Download as PDF, PPTX



![9
App Resiliency : Connection Profile
• Unique Cluster Names – RREnnnn (Region, Env, Numeric)
• Connection profile is queried via API using cluster name
• Applications are immune from Infra changes
{
"clusterName": "NAD1700",
"topicSuffix": "na1700",
"kafkaBrokerConnectionProtocols": [
{
"protocol": "SASL_SSL",
"bootstrapServersStr": "",
"serviceName": " jpmckafka",
}
],
"schemaRegistryURLs": [
],
"restProxyURLs": [],
"clusterReplicationPattern": "ACTIVE_ACTIVE",
"replicatedClusterProfile": {
"clusterName": "NAD1701",
"topicSuffix": "na1701",
"kafkaBrokerConnectionProtocols": [
{
"protocol": "SASL_SSL",
"bootstrapServersStr": "",
"serviceName": “jpmckafka",
}
],
"schemaRegistryURLs": [
],
"restProxyURLs": []
}
}
/applications/{appid}/cluster/{ClusterName}/connectionProfile Connection Profile for a given clusterGET](https://image.slidesharecdn.com/vishnubalusuashokkadambala-191007044527/75/Secure-Kafka-at-scale-in-true-multi-tenant-environment-Vishnu-Balusu-Ashok-Kadambala-JP-Morgan-Chase-Kafka-Summit-SF-2019-9-2048.jpg)


![18
Kafka Streams
{
"streamApplicationId": “user-transactions-stream",
"clusterName": “NAD100",
"streamAuthId": “someuser@REALM.COM",
"streamThroughputInKBPS": 1000,
"owningApplicationId": 1234,
"streamUserTopics": {
"inputTopics": [
“user-transactions”
],
"intermediateTopics": [],
"outputTopics": [
“patterns”,
“rewards”,
“purchases”
]
}
}
Example Use Case
Onboard Stream API
Masking
user-transactions
Rewards Patterns
rewards patterns
purchases](https://image.slidesharecdn.com/vishnubalusuashokkadambala-191007044527/75/Secure-Kafka-at-scale-in-true-multi-tenant-environment-Vishnu-Balusu-Ashok-Kadambala-JP-Morgan-Chase-Kafka-Summit-SF-2019-18-2048.jpg)
![20
{
"deployKeytabs": false,
"componentsInScope": [
{
"component": “KAFKA",
"deployConfig": true,
"deployBinaries": true,
"binariesVersion": “Confluent-5.2.2"
}
],
"goodToGoEvidence": {
"evidenceType": "NOT_APPLICABLE",
"evidenceId": "string"
}
}
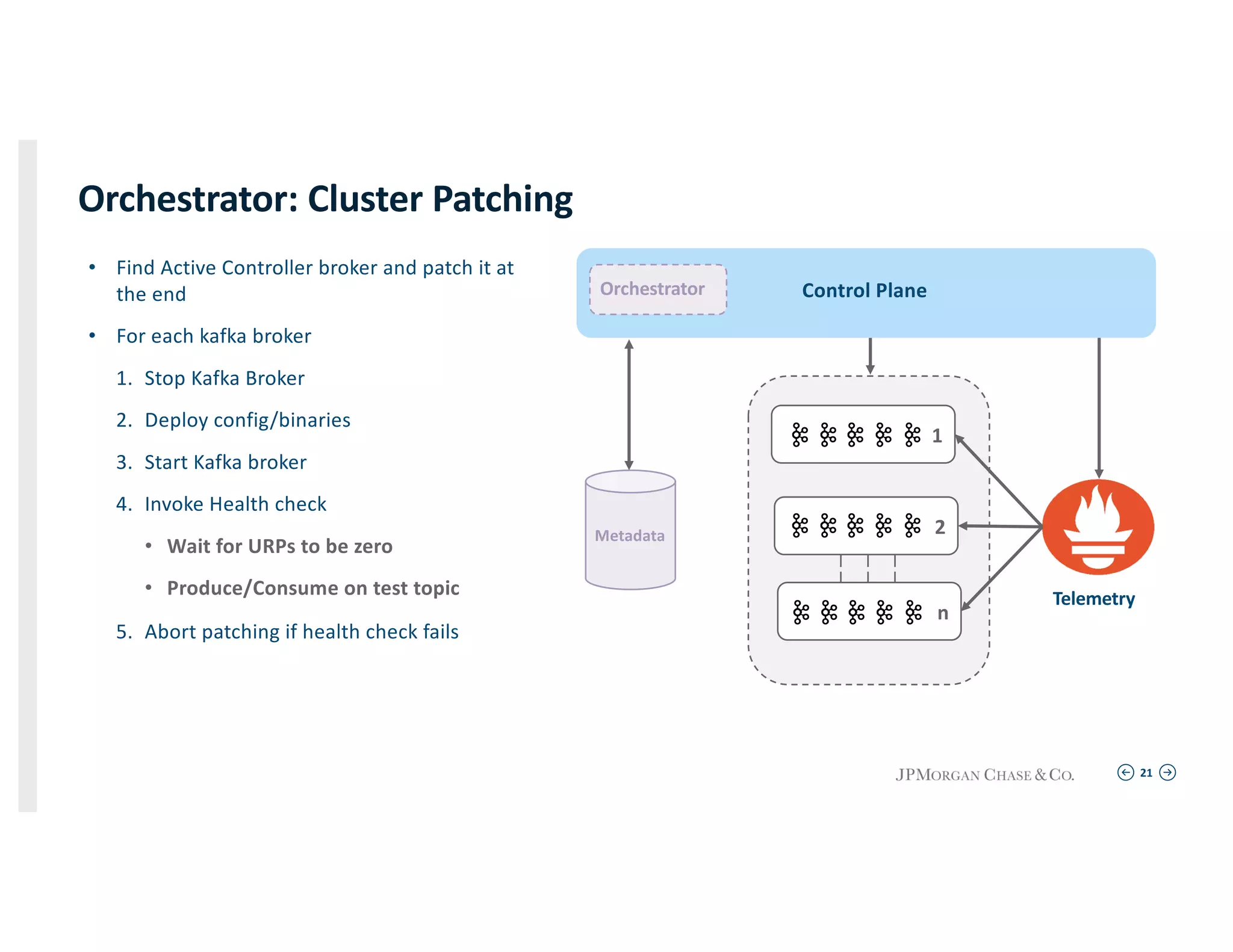
Orchestrator: Cluster Patching
1
2
n
Metadata
Control Plane
Telemetry
Orchestrator](https://image.slidesharecdn.com/vishnubalusuashokkadambala-191007044527/75/Secure-Kafka-at-scale-in-true-multi-tenant-environment-Vishnu-Balusu-Ashok-Kadambala-JP-Morgan-Chase-Kafka-Summit-SF-2019-20-2048.jpg)




The document outlines the design and implementation of a managed Kafka service that addresses various challenges such as security, resiliency, and governance for multi-tenancy in a cloud environment. It covers key components including cluster design, data-driven control plane, and self-service APIs for applications, along with lessons learned and future enhancements in the Kafka ecosystem. Presenters Vishnu Balusu and Ashok Kadambala highlight the importance of automating processes and maintaining a centralized schema registry for effective management.
