Download to read offline



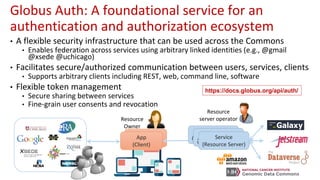
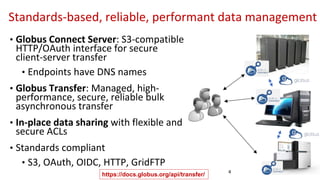
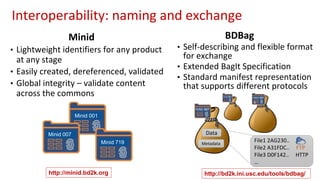


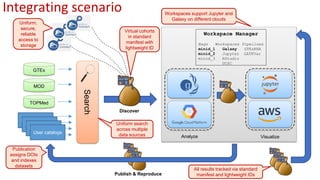


The document outlines the implementation of a commons platform for promoting continuous fairness in data sharing, emphasizing the need for data to be findable, accessible, interoperable, and reusable. It highlights essential components like Globus Auth for secure authentication, Globus Connect Server for data transfer, and the use of standardized identifiers and formats for data management and sharing. The infrastructure aims to support scalability, interoperability, and user-friendly experiences for diverse collaboration and virtual cohort creation.























































































