The document discusses count-distinct algorithms for estimating the cardinality of large data streams. It provides an overview of the history of count-distinct algorithms, from early linear counting approaches to modern algorithms like LogLog counting and HyperLogLog counting. The document then describes the basic ideas, algorithms, and implementations of LogLog counting and HyperLogLog counting. It analyzes the performance of these algorithms and discusses open issues like how to handle small and large cardinalities more accurately.
















![HYPERLOGLOG COUNTING
HYPERLOGLOG COUNTING
LOGLOG COUNTING algorithm with Harmonic Mean
E := ↵mm2
1
m
P
j M(j)
1
m
(M(1)
+ M(2)
+ · · · + M(m)
)
Arithmetic mean
m
1
2M(1) + 1
2M(2) + · · · + 1
2M(m)
E := ↵mm2
0
@
mX
j=1
2 M[j]
1
A
1
Harmonic Mean](https://image.slidesharecdn.com/project-180219215947/75/Count-Distinct-Problem-20-2048.jpg)
![3. HYPERLOGLOG COUNTING algorithm
HYPERLOGLOG COUNTING( input : multiset of items):
assume with
initialize a collection of integers, to ;
for do
set (value of first k bits in base 2)
set (the binary address determined
by the first bits of )
set set
compute
return
m = 2b b 2 Z>0
m M[1], ..., M[m] 1
v 2 M
x := h(v)
j = 1 + hx1x2...xbi2
b x
w := xb+1xb+2...; M[j] := max(M[j], ⇢(!))
Z :=
0
@
mX
j=1
2 M[j]
1
A
1
E := ↵mm2
Z
HYPERLOGLOG COUNTING
M](https://image.slidesharecdn.com/project-180219215947/75/Count-Distinct-Problem-21-2048.jpg)

![if then
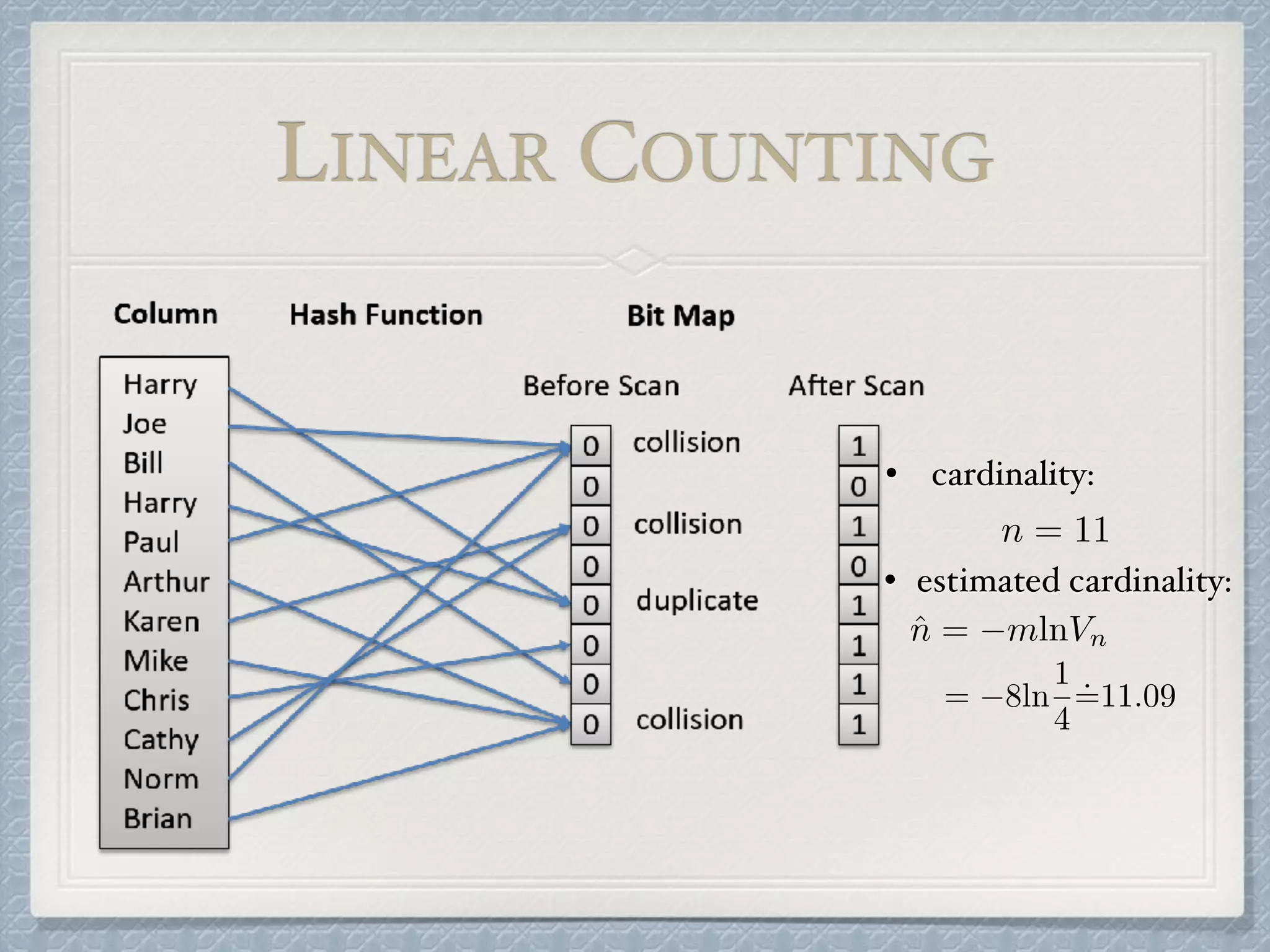
Let V be the number of registers equal to 0.
