Download as PDF, PPTX




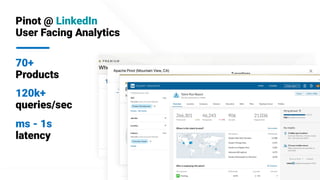
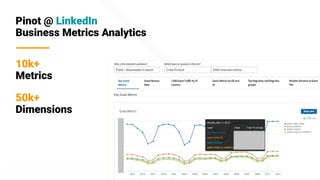





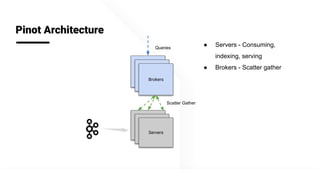
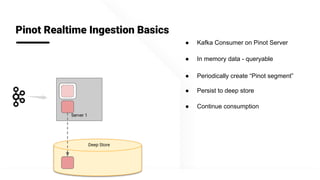

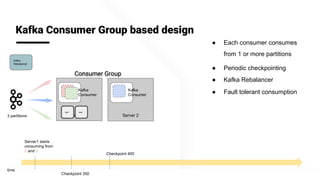
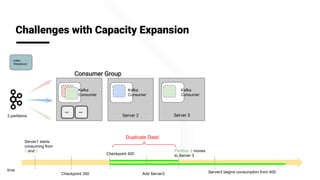
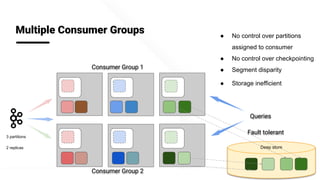
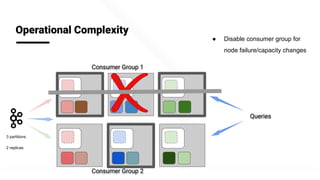
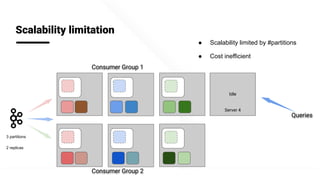
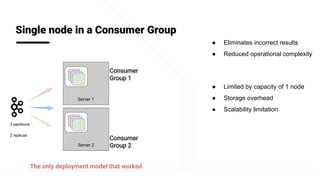

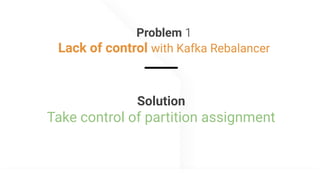


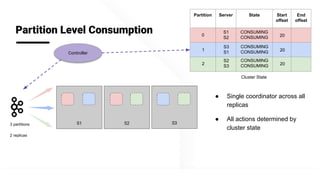
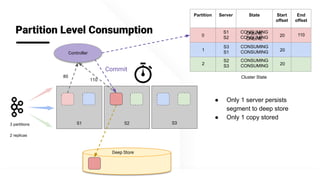
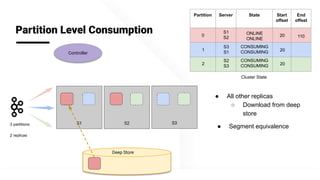
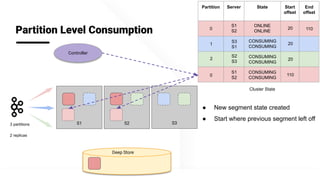
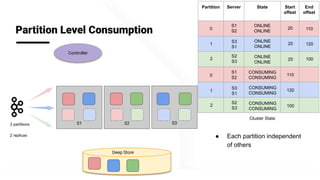
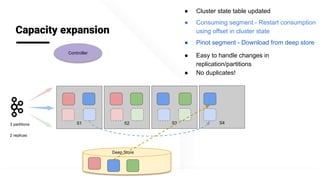
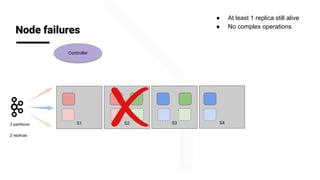
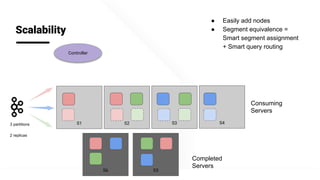
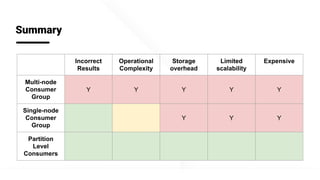


The document describes Apache Pinot, an open source distributed real-time analytics platform used at LinkedIn. It discusses the challenges of building user-facing real-time analytics systems at scale. It initially describes LinkedIn's use of Apache Kafka for ingestion and Apache Pinot for queries, but notes challenges with Pinot's initial Kafka consumer group-based approach for real-time ingestion, such as incorrect results, limited scalability, and high storage overhead. It then presents Pinot's new partition-level consumption approach which addresses these issues by taking control of partition assignment and checkpointing, allowing for independent and flexible scaling of individual partitions across servers.


























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)