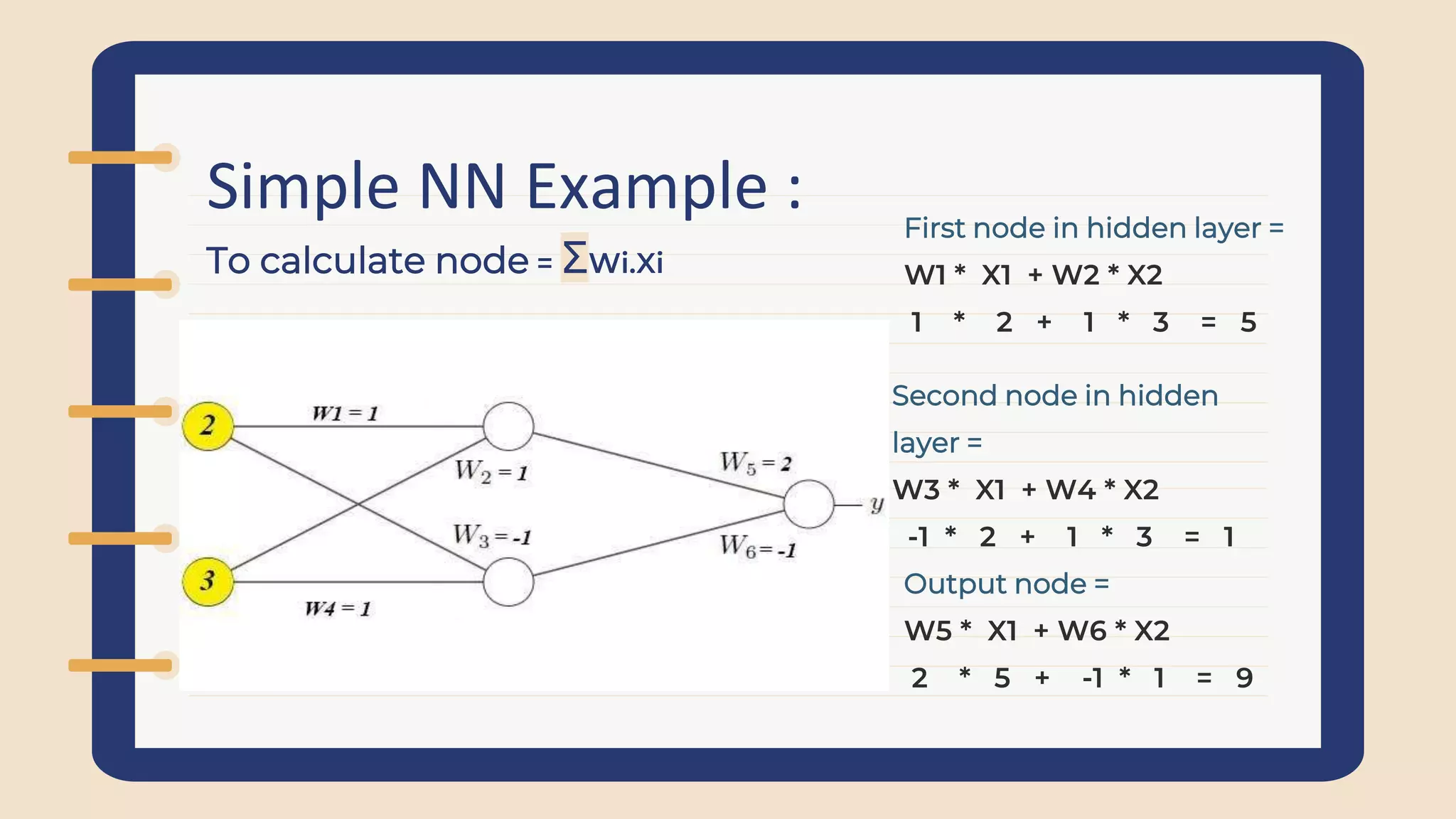
Introduction by Mohamed Essam and Nourhan Ahmed. Overview of simple neural networks, including layers and an example calculation of node outputs in a neural network.
