Download as PDF, PPTX














![Flink
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
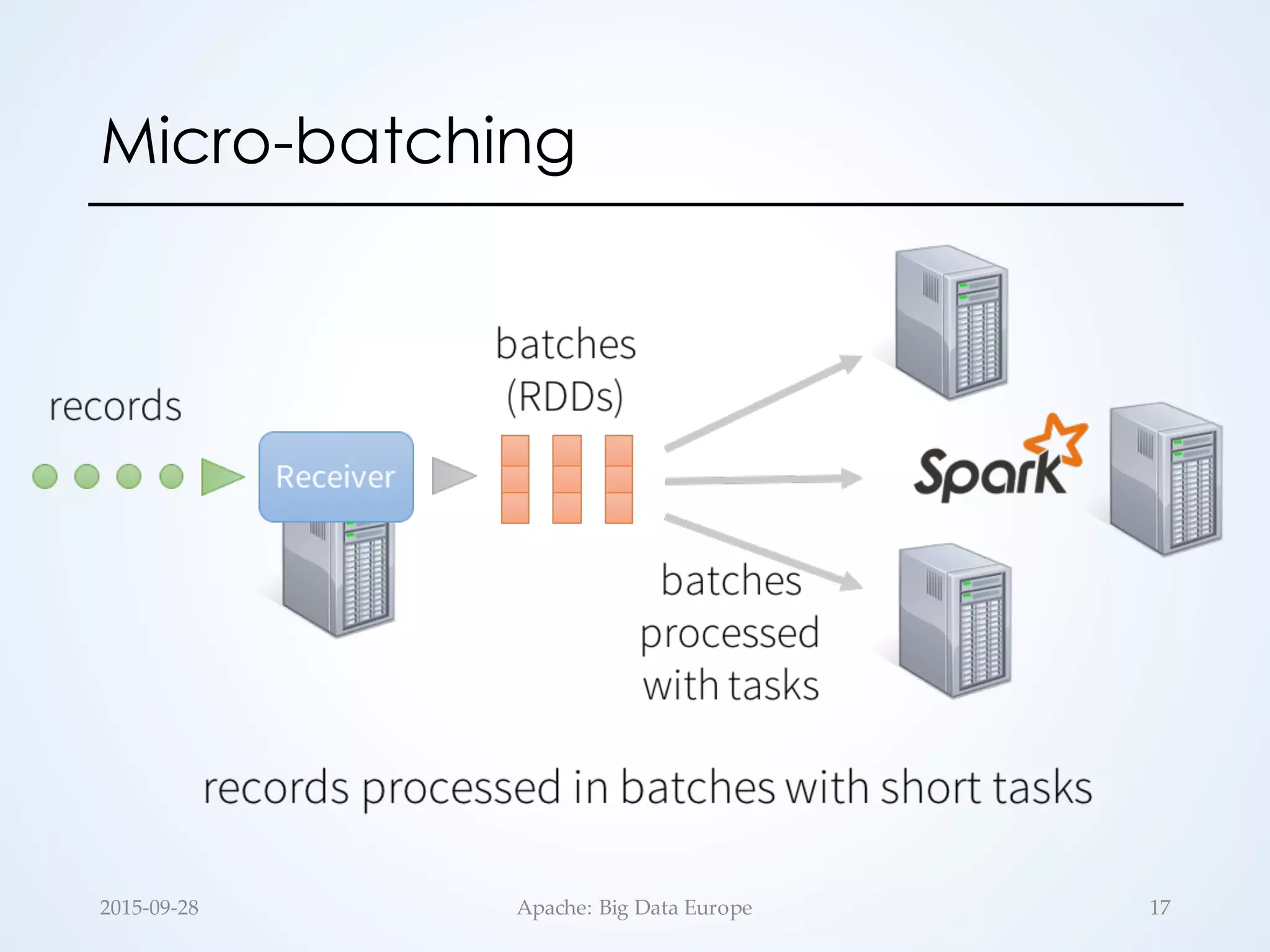
Rolling word count
Window word count
252015-‐‑09-‐‑28 Apache: Big Data