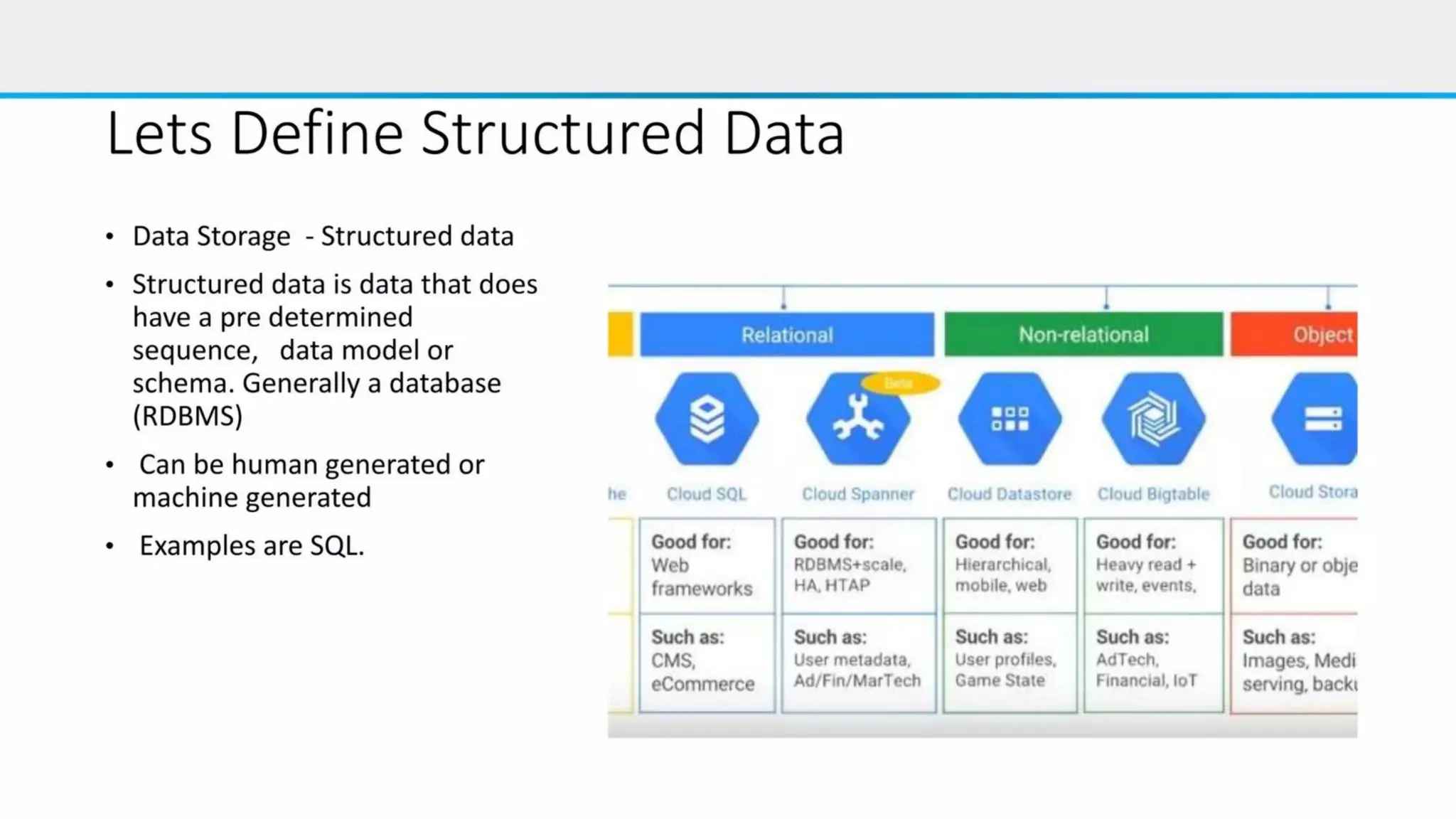
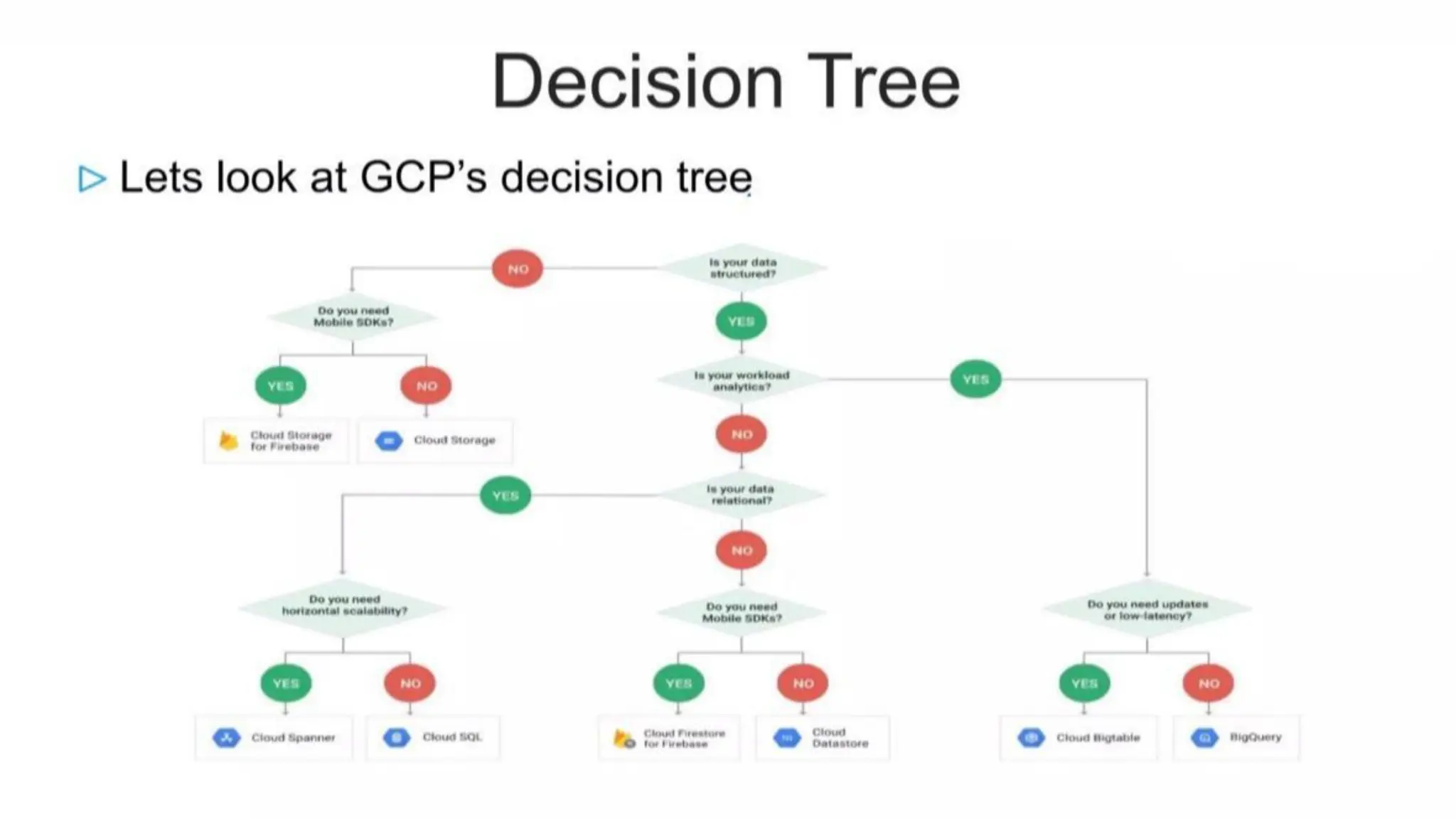