V ~=0 then set E := LinearCounting(m, V )
else
do nothing
end
if then
E := E
if
end
return E
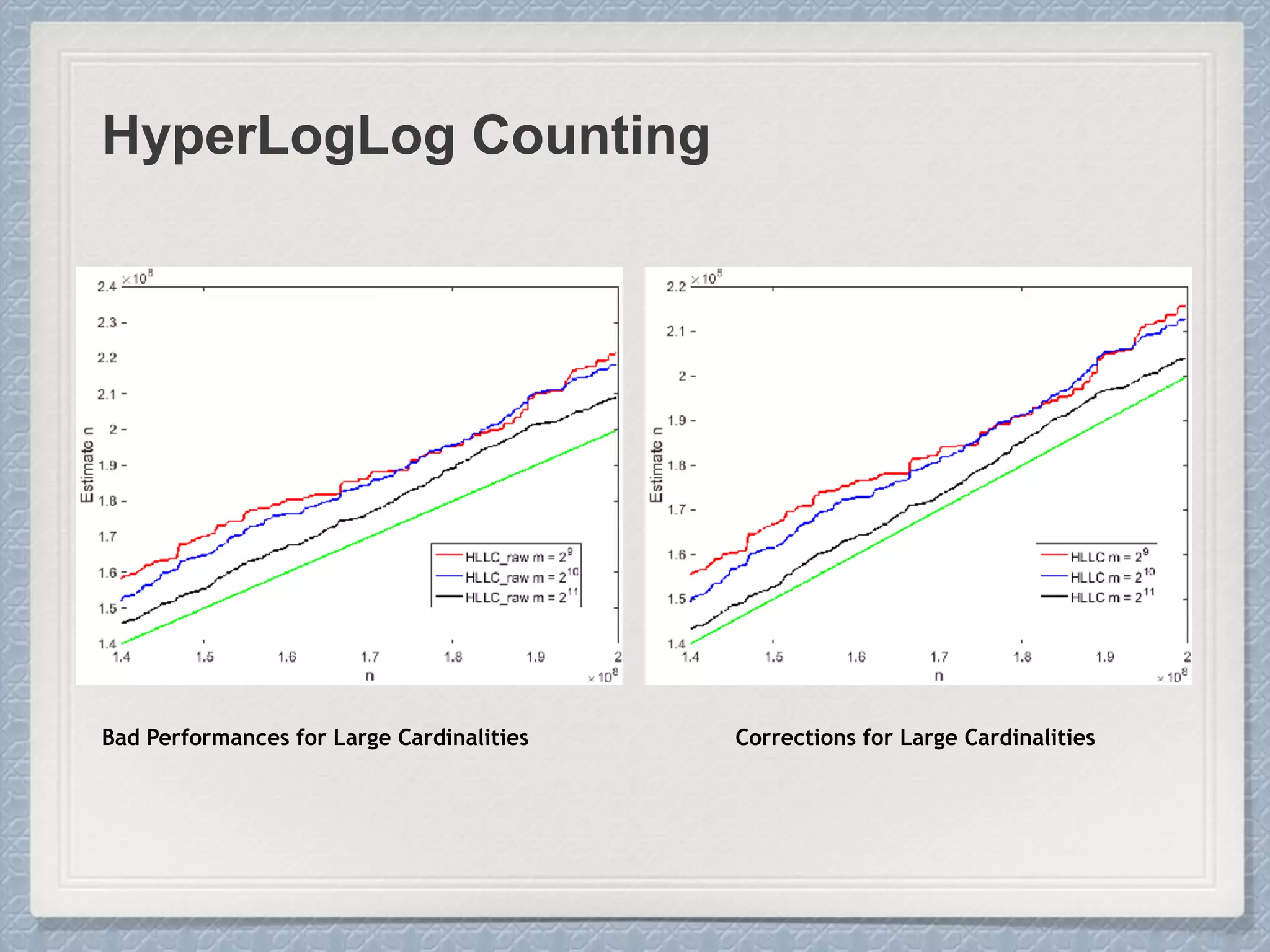
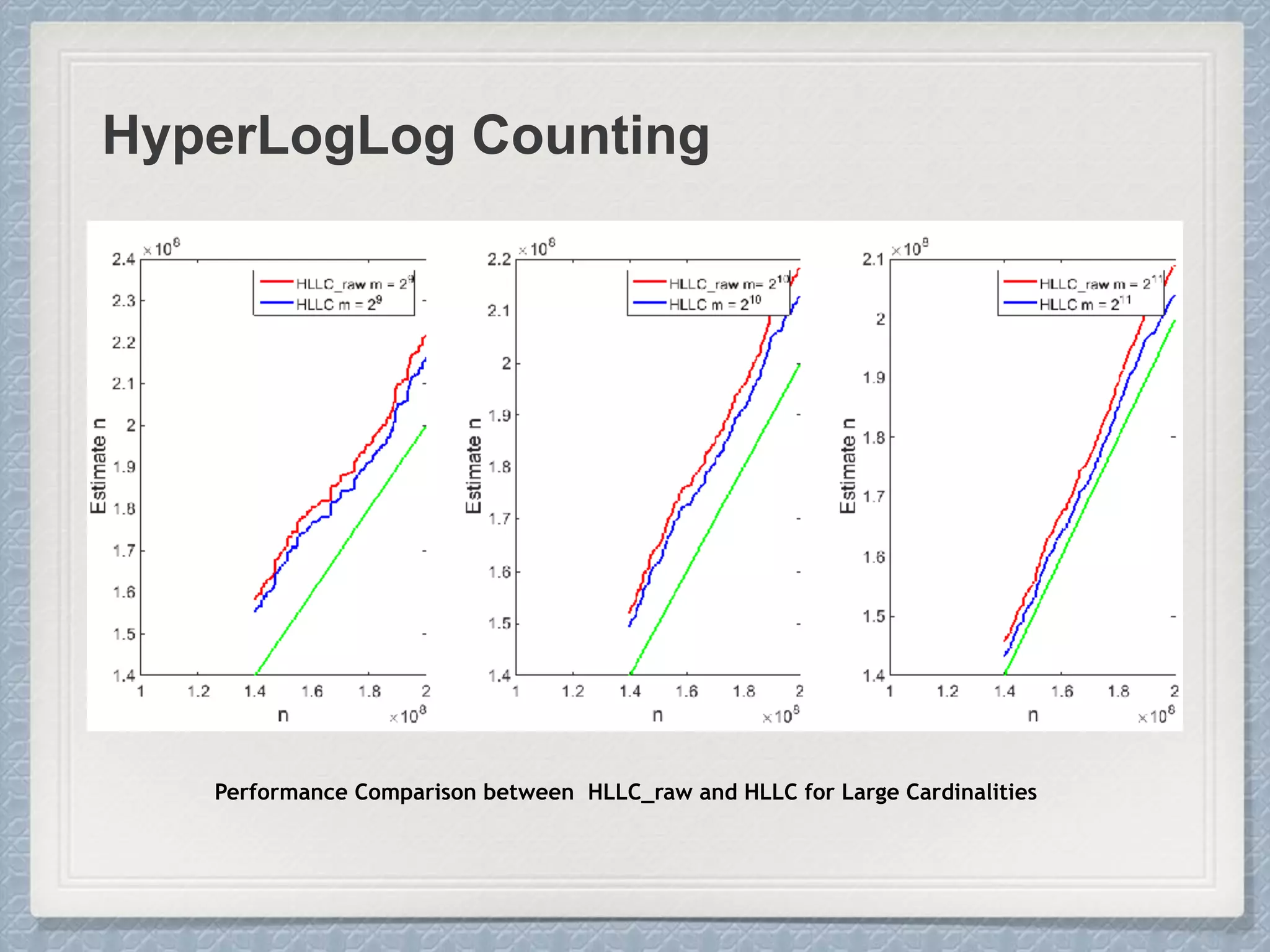
