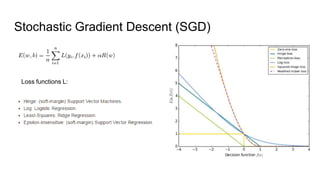
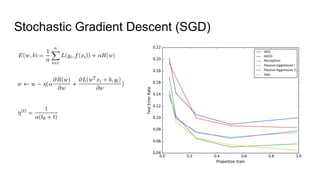
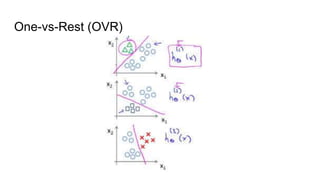
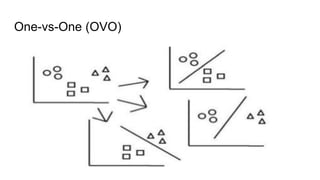
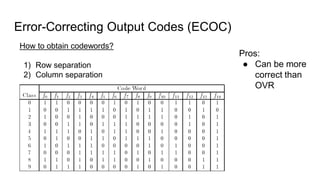
The document discusses various methods for multiclass classification including Gaussian and linear classifiers, multi-class classification models, and multi-class strategies like one-versus-all, one-versus-one, and error-correcting codes. It also provides summaries of naive Bayes, linear/quadratic discriminant analysis, stochastic gradient descent, multilabel vs multiclass classification, and one-versus-all, one-versus-one, and error-correcting output codes classification strategies.






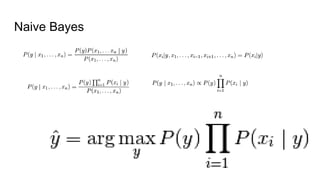


















































































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
