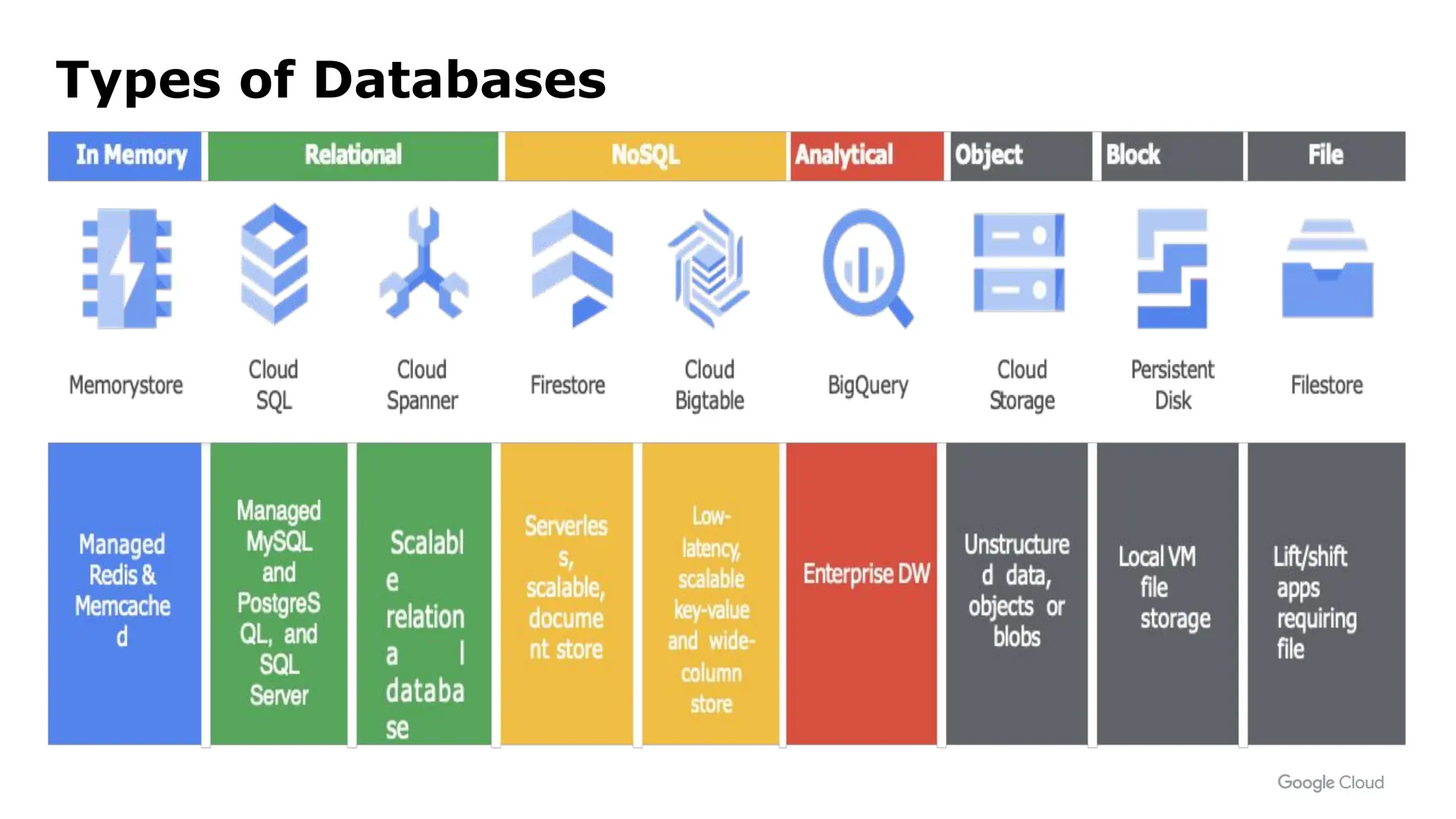
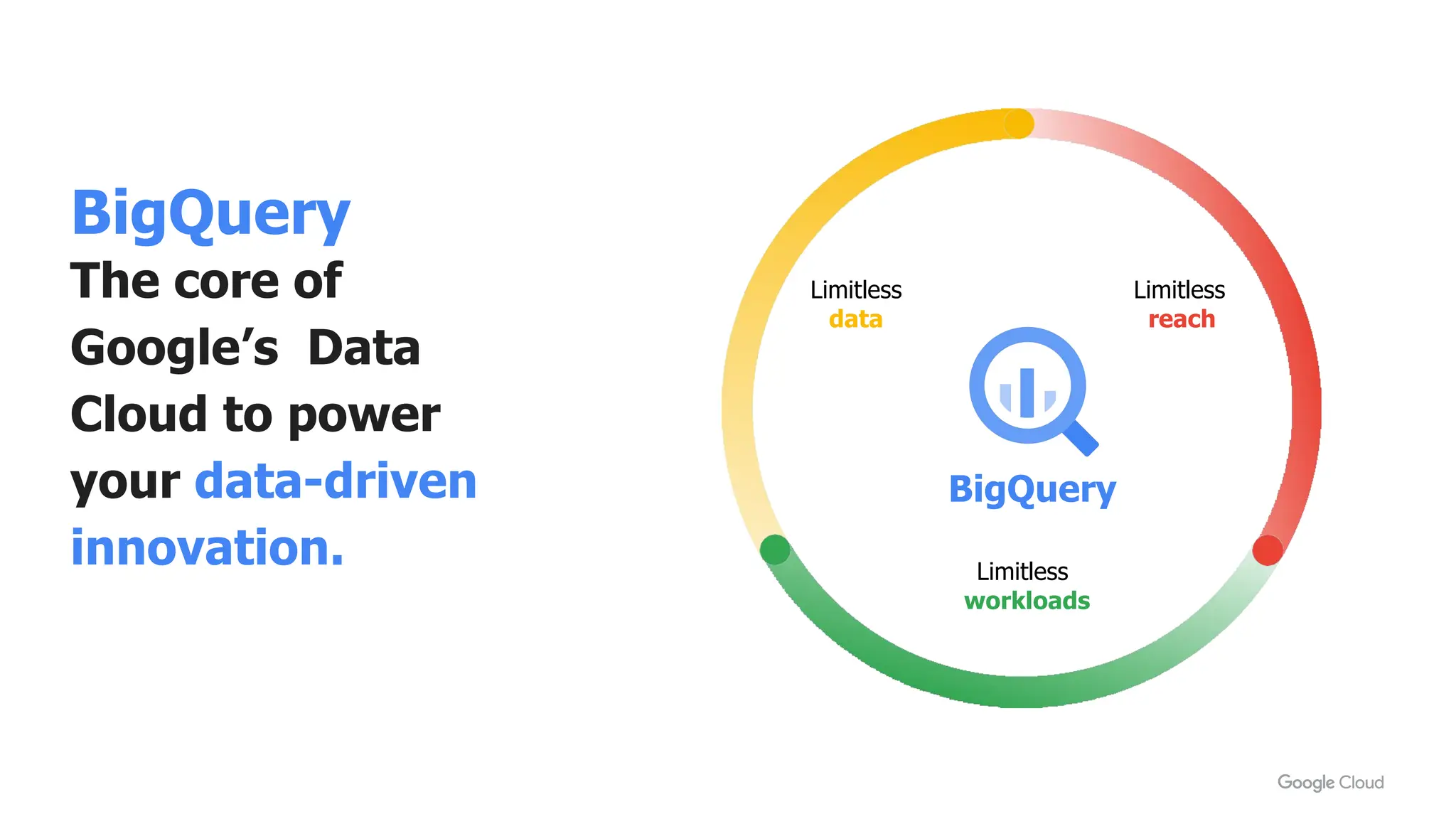
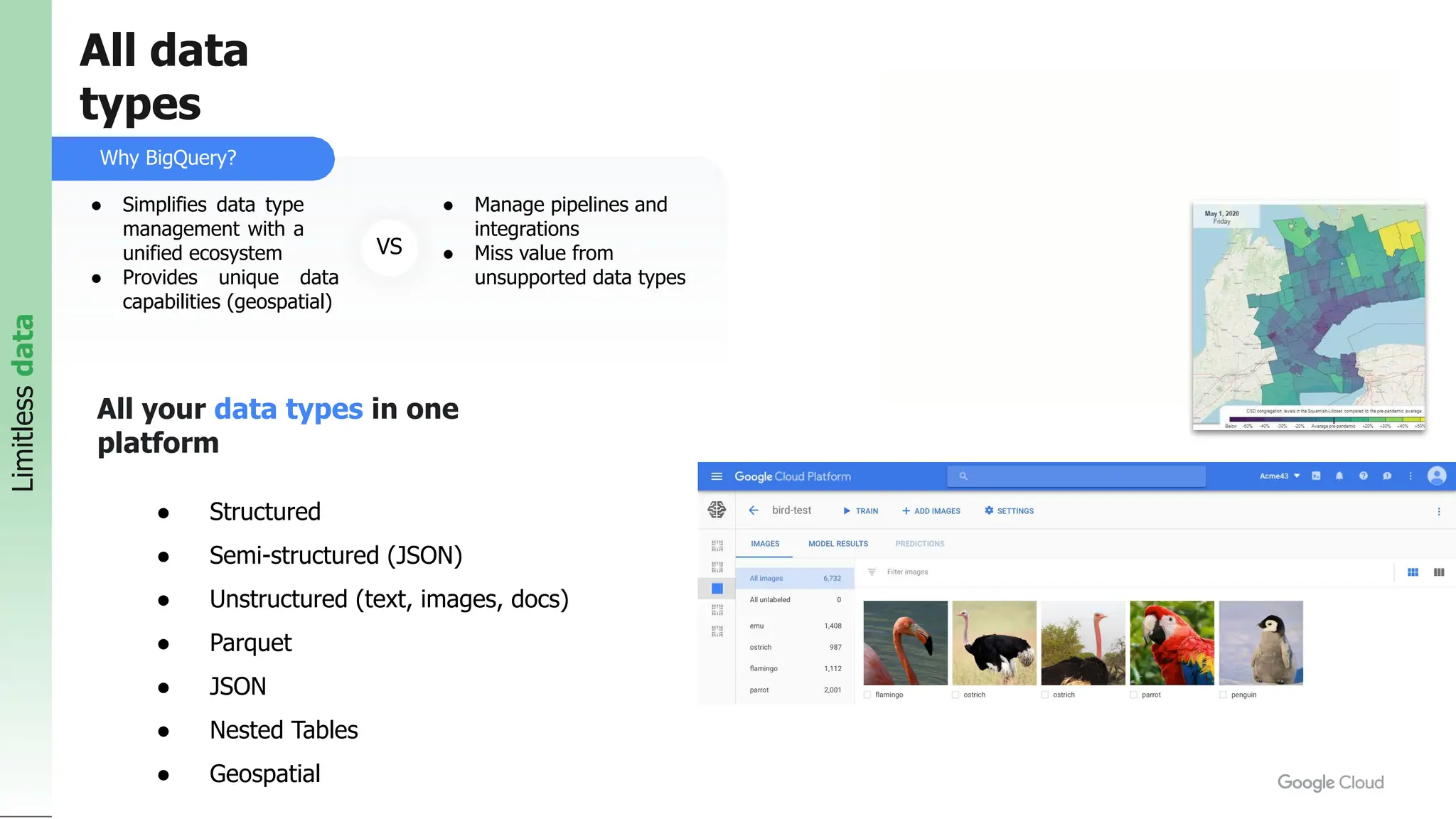