Introduction to secure Kafka implementation in a multi-tenant environment presented at Kafka Summit 2019.
Detailed agenda outlining two parts focusing on design principles, cluster design, APIs, resiliency, and future directions.
Presenting challenges faced like varied designs and lack of governance, and proposing a fully managed service solution with specified design principles.
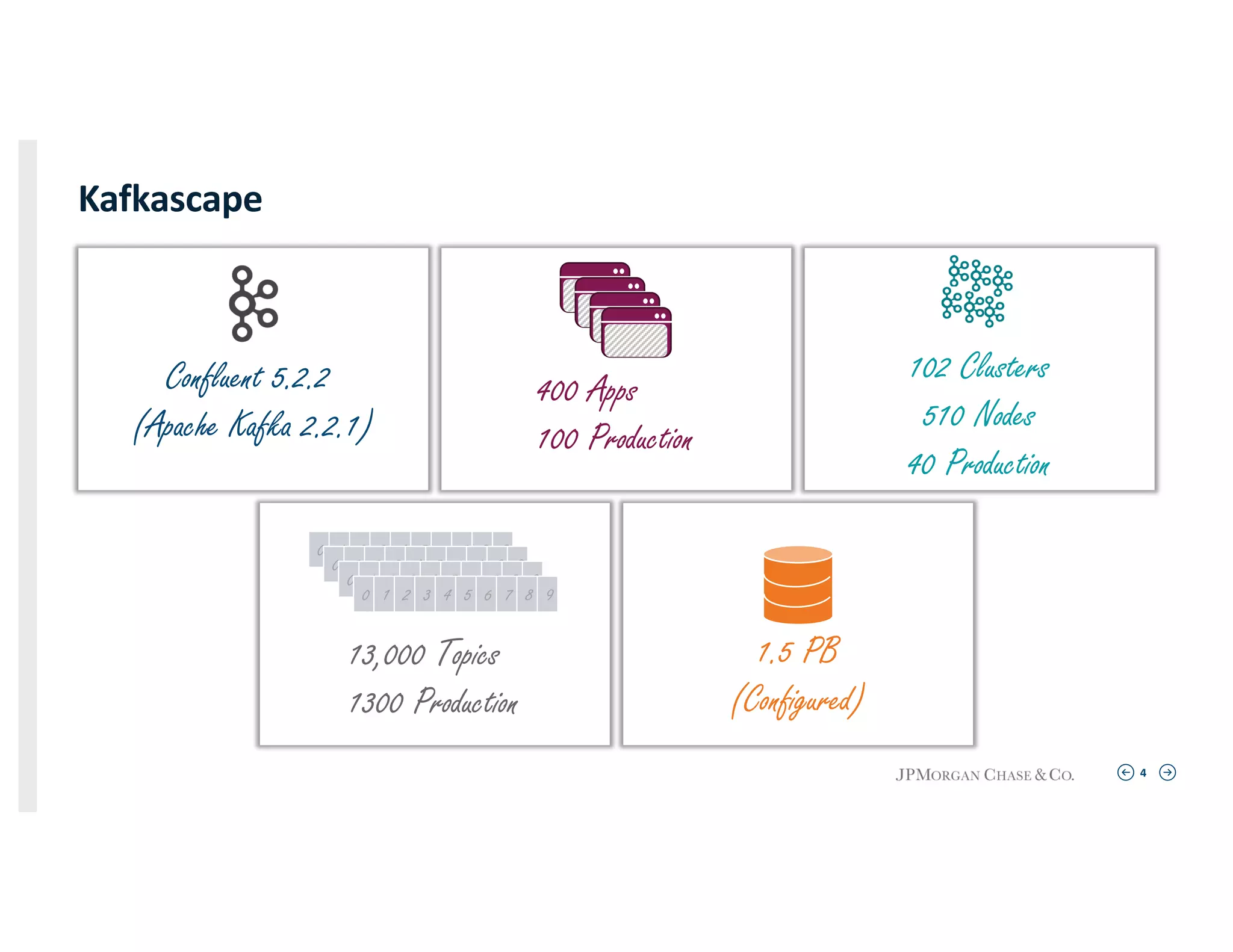
Insights into Kafka ecosystem showcasing infrastructure metrics including 400 Apps, 102 Clusters, and 1.5 PB configured.
