Download as PDF, PPTX







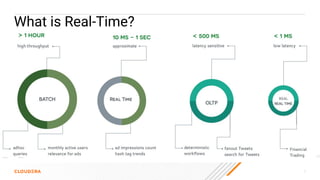
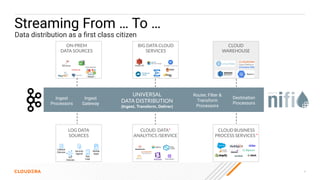

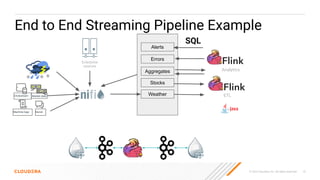

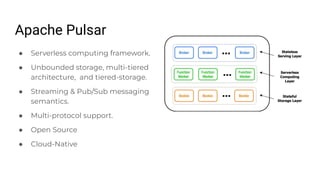
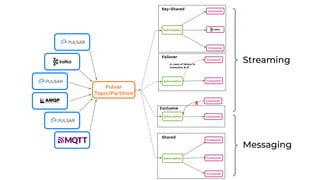
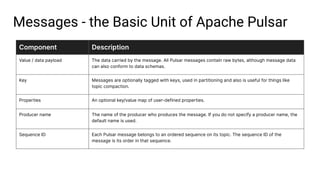





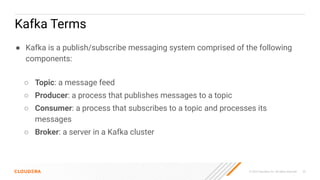
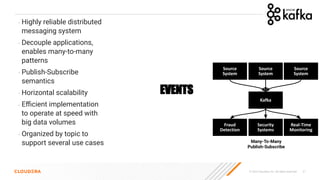

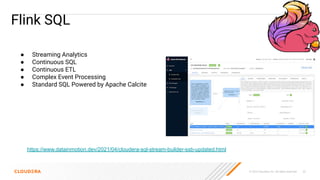



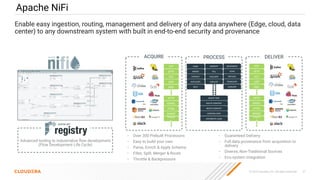
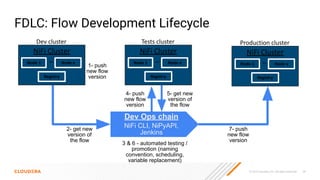





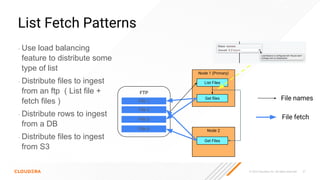

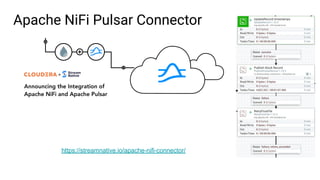
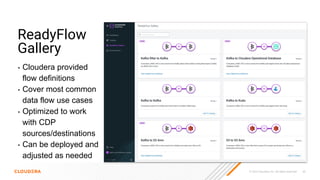
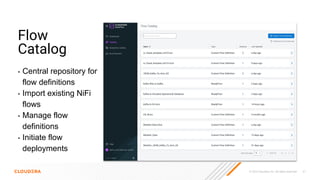









The document discusses the development and implementation of real-time data streaming applications using technologies like Apache Pulsar, Apache Kafka, and Apache NiFi. It covers concepts including data ingestion, processing pipelines, and the roles of key components in a streaming architecture. Additionally, it highlights best practices and resources for effectively managing data flows in a scalable, cloud-native environment.




















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)