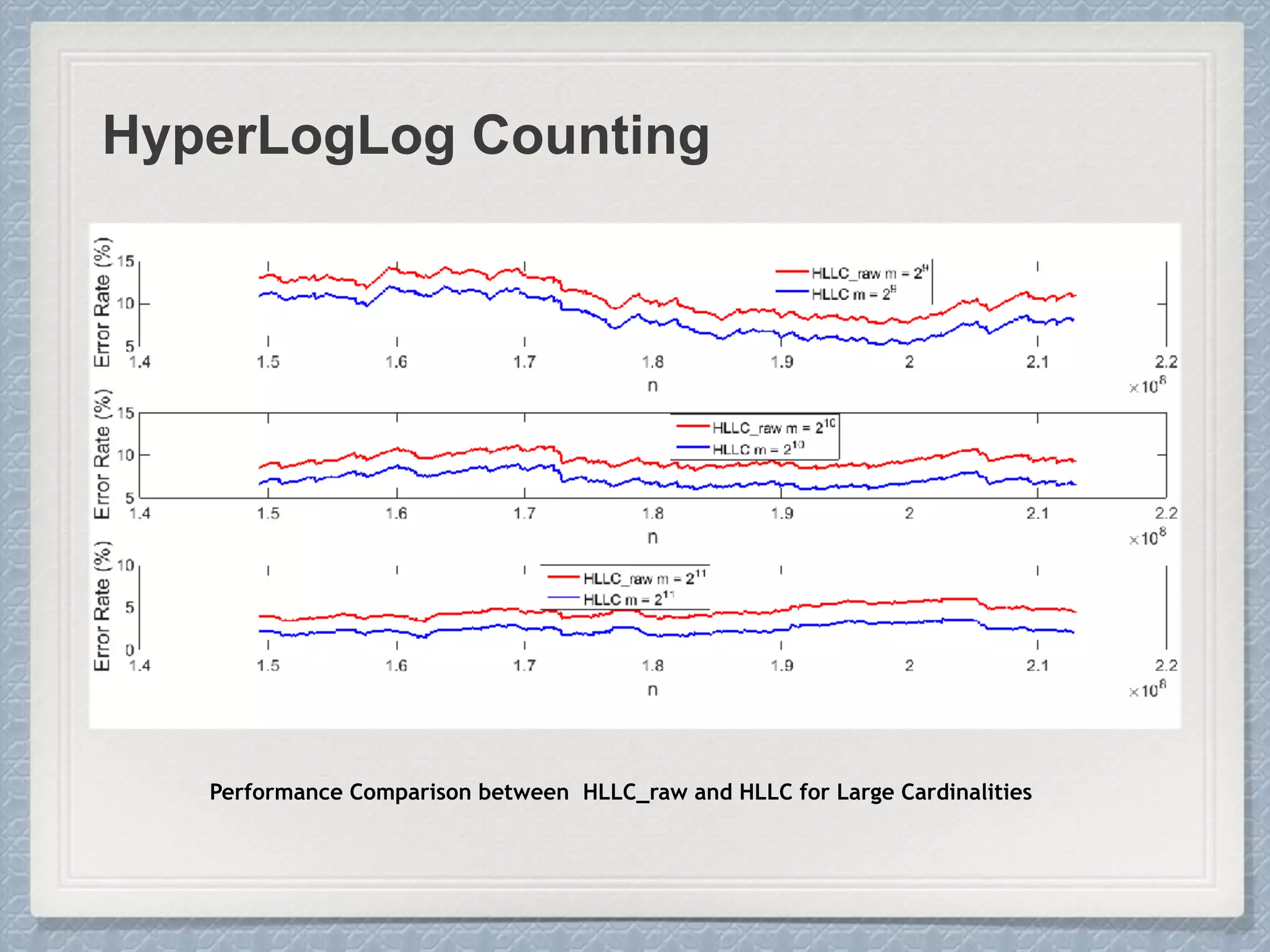
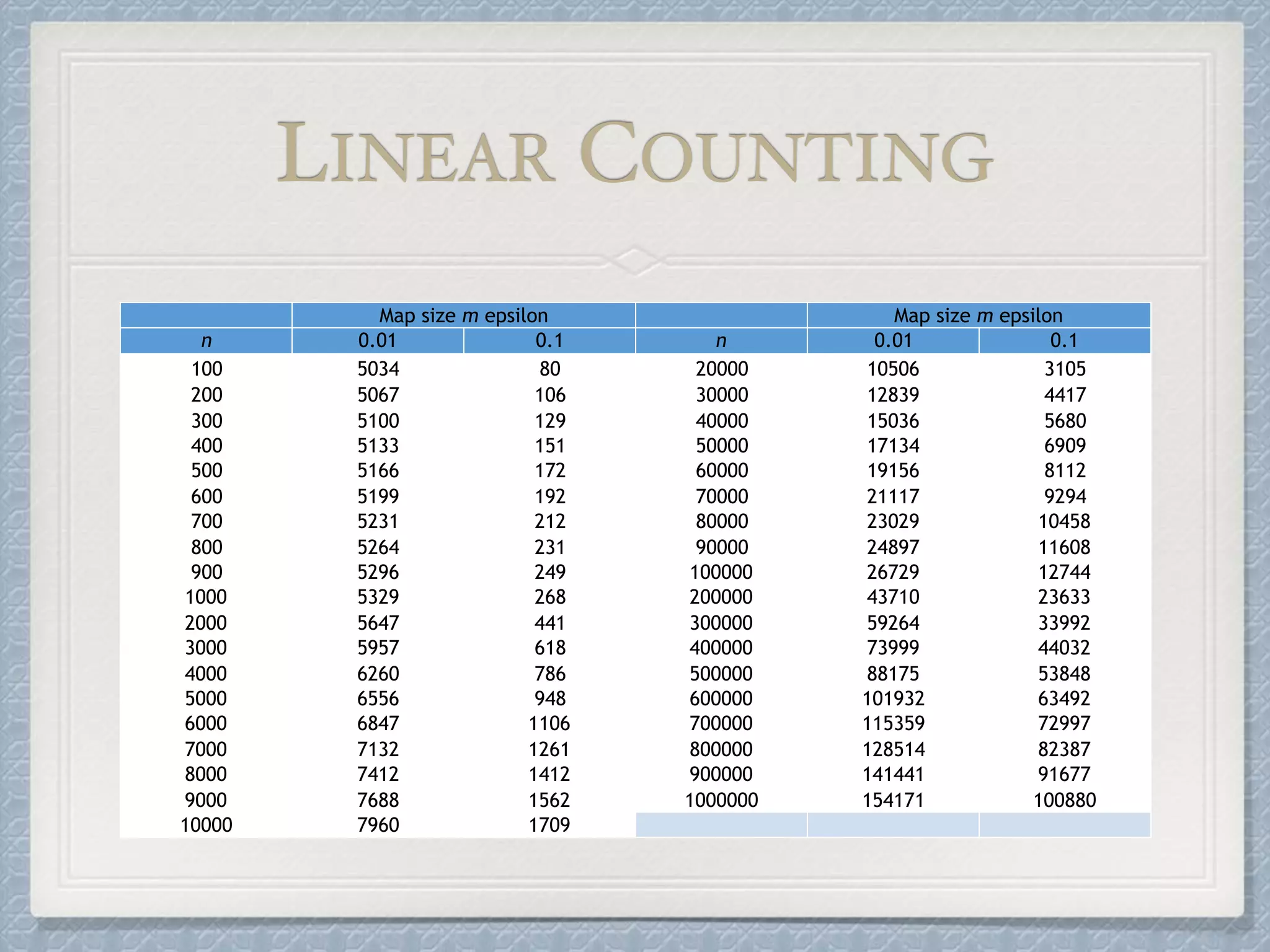
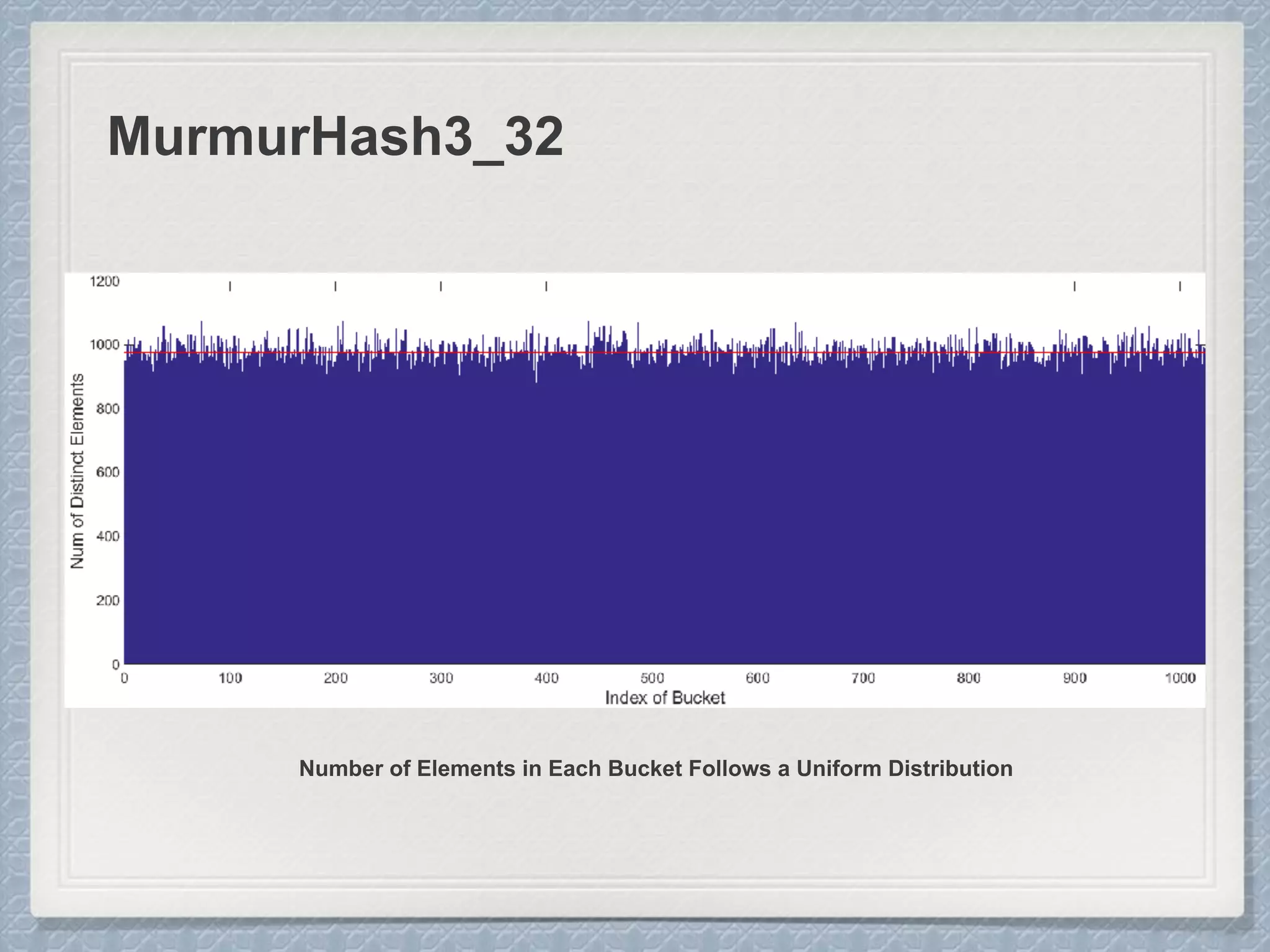
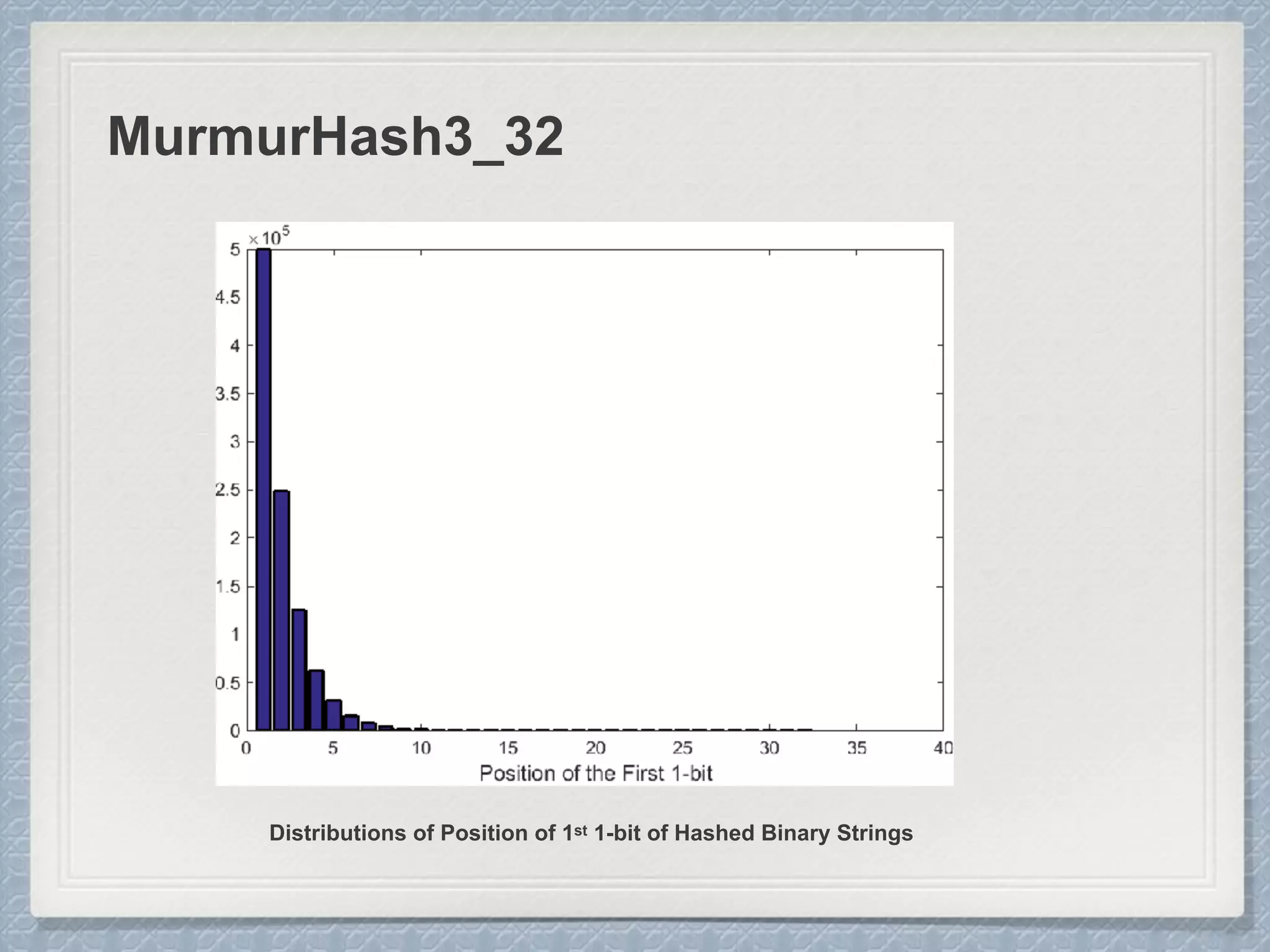