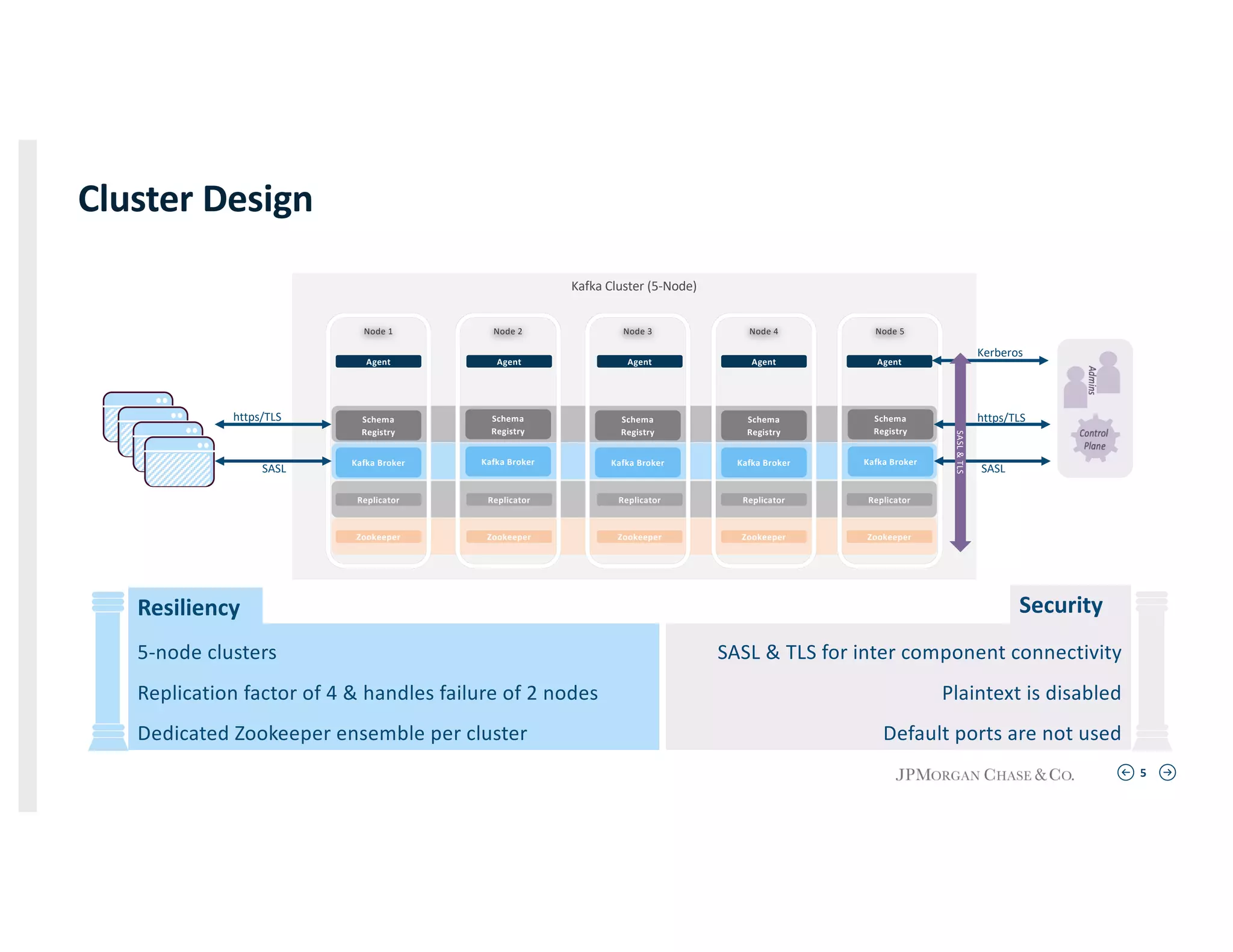
Details on cluster design specifying a 5-node structure with resilience and security configurations including SASL and TLS.
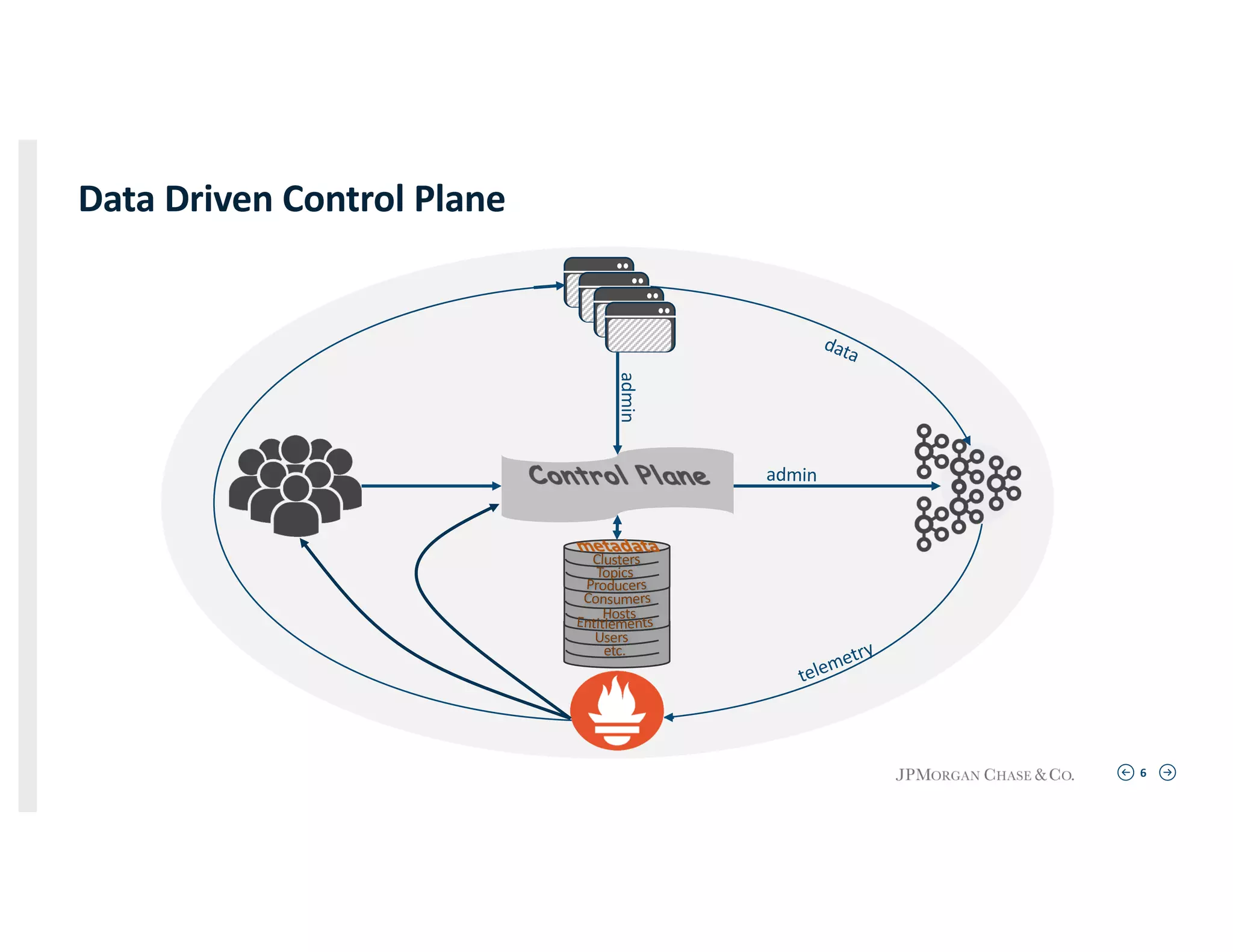
Focus on the data-driven control plane functionality across clusters ensuring efficient management and telemetry.