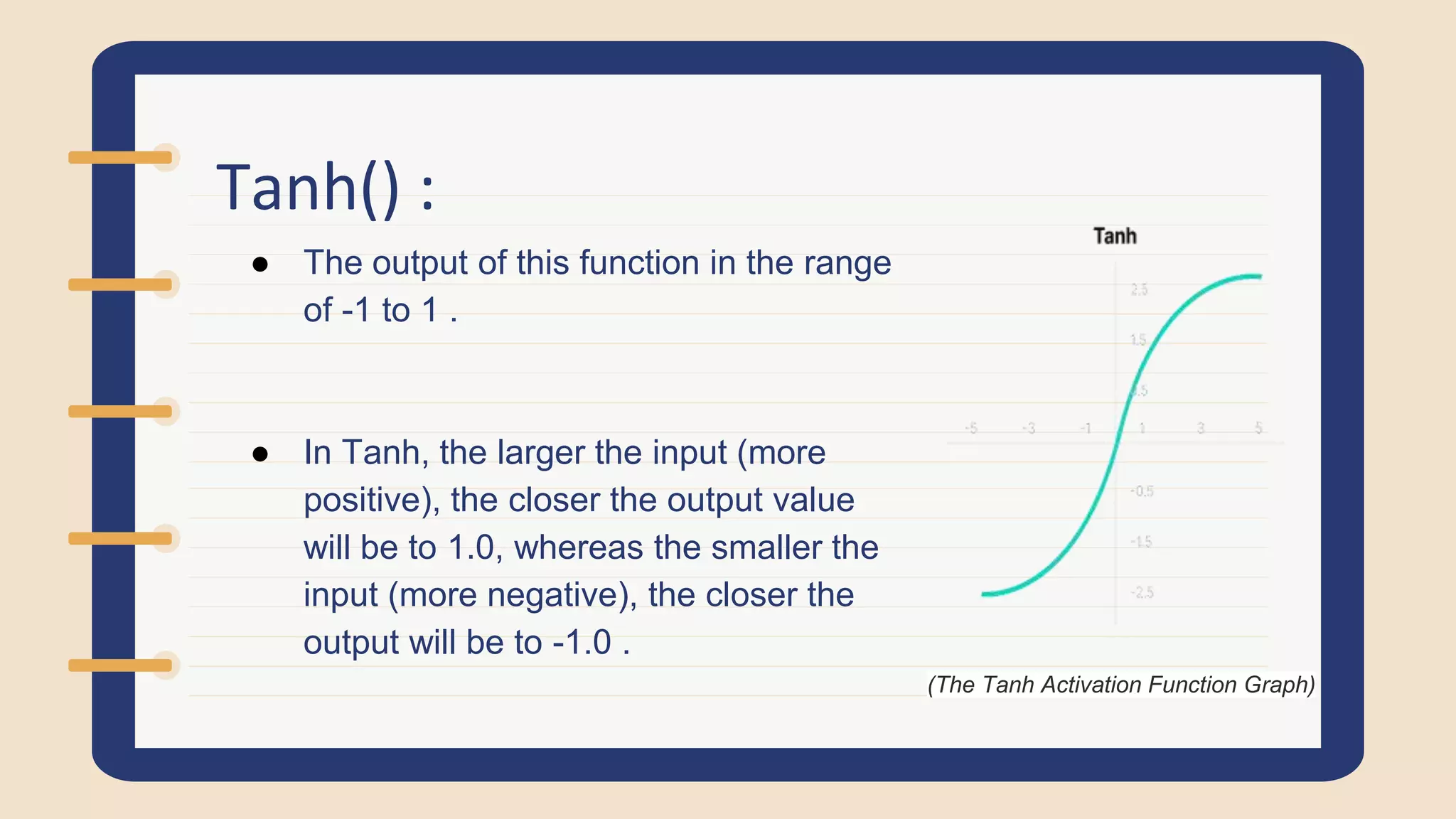
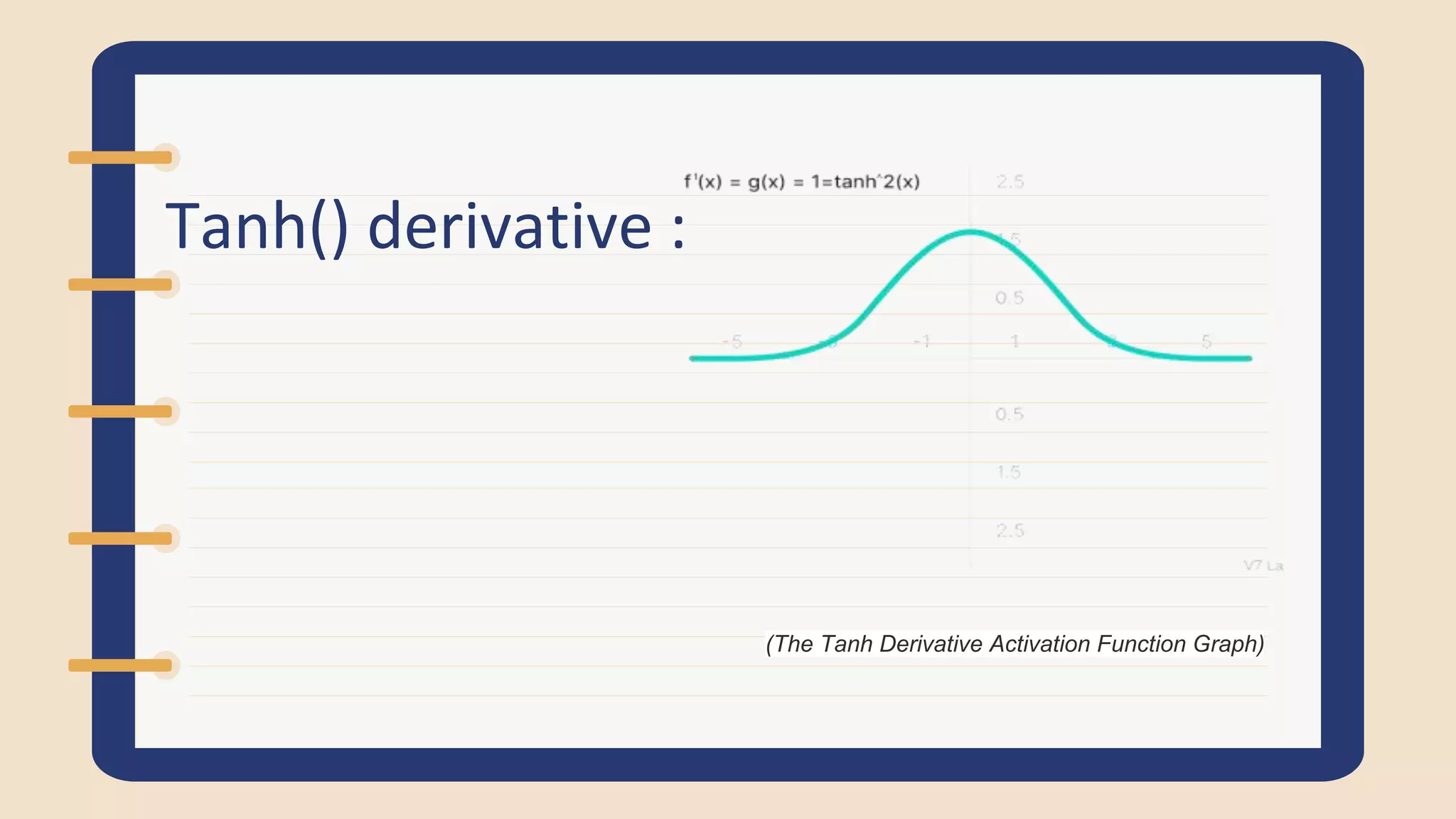
Defines activation functions, explaining their necessity for introducing non-linearity. Discusses Tanh function, its graph, and example calculations.
Introduction to ReLU (Rectified Linear Unit) function, its computational efficiency, and how it only activates neurons when outputs are >0.