Europe](https://image.slidesharecdn.com/opensourcestreaming-150928093329-lva1-app6891/75/Large-Scale-Stream-Processing-in-the-Hadoop-Ecosystem-25-2048.jpg)



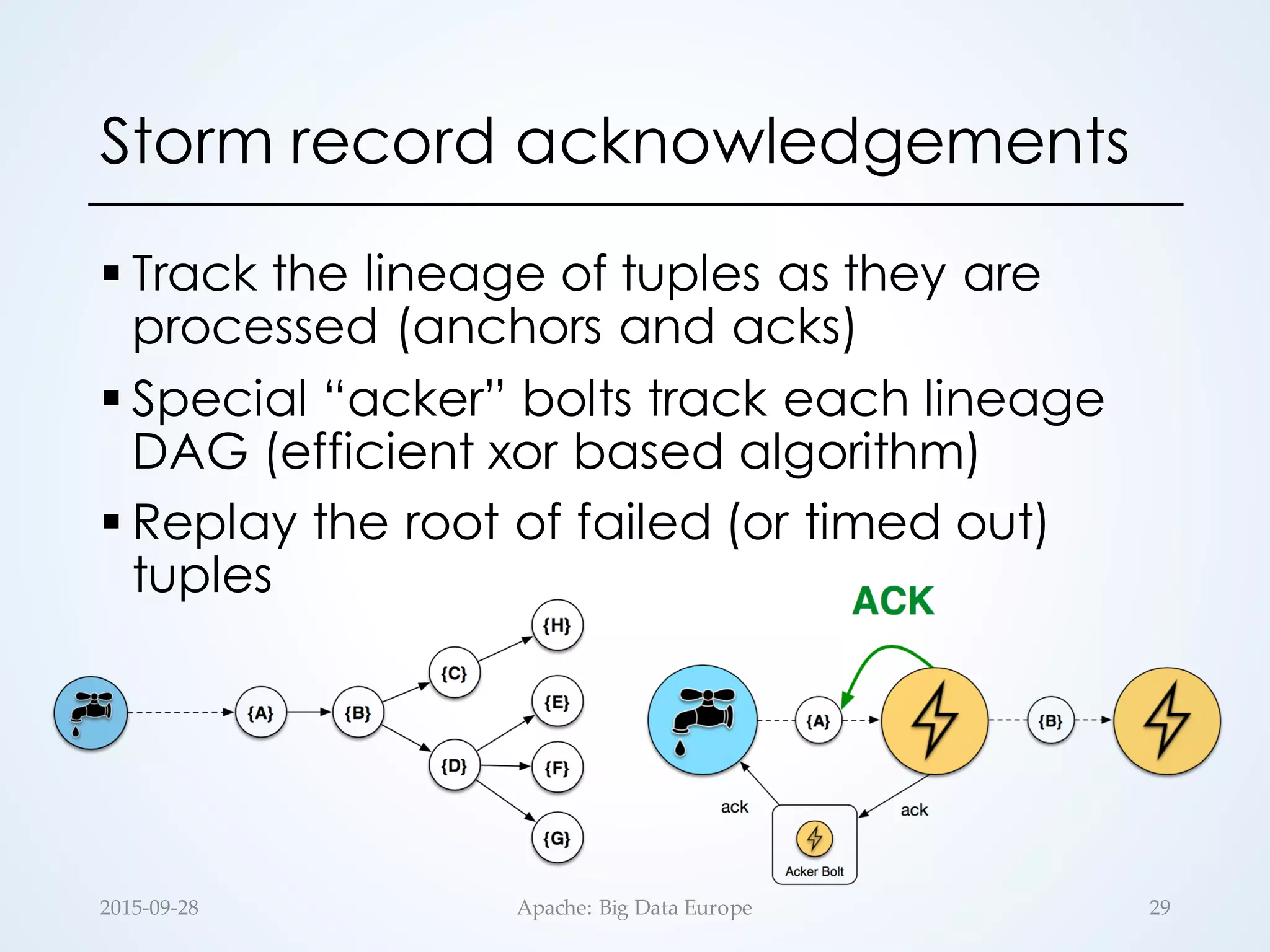
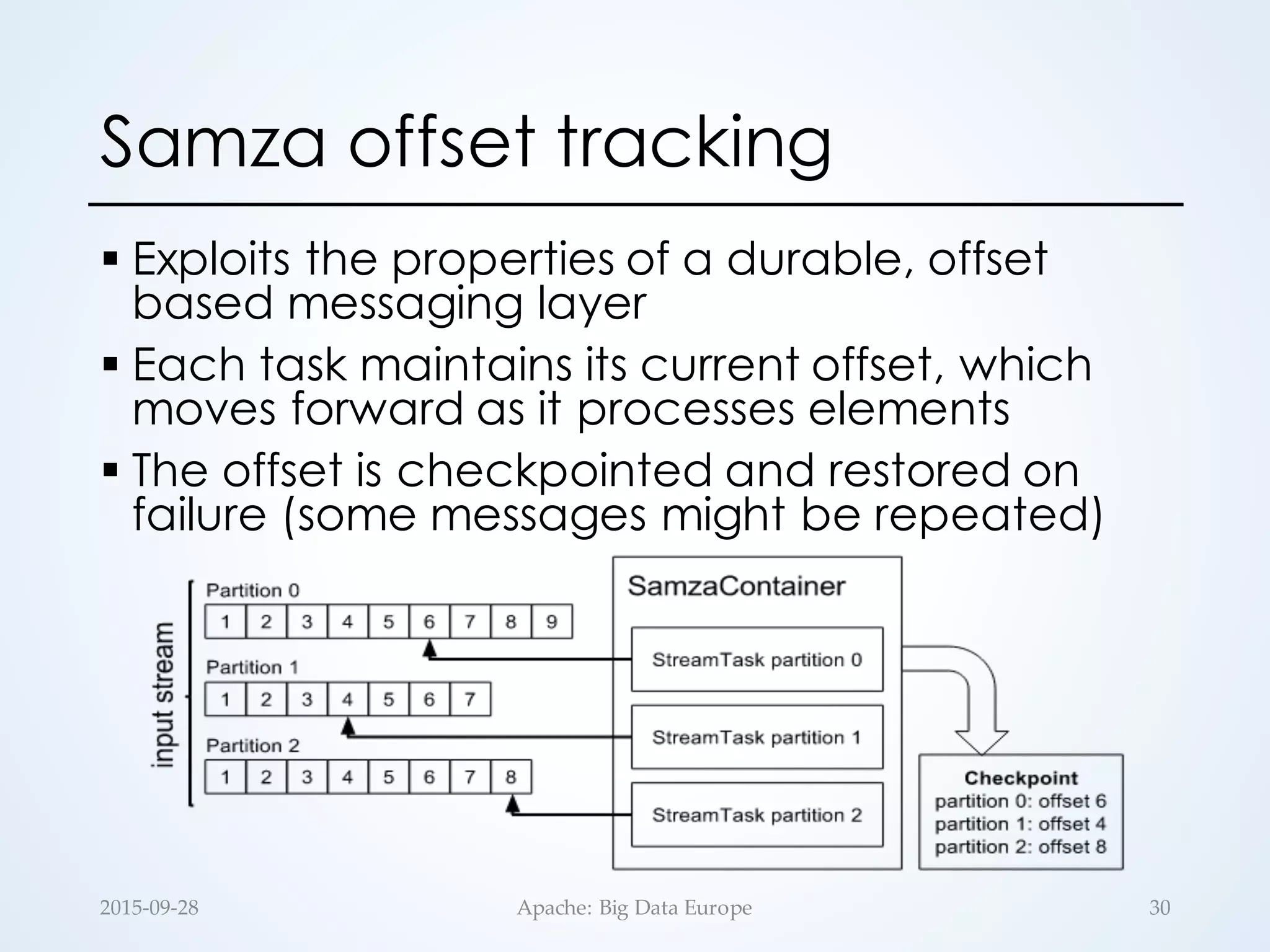



