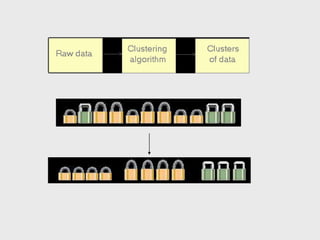
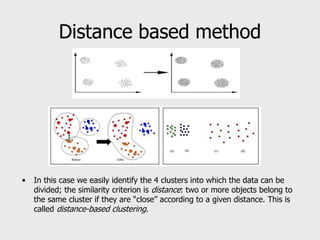
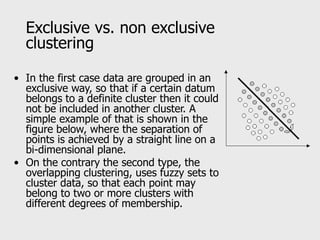
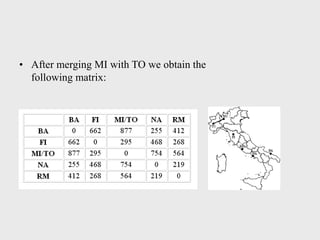
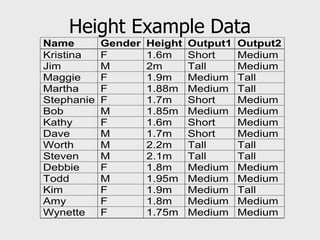
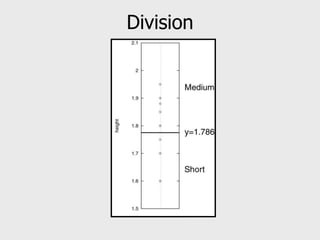
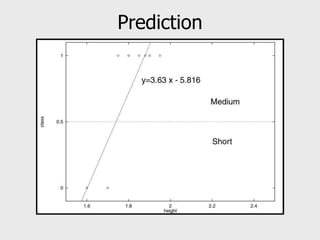
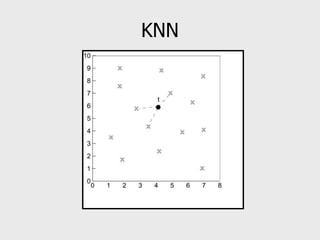
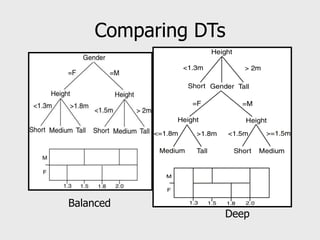
This document provides an overview of data mining techniques including clustering and classification. It defines clustering as the process of organizing objects into groups of similar objects. The document outlines several existing clustering methods such as hierarchical, partitioning, and probabilistic clustering. It also defines classification as assigning data to predefined categories or classes. Several classification examples are described along with techniques like decision trees, k-nearest neighbors, regression, and neural networks. The document concludes that these techniques are useful for simplifying data, detecting patterns, and performing supervised and unsupervised learning.













![Single-Linkage Clustering(hierarchical)
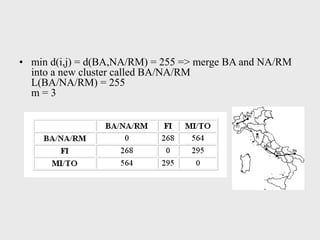
• The N*N proximity matrix is D = [d(i,j)]
• The clusterings are assigned sequence
numbers 0,1,......, (n-1)
• L(k) is the level of the kth clustering
• A cluster with sequence number m is
denoted (m)
• The proximity between clusters (r) and (s)
is denoted d [(r),(s)]
Mu-Yu Lu, SJSU](https://image.slidesharecdn.com/slide-tif311-dm-10-11-230430102755-7013ff27/85/Slide-TIF311-DM-10-11-ppt-16-320.jpg)
![The algorithm is composed of the
following steps:
• Begin with the disjoint clustering having level
L(0) = 0 and sequence number m = 0.
• Find the least dissimilar pair of clusters in the
current clustering, say pair (r), (s), according to
d[(r),(s)] = min d[(i),(j)]
where the minimum is over all pairs of clusters
in the current clustering.](https://image.slidesharecdn.com/slide-tif311-dm-10-11-230430102755-7013ff27/85/Slide-TIF311-DM-10-11-ppt-17-320.jpg)
![The algorithm is composed of the
following steps:(cont.)
• Increment the sequence number : m = m +1. Merge
clusters (r) and (s) into a single cluster to form the next
clustering m. Set the level of this clustering to
L(m) = d[(r),(s)]
• Update the proximity matrix, D, by deleting the rows and
columns corresponding to clusters (r) and (s) and adding
a row and column corresponding to the newly formed
cluster. The proximity between the new cluster, denoted
(r,s) and old cluster (k) is defined in this way:
d[(k), (r,s)] = min d[(k),(r)], d[(k),(s)]
• If all objects are in one cluster, stop. Else, go to step 2.](https://image.slidesharecdn.com/slide-tif311-dm-10-11-230430102755-7013ff27/85/Slide-TIF311-DM-10-11-ppt-18-320.jpg)


















































![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)



