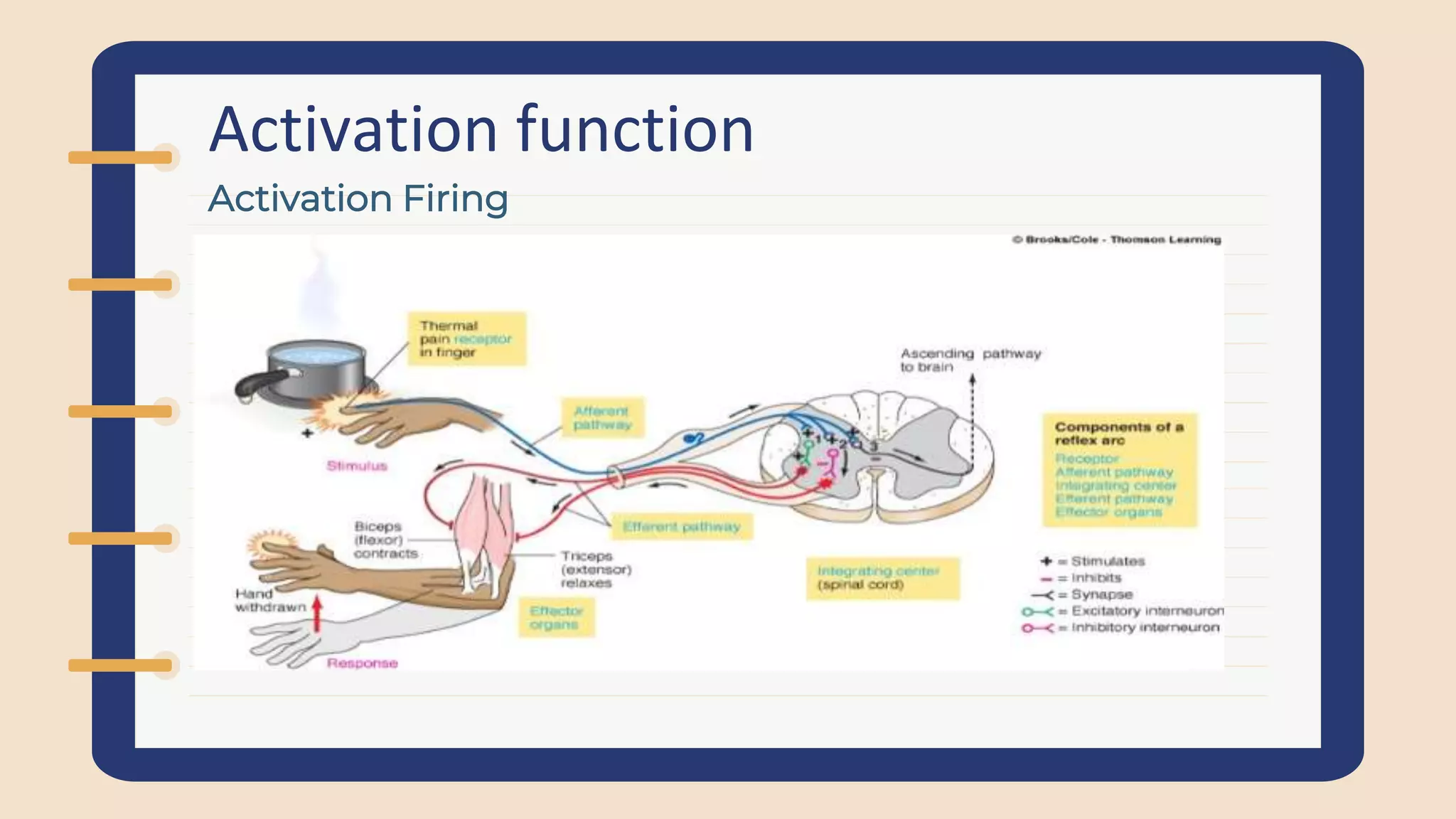
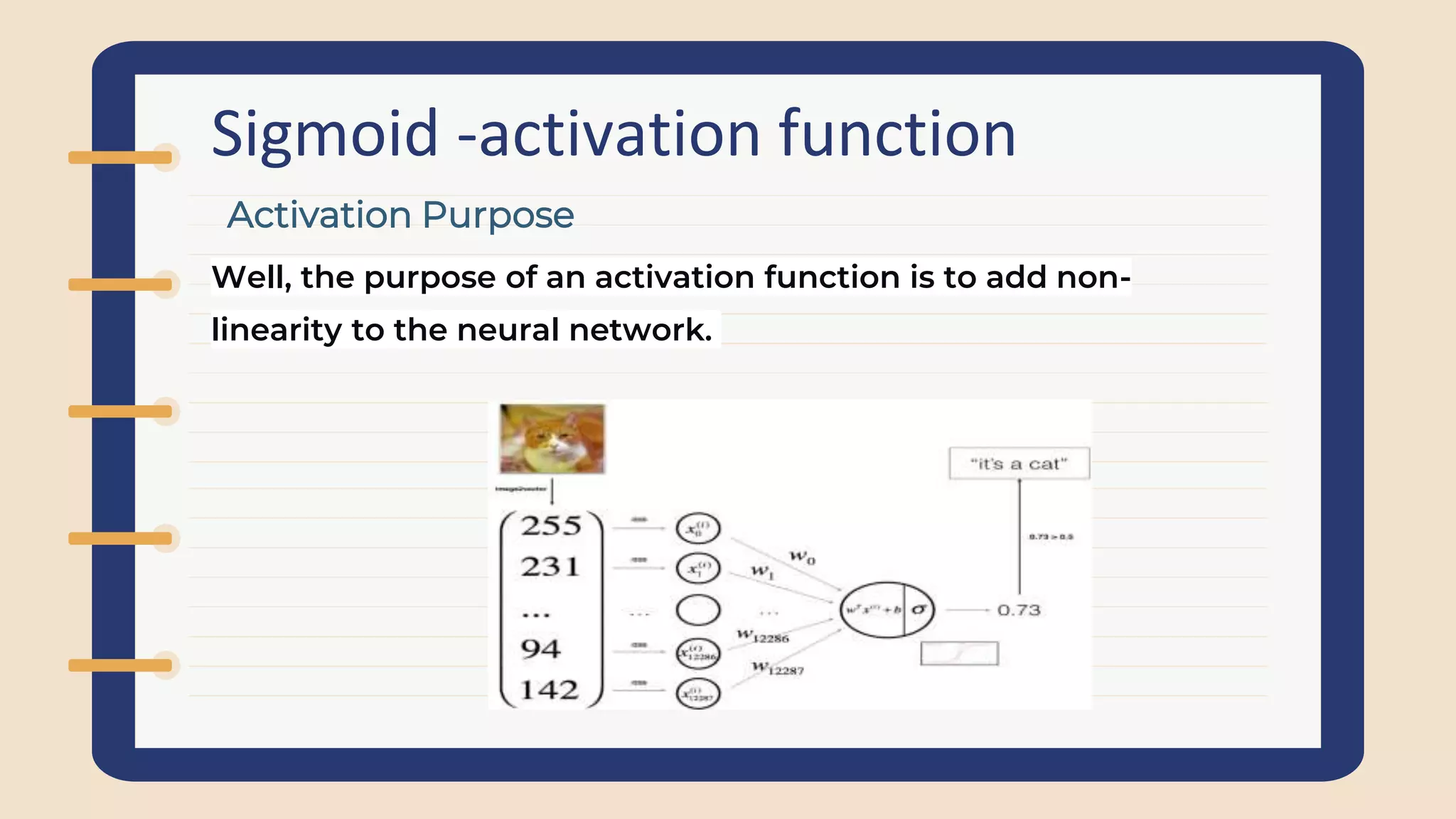
Explains role of activation functions in neuron firing, mapping outputs, and determining neuron importance for predictions.