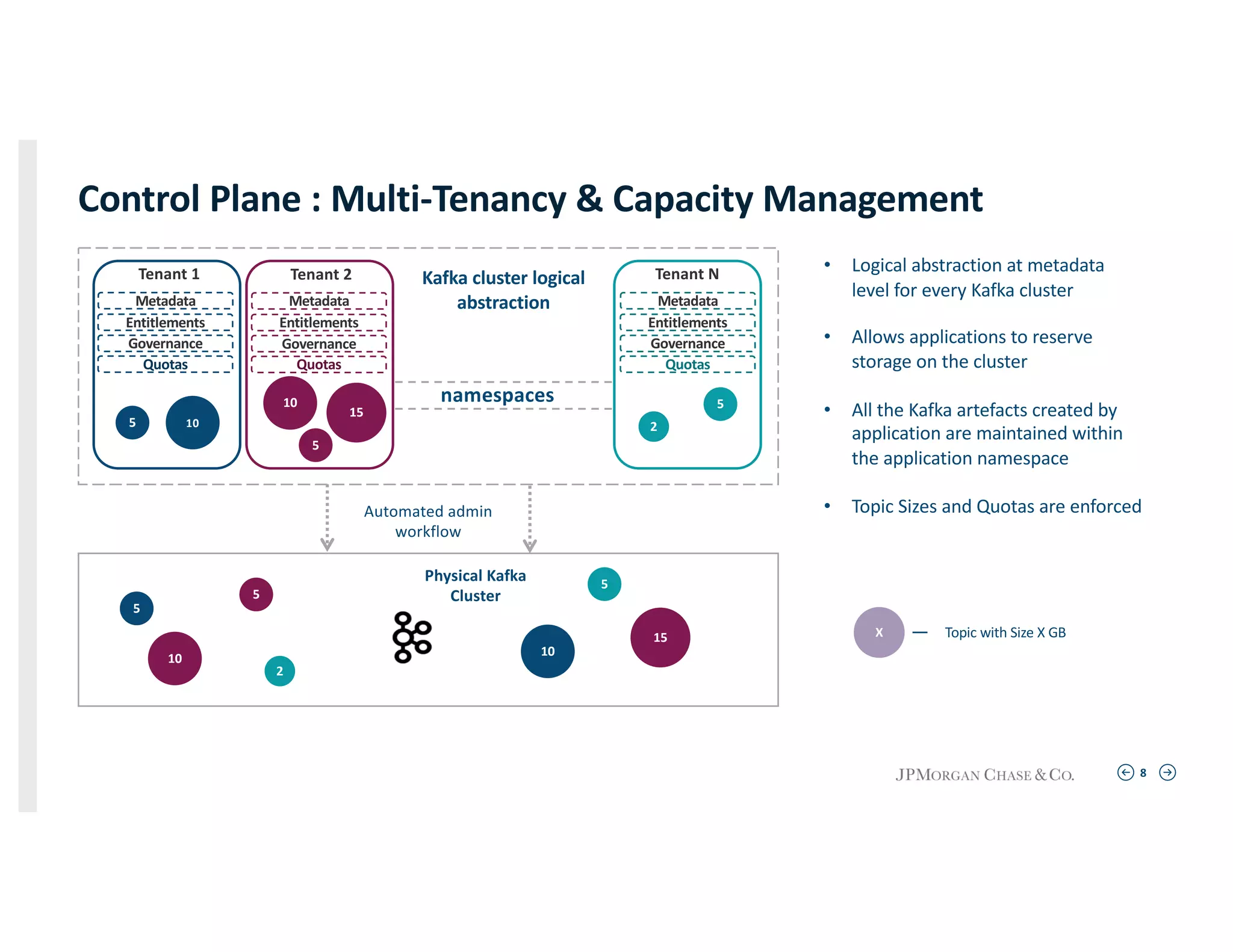
Explaining logical abstraction for metadata management and automated policy enforcement across tenant namespaces.
