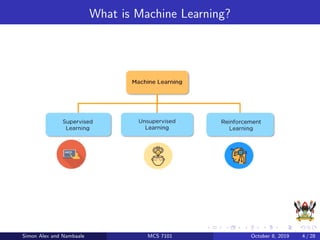
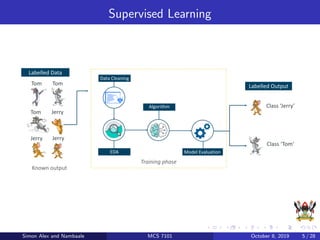
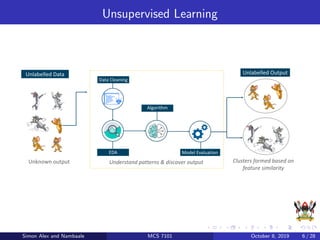
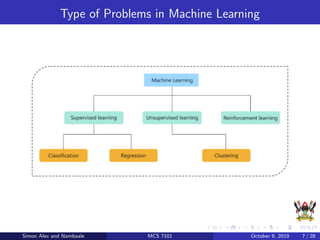
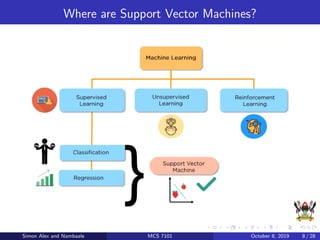
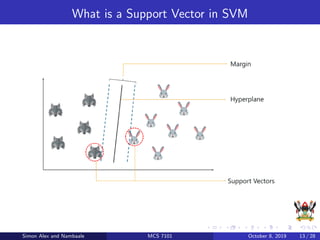
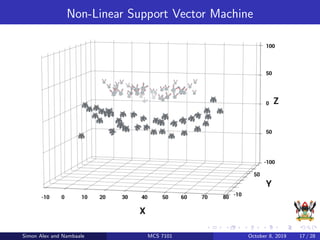
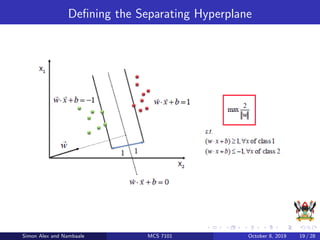
The document discusses support vector machines (SVM), a supervised machine learning algorithm. SVM can be used for both classification and regression problems by finding a hyperplane that separates classes with the maximum margin. It explains key SVM concepts like support vectors, kernels, hyperparameters like gamma and C, and evaluation techniques like cross-validation. Applications mentioned include text categorization, bioinformatics, face recognition and image classification.






















































![SUPPORT VECTOR MACHINE ( SVM)akjhgaskjdgjksdgajkgdagdaakg[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/supportvectormachinesvm1-240702134610-f37092eb-thumbnail.jpg?width=640&height=640&fit=bounds)





