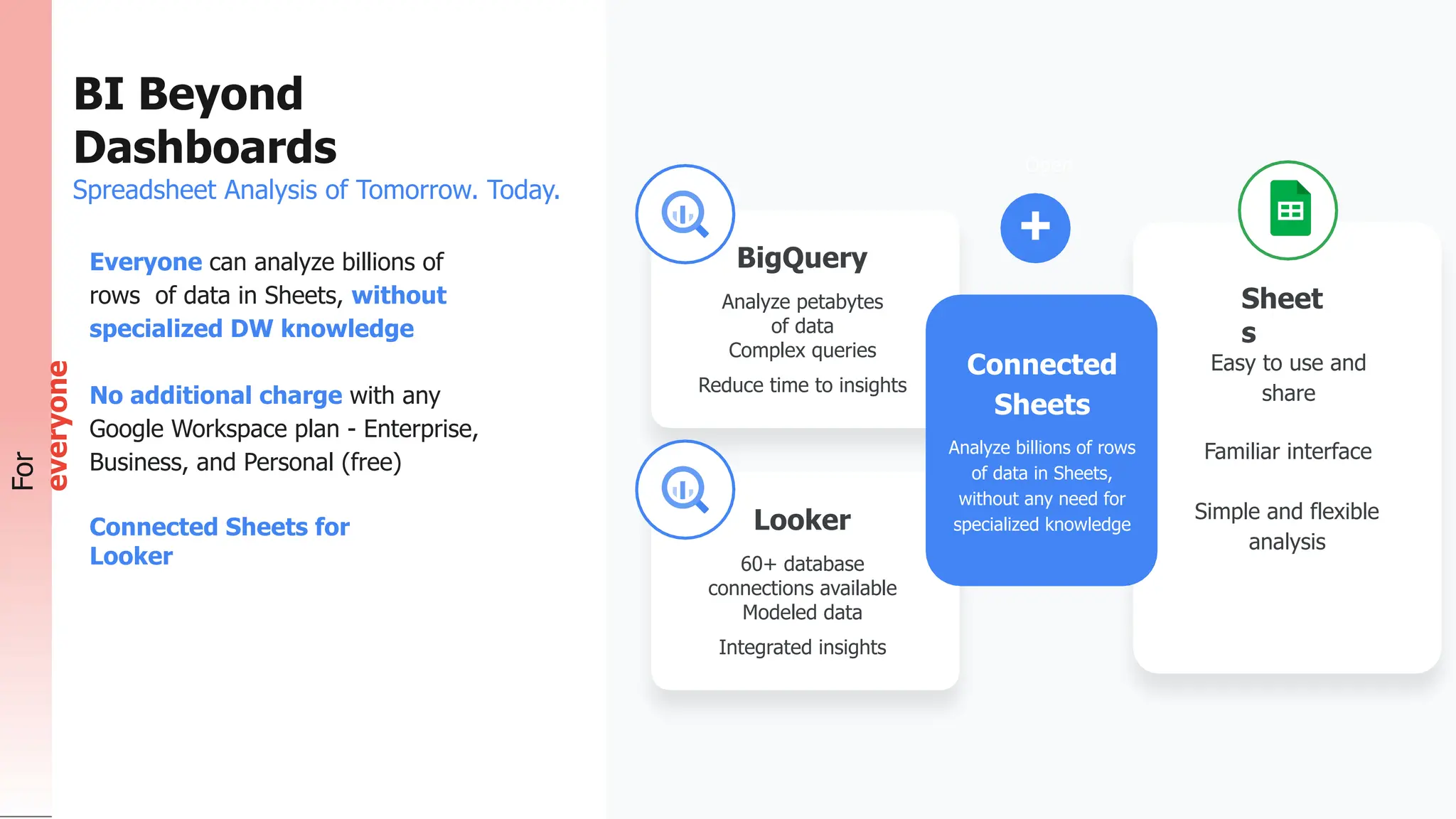
The document summarizes different database options available on Google Cloud, including:
- Memorystore, a fully managed Redis and Memcached database for sub-millisecond data access. It is scalable, secure, and highly available.