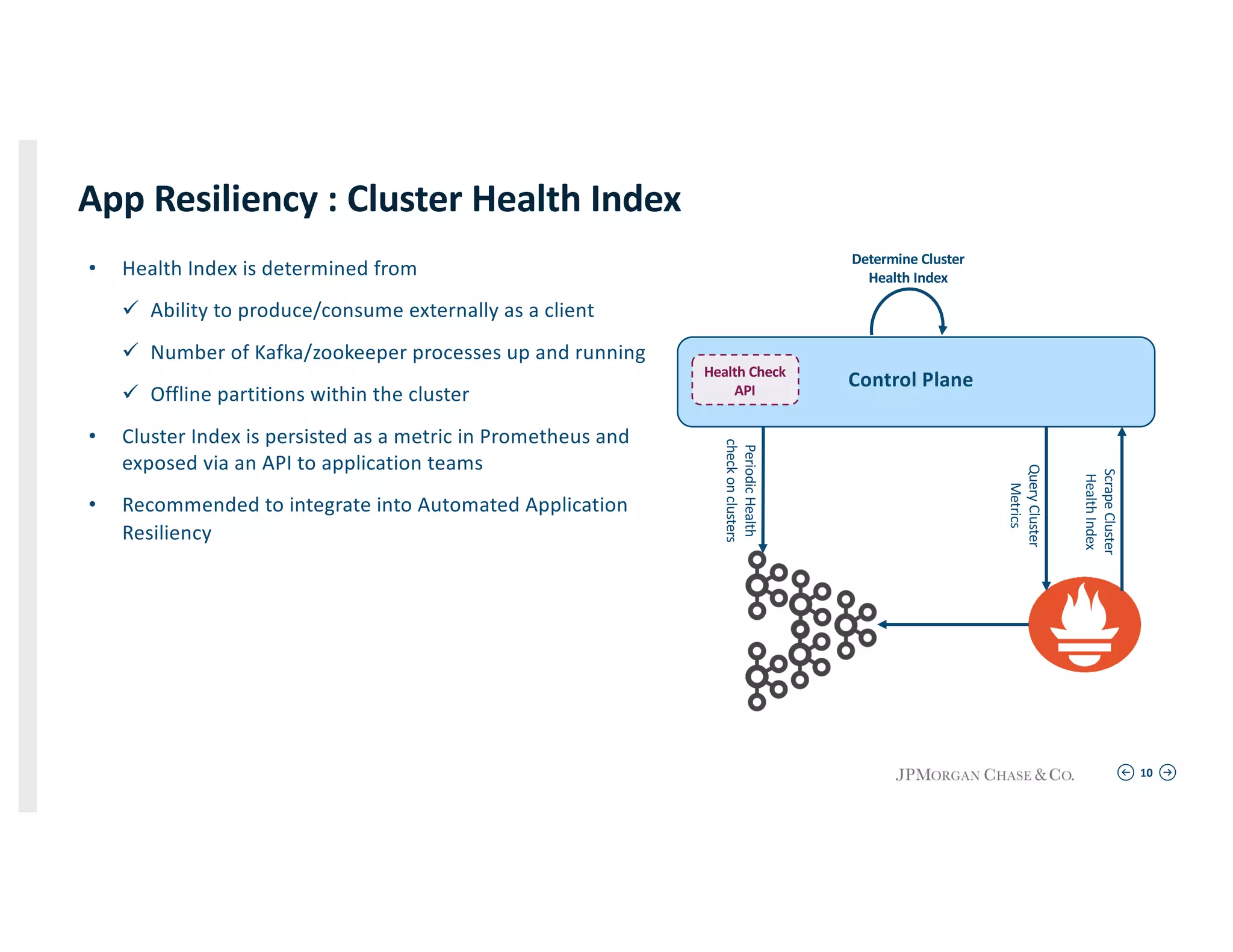
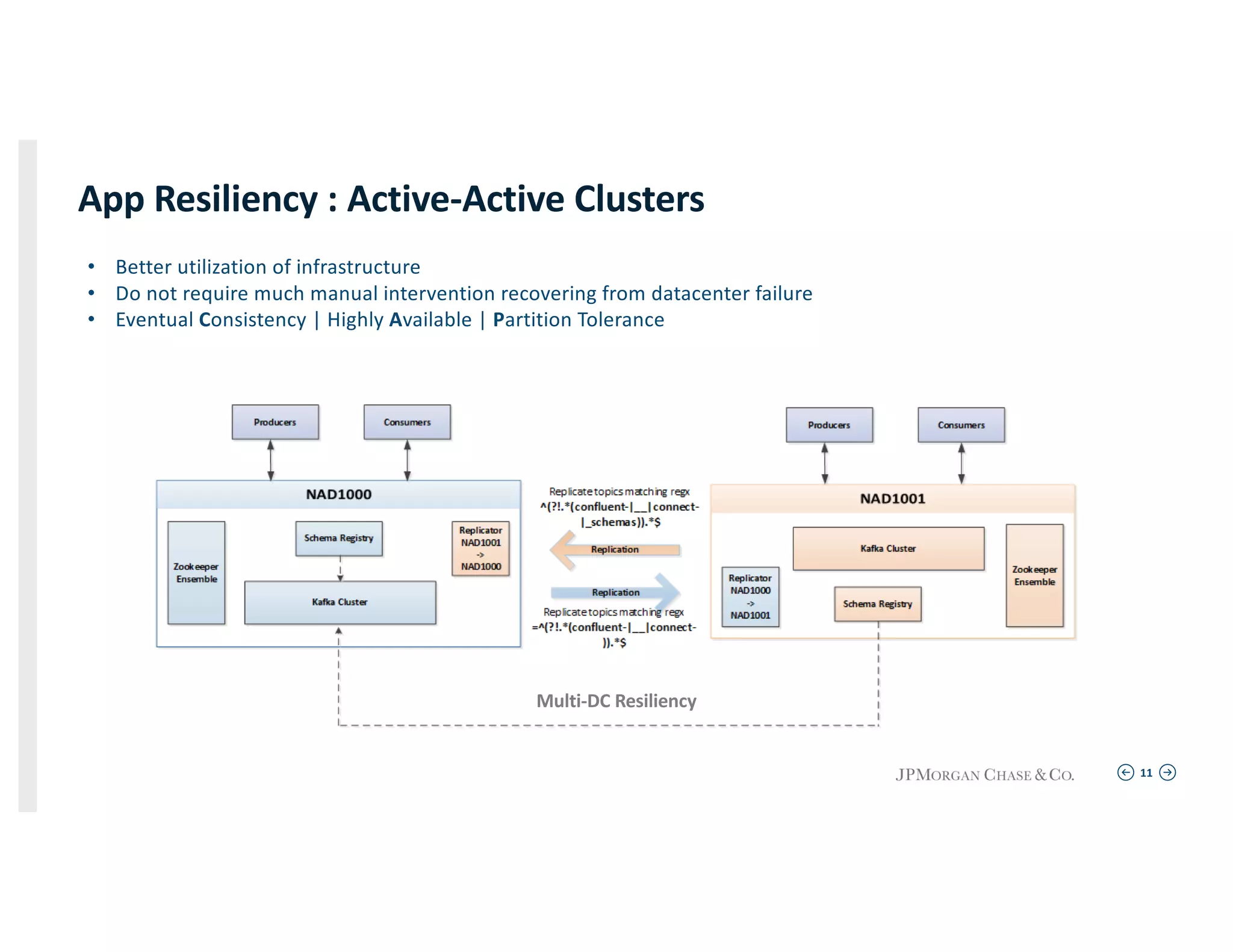
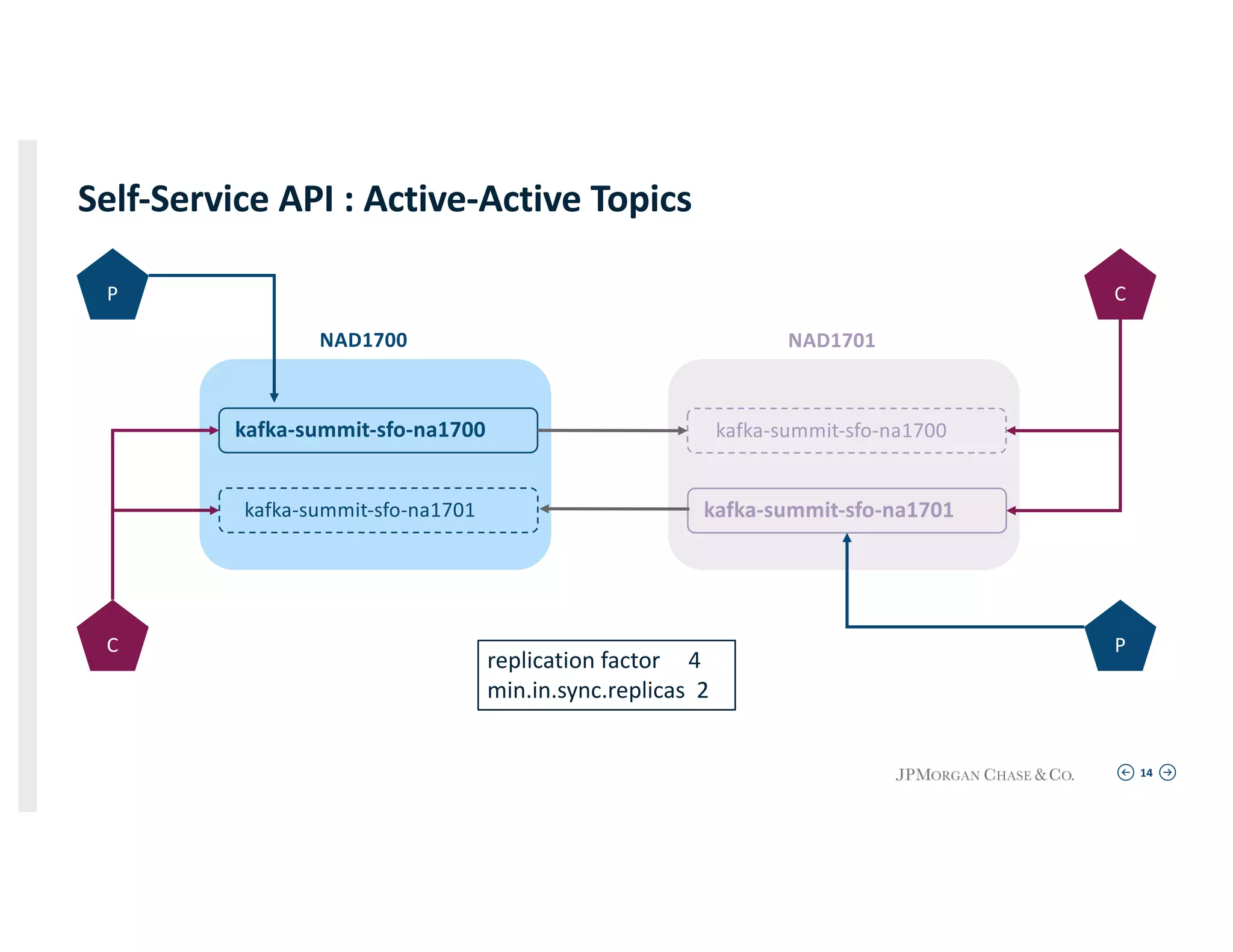
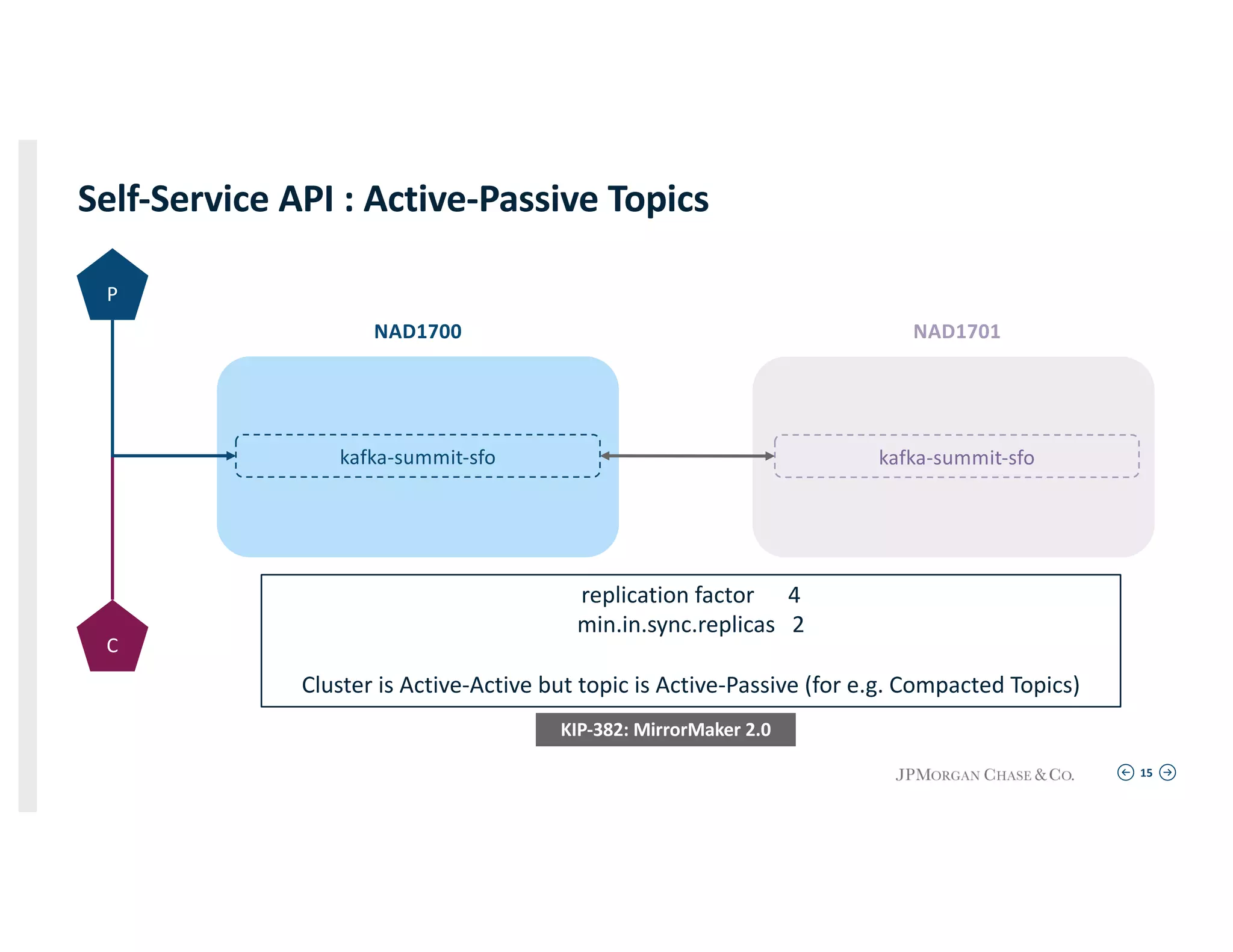
Techniques for maintaining application connectivity and health indices in a resilient environment utilizing active-active cluster setups.
