Downloaded 51 times










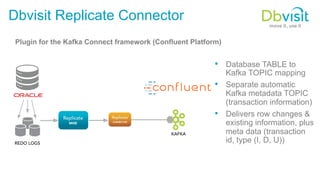






Dbvisit is a New Zealand-based company with offices worldwide that provides software to replicate data from Oracle databases in real-time to Apache Kafka. Their Dbvisit Replicate Connector is a plugin for Kafka Connect that allows minimal impact replication of database table changes to Kafka topics. The connector also generates metadata topics. Dbvisit focuses only on Oracle databases and replication, has proprietary log mining technology, and supports Oracle back to version 9.2. They have over 1,300 customers globally and offer perpetual or term licensing models for their replication software along with support plans. Dbvisit is a good fit for organizations using Oracle that want to offload reporting, enable real-time analytics, and integrate data into Kafka in a cost-effective manner



![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[db tech showcase Tokyo 2016] E22: Getting real time Oracle data into Kafka a...](https://cdn.slidesharecdn.com/ss_thumbnails/33xykpqpmbutrglvlbgg-signature-6edb48f833318dd95dfa58e0d889618cd124b3092d7873eb24c23621e1294cb3-poli-160815030056-thumbnail.jpg?width=640&height=640&fit=bounds)





















