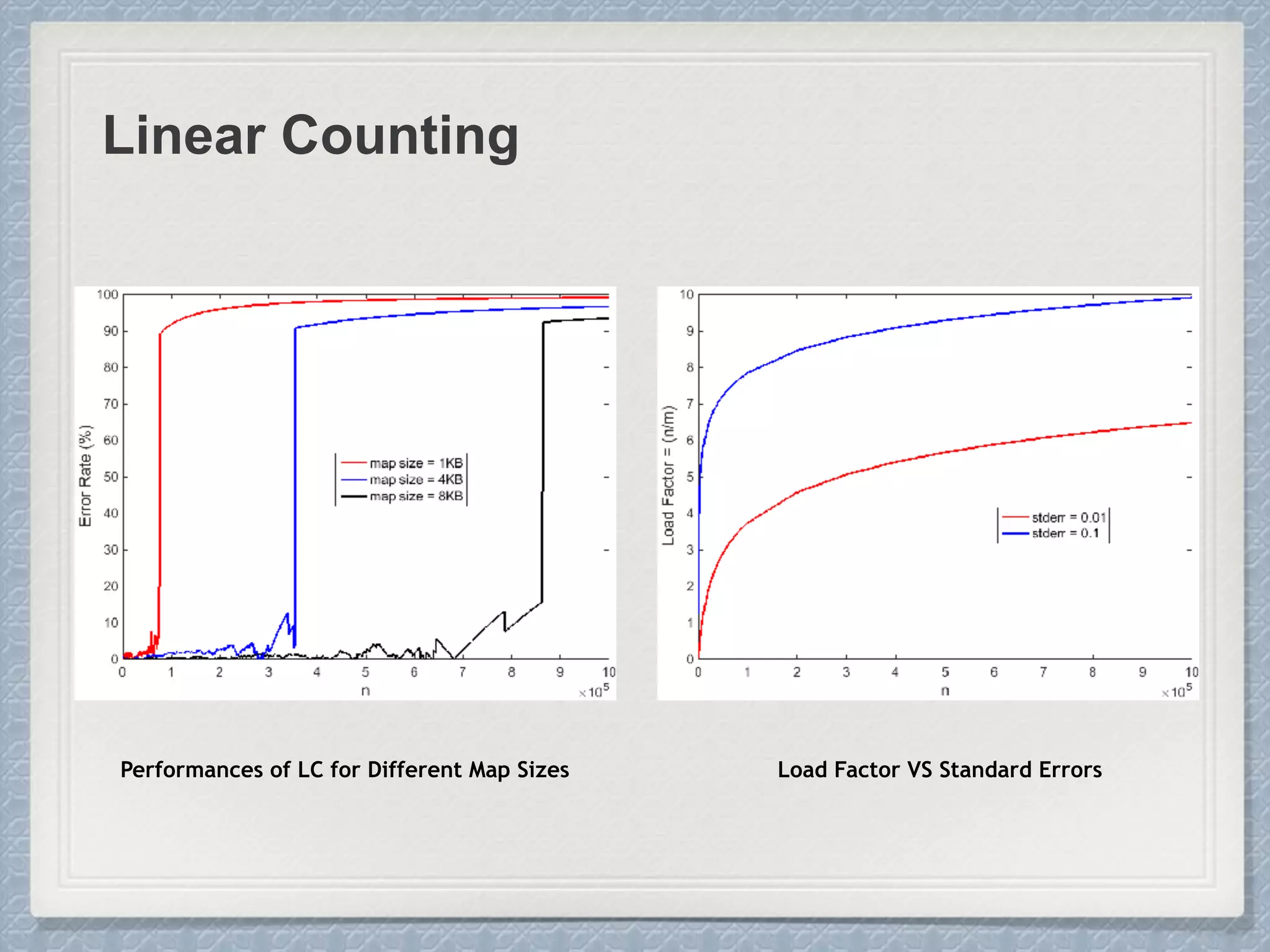
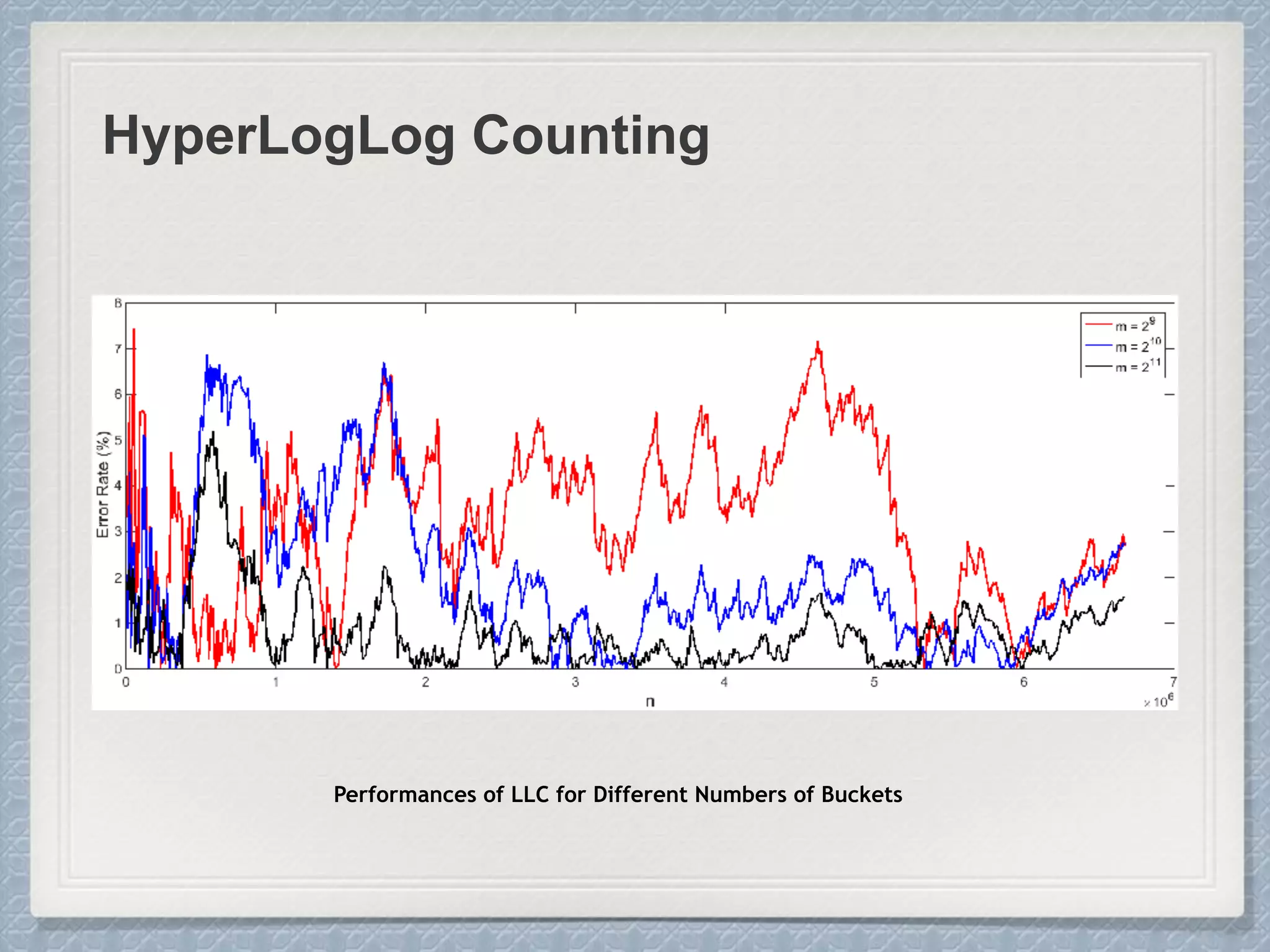
Large Cardinalities:
A hash function of L bits can at most
distinguish 2L different values, and as the
cardinality n approaches 2L, hash
collisions become more and more likely
and accurate estimation gets impossible.