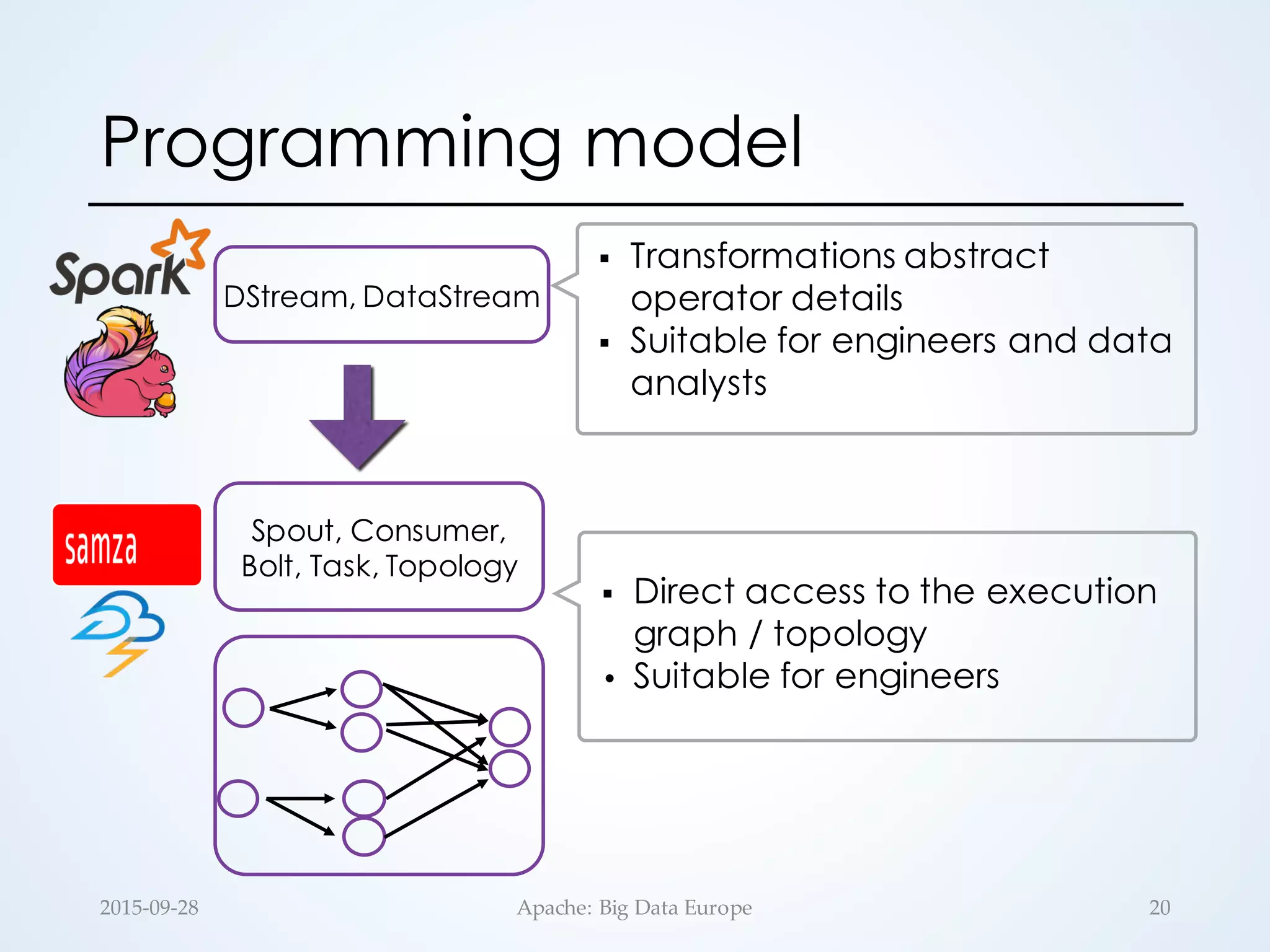
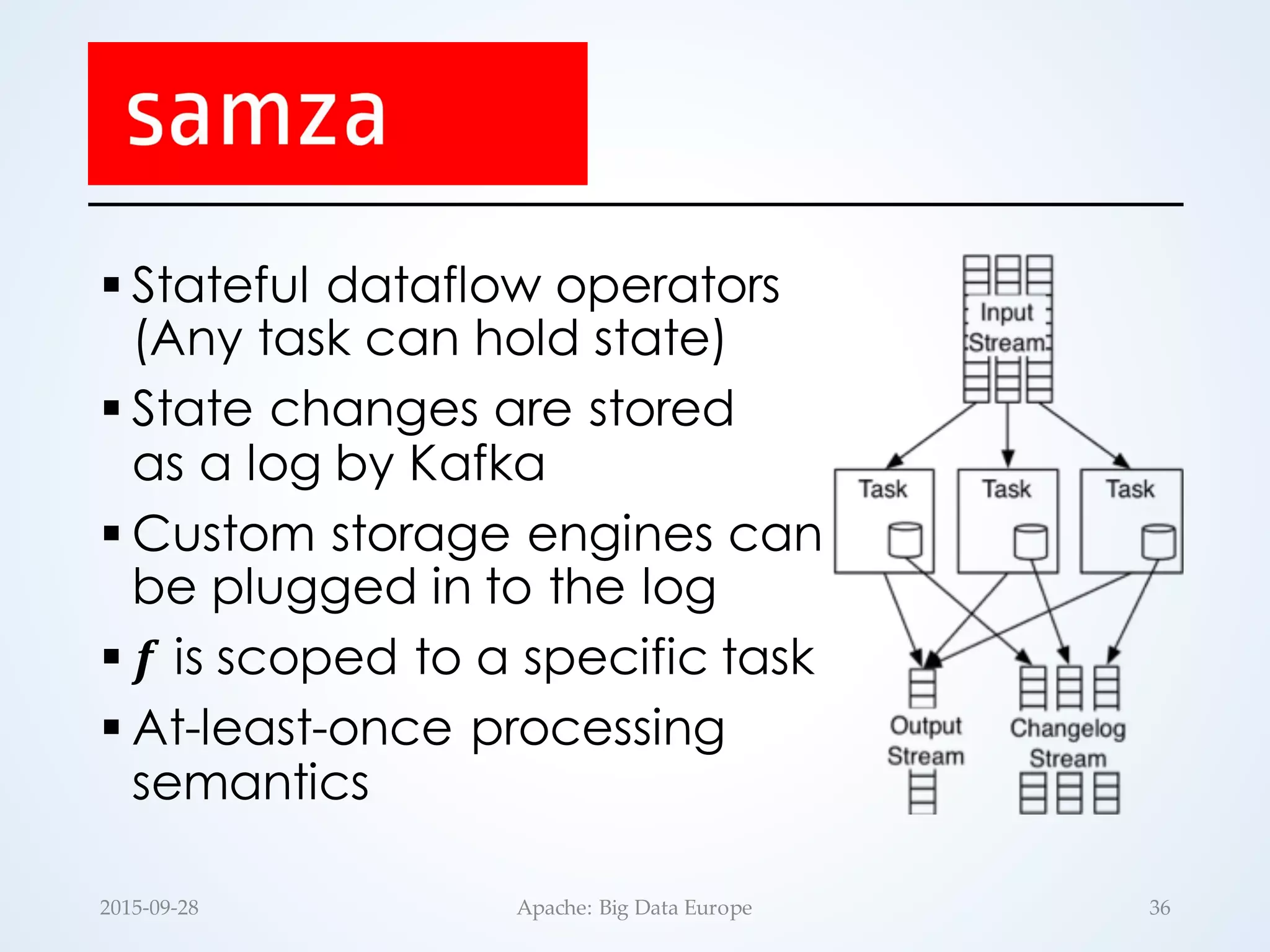
![§ Stateless runtime by design
• No continuous operators
• UDFs are assumed to be stateless
§ State can be generated as a separate
stream of RDDs: updateStateByKey(…)
