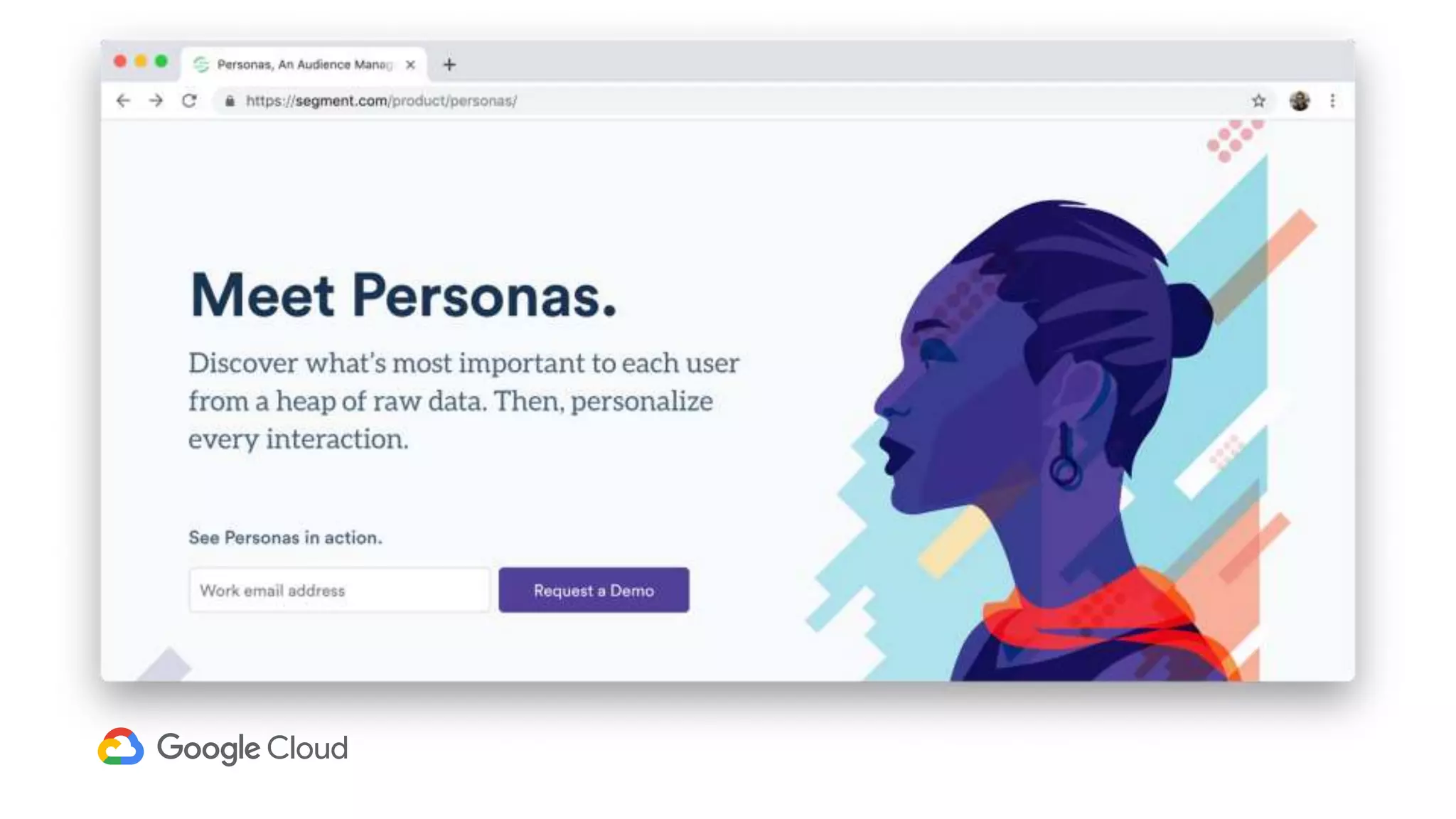
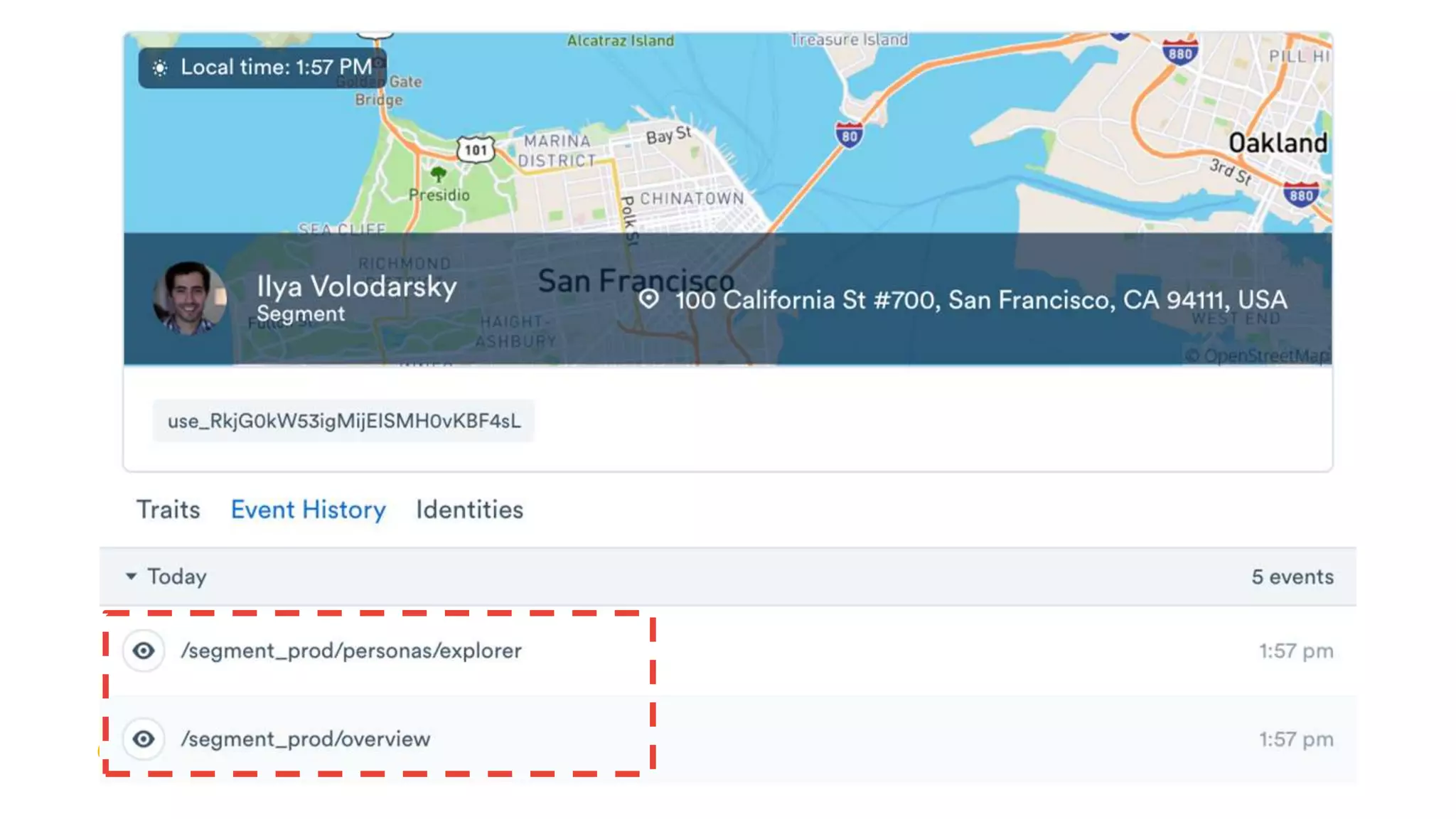
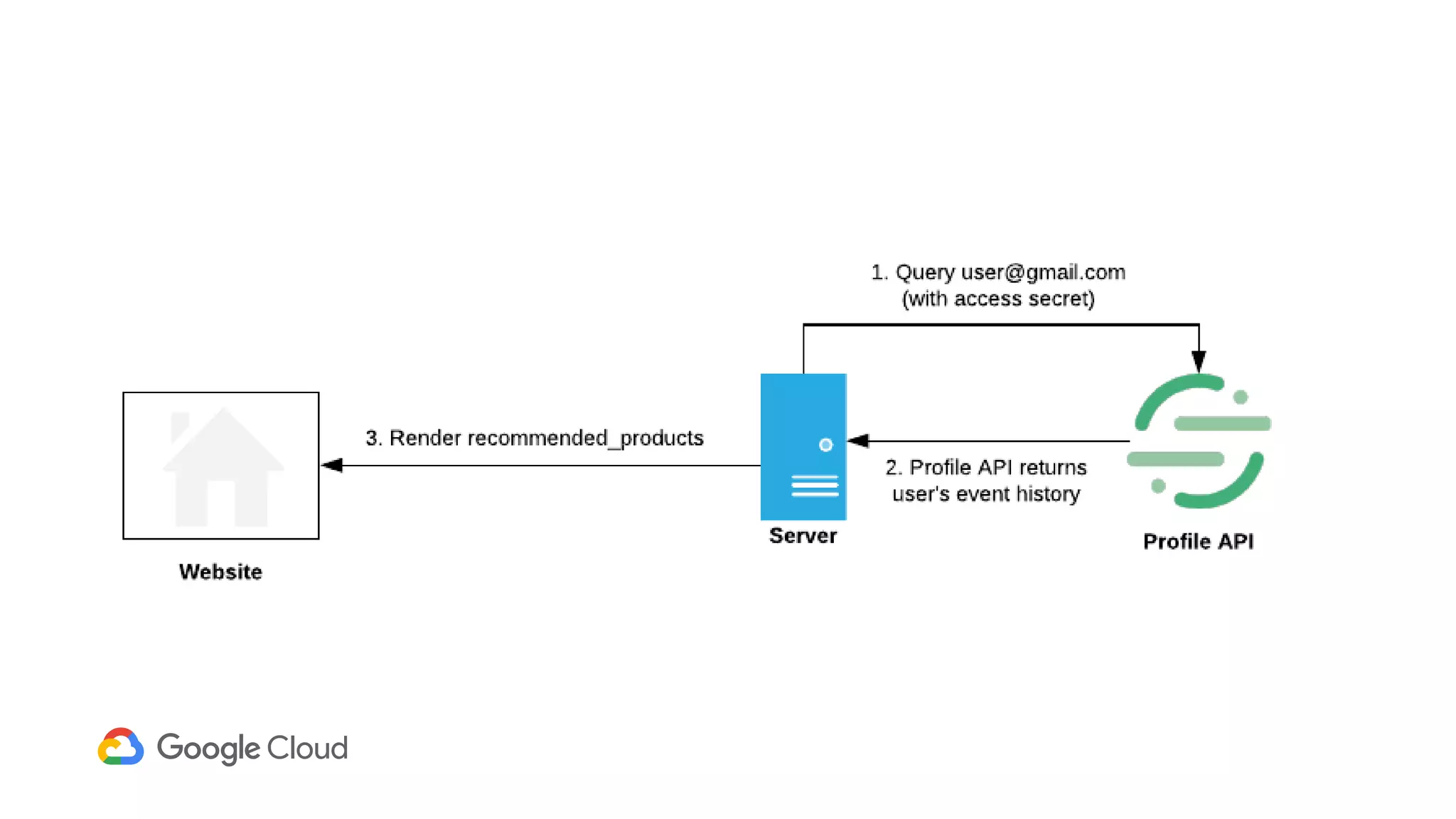
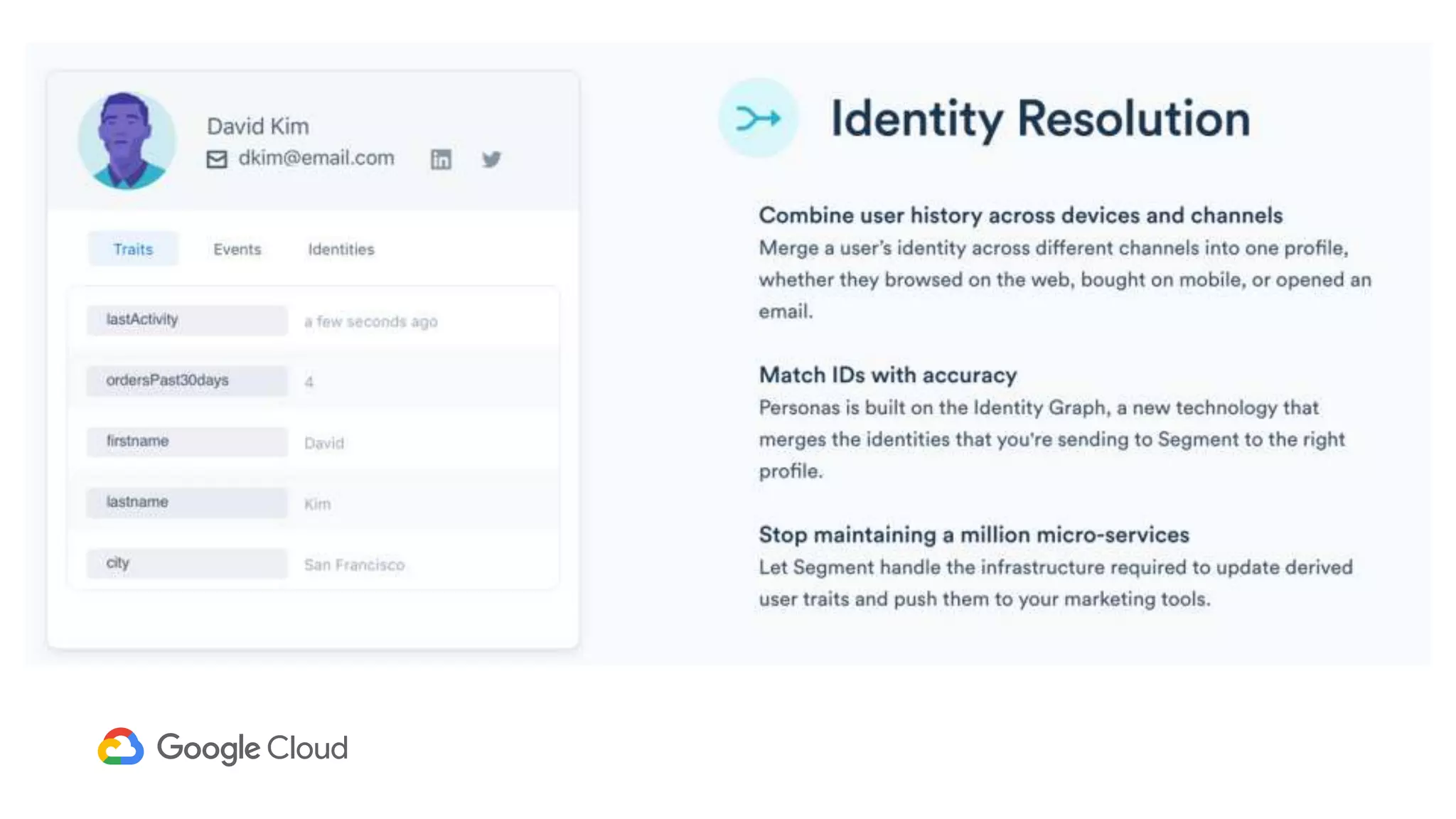
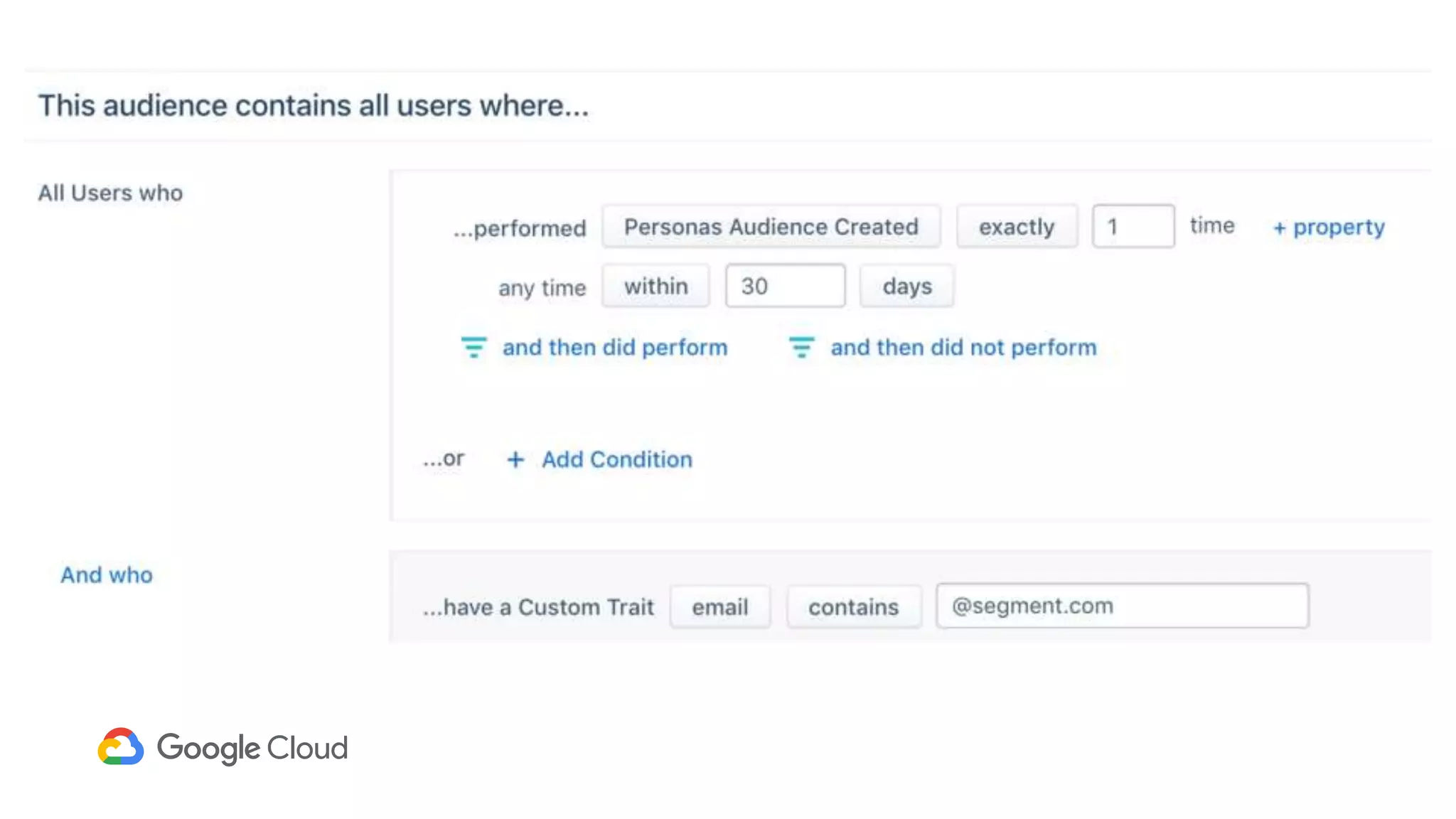
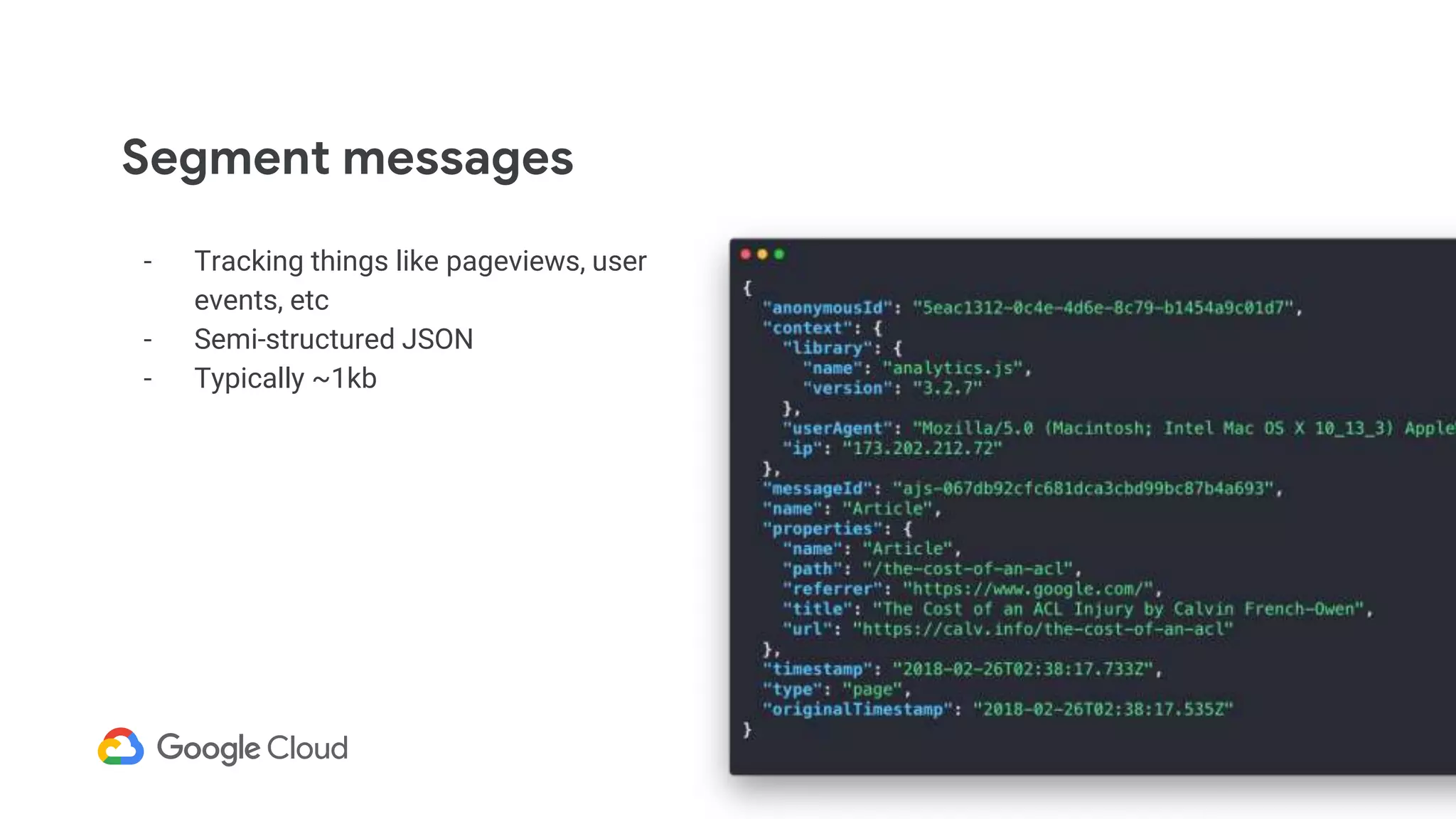
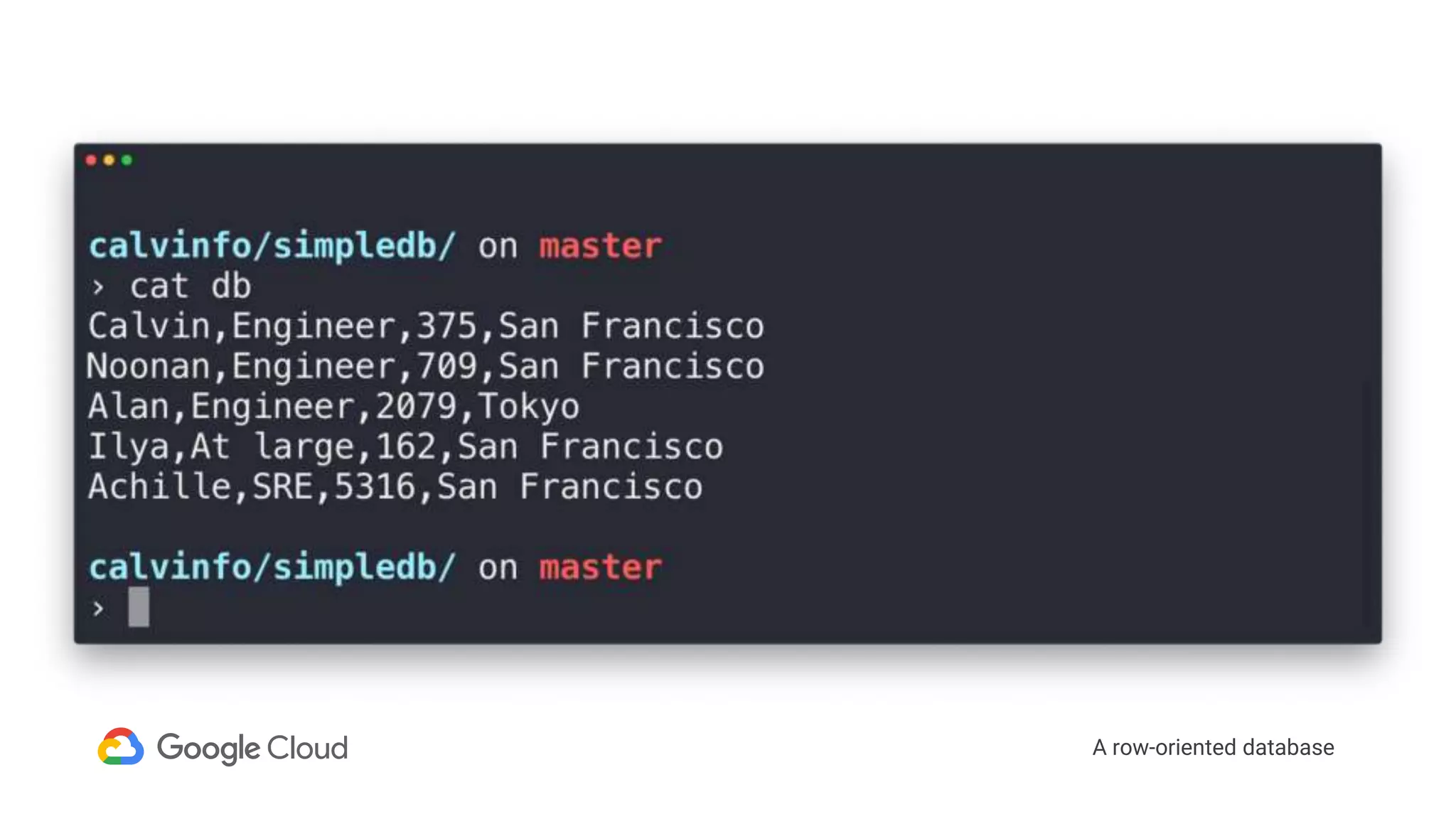
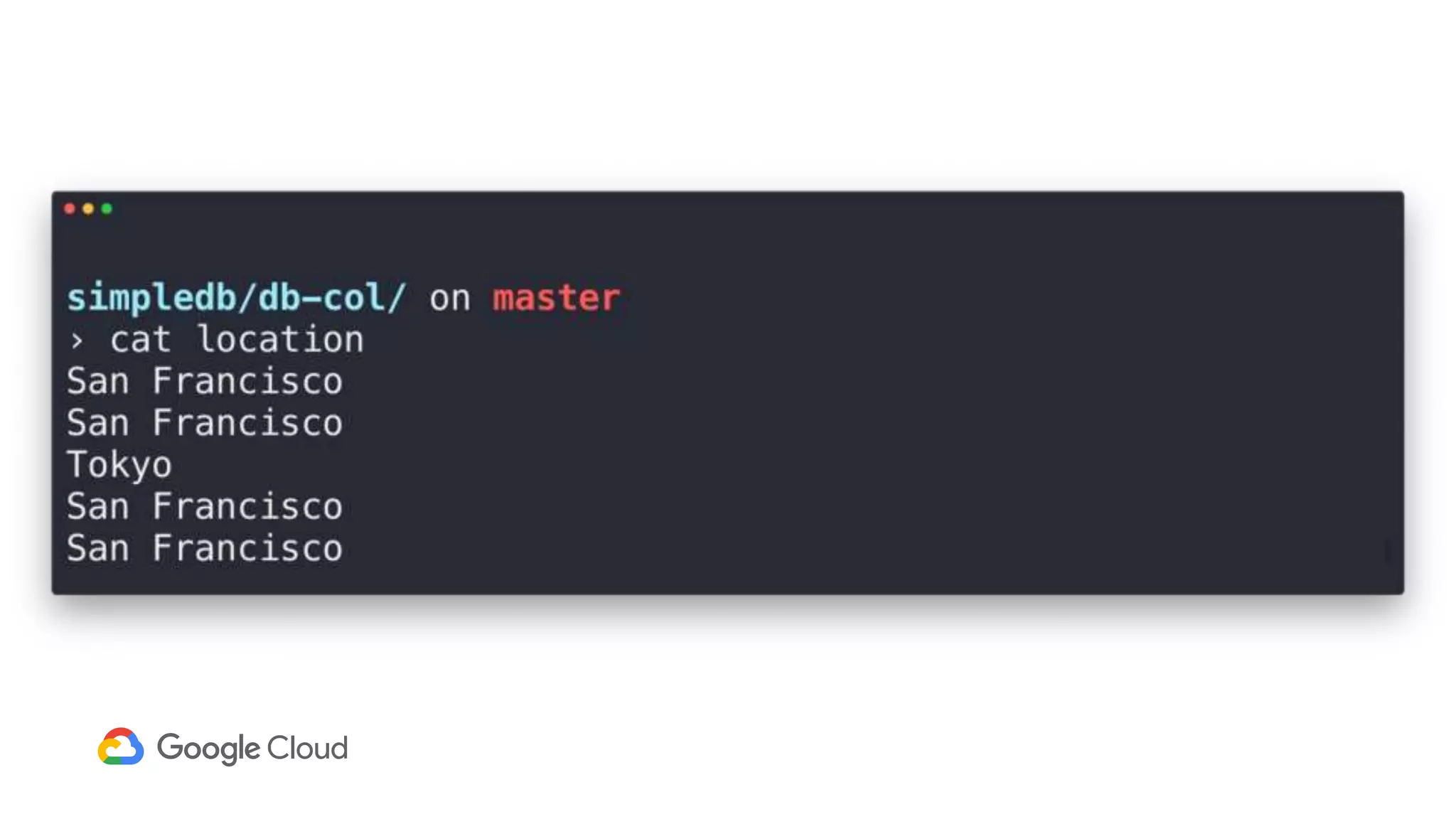