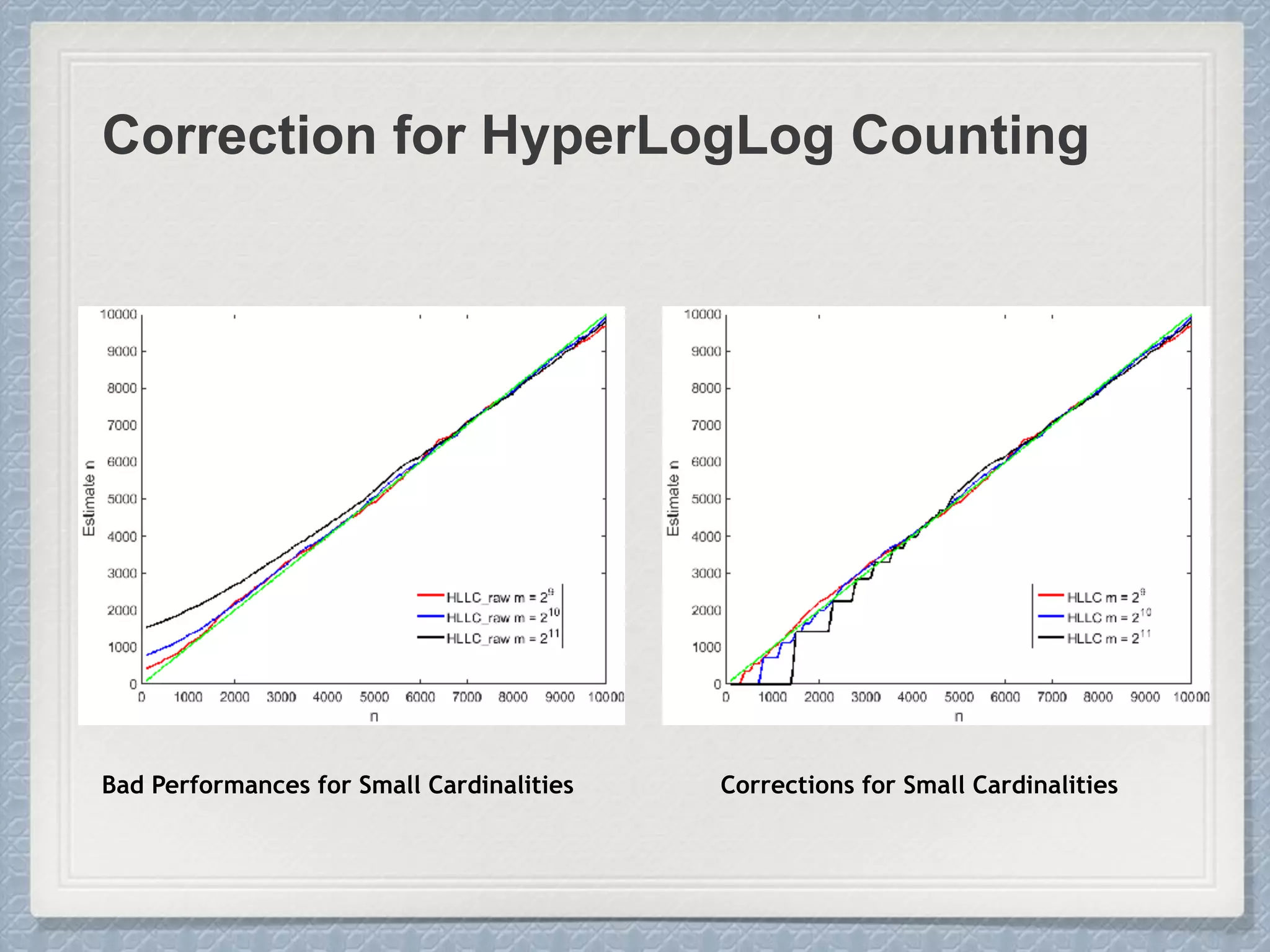
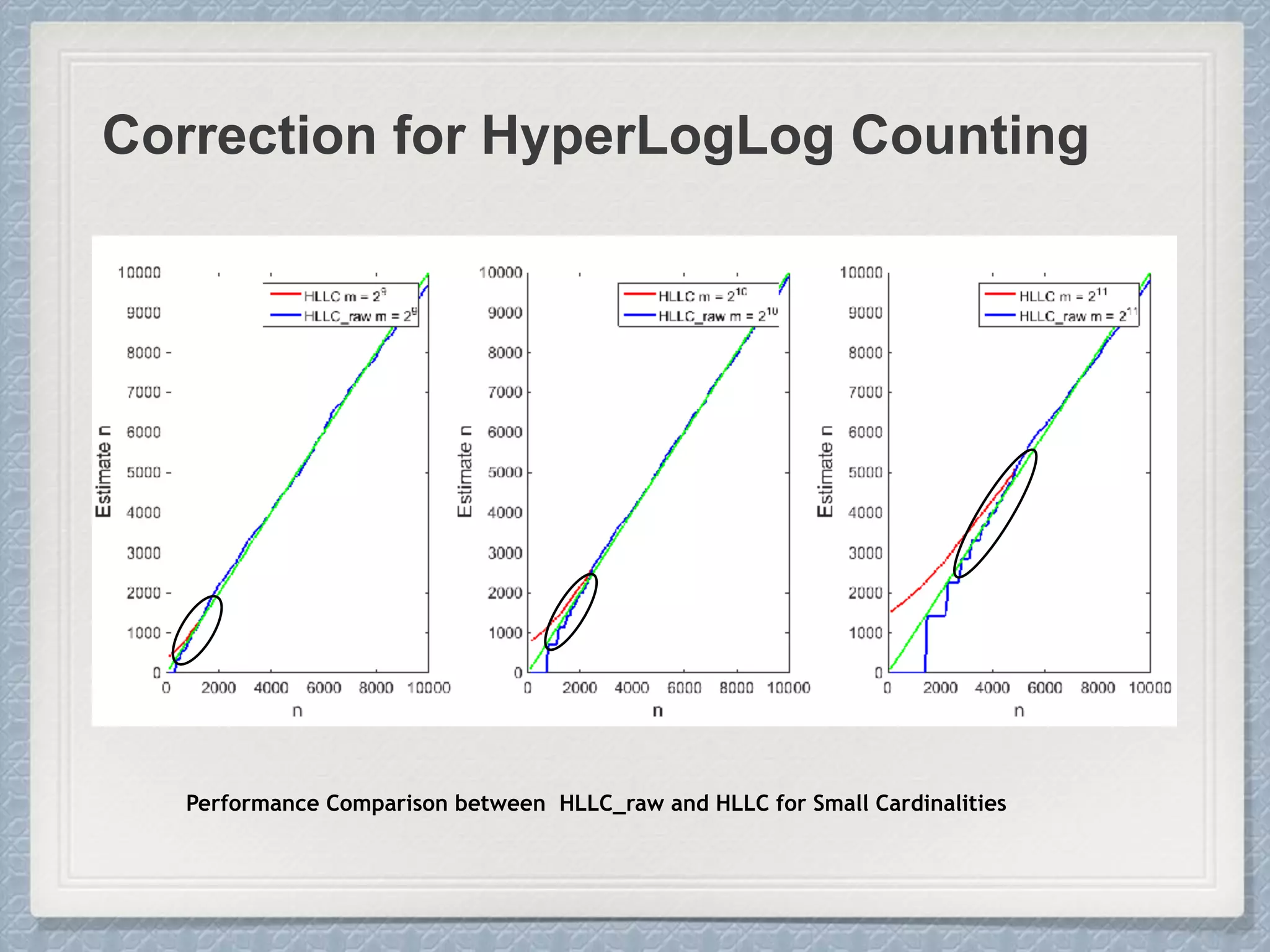
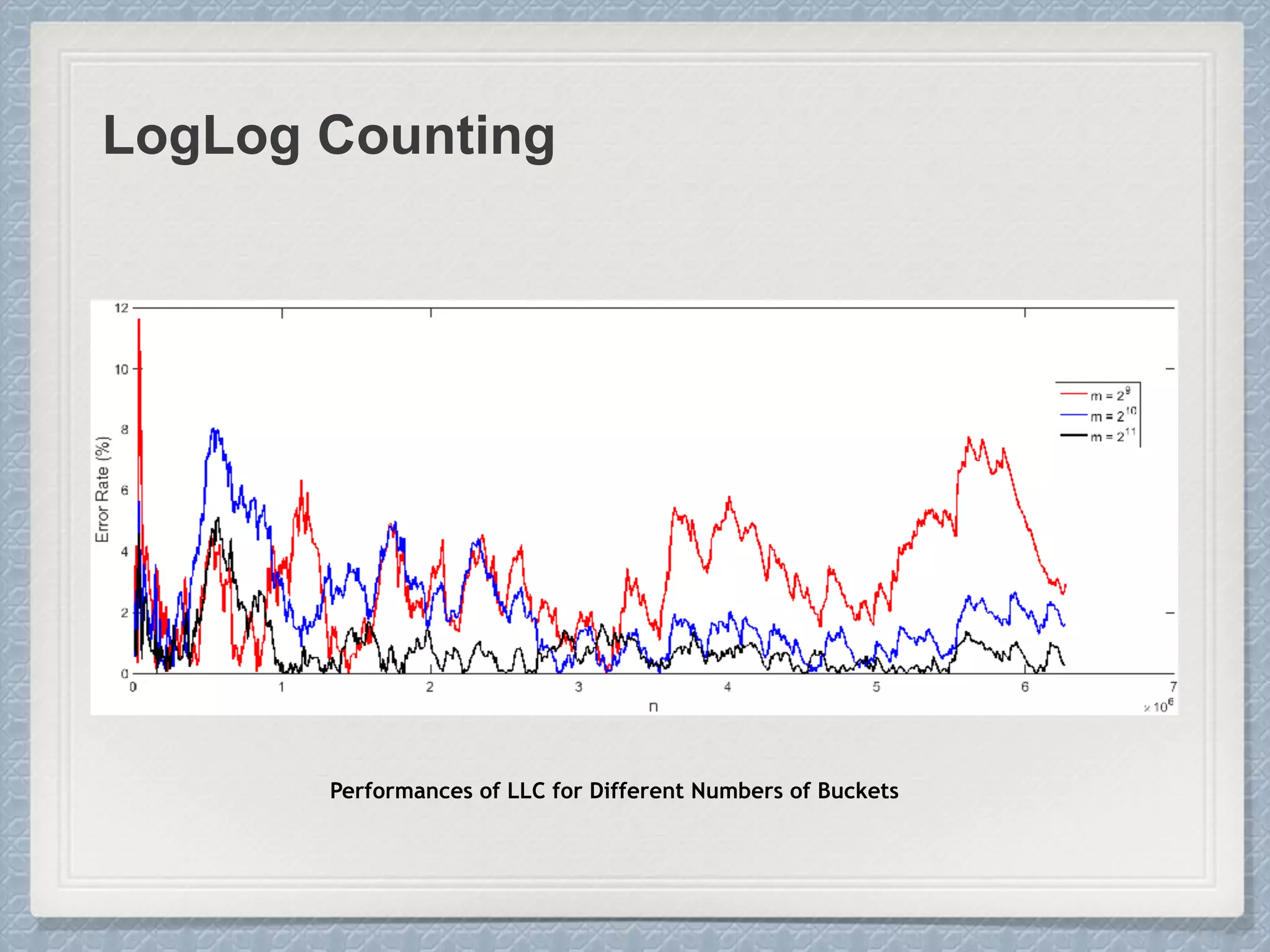
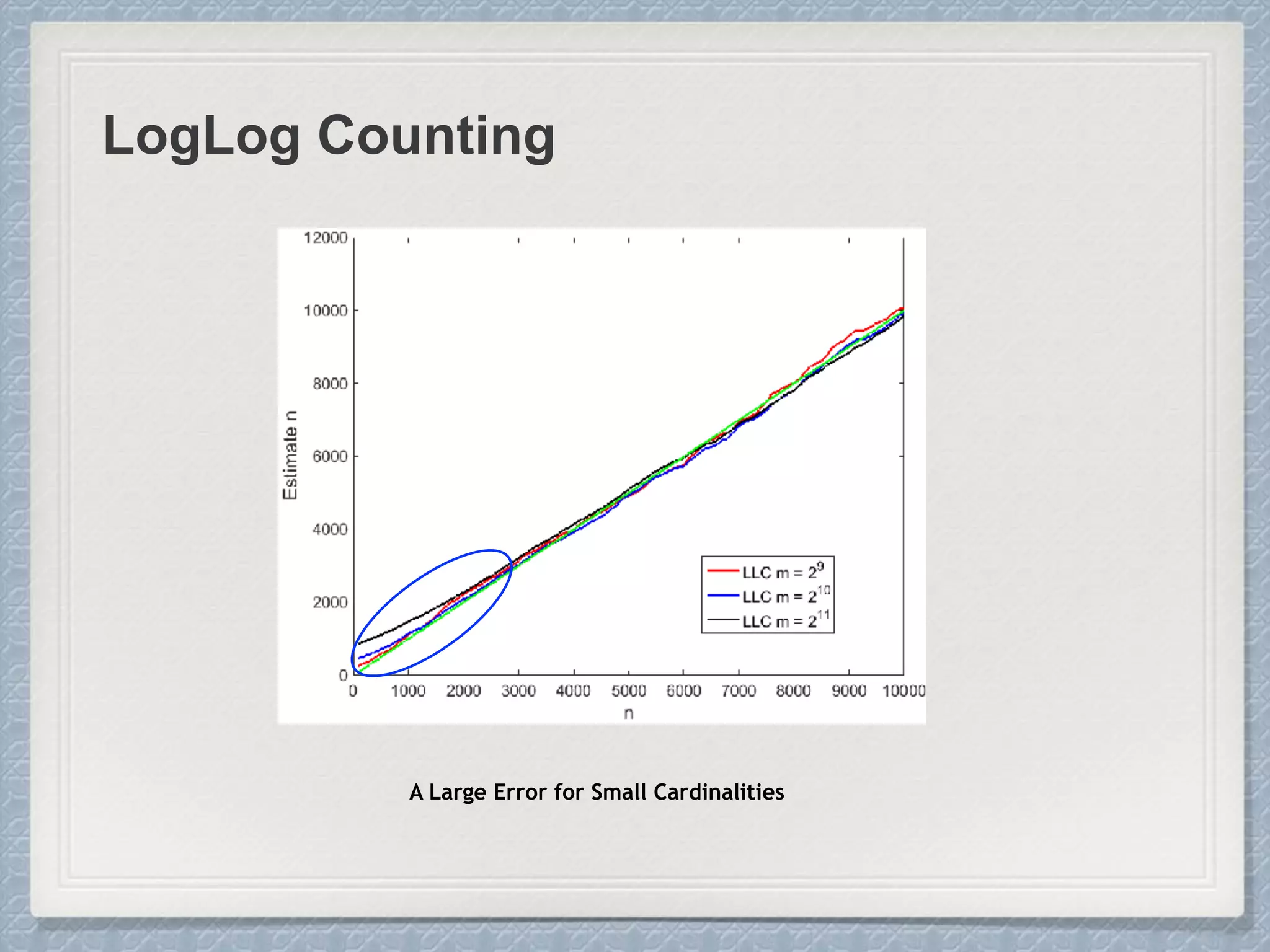