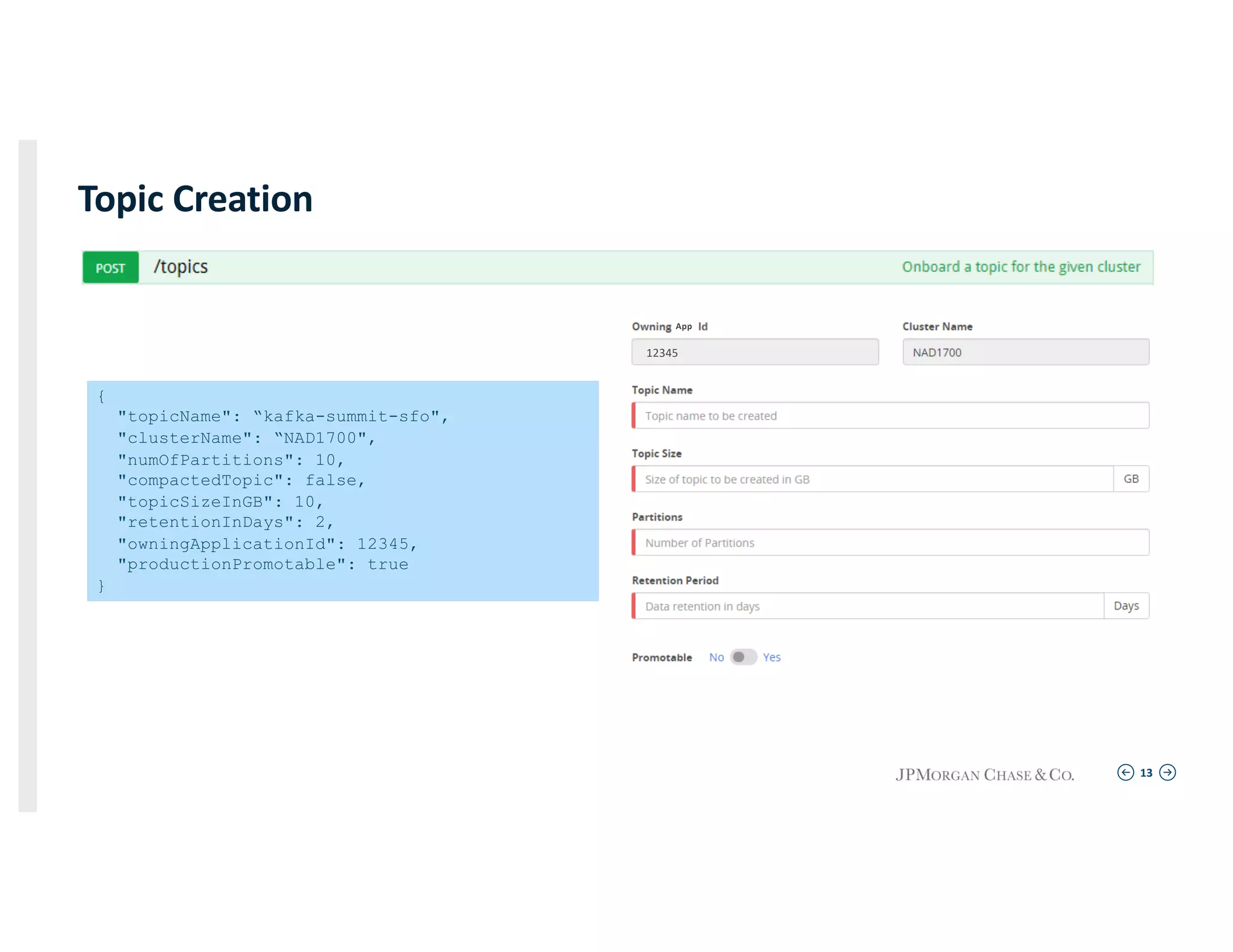
Describing the self-service API for creating topics, including the specifics of topic replication and configurations for various scenarios.
Best practices for managing schema registered data while ensuring security and maintaining data lineage.
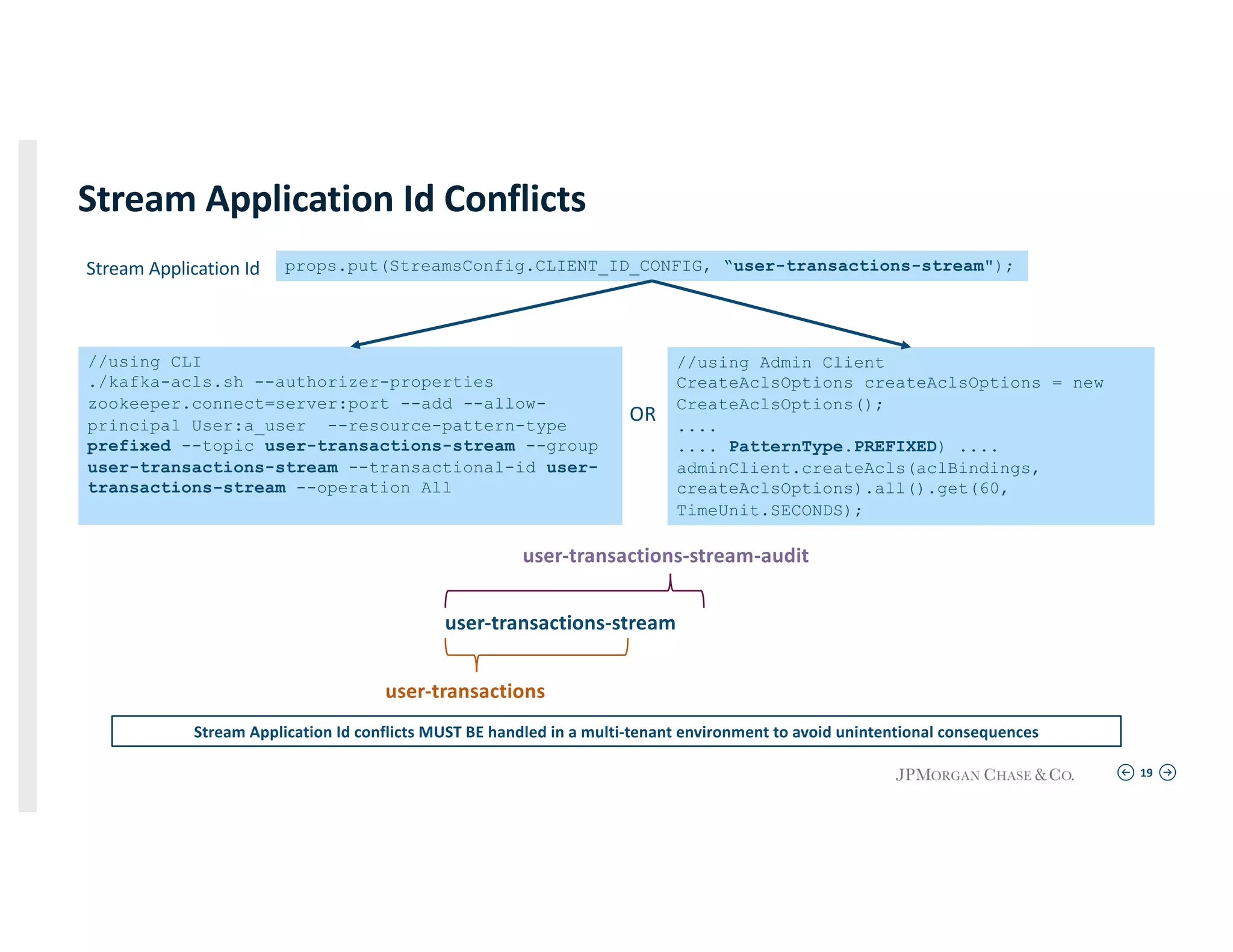
Showcasing Kafka Streams with defined application flows, highlighting conflict resolution in a multi-tenant setup.