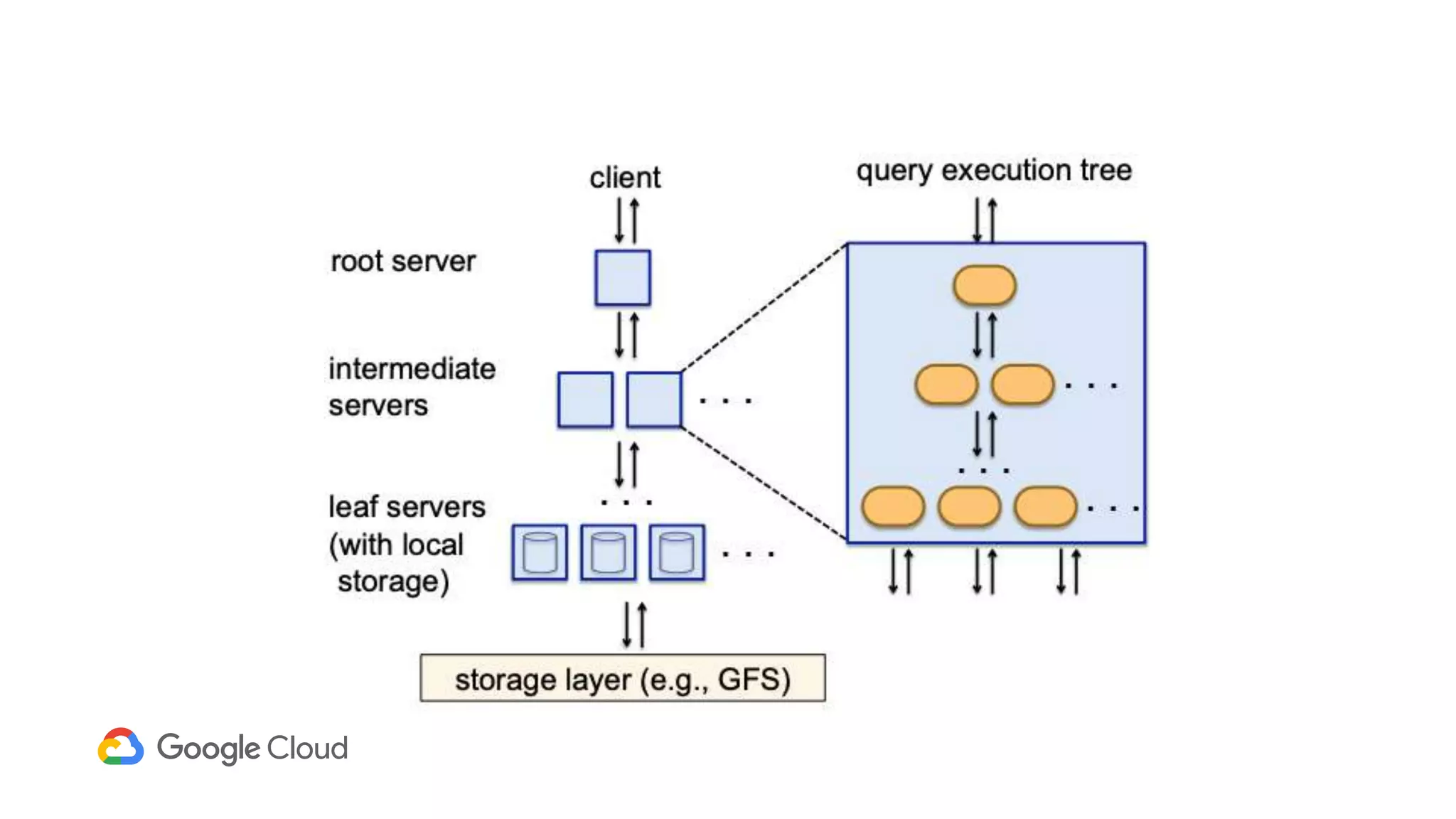
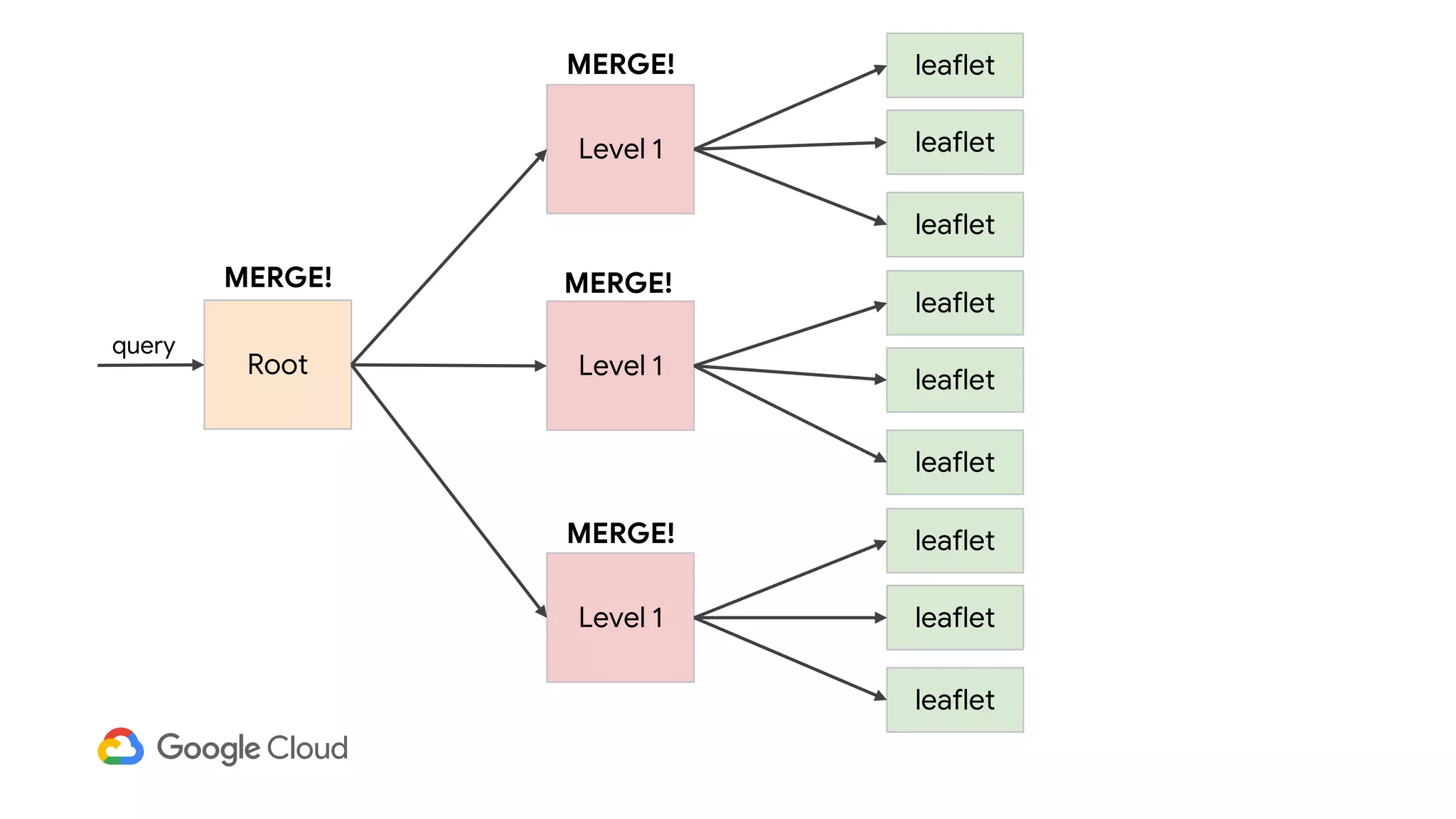
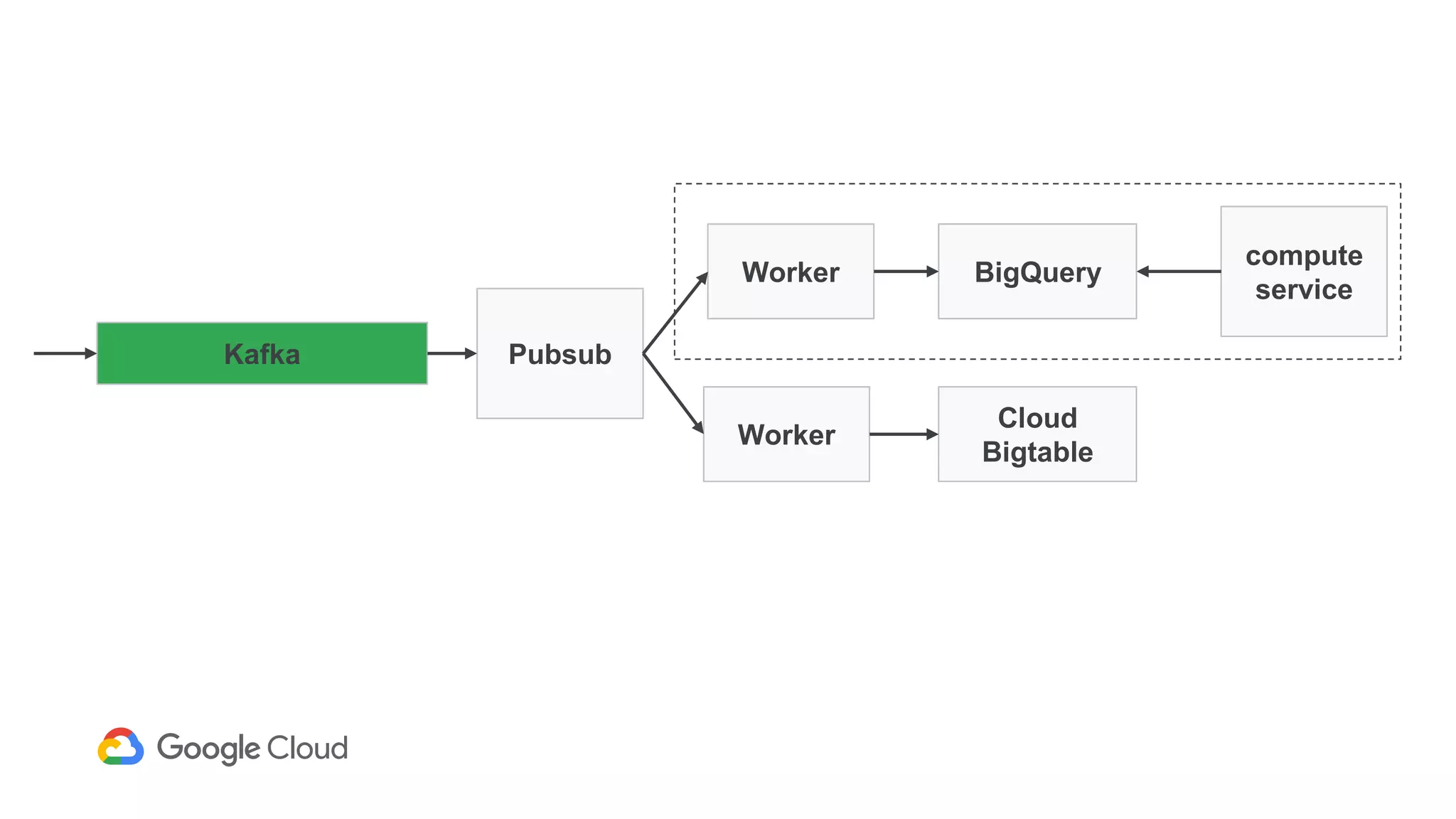
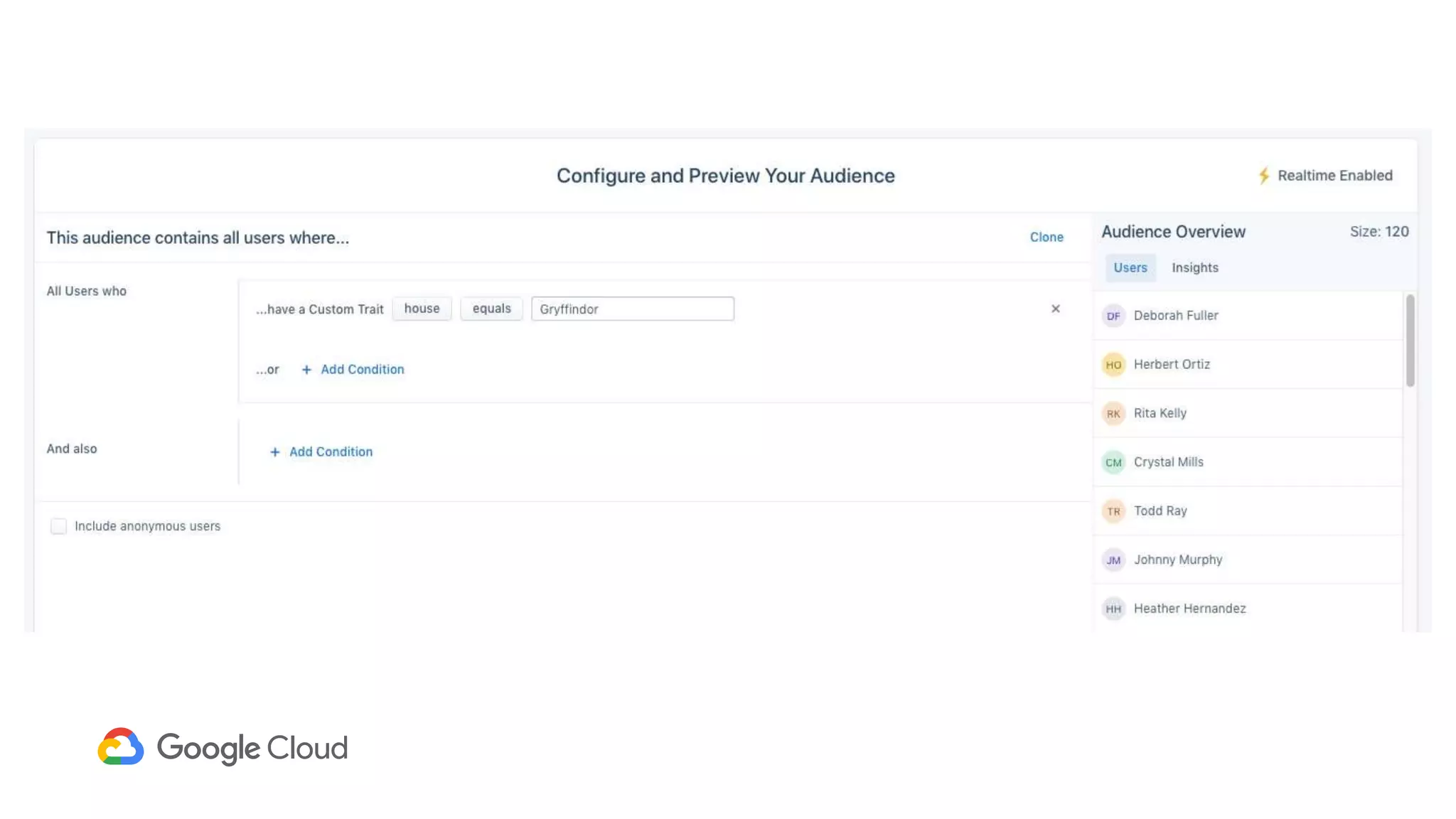
1) Segment uses Cloud Bigtable and BigQuery together to power their Personas product, which handles personalized user profiles and audiences at scale. Cloud Bigtable handles