Download as PDF, PPTX






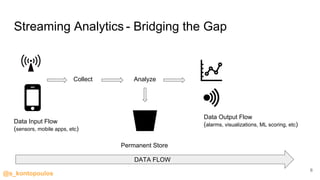



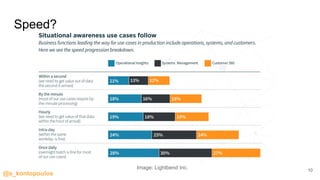
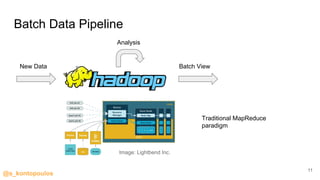
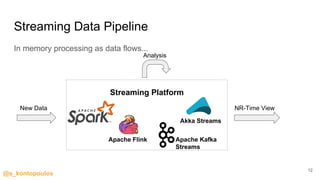





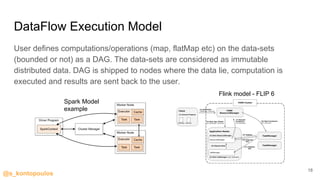

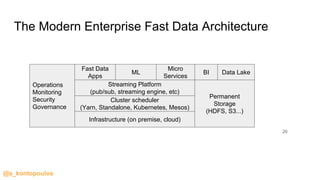
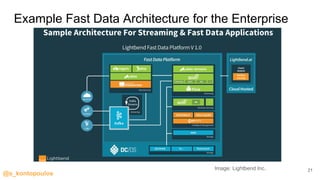



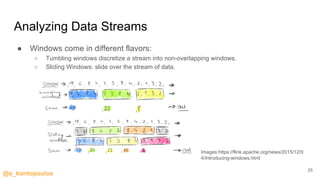

















This document provides an overview of streaming analytics, including definitions, common use cases, and key concepts like streaming engines, processing models, and guarantees. It also provides examples of analyzing data streams using Apache Spark Structured Streaming, Apache Flink, and Kafka Streams APIs. Code snippets demonstrate windowing, triggers, and working with event-time.








































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)

































