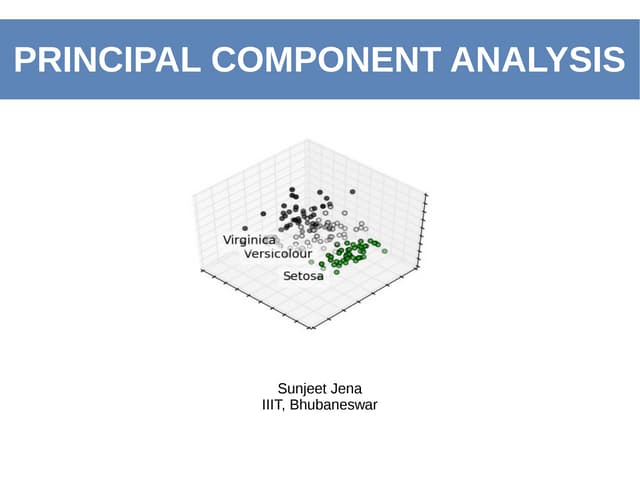
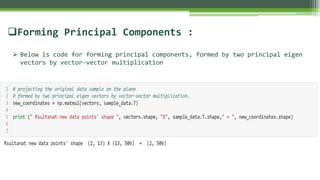
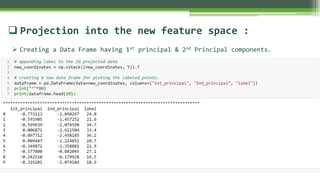
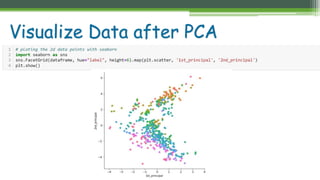
The document outlines the implementation of Principal Component Analysis (PCA) in Python for dimensionality reduction, particularly using the Boston housing dataset. It explains key concepts such as variance, covariance, and the steps involved in PCA, including standardizing data, calculating eigenvalues and eigenvectors, and forming principal components. Finally, it provides a link to the complete code for PCA implementation.













![1) [ True or False ] PCA can be used for projecting and visualizing data in lower
dimensions.
A. TRUE
B. FALSE
2) We apply PCA on image dataset.
A. TRUE
B. FALSE
3) PCA is based on variance maximization and distance minimization.
A. TRUE
B. FALSE
Implement PCA for number of components = 3 and then visualize data, also load
iris dataset and perform same task
Assessment and Evaluation
Ans:1-A,2-A,3-A](https://image.slidesharecdn.com/implementprincipalcomponentanalysispcain-190913185453/85/Implement-principal-component-analysis-PCA-in-python-from-scratch-19-320.jpg)