small, random reads for real-time queries of user profiles, while BigQuery handles batch computations over terabytes of data.
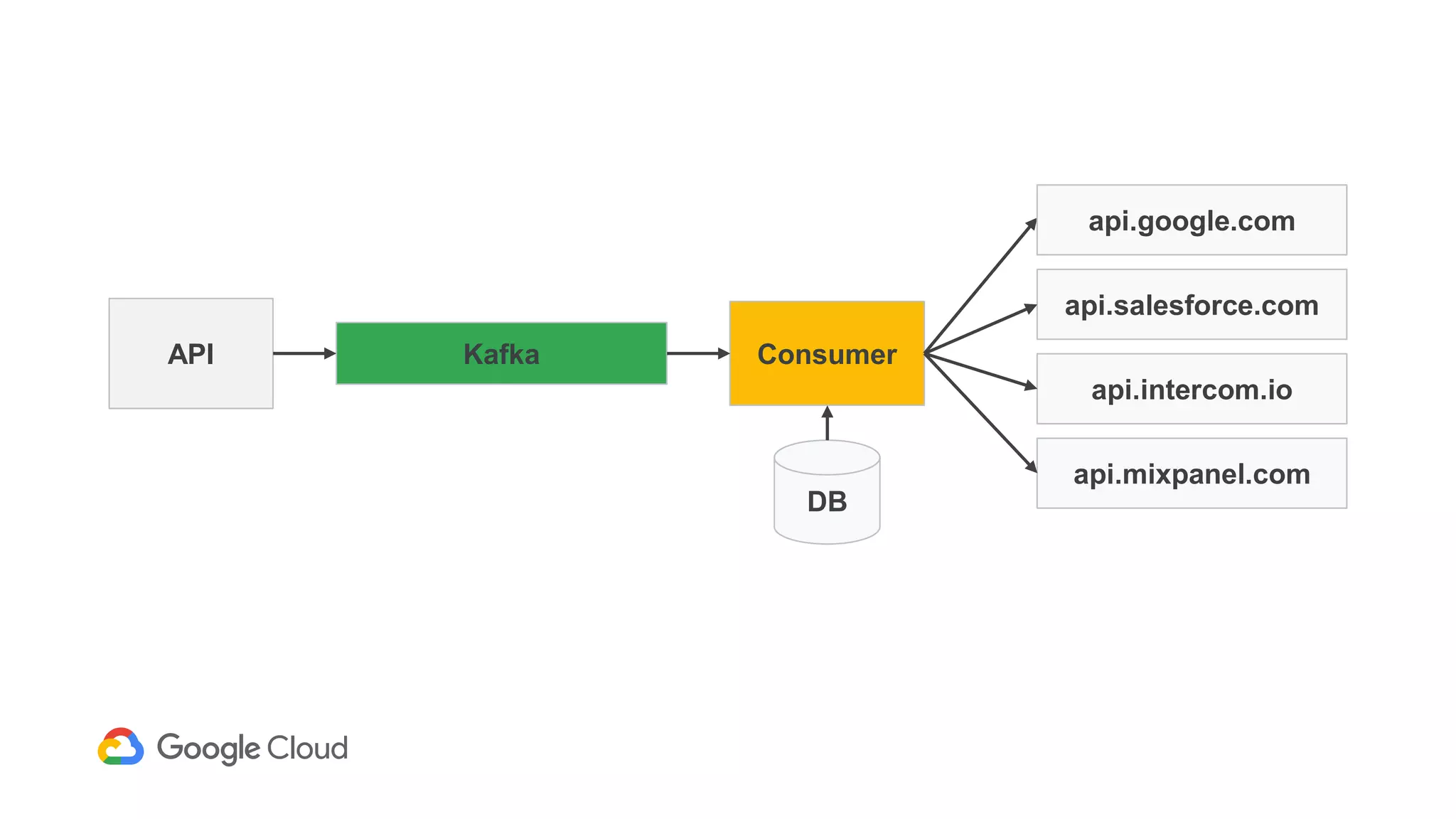
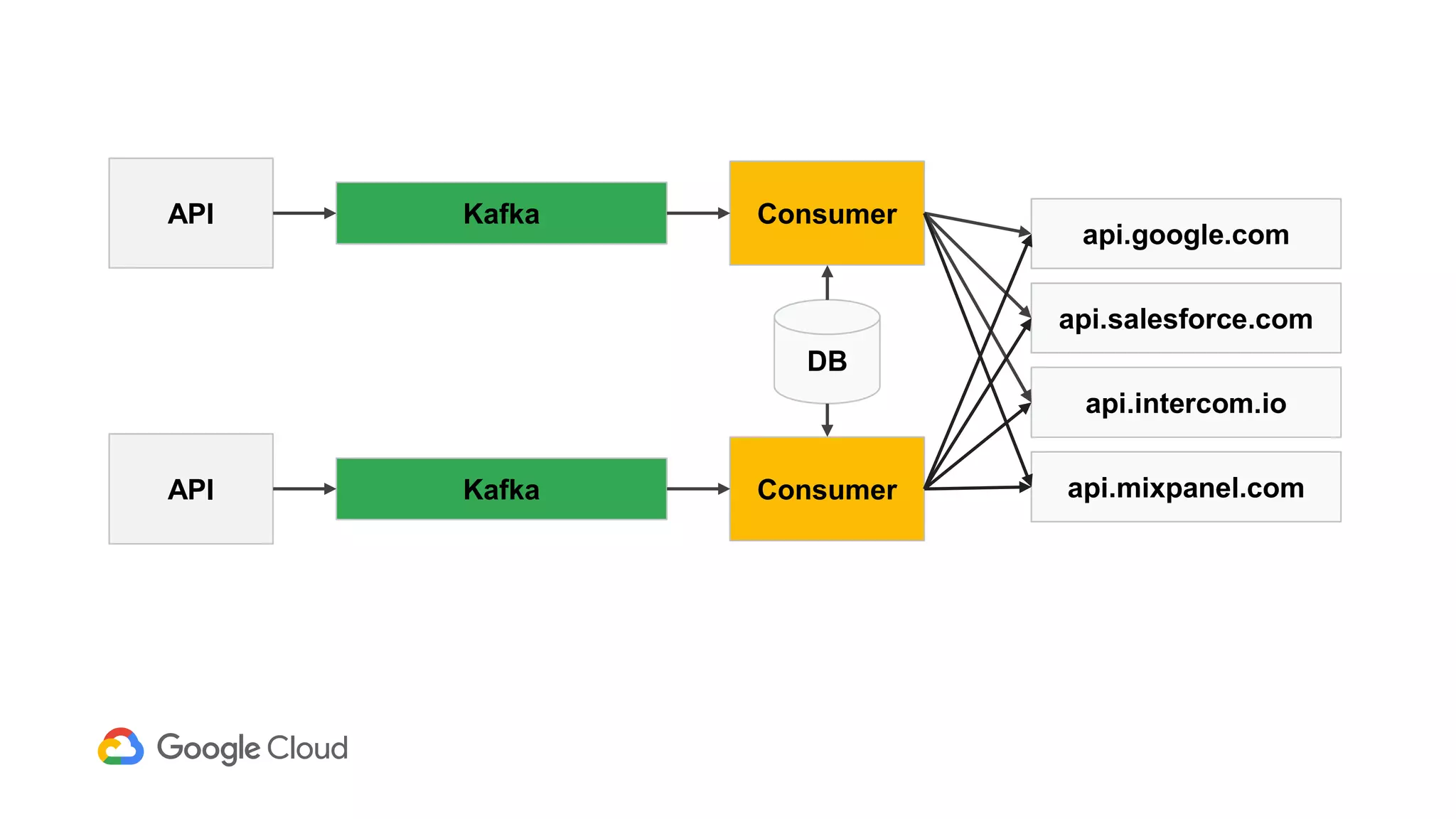
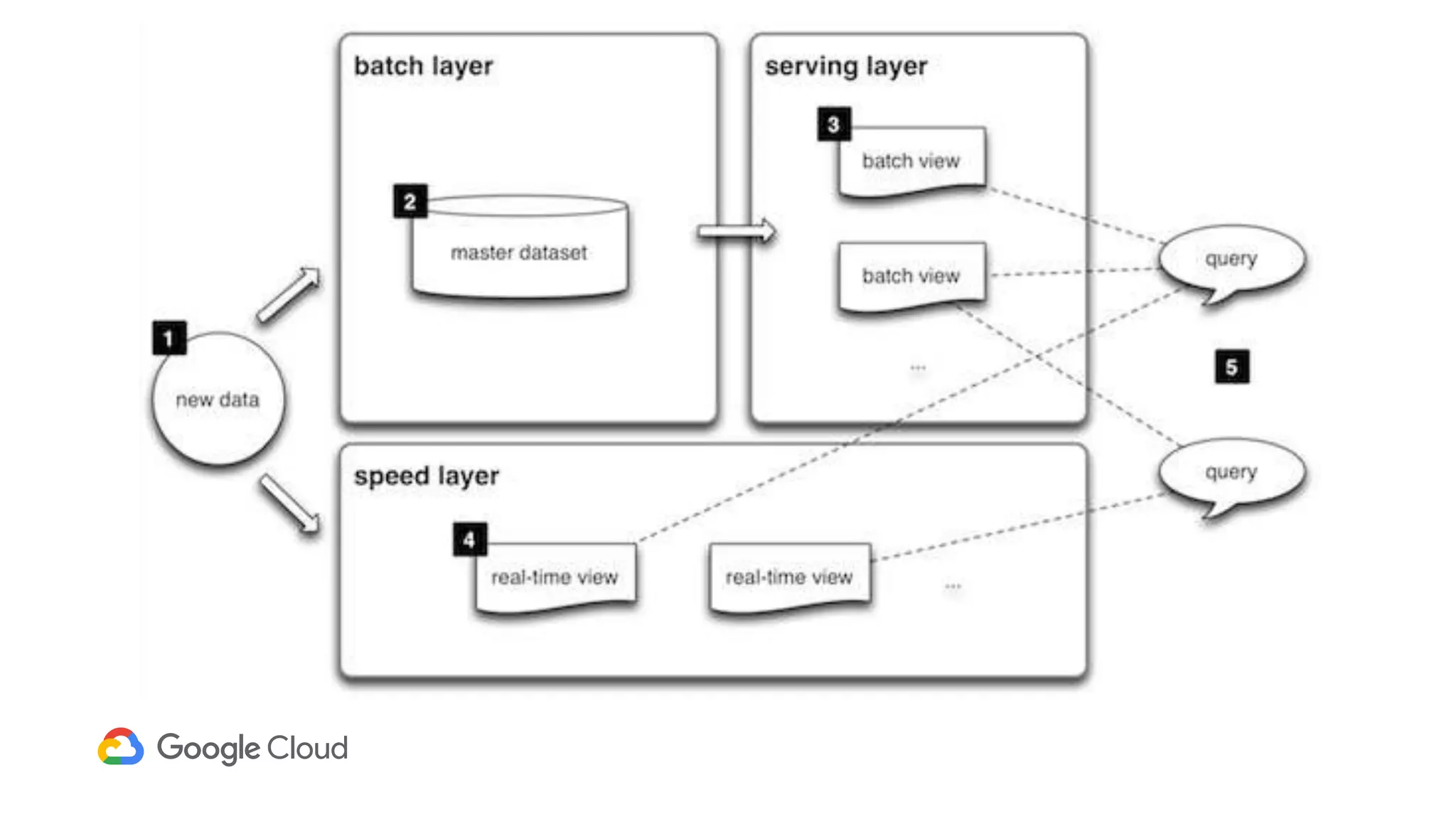
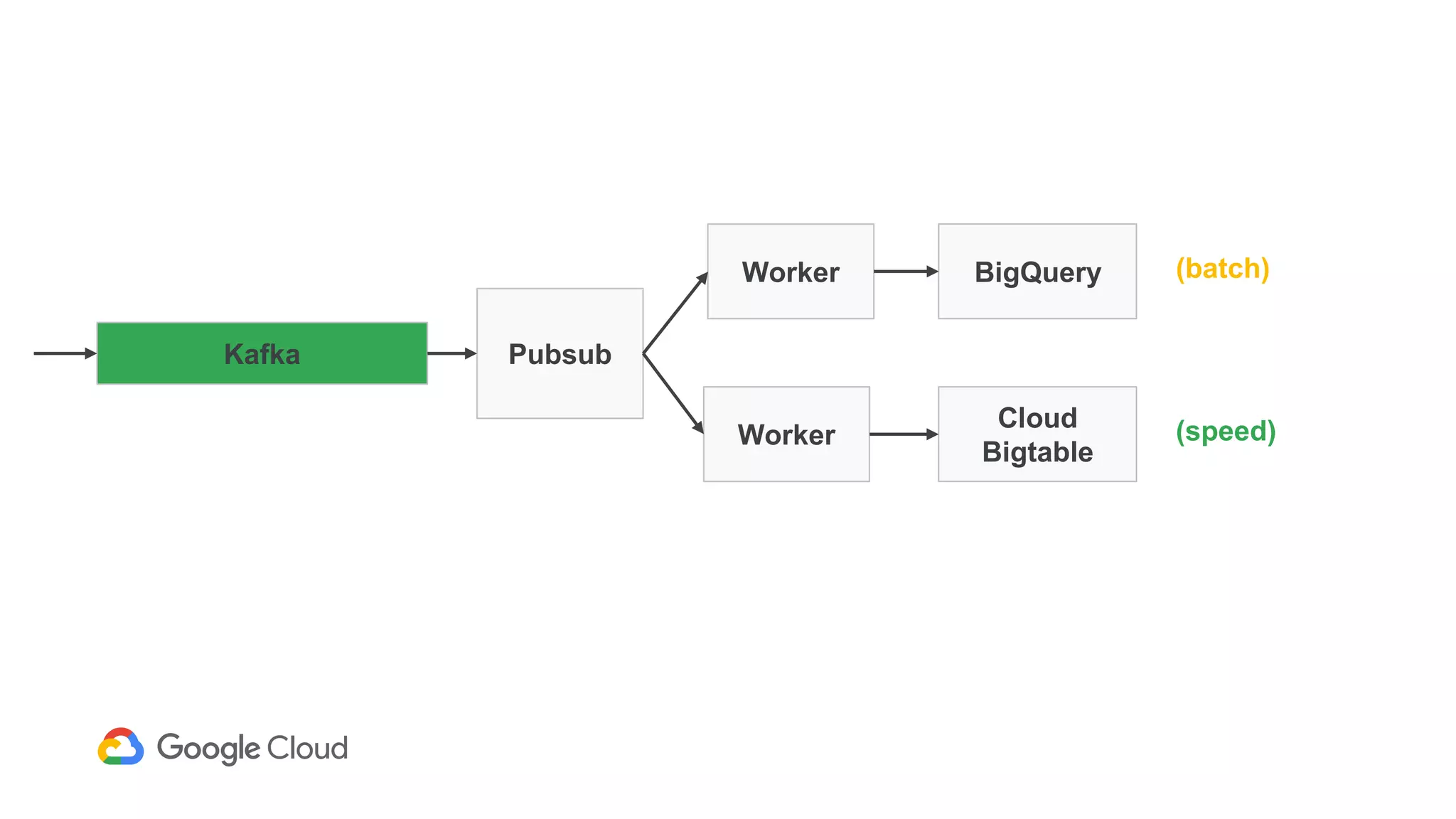
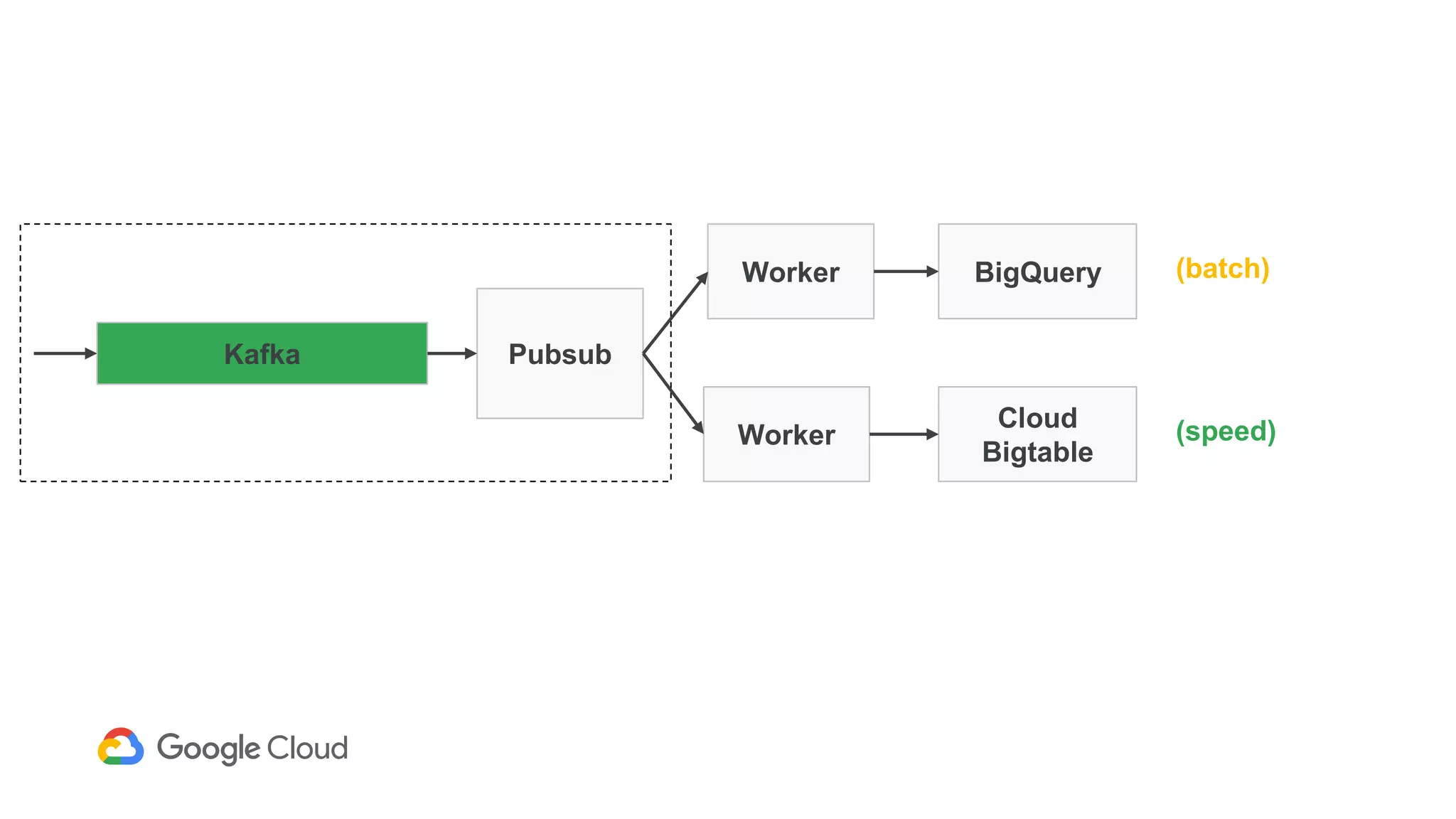
