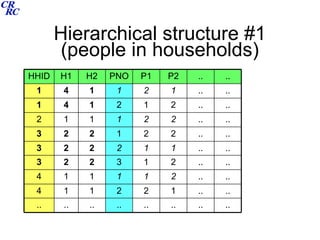
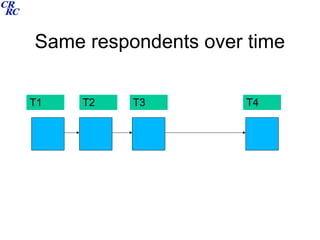
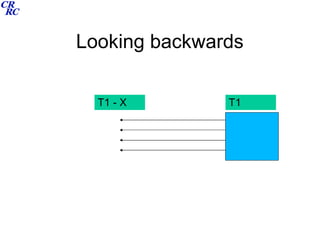
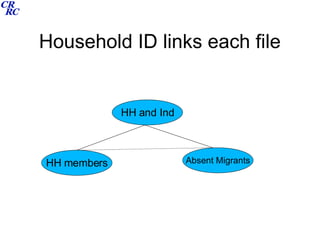
This document summarizes a course on data archiving and processing. The course covers archiving theory and practices, data structures and processing, survey documentation, and user guides. It discusses different types of survey designs including cross-sectional, panel, cohort, and retrospective designs. It provides examples of deriving variables, creating analytic files, data linkage for hierarchical and longitudinal data, and exercises for participants. The intended outcomes are understanding the need to archive data, differentiating data types and structures, using software to process and analyze data, and appreciating user guides.














































































































![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)


