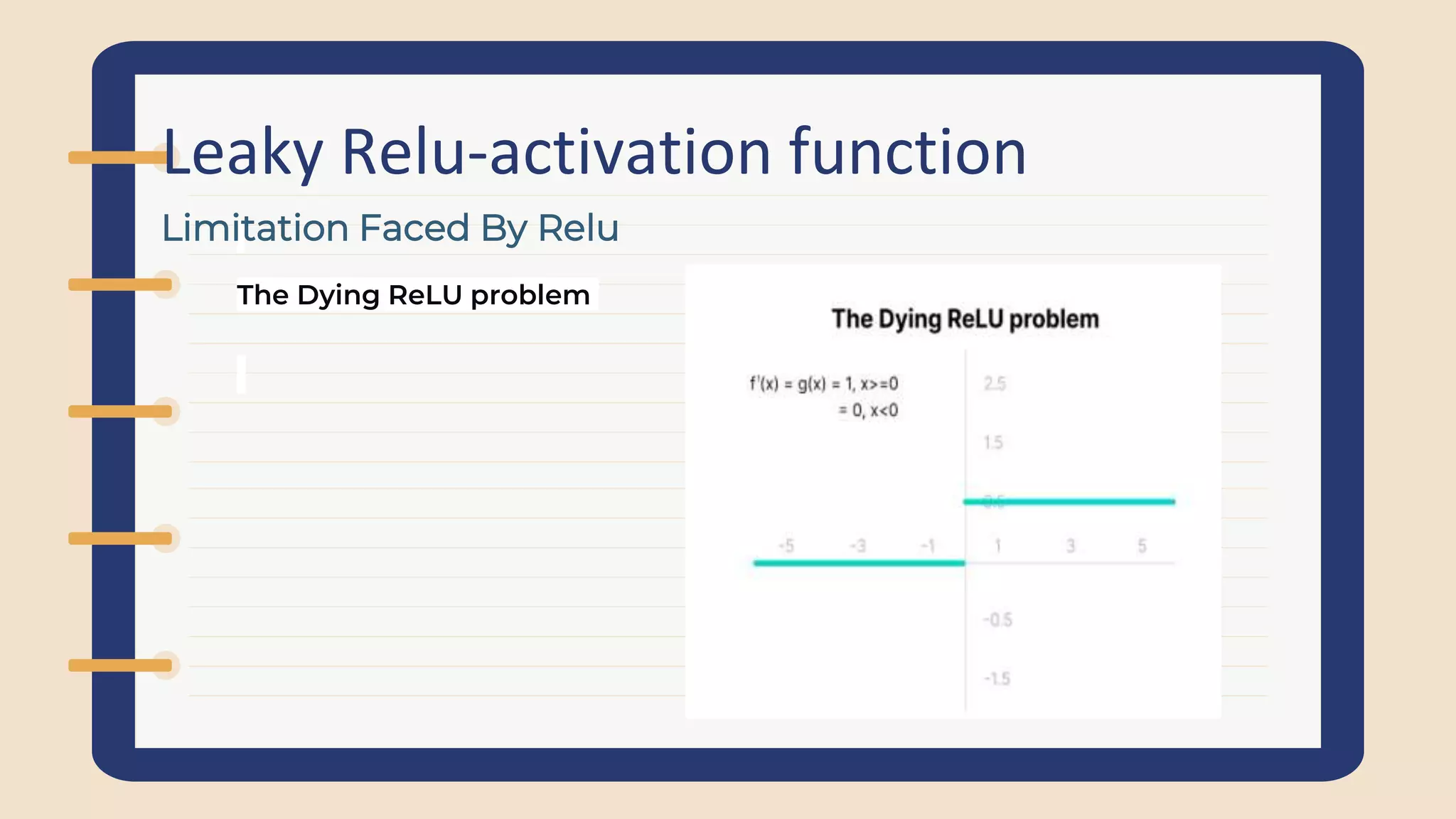
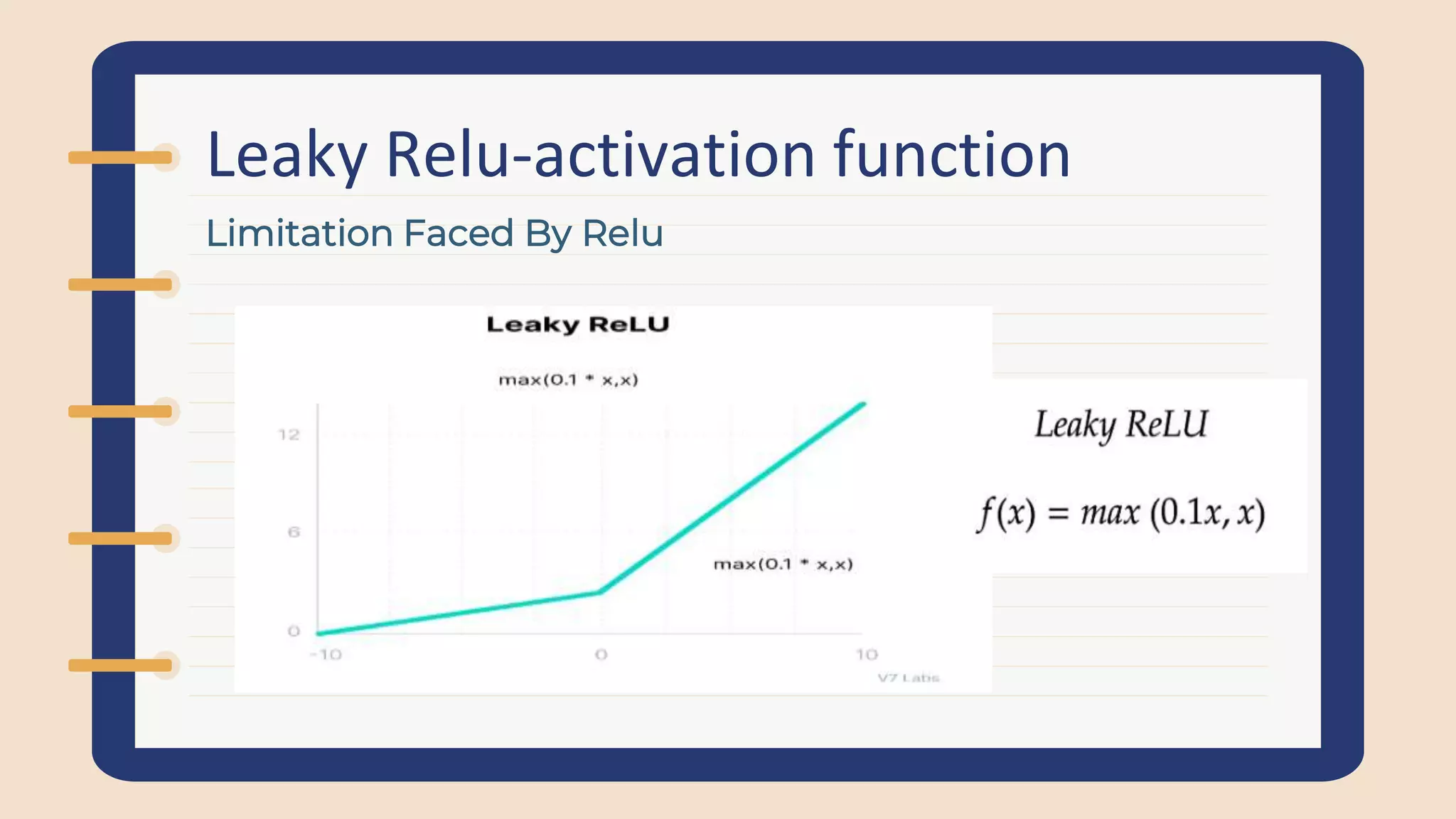
Discusses the Dying ReLU problem, limitations of ReLU, and the advantages of Leaky ReLU which prevents dead neurons during training.
