Downloaded 27 times









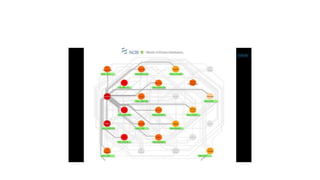
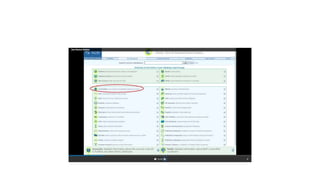
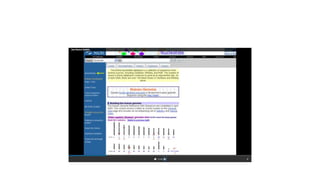
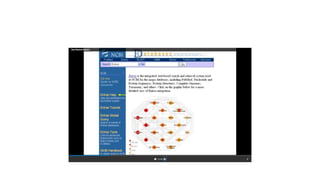
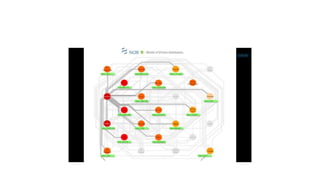




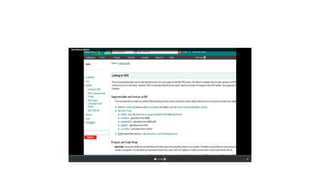
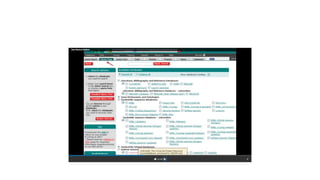





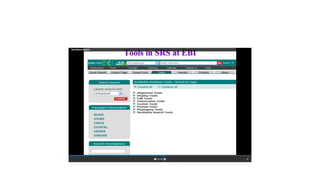

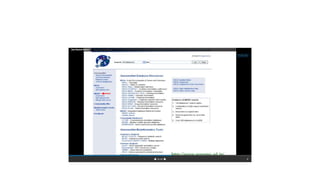
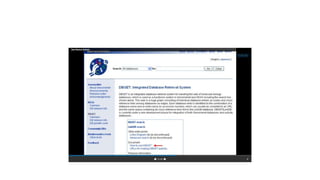










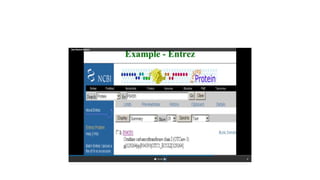
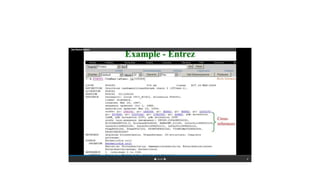
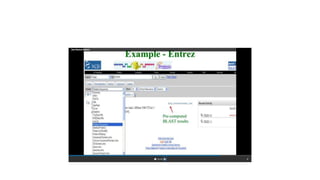






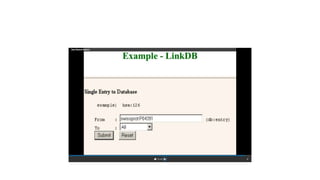
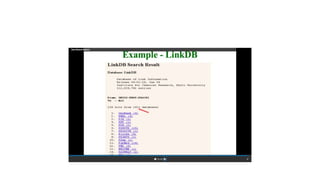
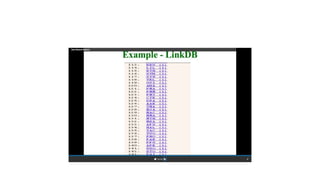


This document describes several text-based biological databases and how to search them. It discusses Entrez, which searches multiple databases and links related entries. It also describes the Sequence Retrieval System (SRS) which allows searching over 80 biological databases. Additionally, it outlines DBGET/LinkDB, an integrated system that searches about 20 databases and links results to associated information. The document provides an example of using each system to retrieve information on a specific protein entry.



































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











