補足:関連するかもしれない研究
• Generalization inDeep Networks: The Role of Distance from Initialization [Vaishnavh
Nagarajan+, NIPSW2017] http://www.cs.cmu.edu/~vaishnan/papers/nips17_dltp.pdf
• Towards Understanding the Role of Over-Parametrization in Generalization of Neural
Networks [Behnam Neyshabur+, arXiv2018] https://arxiv.org/abs/1805.12076
ランダム初期化時と学習後の重みの値の距離に基づいて汎化誤差を分析
• DropBack: Continuous Pruning During Training [Maximilian Golub+, arXiv2018]
https://arxiv.org/abs/1806.06949
• Intriguing Properties of Randomly Weighted Networks: Generalizing While Learning Next
to Nothing [Amir Rosenfeld+,arXiv2018] https://arxiv.org/abs/1802.00844
重みの大半をランダム初期値で固定し、一部の重みのみを更新
• Insights on representational similarity in neural networks with canonical correlation
[Ari S. Morcos+, arXiv2018] https://arxiv.org/abs/1806.05759
大きなネットワークほど似た解に収束する



![ディープの闇1:ガチャ問題
• DNNの重み初期値は乱数で決定されることが多い
• ランダムSEEDによって精度が大きく変動し、
ガチャ、くじ、運ゲーの要素を持つ
https://twitter.com/mosko_mule/status/877318385381421056
https://twitter.com/takayosiy/status/997145407183503361
・Deep Reinforcement Learning that Matters
[Peter Henderson+, AAAI2018] https://arxiv.org/abs/1709.06560
・Deep Reinforcement Learning Doesn't Work Yet
https://www.alexirpan.com/2018/02/14/rl-hard.html
・How Many Random Seeds? [Cédric Colas+, arXiv2018]
https://arxiv.org/abs/1806.08295
強化学習での例
https://twitter.com/musyokudon/status/873478045847273472](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-3-320.jpg)



![標準的なpruning方法
図は [Song Han+, NIPS2015] を元に作成
(1) ランダム初期化
(2) 学習 (3) pruning (5) 再学習
重要性の低い要素を除去](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-7-320.jpg)
![宝くじ券仮説の実験的な確かめ方(pruningによる当選券抽出)
図は [Song Han+, NIPS2015] を元に作成
(2) 学習 (3) pruning (5) 再学習
(4) (1)でのランダム初期値に
リセットし、当選券抽出(1) ランダム初期化](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-8-320.jpg)
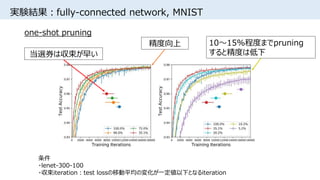
![実験条件
• [Song Han+, NIPS2015]同様、重みの絶対値が小さい接続をpruning
• One-shot pruning:学習後、所望のサイズまで一気にpruning
• Iterative pruning:学習、pruning、重みリセットを繰り返し、
徐々にネットワークを小さくする
• ネットワーク設計等](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-9-320.jpg)
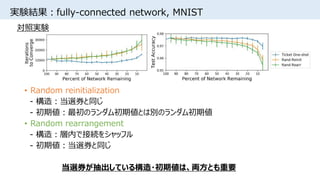
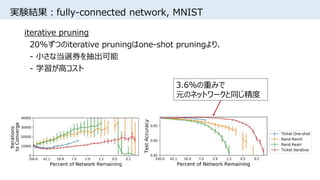
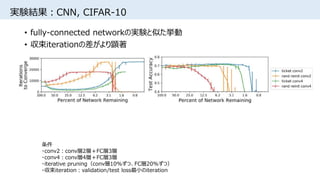
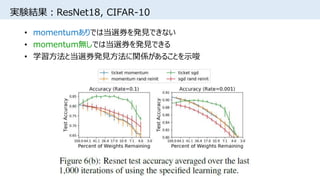
![実験結果:当選券の初期値分布
• 0付近の初期値を持つ重みは学習後も値が小さくpruningされやすい
• [Song Han+, NIPS2015]でpruning・再学習後に見られる分布と似ているが、
上図は学習前の分布
• 正規分布からのランダム初期化は実質的に
スパースなアーキテクチャをサンプリングしていることを示唆
条件
・iterative pruning
・fully-connected network
・MNIST](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-15-320.jpg)
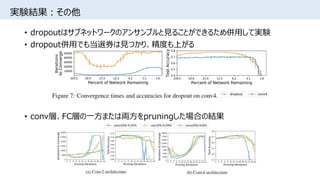
![関連研究(RandomOut)
RandomOut: Using a convolutional gradient norm to win The Filter
Lottery [Joseph Paul Cohen+, ICLRW2016]
https://openreview.net/forum?id=2xwPmERVBtpKBZvXtQnD
https://arxiv.org/abs/1602.05931
初期値ガチャ問題を正面突破する論文
• CNNのフィルタは初期化に敏感で、
ランダムSEEDによって精度も学習されるフィルタも変わる
• 当選して、満足いく精度に収束したらSEEDが決まるため、
この問題を “The Filter Lottery” と呼ぶ
• 重要でないフィルタを初期化し直し、
探索するフィルタを増やすことで、
ネットワークサイズを大きくすることなく精度を向上させる](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-17-320.jpg)
![関連研究(接続復活系)
• DSD: Dense-Sparse-Dense Training [Song Han+, ICLR2017]
https://arxiv.org/abs/1607.04381
• Iterative Hard Thresholding (IHT) [Xiaojie Jin+, arXiv2016]
https://arxiv.org/abs/1607.05423
• Dynamic Network Surgery [Yiwen Guo+, NIPS2016]
https://arxiv.org/abs/1608.04493
• Deep Rewiring (DEEP R) [Guillaume Bellec+, ICLR2018]
https://arxiv.org/abs/1711.05136
http://db-event.jpn.org/deim2018/data/papers/317.pdf](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-18-320.jpg)


