Download as PDF, PPTX






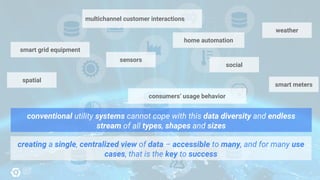


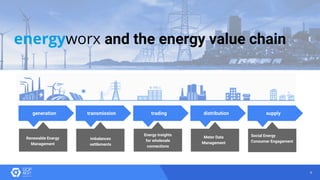



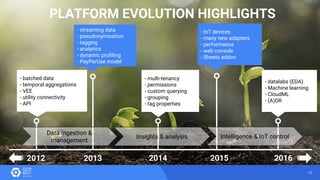
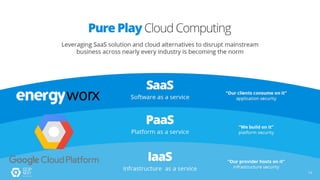
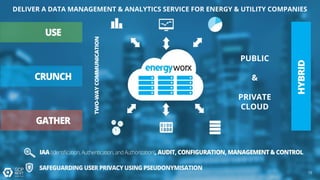


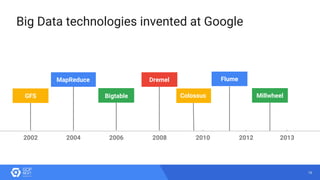














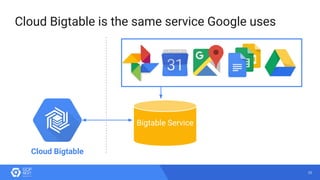

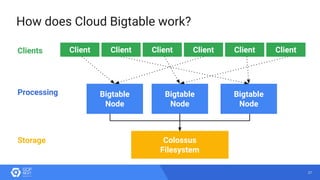
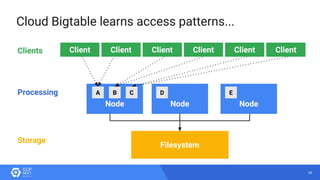
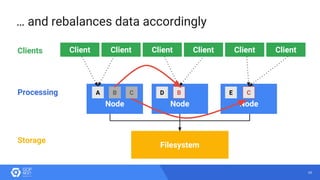
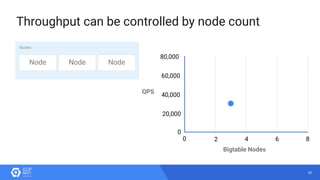
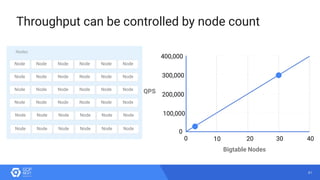
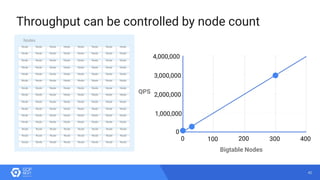






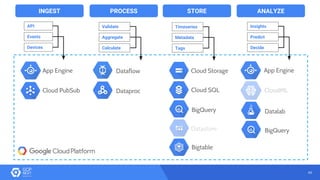
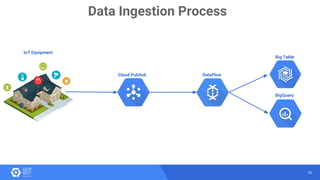








The document discusses the analysis of smart meter data through advanced data management services leveraging Google Cloud technologies like Bigtable, Dataflow, and BigQuery, aimed at addressing challenges in the evolving energy market. It emphasizes the need for centralized data views, privacy safeguards, and the emergence of data-driven business models in the utility sector. Key advantages of the proposed solutions include cloud scalability, machine learning integration, and support for various IoT devices.










![[Webinar] Measure Twice, Build Once: Real-Time Predictive Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/infochimpsthinkbigwebinar-130510142153-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![code lab live Google Cloud Endpoints [DevFest 2015 Bari]](https://cdn.slidesharecdn.com/ss_thumbnails/nickcodelablivegooglecloudendpoints-150509100715-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