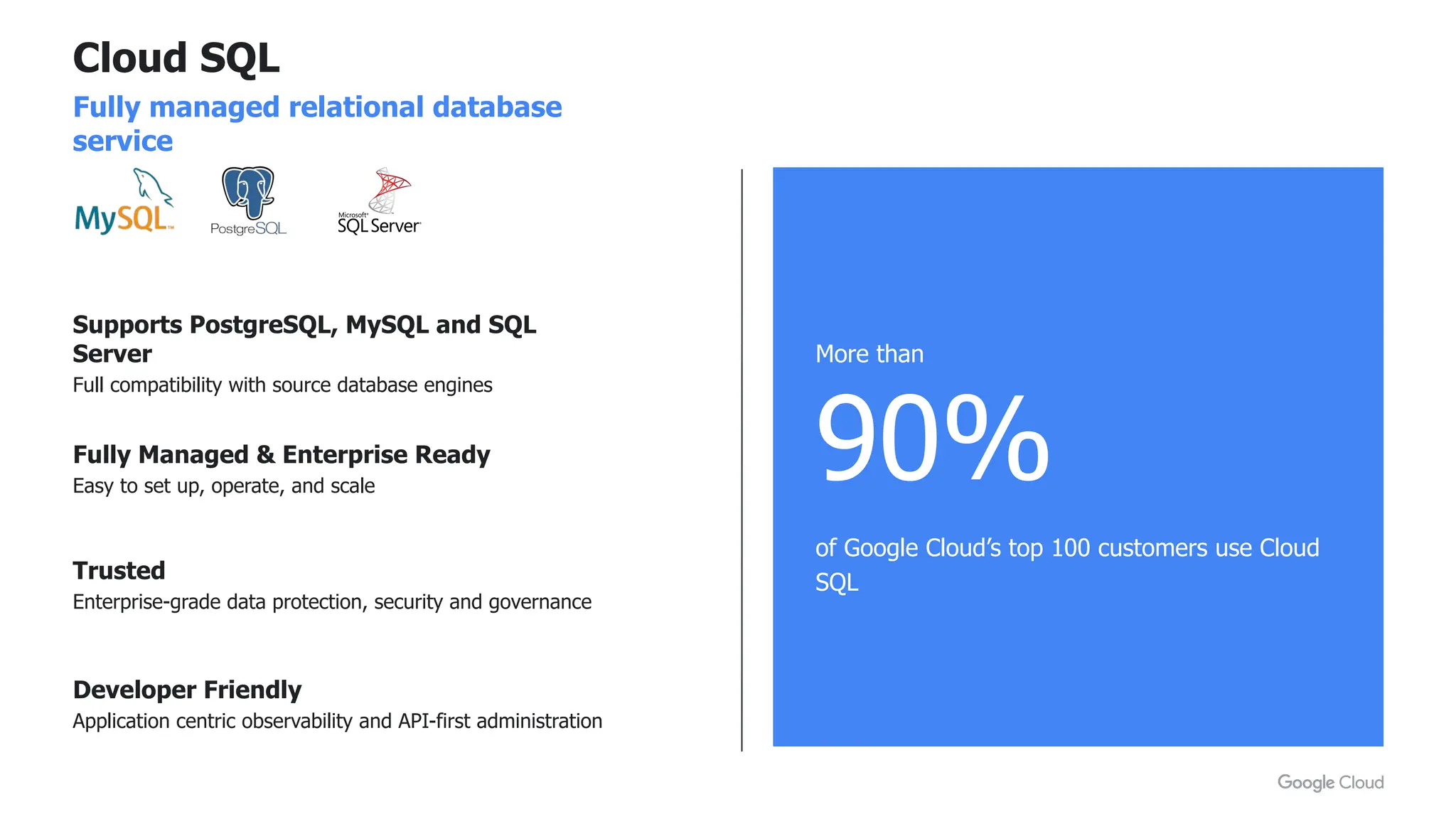
- Cloud SQL, a managed database platform for MySQL, PostgreSQL and SQL Server databases that is easy to set up and scale.