![補足:関連するかもしれない研究
• Generalization in Deep Networks: The Role of Distance from Initialization [Vaishnavh
Nagarajan+, NIPSW2017] http://www.cs.cmu.edu/~vaishnan/papers/nips17_dltp.pdf
• Towards Understanding the Role of Over-Parametrization in Generalization of Neural
Networks [Behnam Neyshabur+, arXiv2018] https://arxiv.org/abs/1805.12076
ランダム初期化時と学習後の重みの値の距離に基づいて汎化誤差を分析
• DropBack: Continuous Pruning During Training [Maximilian Golub+, arXiv2018]
https://arxiv.org/abs/1806.06949
• Intriguing Properties of Randomly Weighted Networks: Generalizing While Learning Next
to Nothing [Amir Rosenfeld+,arXiv2018] https://arxiv.org/abs/1802.00844
重みの大半をランダム初期値で固定し、一部の重みのみを更新
• Insights on representational similarity in neural networks with canonical correlation
[Ari S. Morcos+, arXiv2018] https://arxiv.org/abs/1806.05759
大きなネットワークほど似た解に収束する](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-21-320.jpg)
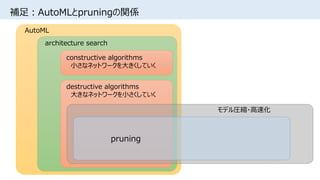
![補足:AutoMLとpruningの関係
• constructive/destructive algorithmsは、
単調に変形を行うstructural hill climbingであり、
structural local minimaに陥りやすいという指摘がある
[Peter J. Angeline+, Neural Networks 1994]
• pruningや以下のようなアーキテクチャ探索手法は、
人間が良い初期構造・探索空間を設定することが重要と考えられる
- NASH [Thomas Elsken+, ICLRW2018] https://arxiv.org/abs/1711.04528
https://www.slideshare.net/takahirokubo7792/1simple-and-efficient-architecture-search-for-convolutional-neural-networks
- DARTS [Hanxiao Liu+, arXiv2018] https://arxiv.org/abs/1806.09055
https://www.slideshare.net/YutaKoreeda/darts-differentiable-architecture-search
(重要性の低いoperationをpruningしている)](https://image.slidesharecdn.com/lotteryticket-180710121026/85/The-Lottery-Ticket-Hypothesis-Finding-Small-Trainable-Neural-Networks-23-320.jpg)

![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)









![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会] Adversarial Skill Chaining for Long-Horizon Robot Manipulation via T...](https://cdn.slidesharecdn.com/ss_thumbnails/211210dlseminarnakamoto-211210051019-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