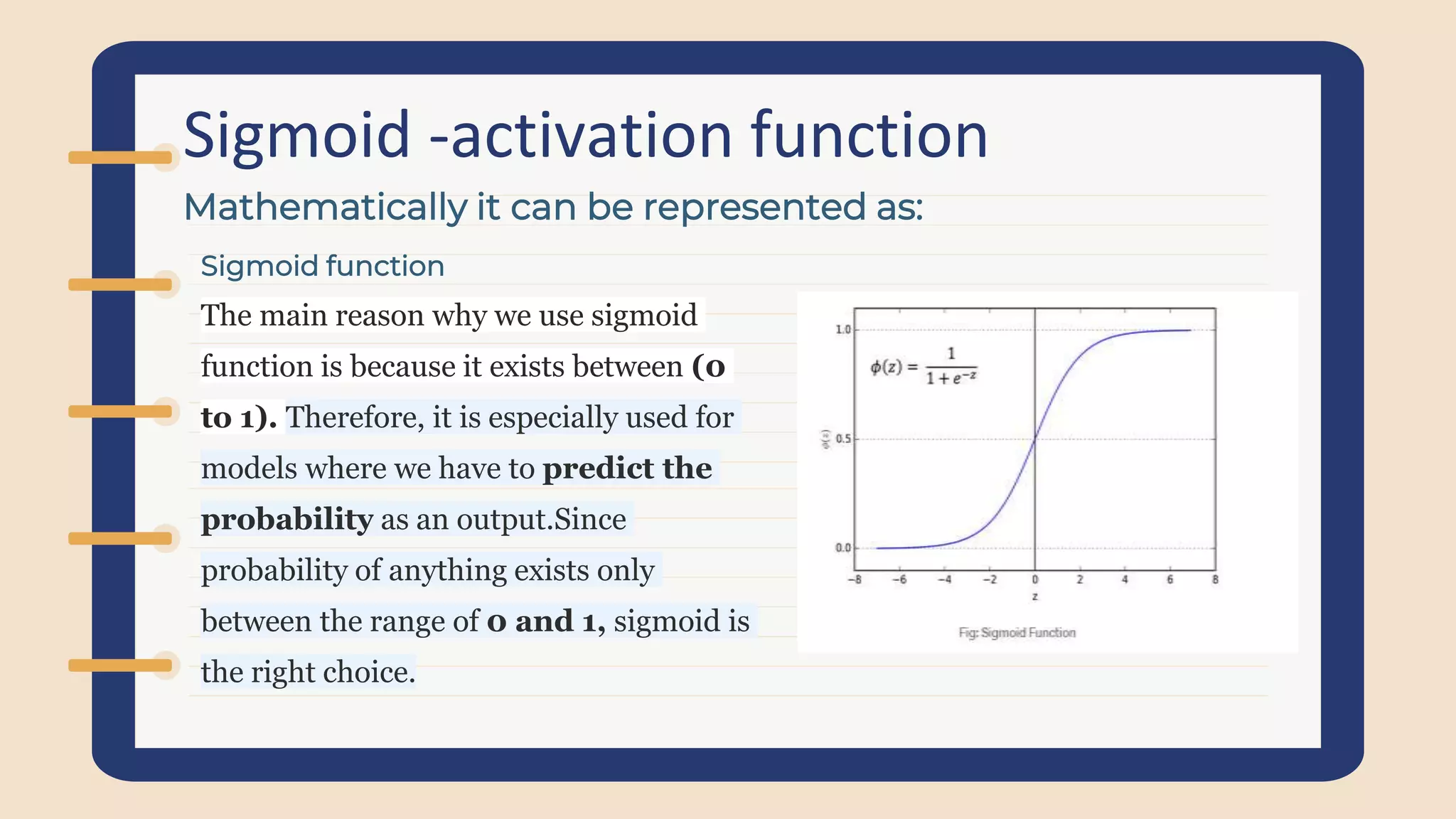
Introduction to the Sigmoid function, why it's used for probabilities, and its role in adding non-linearity within neural networks.
Describes the Softmax function, its transformation of input values into probabilities, comparison with Sigmoid, and its application in neural networks.
Attribution credits for the presentation, thanking the audience and inviting questions.