Downloaded 55 times



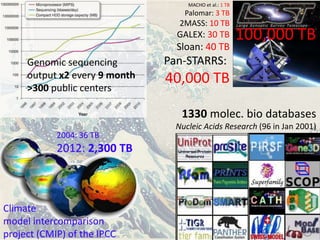













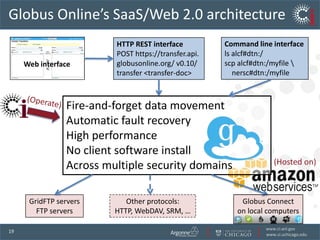
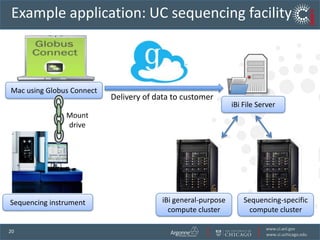

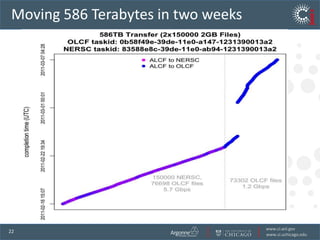
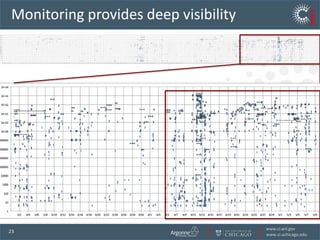
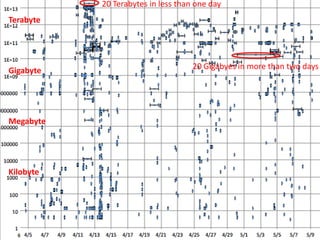
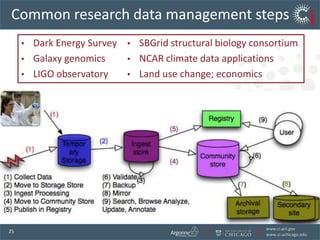

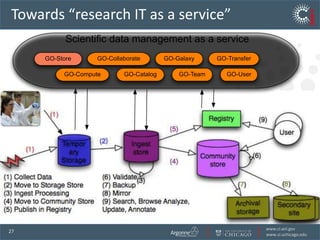
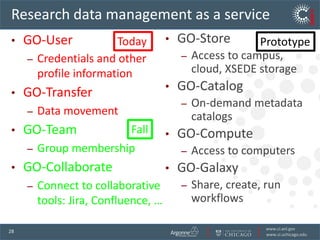
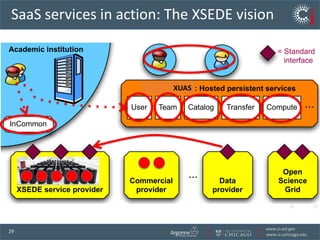
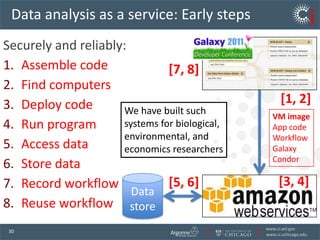
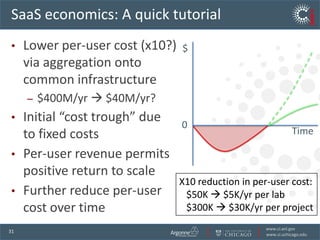
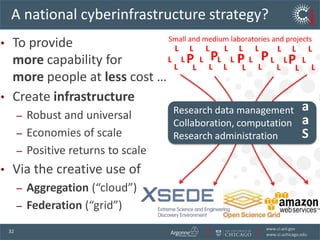




The document discusses the challenges and opportunities in research data management, emphasizing the need for scalable, cloud-based solutions to handle the increasing volume and complexity of data across various scientific fields. It highlights the inefficiencies of current practices and proposes a shift towards Research IT as a Service to enhance accessibility, streamline processes, and reduce costs. Through leveraging Software-as-a-Service, the goal is to democratize access to powerful research tools, ultimately accelerating discovery and innovation.











































































