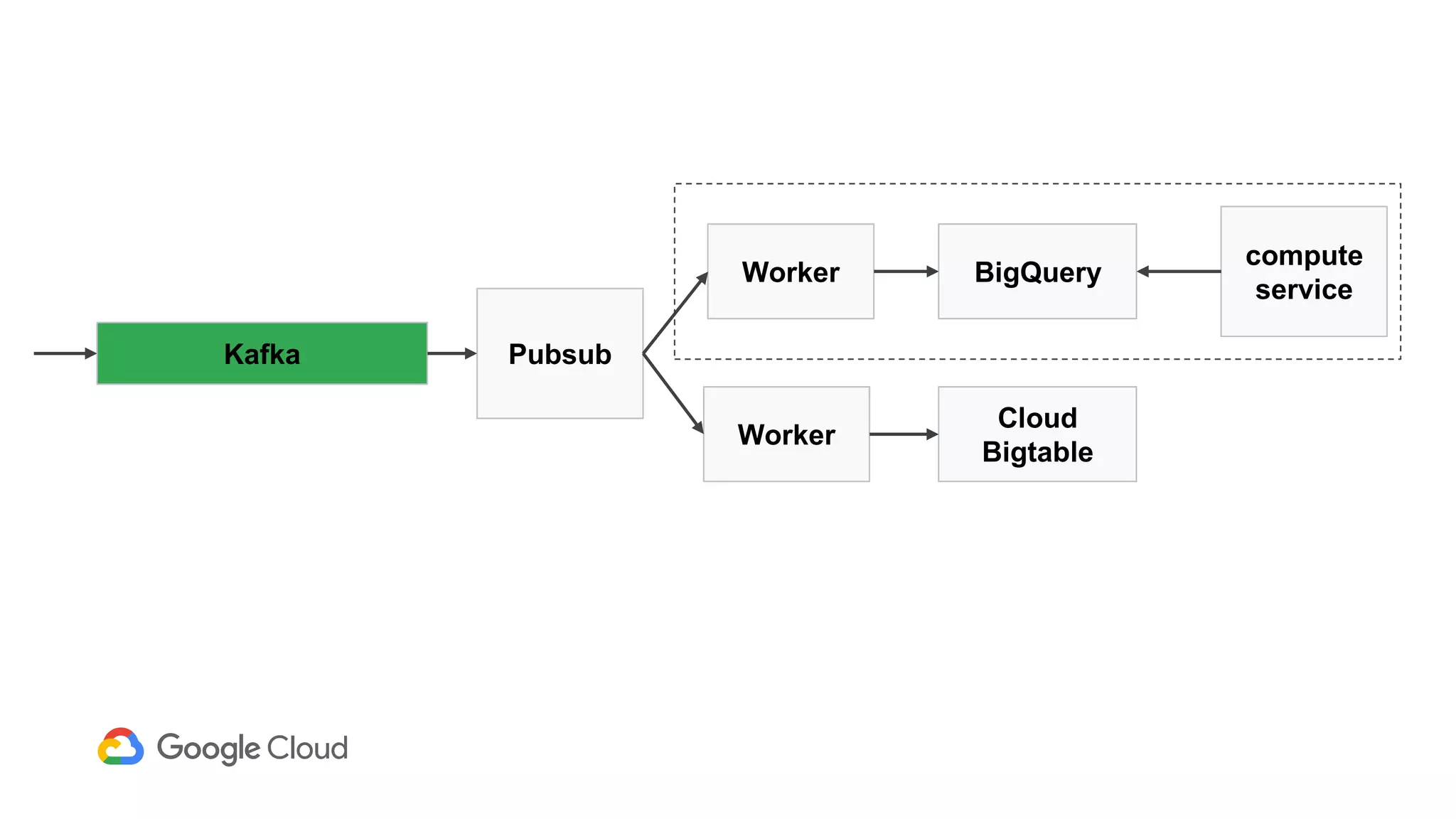
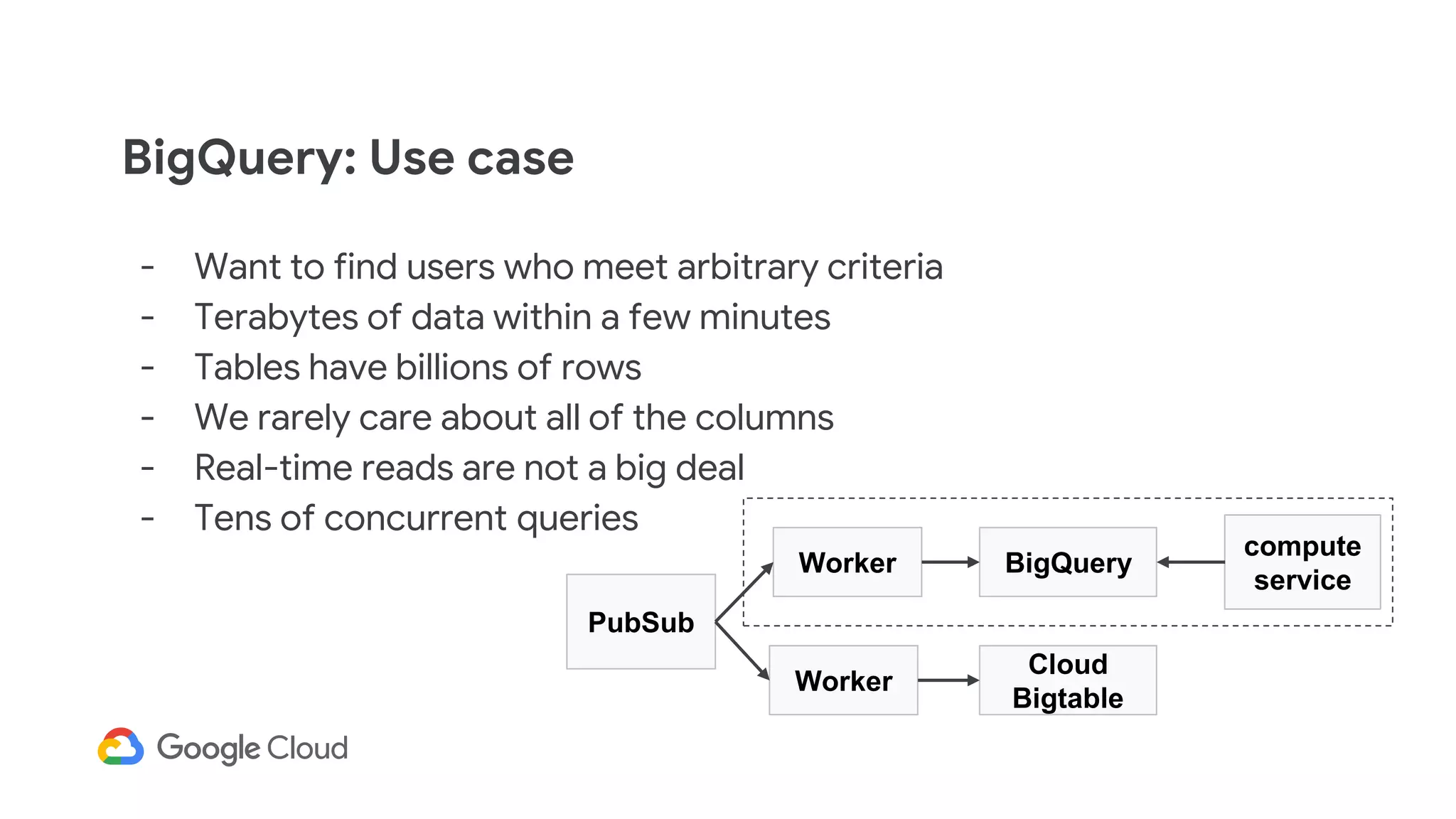
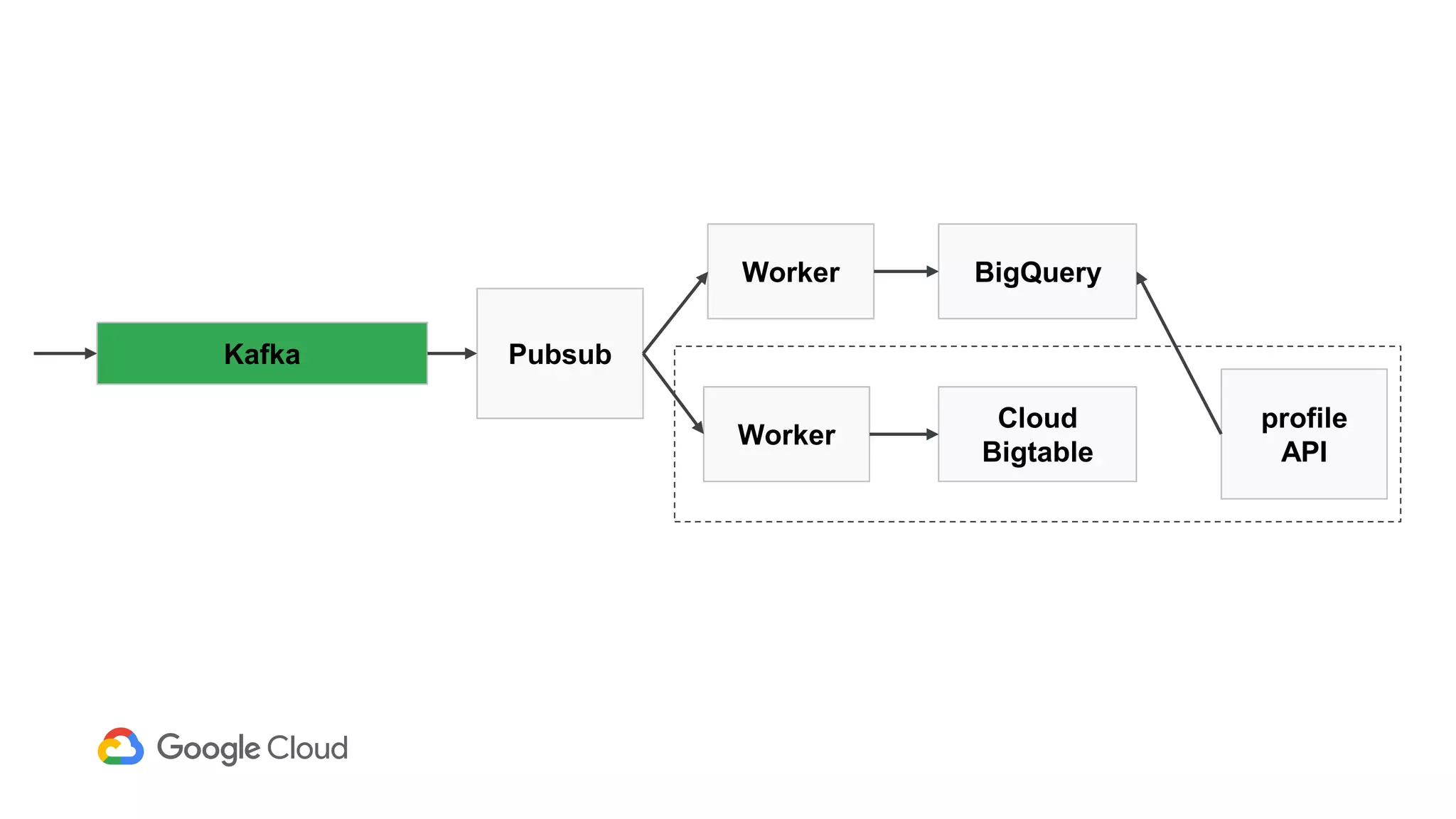
2) The Personas architecture uses a lambda architecture with Cloud Bigtable handling the speed layer for real-time queries and BigQuery handling batch computations. Data is ingested from Kafka into both systems.