Outline of orchestrating Kafka broker updates ensuring health checks and minimal downtime during patching.
Explaining a common control plane strategy that allows for ubiquitous access across various platforms including public and private clouds.
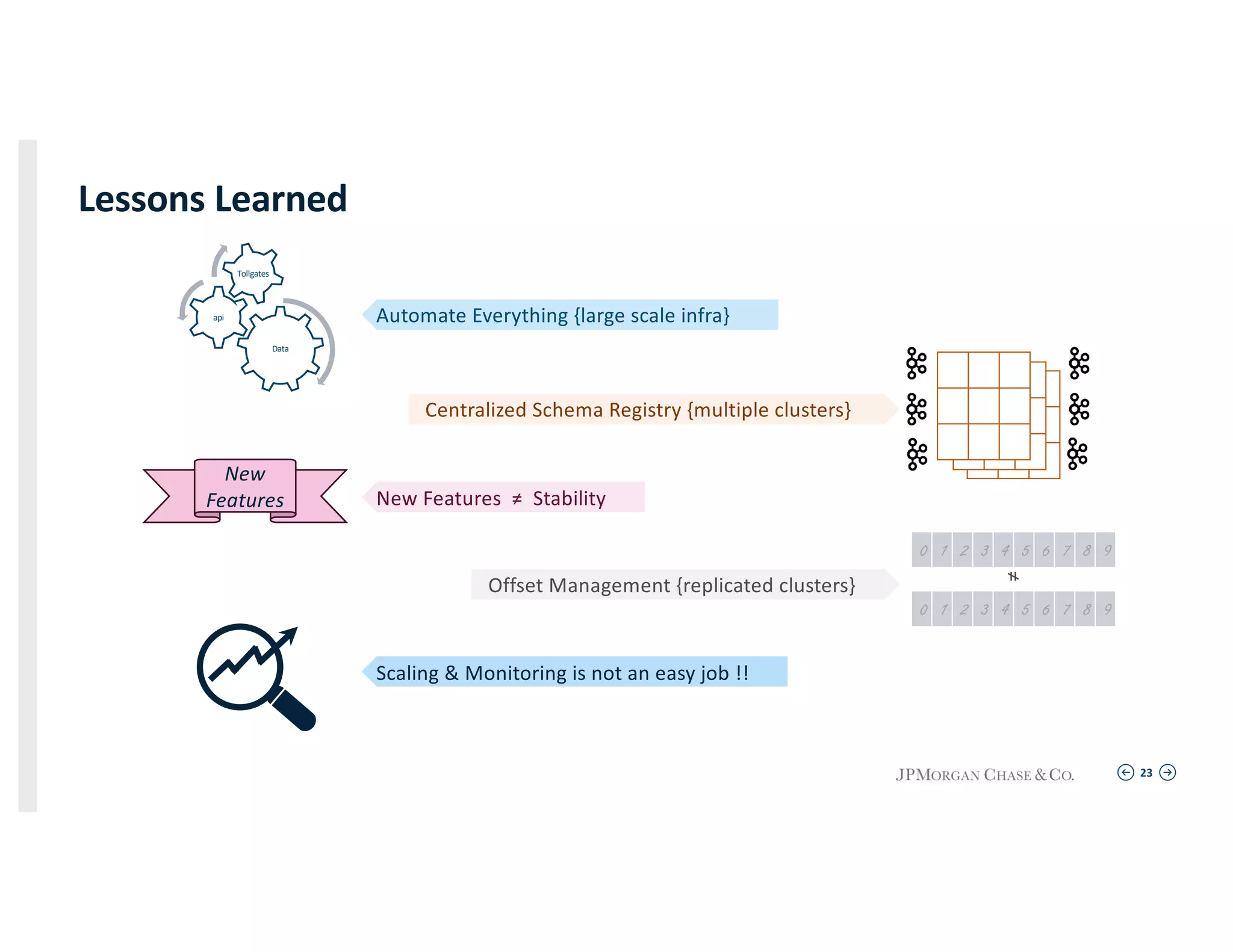
Summarizing lessons learned during implementation phases, focusing on automation, centralized management, and the complexity of scaling.
Vision for future Kafka enhancements including fleet management, self-healing capabilities, and chaos engineering principles.
Conclusion and gratitude expressed at the end of the presentation.











![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)











































































