Download to read offline


































![Demo Walkthrough
{"entriesAddedCounter":1,"numberOfEntries":1,"totalSize":651,"curre
ntLedgerEntries":1,"currentLedgerSize":651,"lastLedgerCreatedTim
estamp":"2021-09-13T16:13:06.6-04:00","waitingCursorsCount":0,"pe
ndingAddEntriesCount":0,"lastConfirmedEntry":"7076:0","state":"L
edgerOpened","ledgers":[{"ledgerId":7076,"entries":0,"size":0,"offloa
ded":false,"underReplicated":false}],"cursors":{},"schemaLedgers":[],
"compactedLedger":{"ledgerId":-1,"entries":-1,"size":-1,"offloaded":fal
se,"underReplicated":false}}](https://image.slidesharecdn.com/cloudlunchandlearn-real-timestreaminginazure-211013183412/85/Cloud-lunch-and-learn-real-time-streaming-in-azure-65-320.jpg)



![Interested In Learning More?
Flink SQL Cookbook
The Github Source for Flink
SQL Demo
The GitHub Source for Demo
Manning's Apache Pulsar in
Action
O’Reilly Book
[10/21] Trino Summit
Resources Free eBooks Upcoming Events](https://image.slidesharecdn.com/cloudlunchandlearn-real-timestreaminginazure-211013183412/85/Cloud-lunch-and-learn-real-time-streaming-in-azure-70-320.jpg)




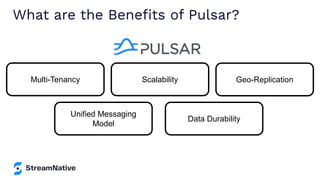
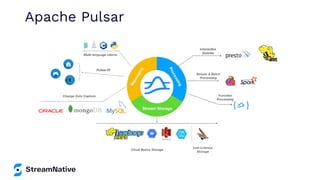
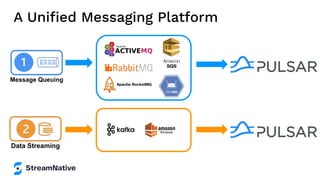
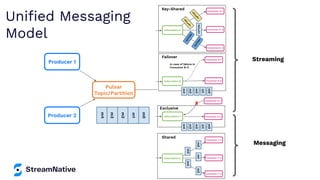
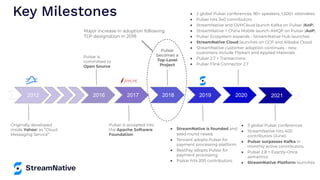
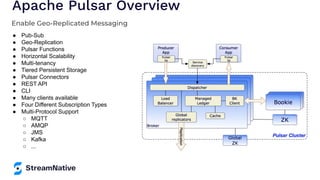
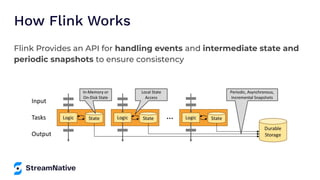
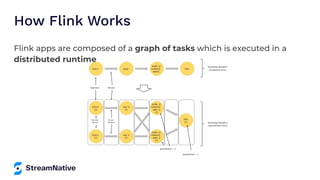
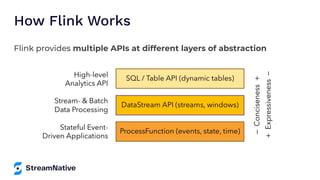
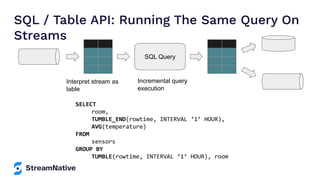
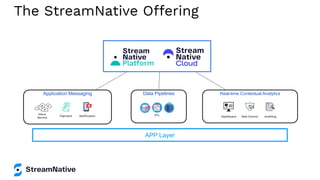
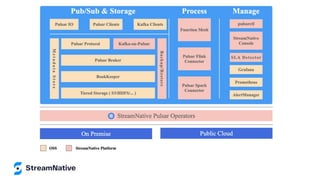
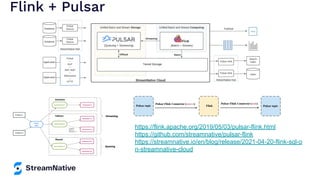
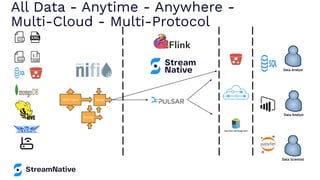
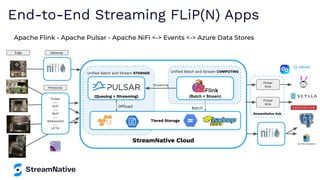
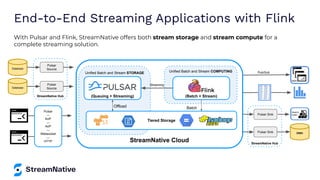
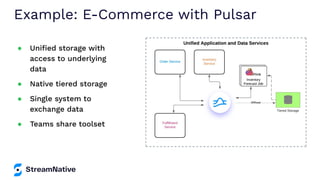
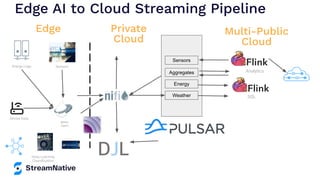
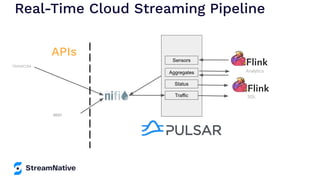
The document provides an overview of Apache Pulsar, a cloud-native event streaming platform, highlighting its features such as data durability, scalability, and unified messaging. It details Pulsar's architecture, benefits, and ecosystem, including support for various messaging protocols and integration with processing engines like Apache Flink and NiFi. The content aims to educate readers about the capabilities and real-time streaming solutions offered by Pulsar and its community resources.





























![[AerospikeRoadshow] Apache Pulsar Unifies Streaming and Messaging for Real-Ti...](https://cdn.slidesharecdn.com/ss_thumbnails/aerospikeroadshowapachepulsarunifiesstreamingandmessagingforreal-timedata2-221103174214-18ce3fa2-thumbnail.jpg?width=640&height=640&fit=bounds)

























