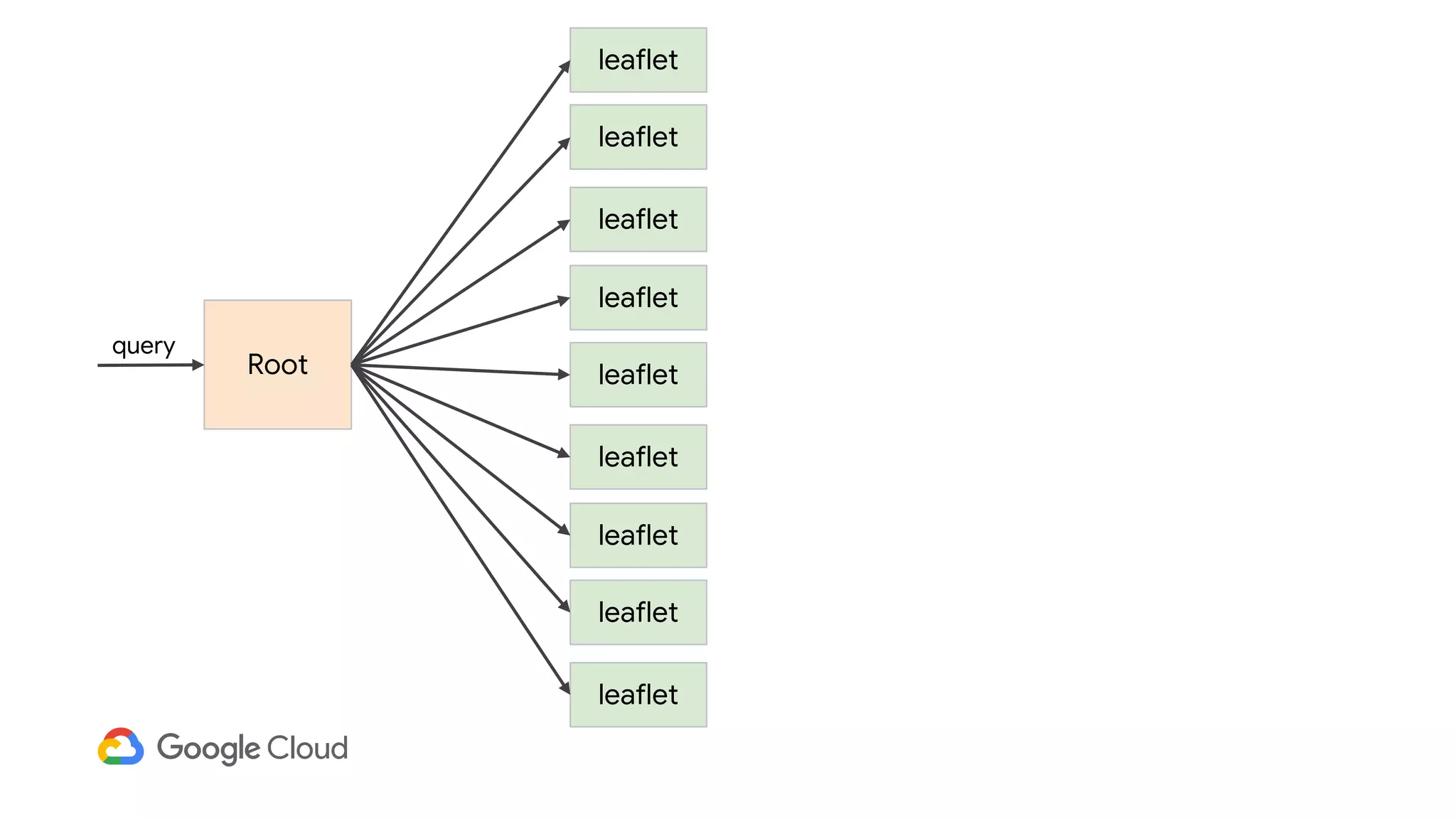
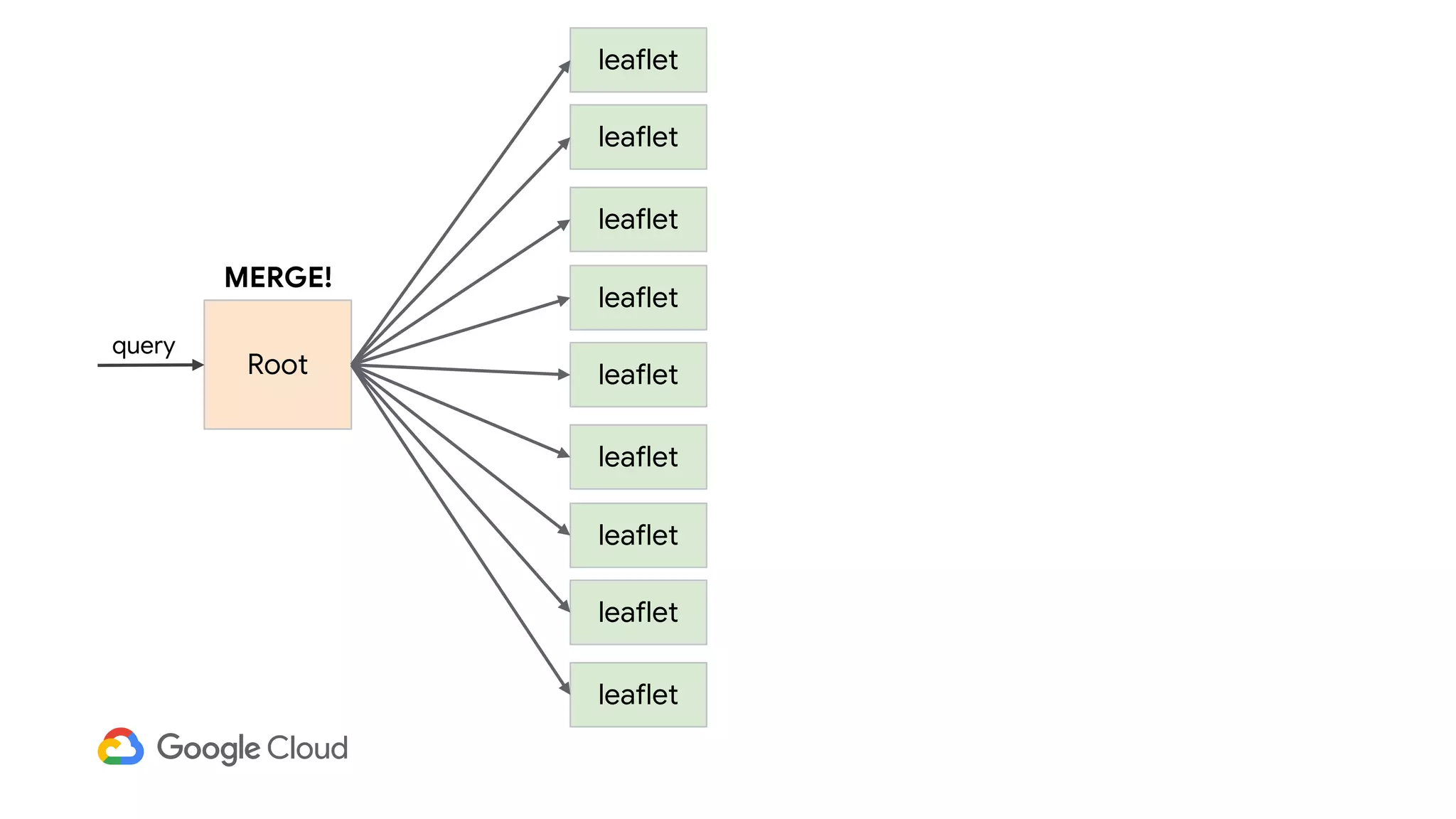
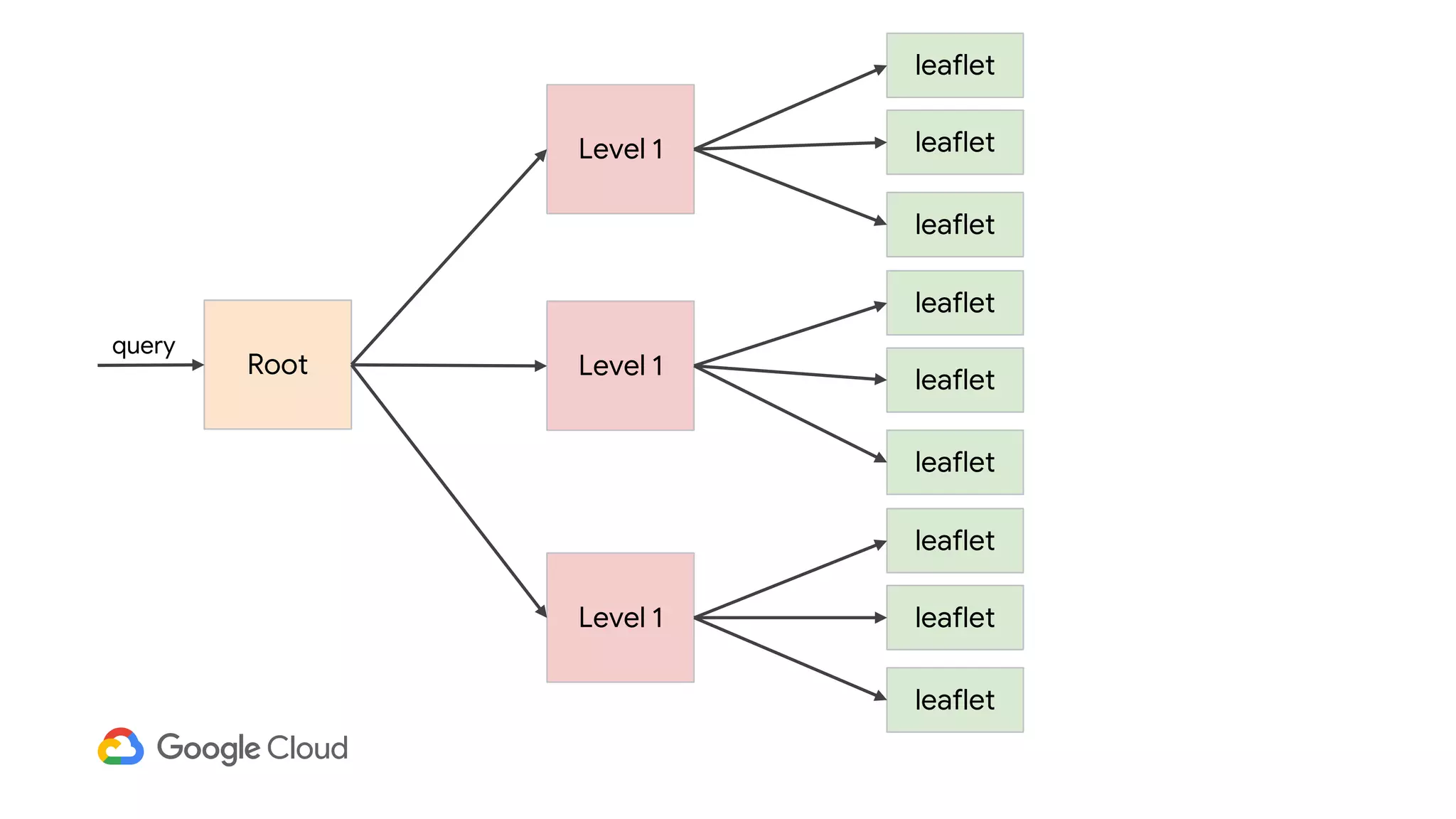
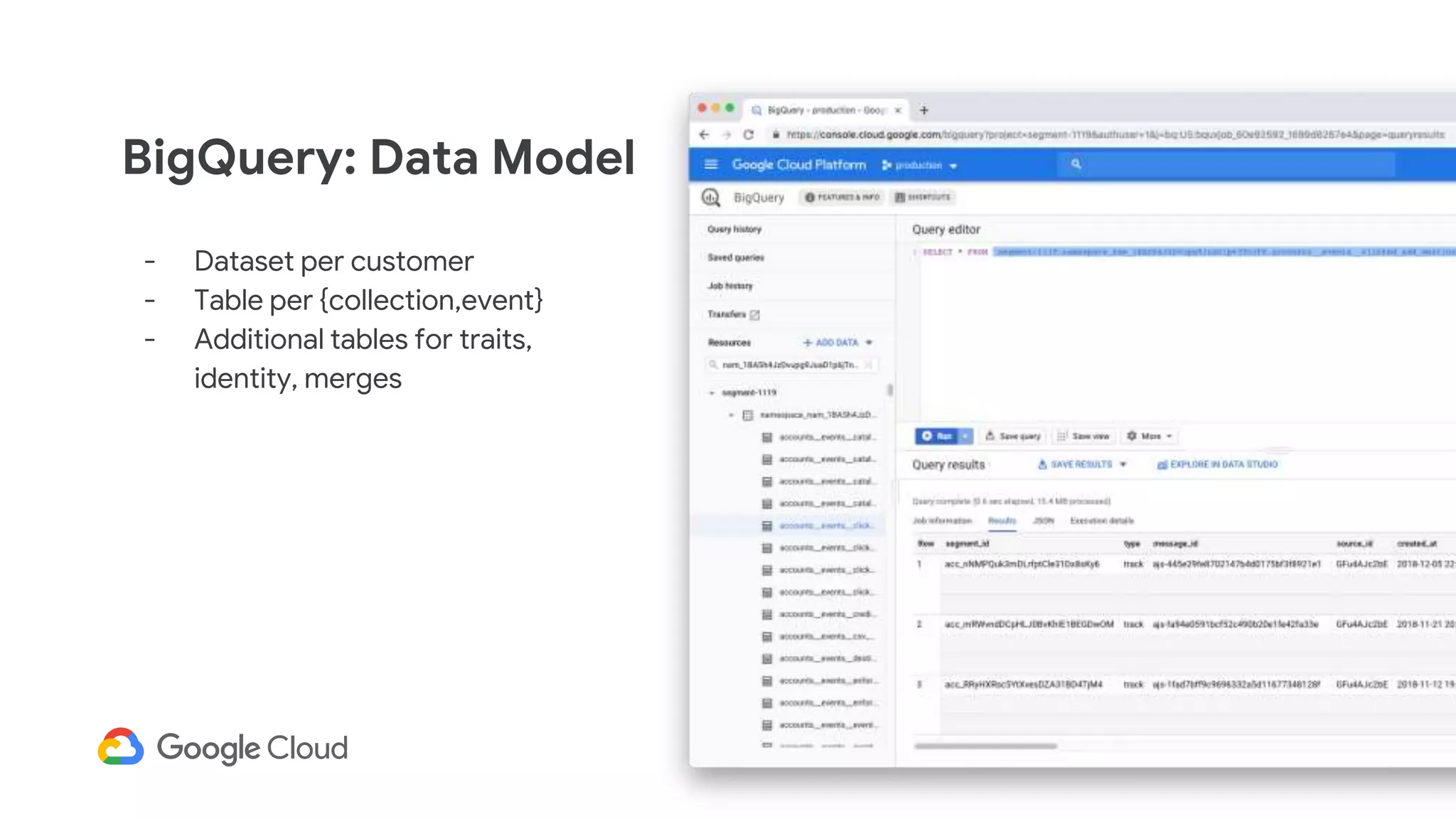
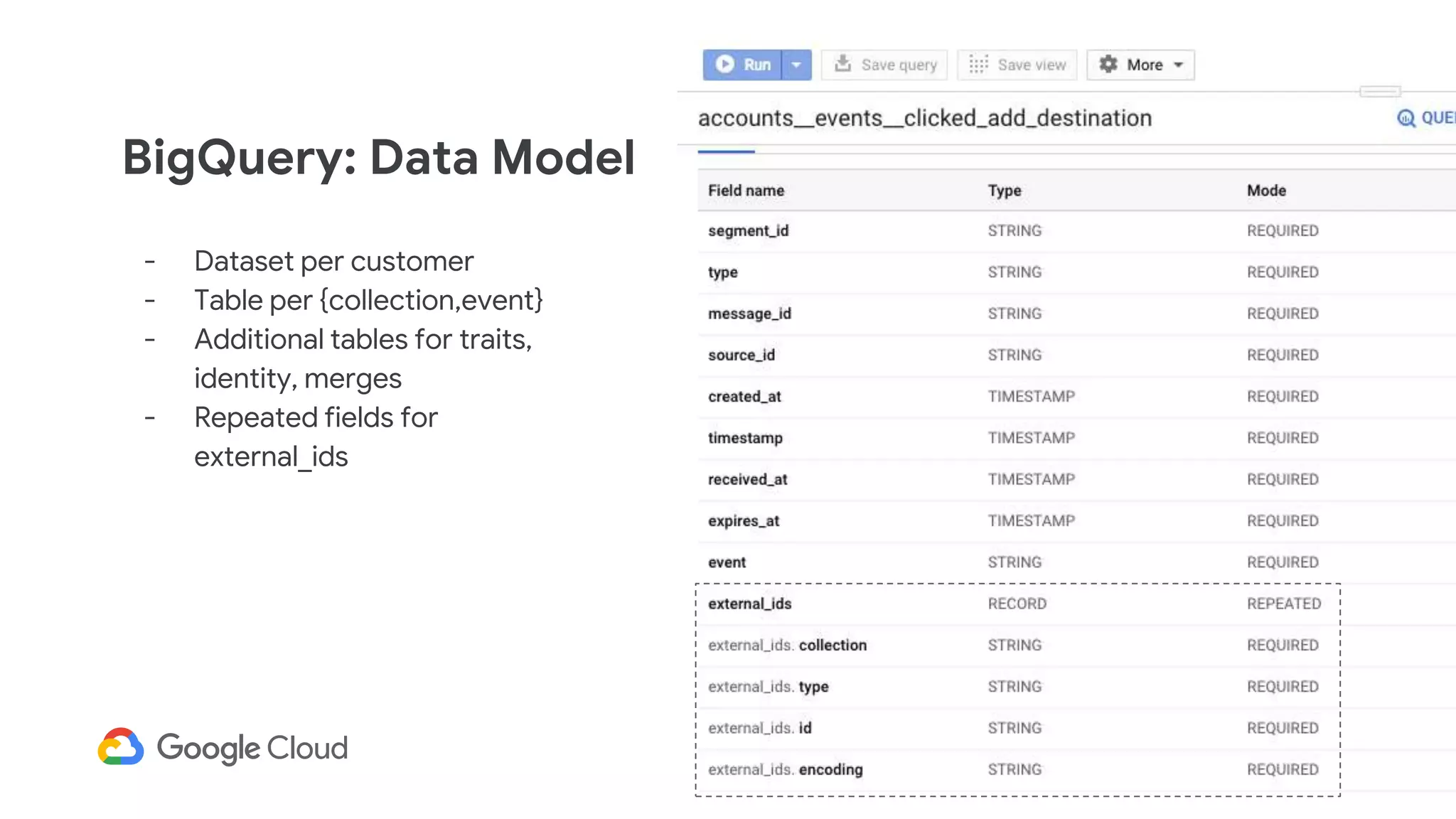
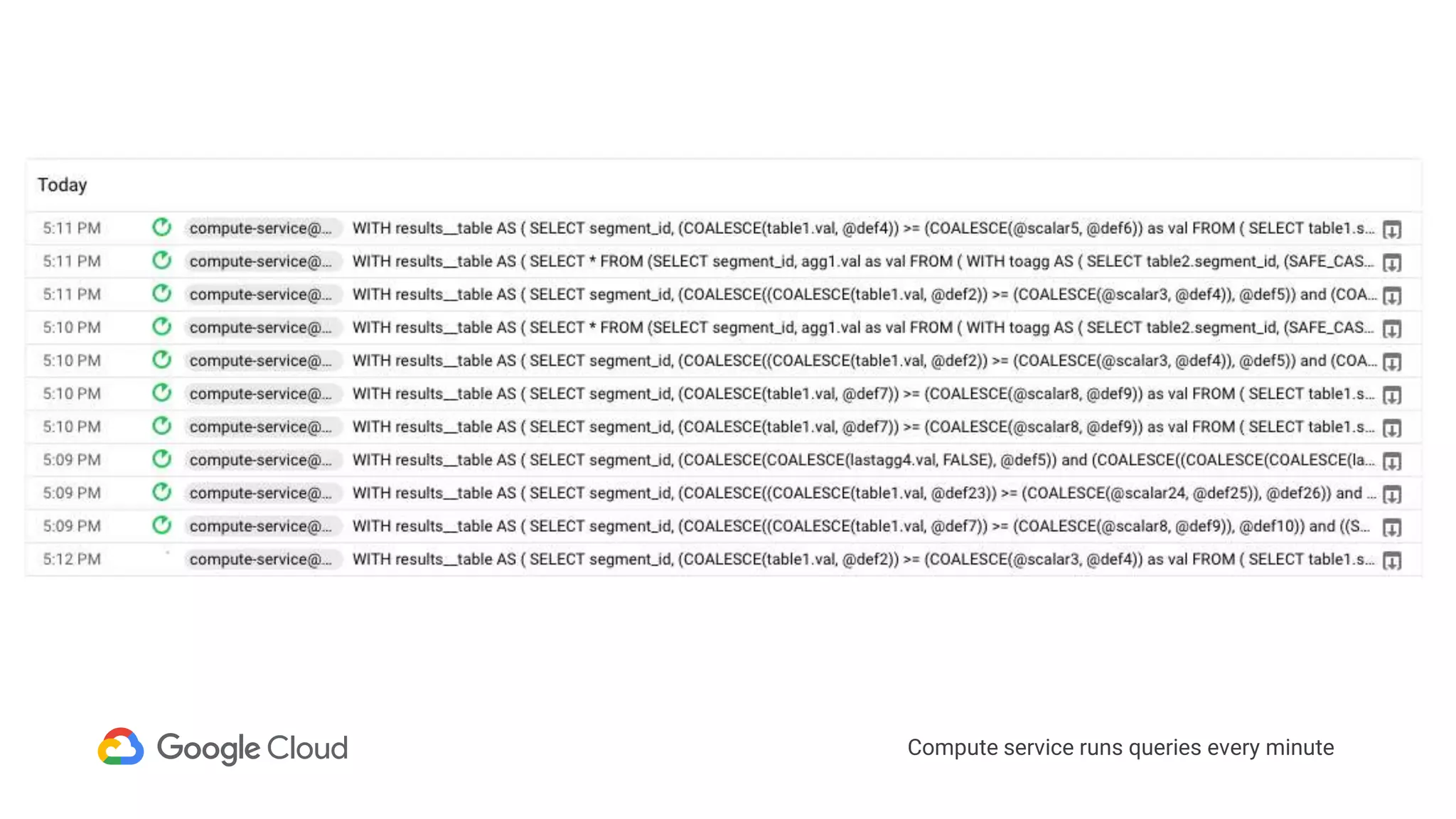
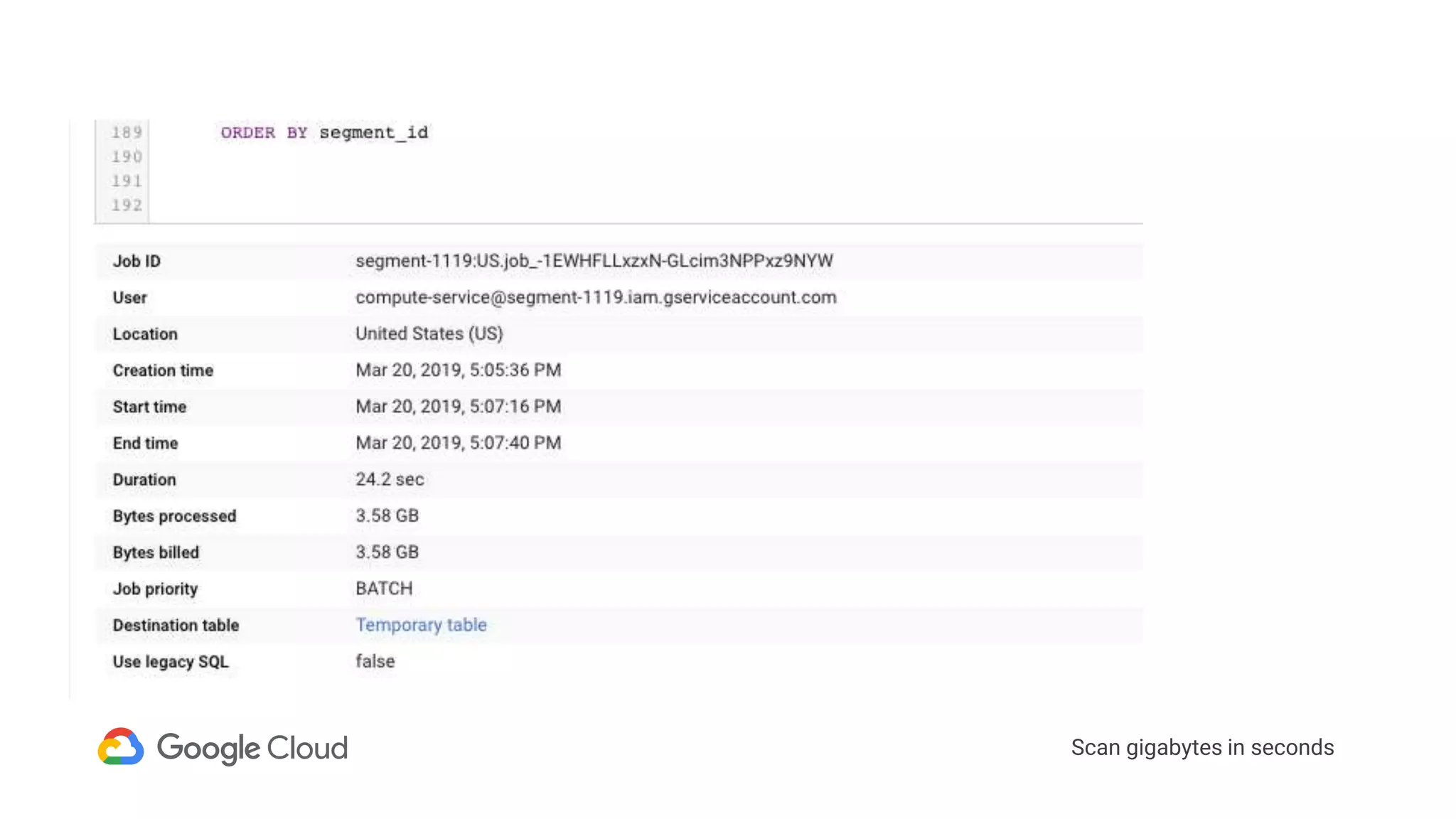
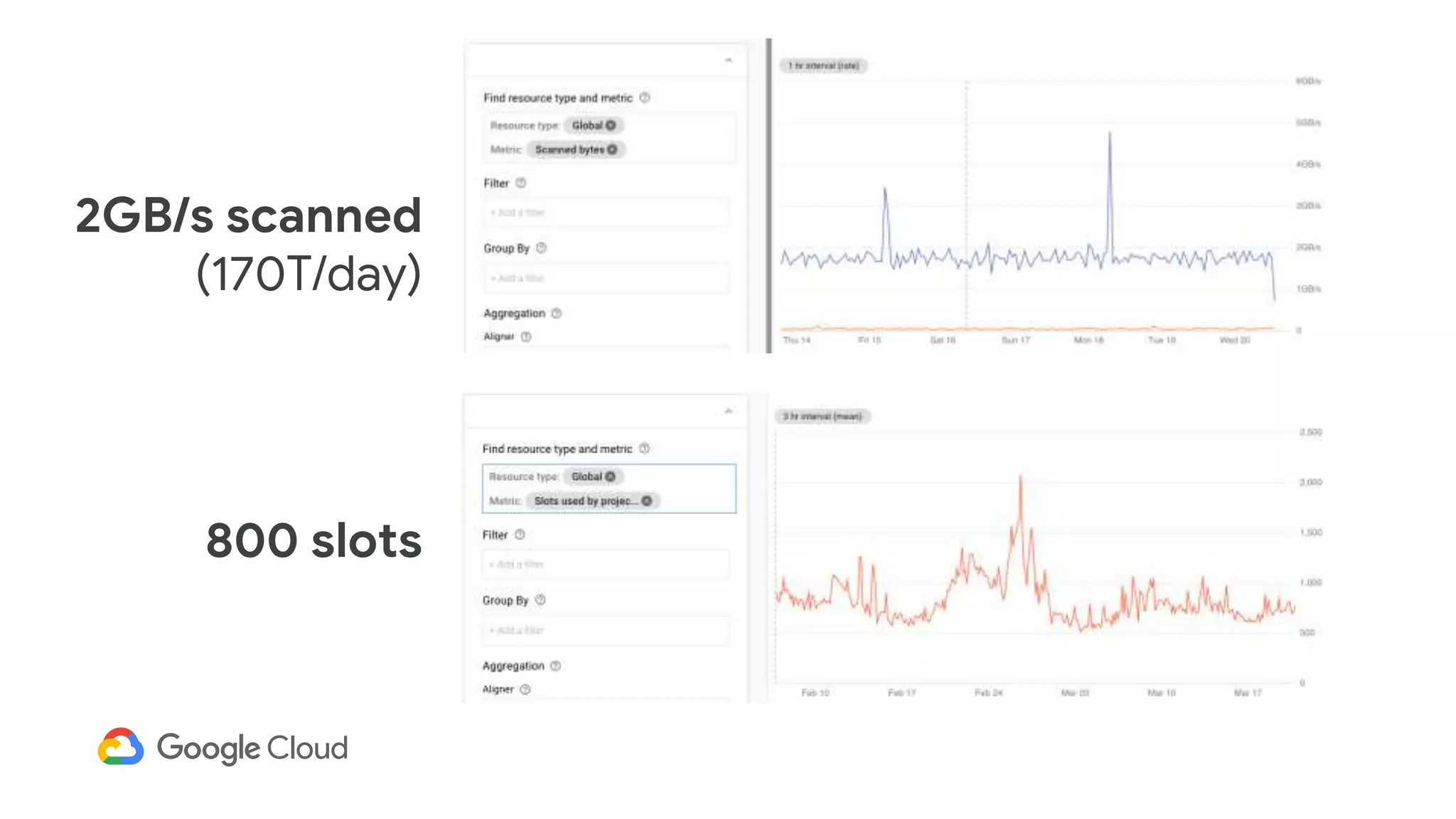
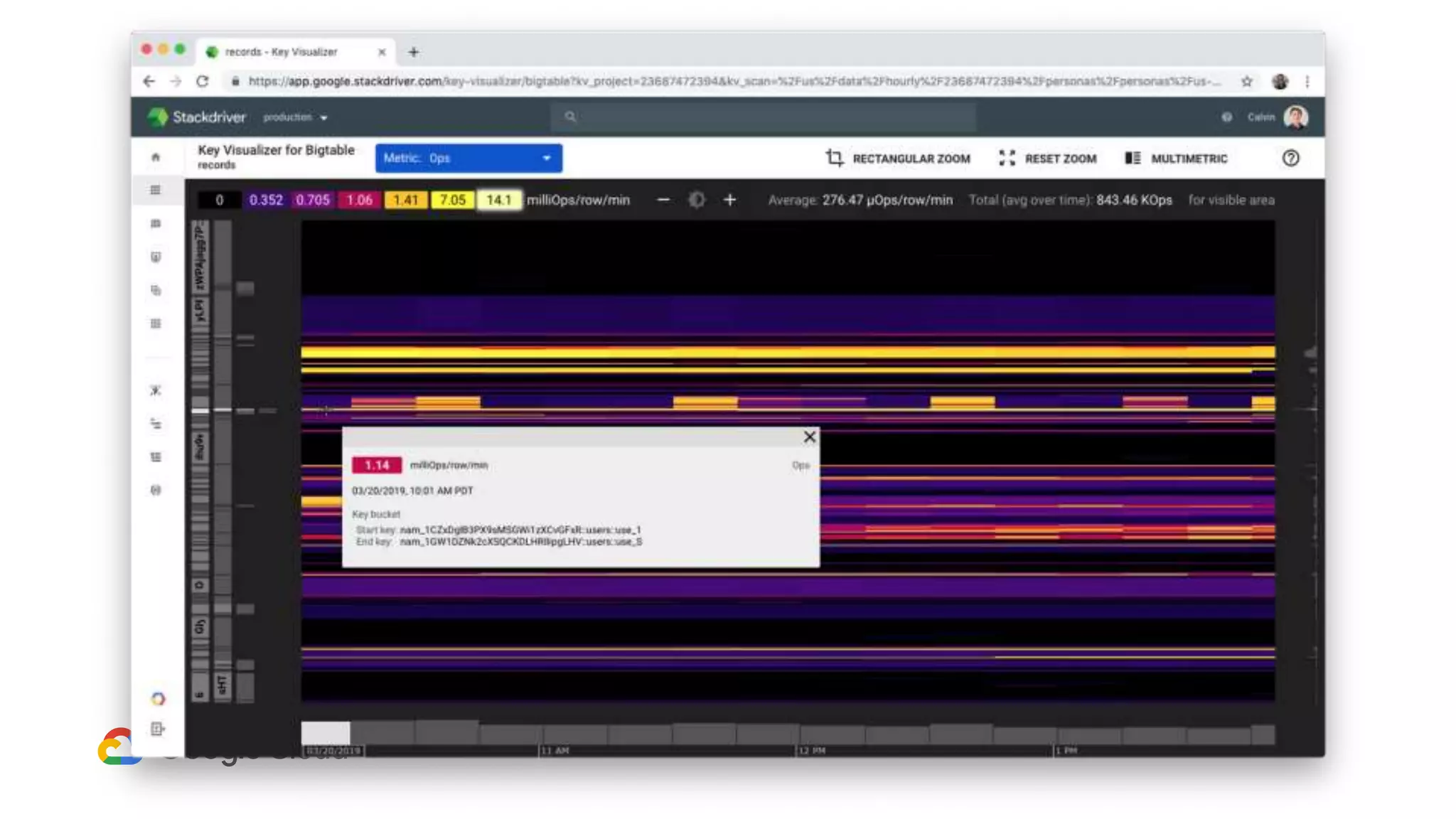
3) In production, Cloud Bigtable handles over 55,000 writes and 175,000 reads per second across 10TB of data distributed across 