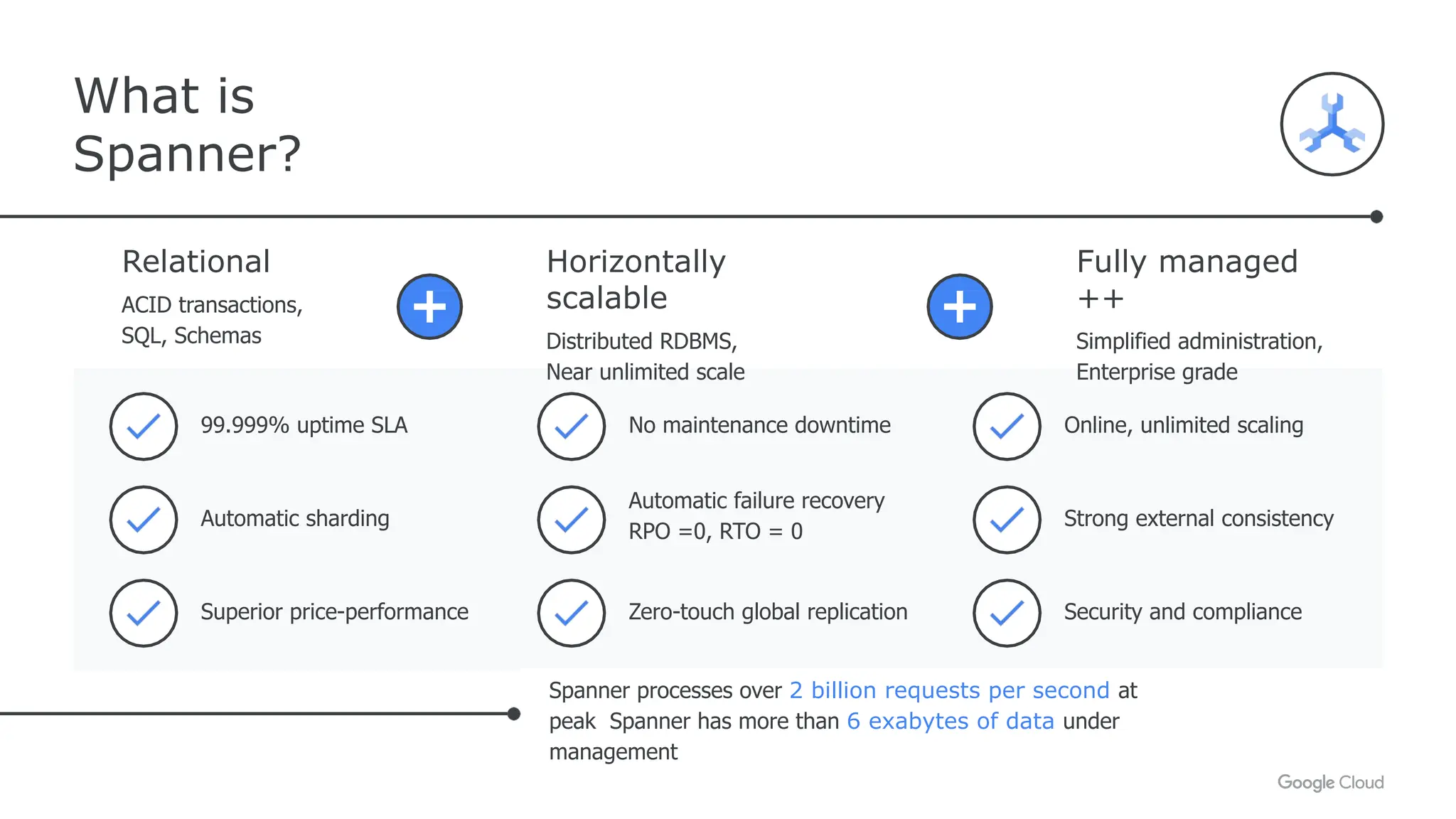
- Spanner, an enterprise-grade, globally distributed SQL database that provides strong consistency and automatic sharding at scale.