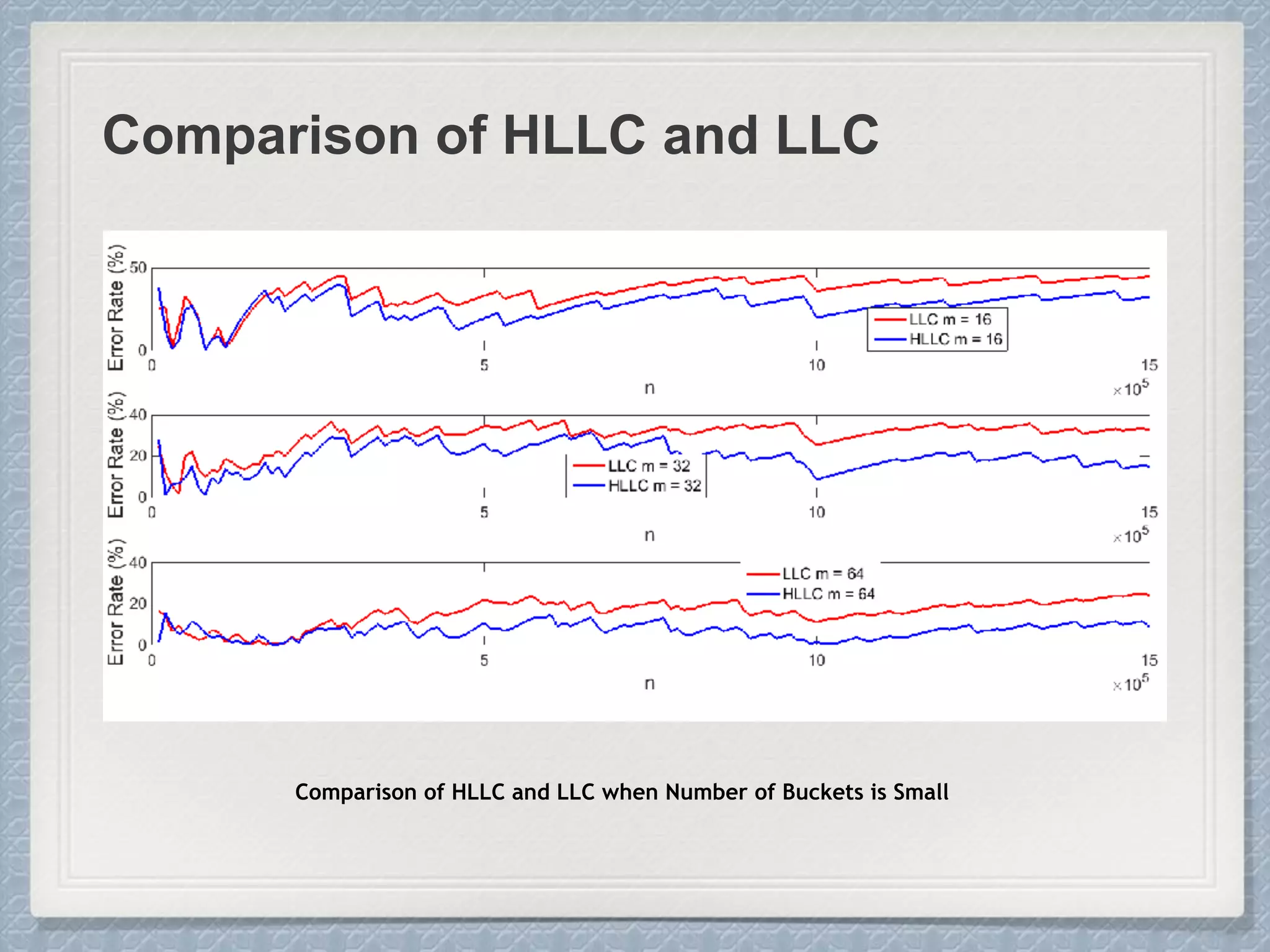
Small Cardinalities:
When cardinality is small, the
proportion of un-hit bucket is large,
which leads to inaccurate estimation.
E := ↵mm2
0
@
mX
j=1
2 M[j]
1
A
2
E <=
5
2
m
E
1
30
232
E = 232
log(1 E/232
)
E
1
30
232
The “raw” estimate:](https://image.slidesharecdn.com/project-180219215947/75/Count-Distinct-Problem-32-2048.jpg)