16 nodes. BigQuery handles hundreds of queries per minute scanning hundreds of gigabytes of data from its 500




























































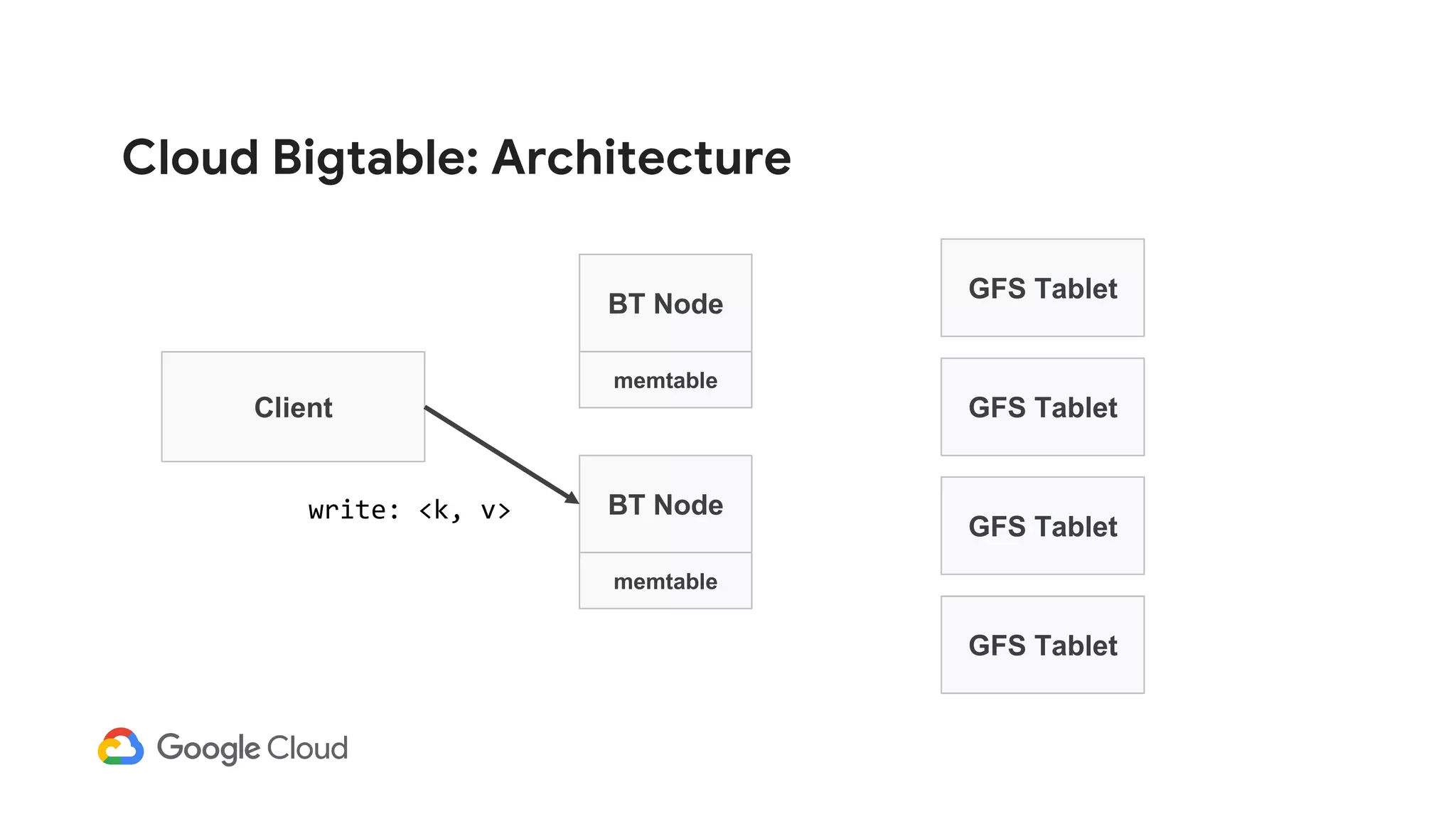
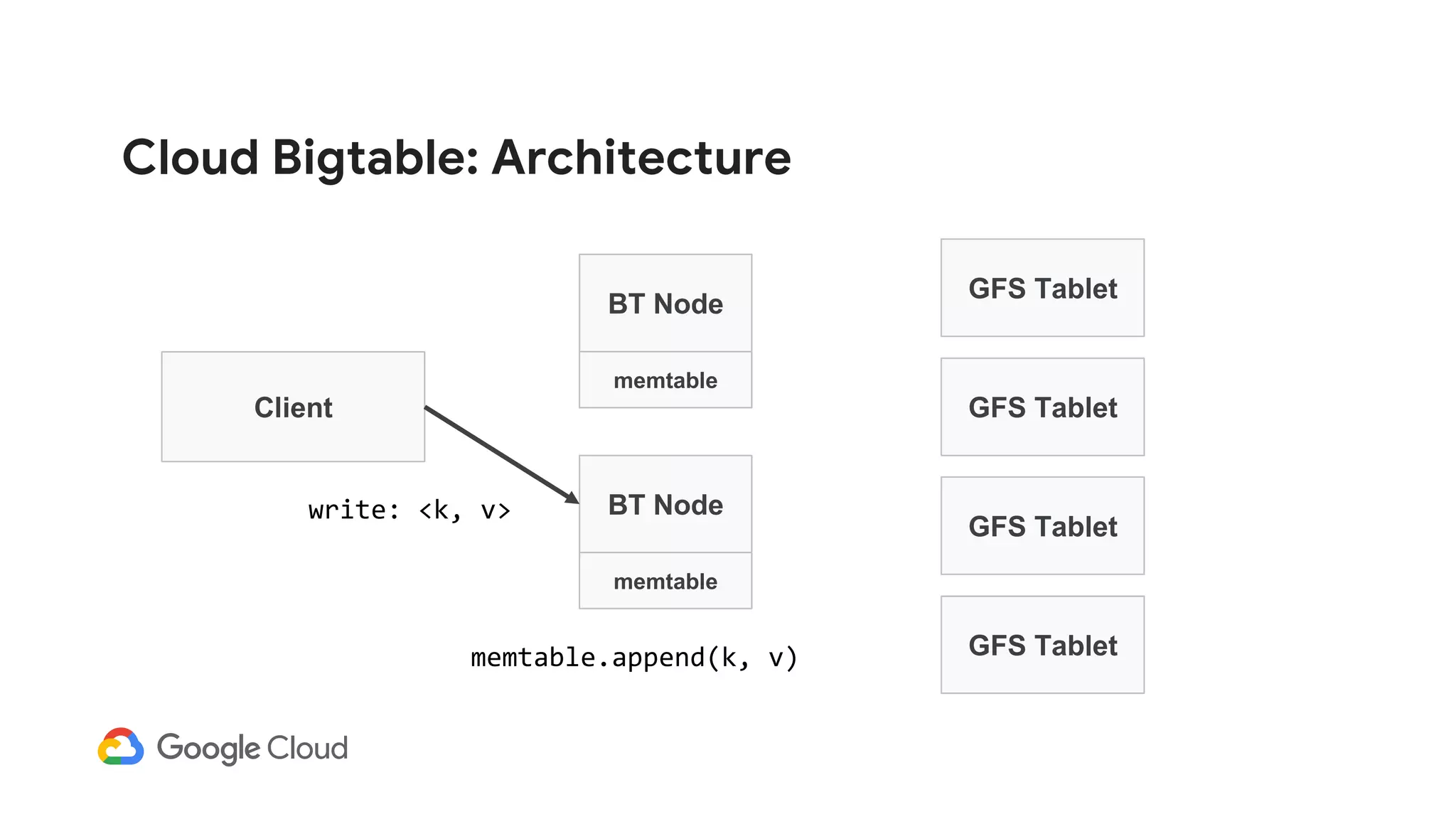
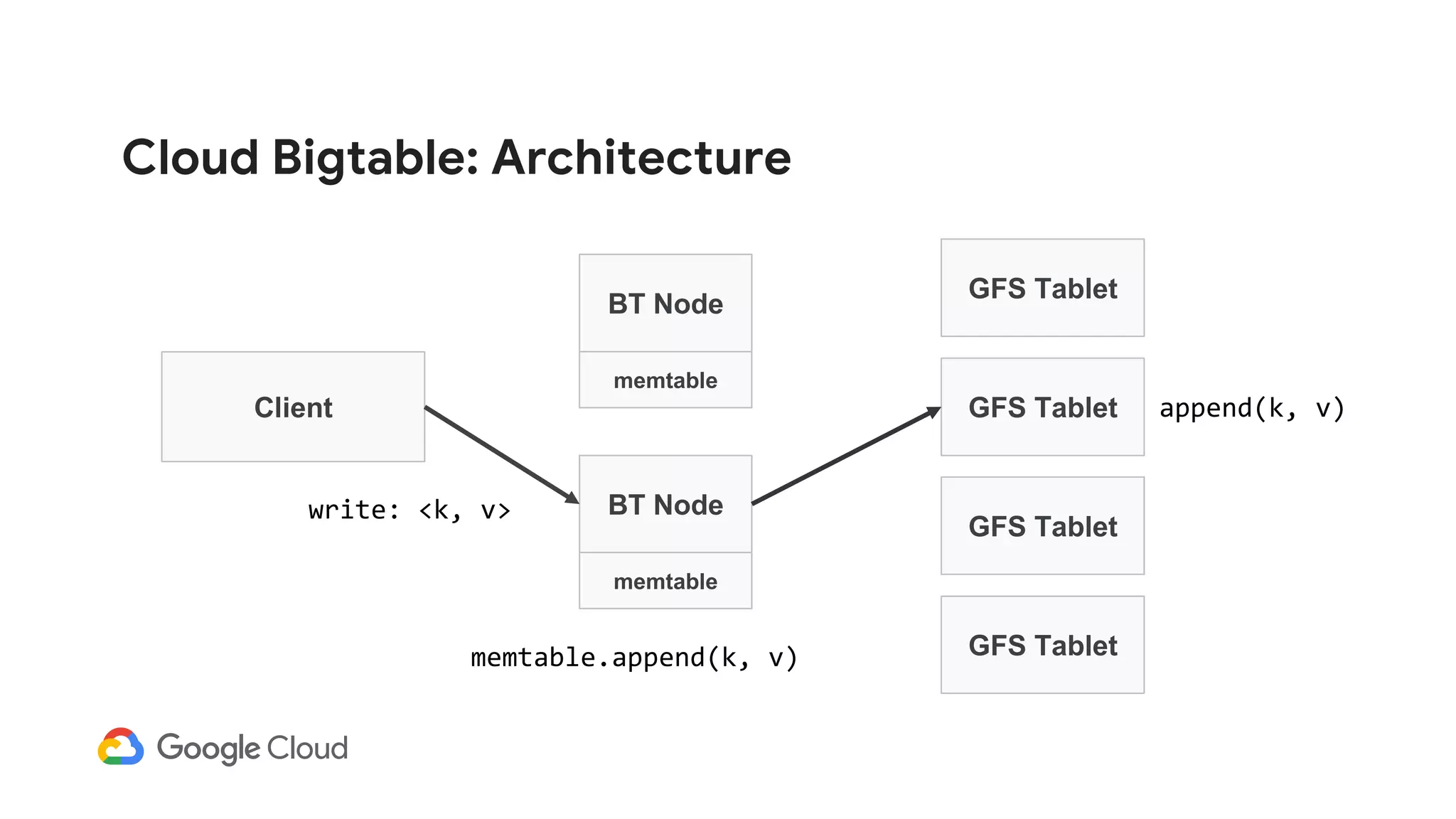

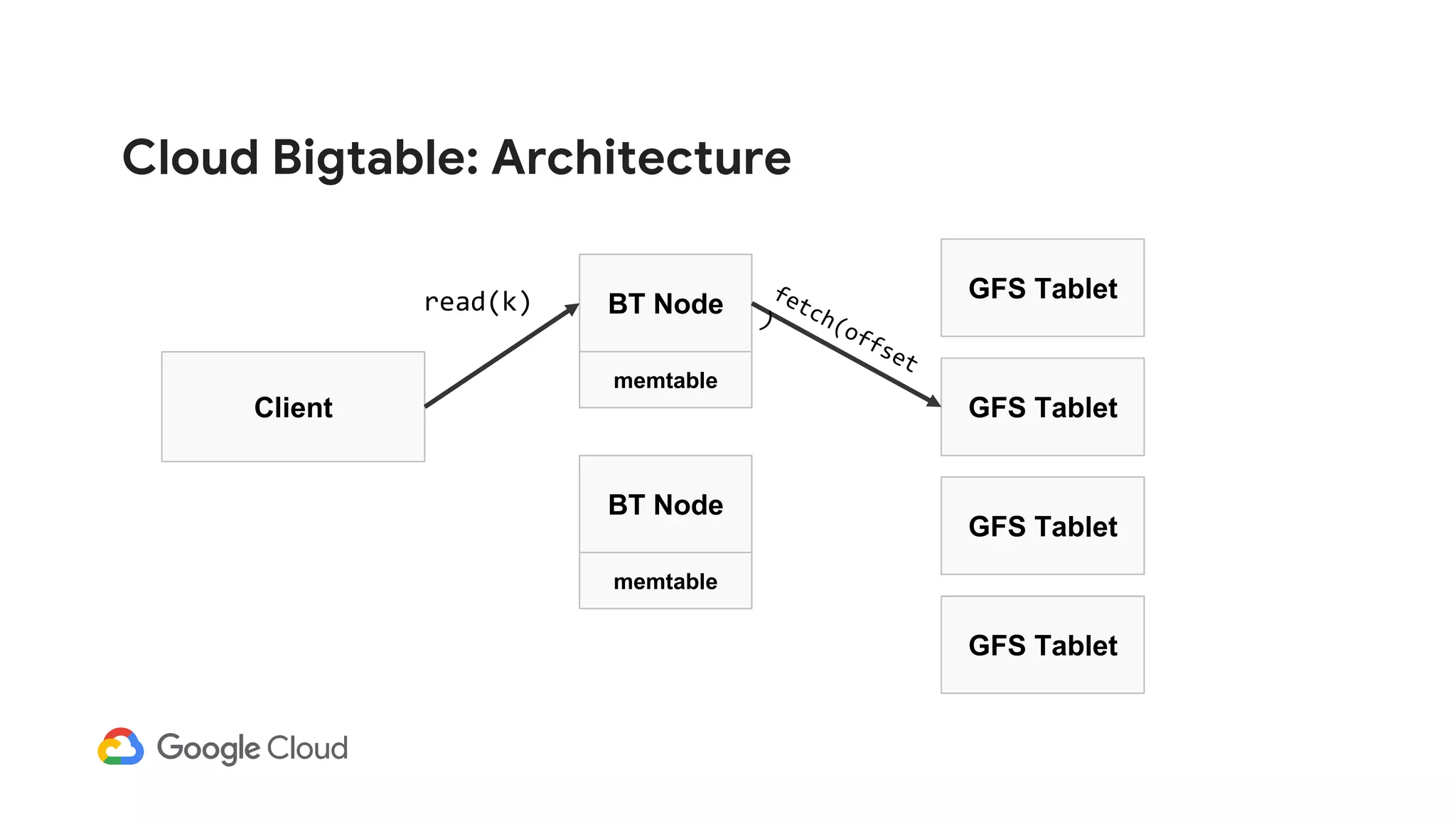
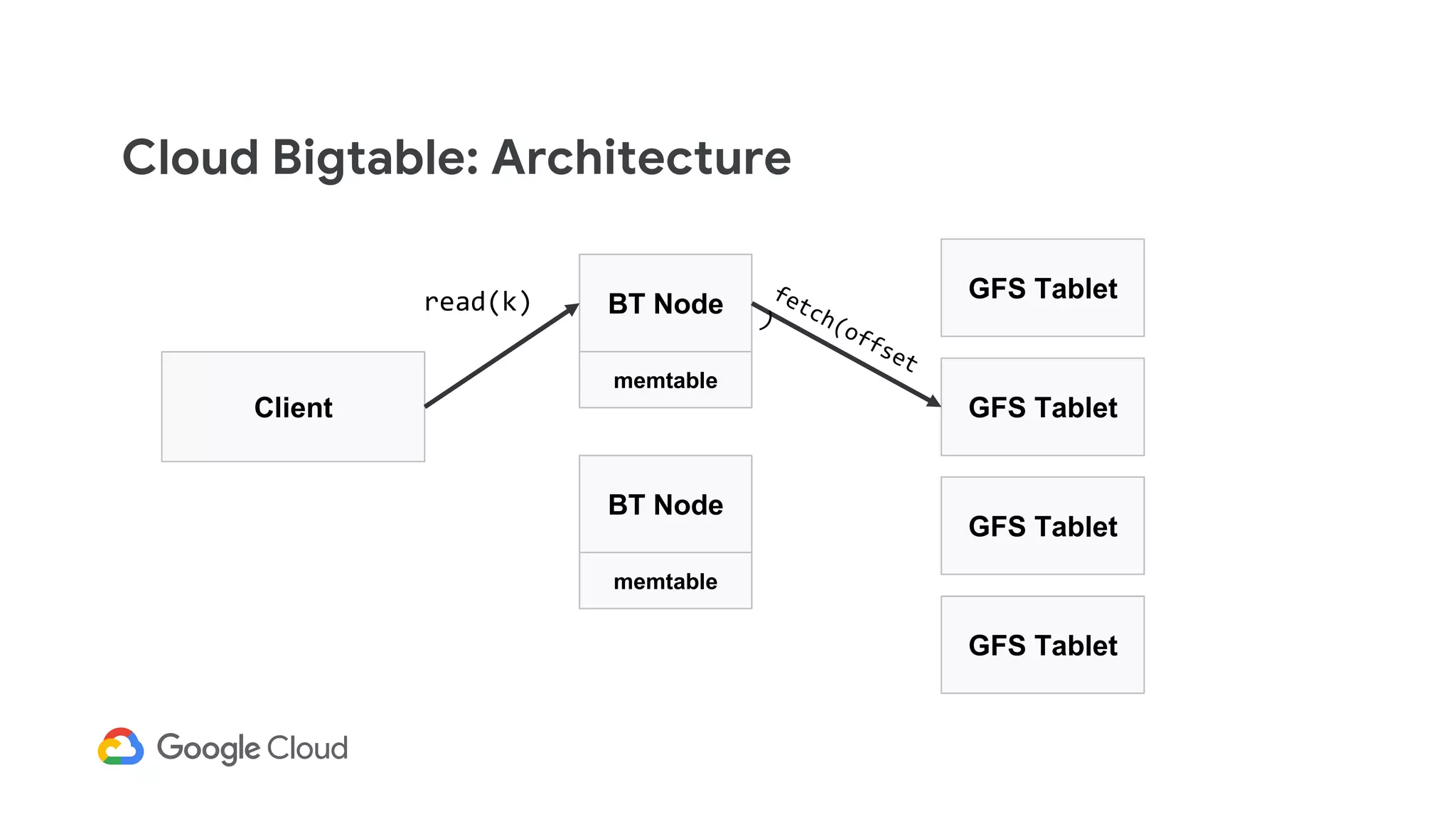
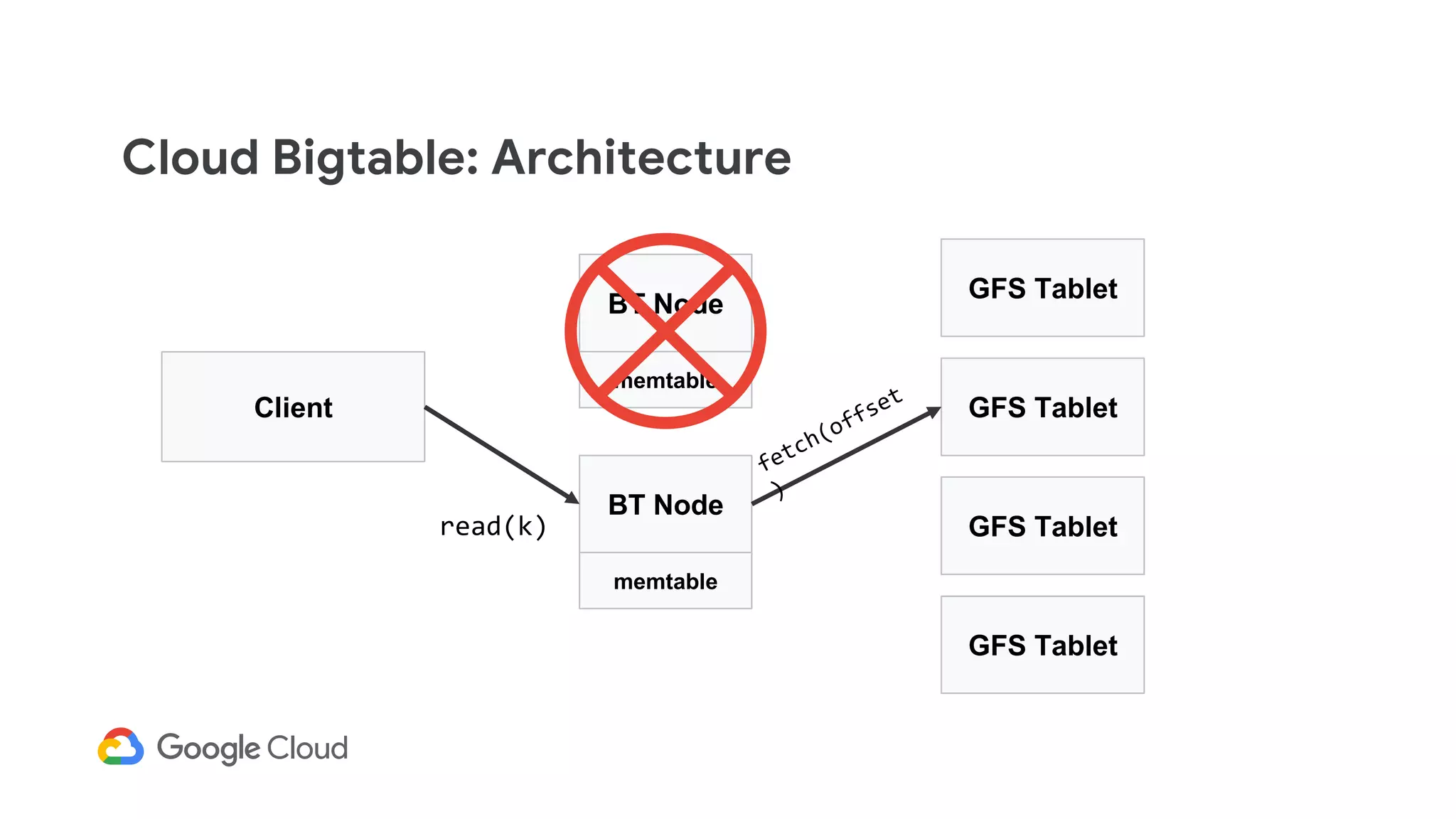
![Cloud Bigtable: Architecture
Client
BT Node
GFS Tablet
GFS Tablet
GFS Tablet