𝒇:
𝑺𝒆𝒒[𝒊𝒏 𝒌], 𝒔𝒕𝒂𝒕𝒆 𝒌 ⟶ 𝒔𝒕𝒂𝒕𝒆.
𝒌
§ 𝒇 is scoped to a specific key
§ Exactly-once semantics
35Apache: Big Data Europe2015-‐‑09-‐‑28](https://image.slidesharecdn.com/opensourcestreaming-150928093329-lva1-app6891/75/Large-Scale-Stream-Processing-in-the-Hadoop-Ecosystem-35-2048.jpg)



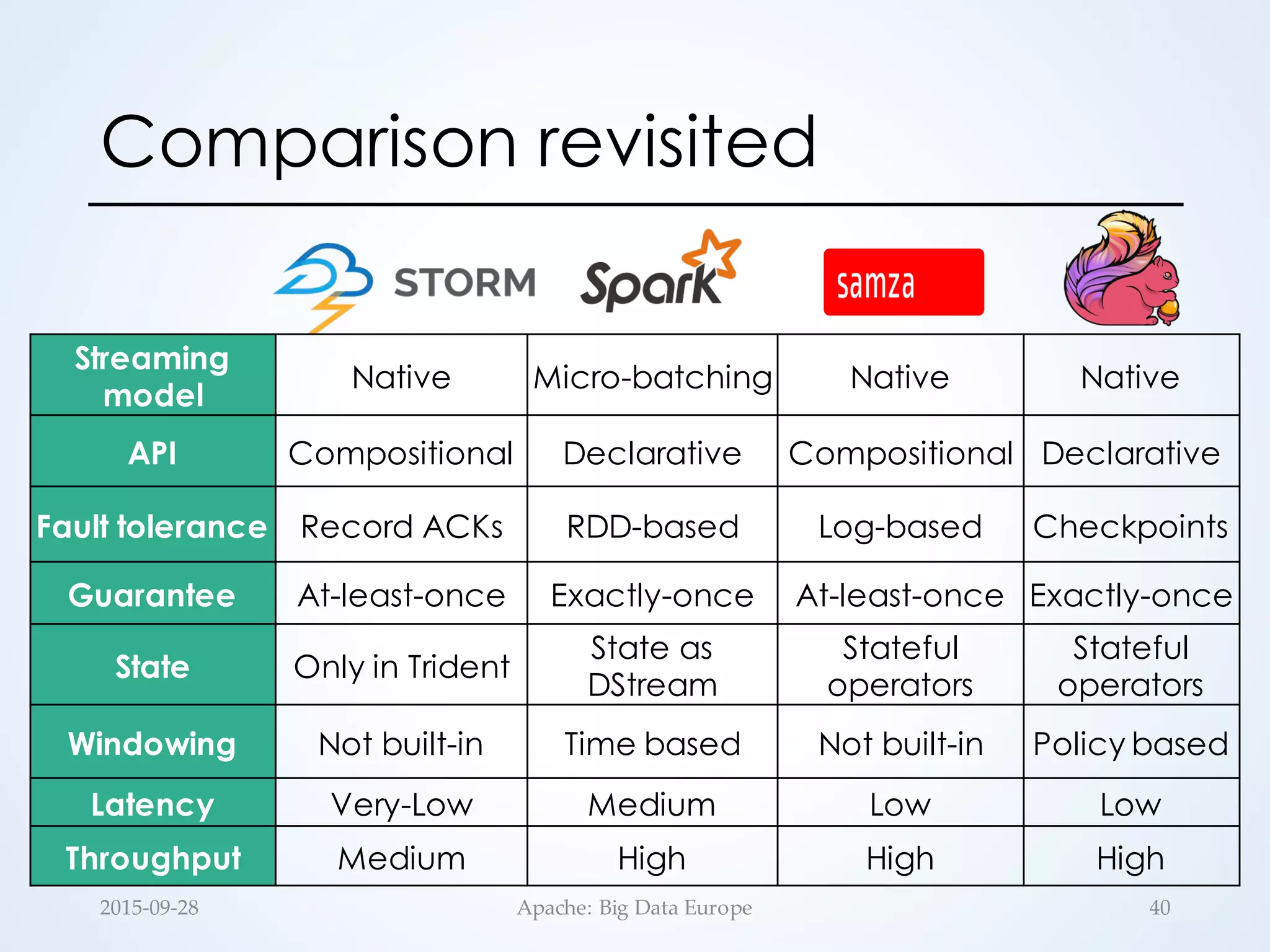




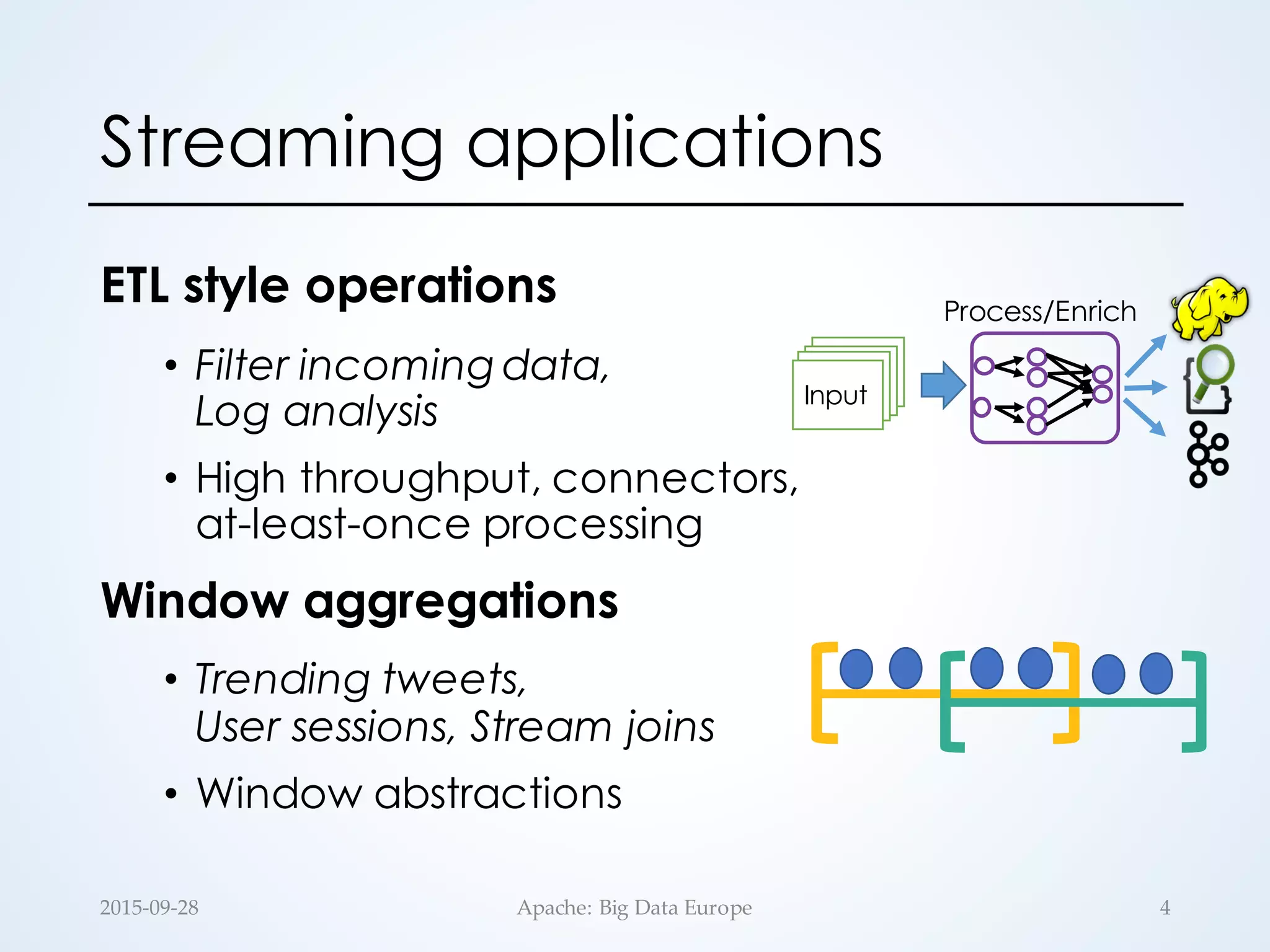
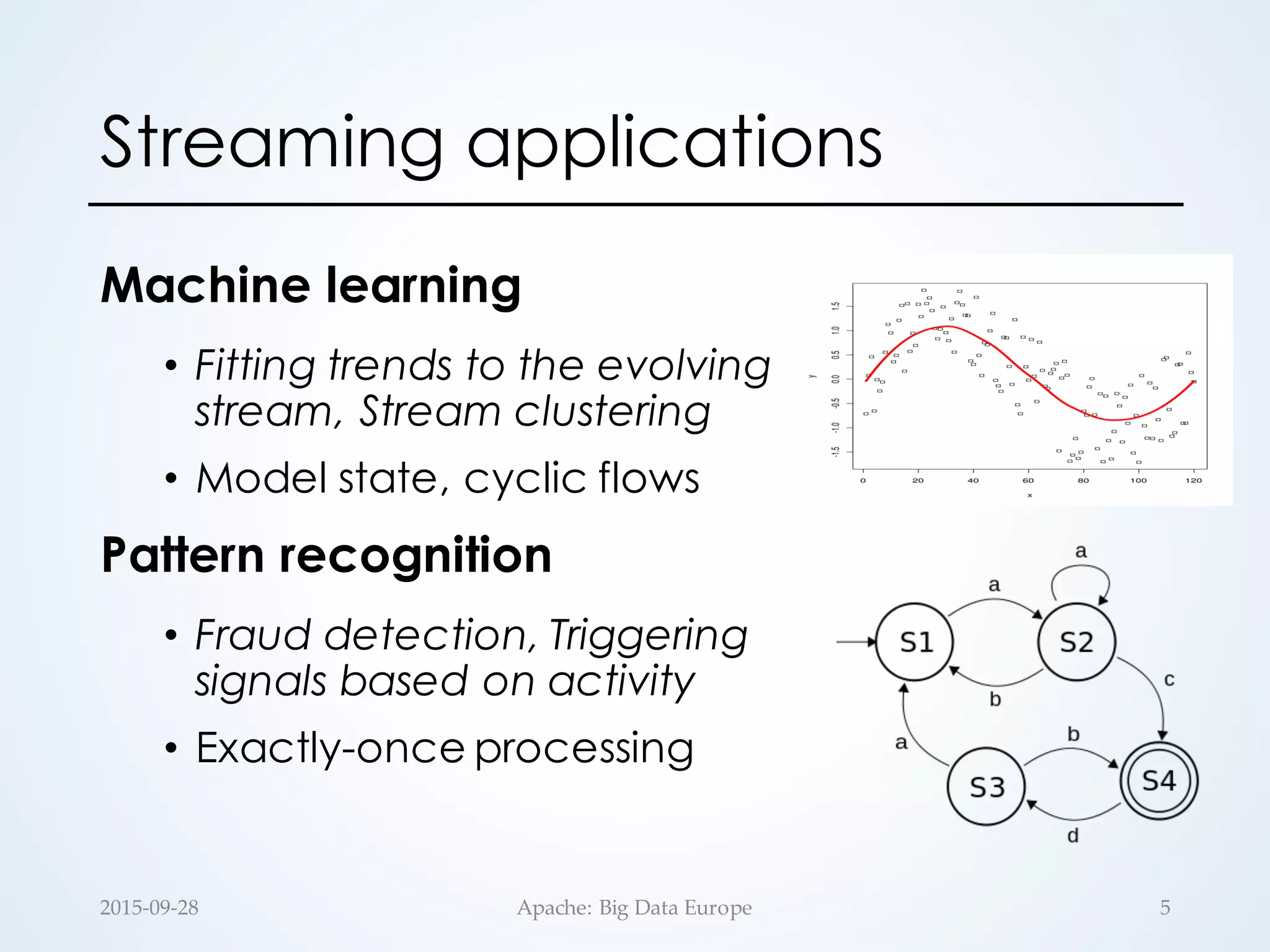
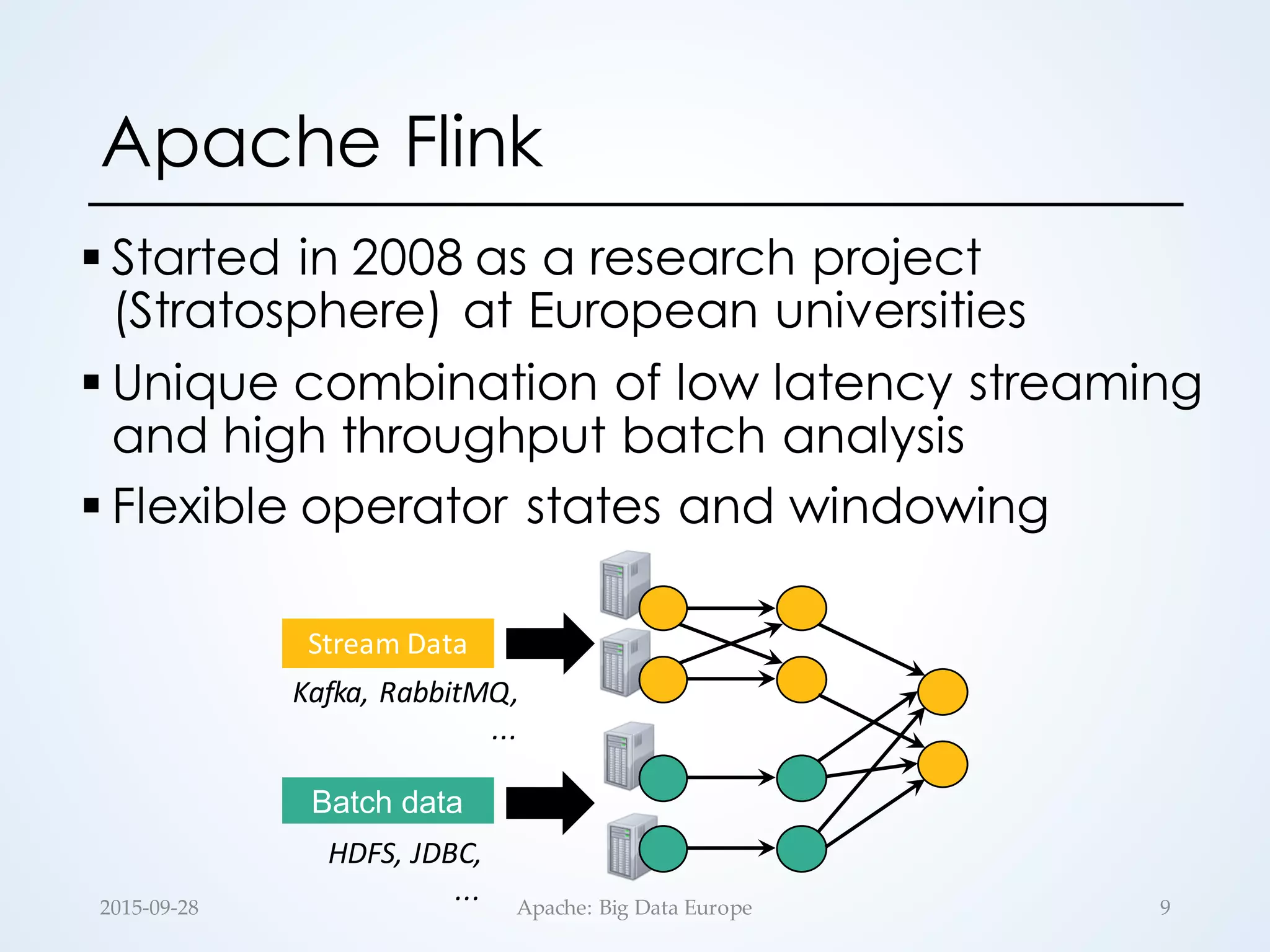