- Firestore, a serverless NoSQL document database that offers automatic scaling, high performance and real-time sync capabilities.
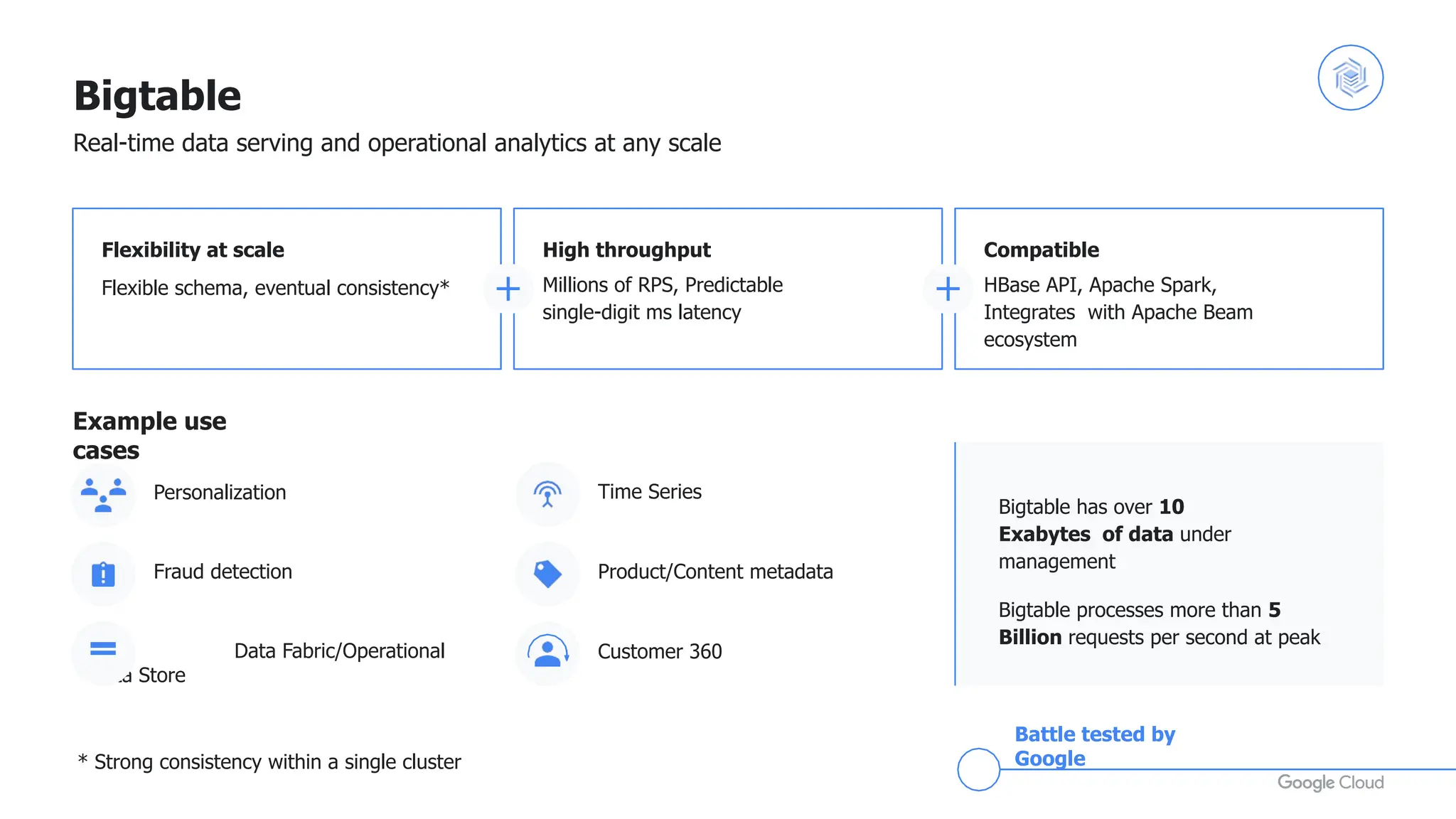
- Bigtable, a globally distributed NoSQL database that provides high performance at massive scales






























![[Cloud OnAir] Talks by DevRel Vol.4 データ管理とデータ ベース 2020年8月27日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ttt-200827092150-thumbnail.jpg?width=640&height=640&fit=bounds)






















































