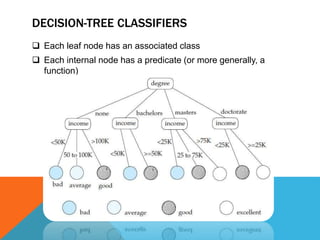
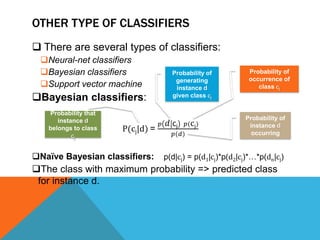
The document discusses various data mining and machine learning techniques. It describes data mining as the process of analyzing large databases to find useful patterns. It discusses classification, decision trees, regression, support vector machines, and validating classifiers. Classification involves predicting which class new data belongs to, based on attributes. Decision trees use a greedy algorithm to recursively split data into pure subsets. Regression predicts a numeric value. Support vector machines find the maximum margin separating hyperplane. Validating classifiers measures accuracy on test data.















































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)


