memtable
BT Node
memtable
GFS Tablet
read(k)
memtable[k]](https://image.slidesharecdn.com/dbs302drivingarealtimepersonalizationenginewithcloudbigtable-190411153007/75/Dbs302-driving-a-realtime-personalization-engine-with-cloud-bigtable-102-2048.jpg)
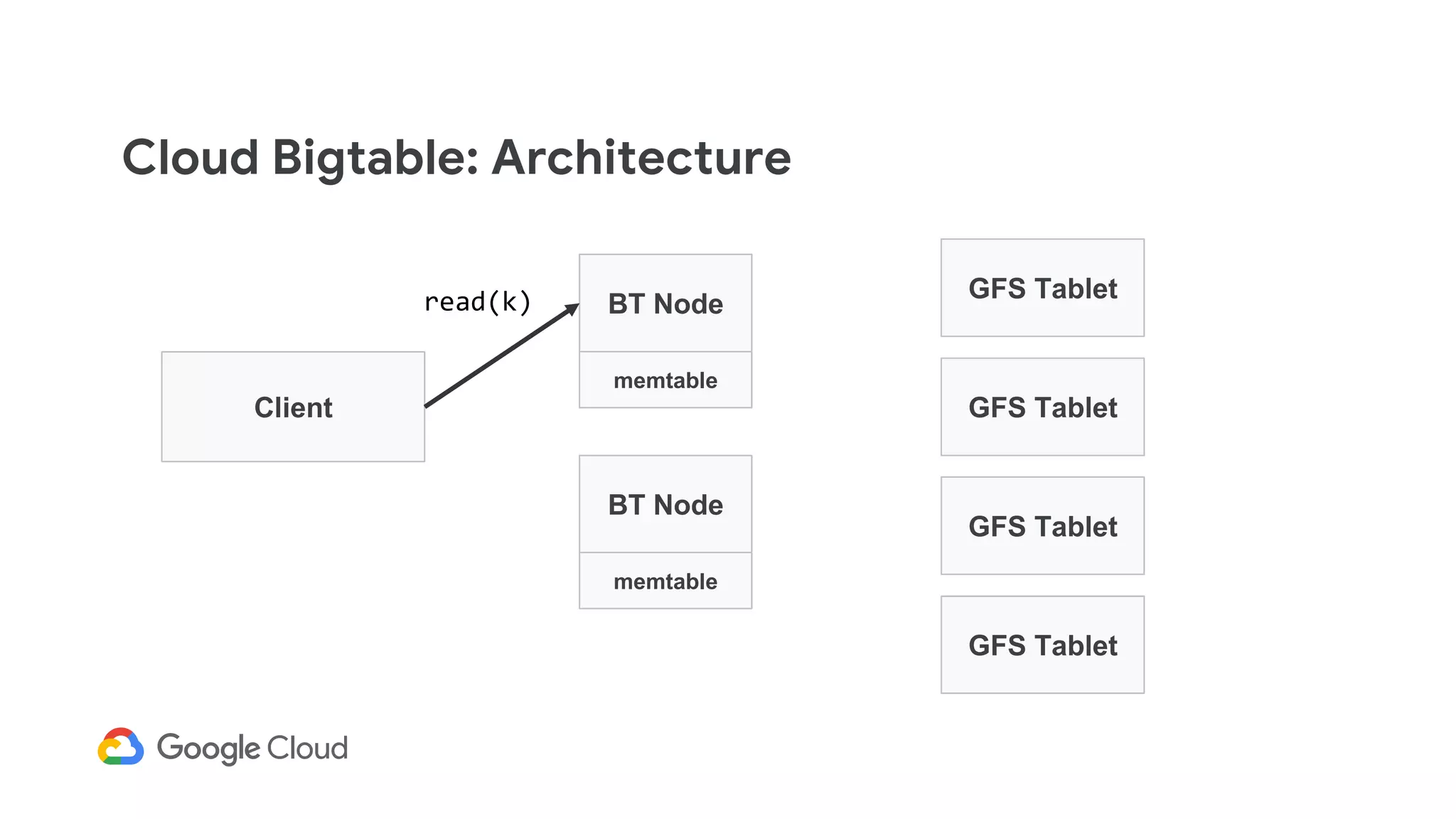
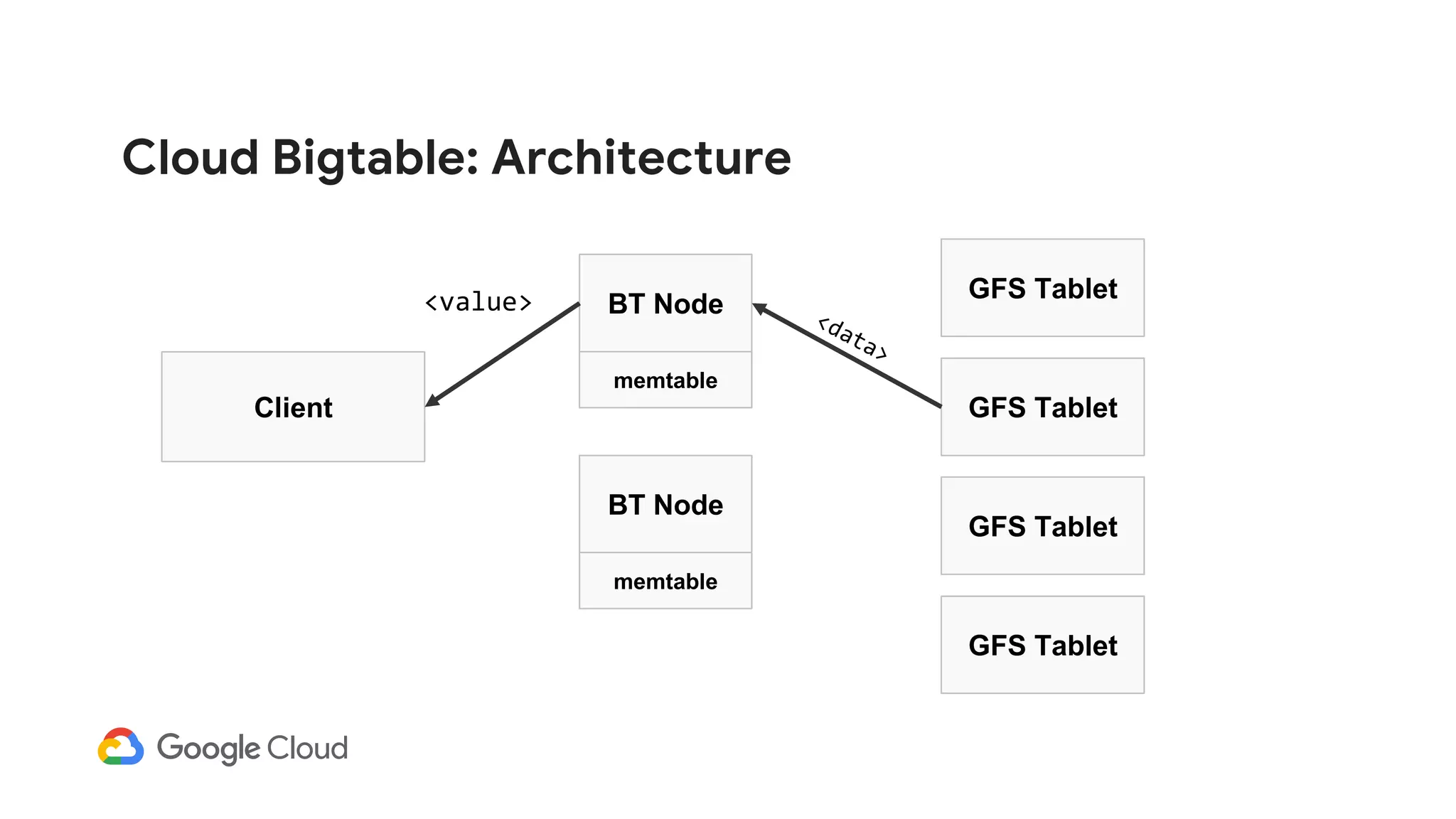
![Cloud Bigtable: Architecture
Client
BT Node
GFS Tablet
GFS Tablet
GFS Tablet
memtable
BT Node
memtable
GFS Tablet
<value>
memtable[k]](https://image.slidesharecdn.com/dbs302drivingarealtimepersonalizationenginewithcloudbigtable-190411153007/75/Dbs302-driving-a-realtime-personalization-engine-with-cloud-bigtable-103-2048.jpg)

























![[EN] Building modern data pipeline with Snowflake + DBT + Airflow.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/enbuildingmoderndatapipelinewithsnowflakedbtairflow-231024053710-6b96c278-thumbnail.jpg?width=640&height=640&fit=bounds)































































