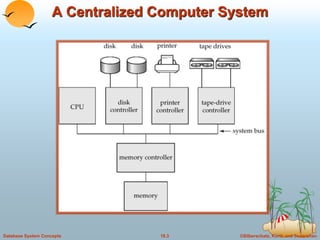
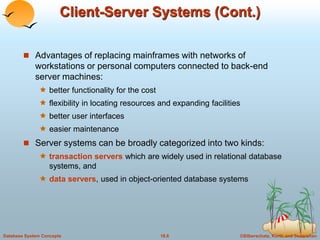
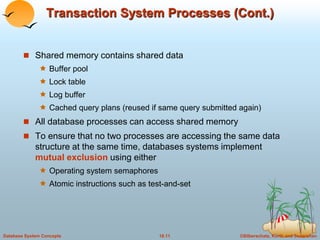
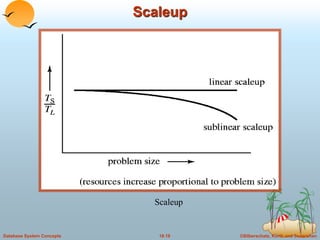
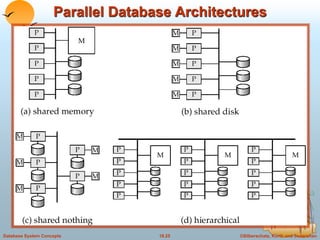
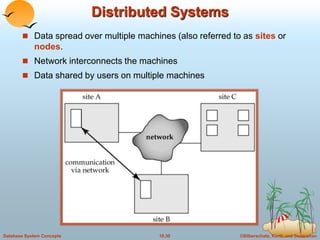
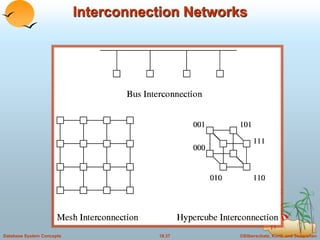
This document discusses different database system architectures including centralized systems, client-server systems, parallel systems, and distributed systems. It provides details on the components and functionality of centralized, client-server, and transaction server architectures. It also describes data servers, addressing issues like page shipping versus item shipping, locking, data caching, and lock caching in data server systems. The document concludes with explanations of speedup and scaleup in parallel database systems.



































































![如何選中小企業網路大學校[熱門排行]的課 以[Google的電子郵件Gmail教學]為例](https://cdn.slidesharecdn.com/ss_thumbnails/googlegmail-091217072549-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















































