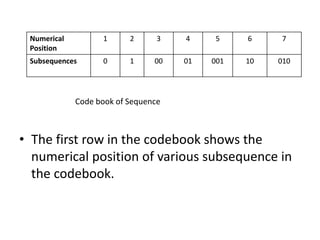
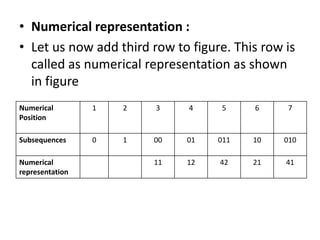
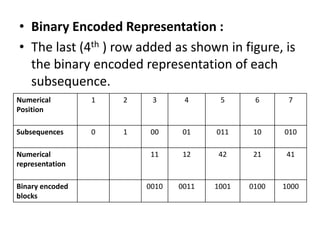
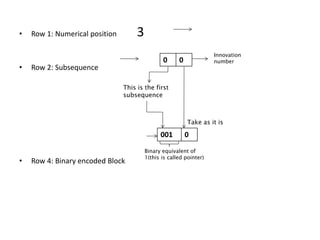
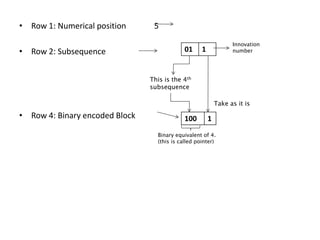
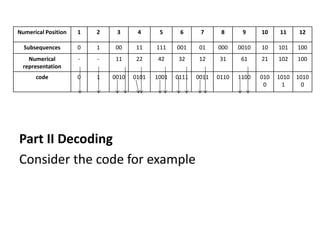
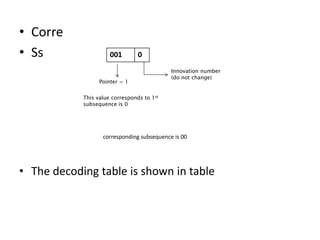
The document provides an introduction to Lempel-Ziv (LZ) algorithms, specifically LZ77 and LZ78, which are lossless data compression techniques. It explains the principles of these algorithms, detailing how they encode and decode data by utilizing previously seen sequences to create a codebook of subsequences. The document also compares the efficiency of LZ algorithms to Huffman coding, illustrating the advantages of LZ in terms of adaptability and implementation simplicity.