

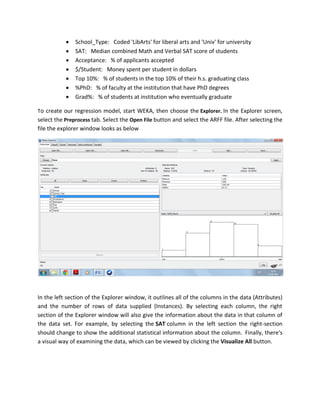
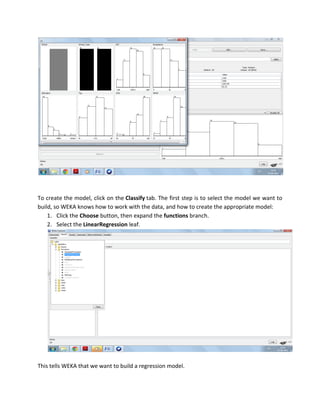
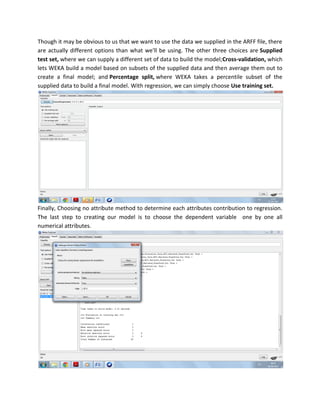
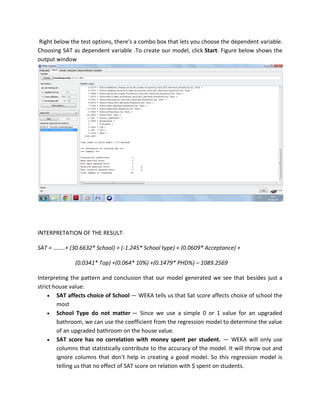
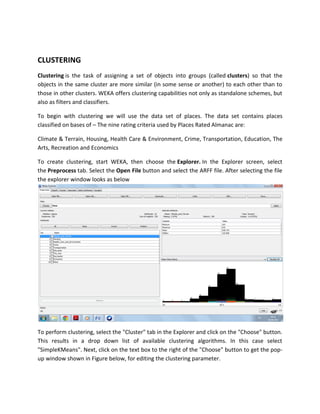
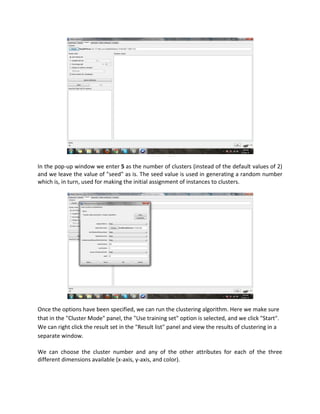
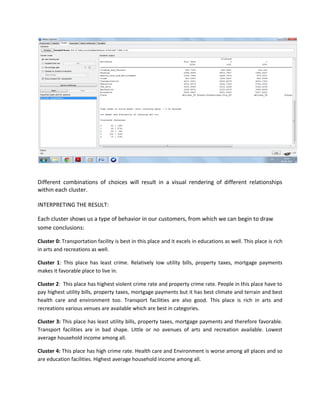

The document discusses the use of Weka, a data mining software from the University of Waikato, for business intelligence applications such as regression analysis and clustering. It details how to load data into Weka, create regression models using various attributes of colleges, and perform clustering on datasets of places based on multiple rating criteria. The results from these analyses provide insights into factors affecting college choice and characteristics of different locations.







































