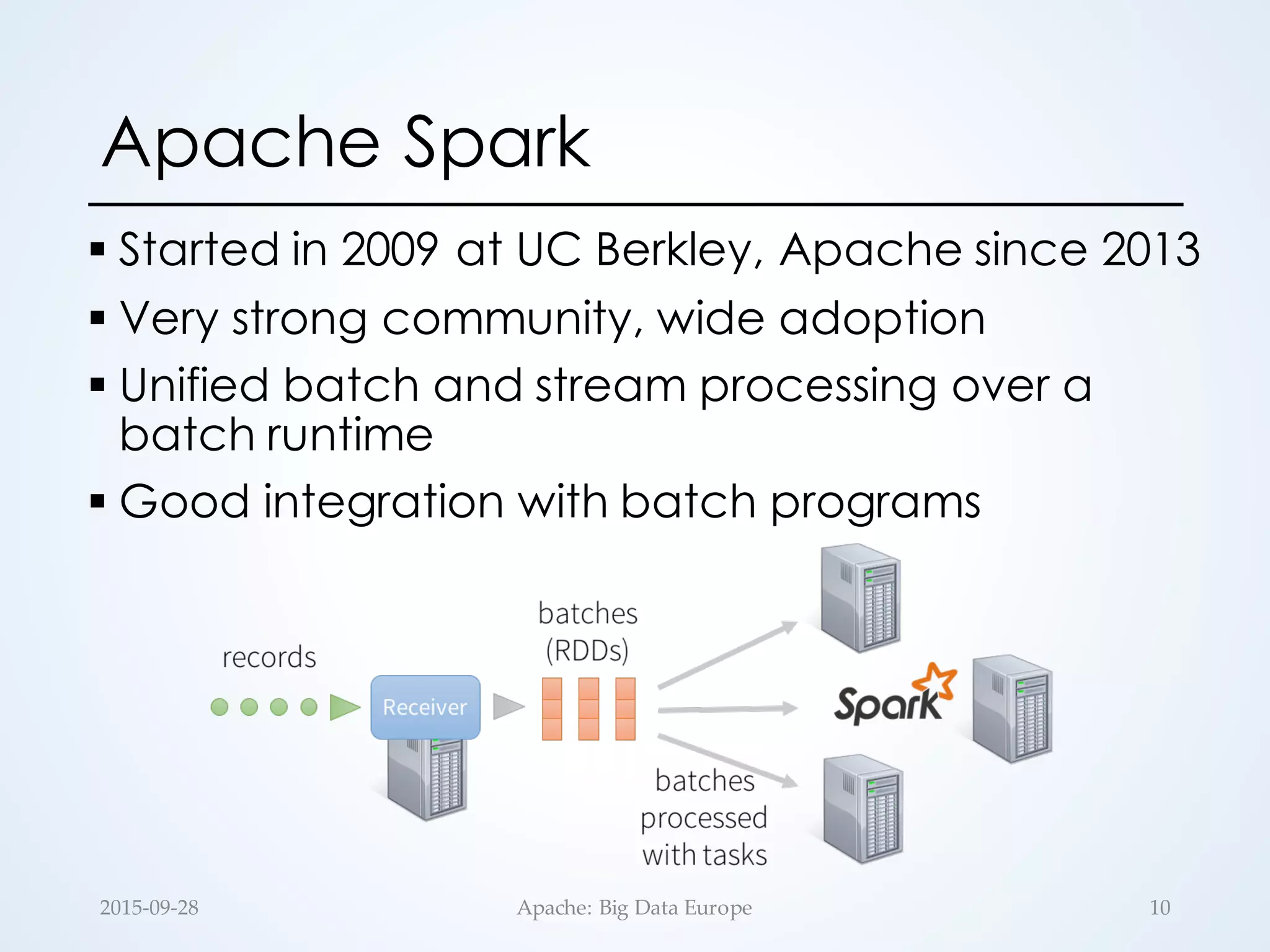
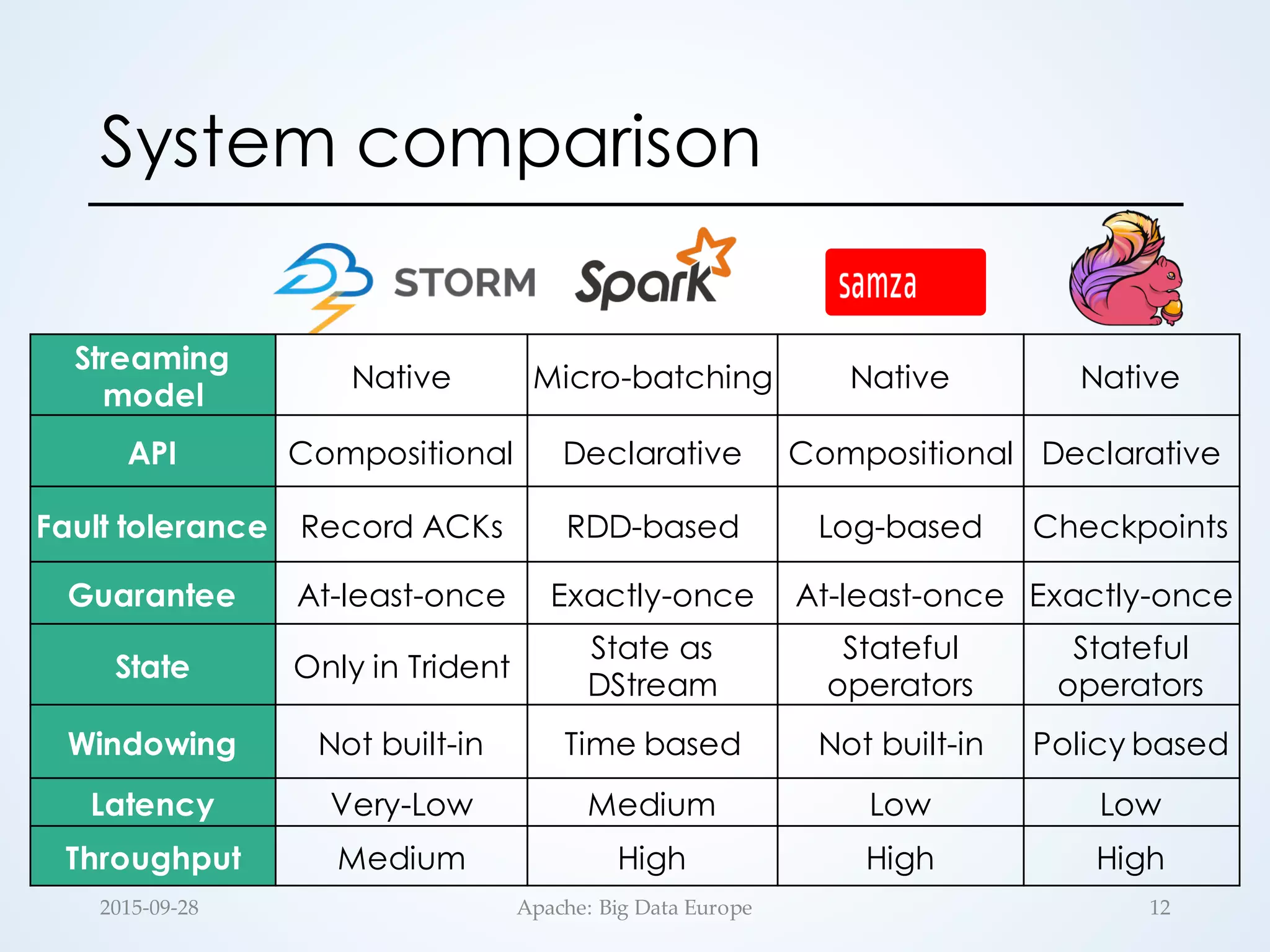
The document discusses large-scale stream processing within the Hadoop ecosystem, focusing on various open-source stream processors such as Apache Storm, Flink, Spark, and Samza. It highlights the differences in runtime architecture, programming models, fault tolerance, stateful processing, and applications of each system. Ultimately, it emphasizes the diversity of streaming applications and the need for choosing the right framework based on specific requirements.






































































![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

