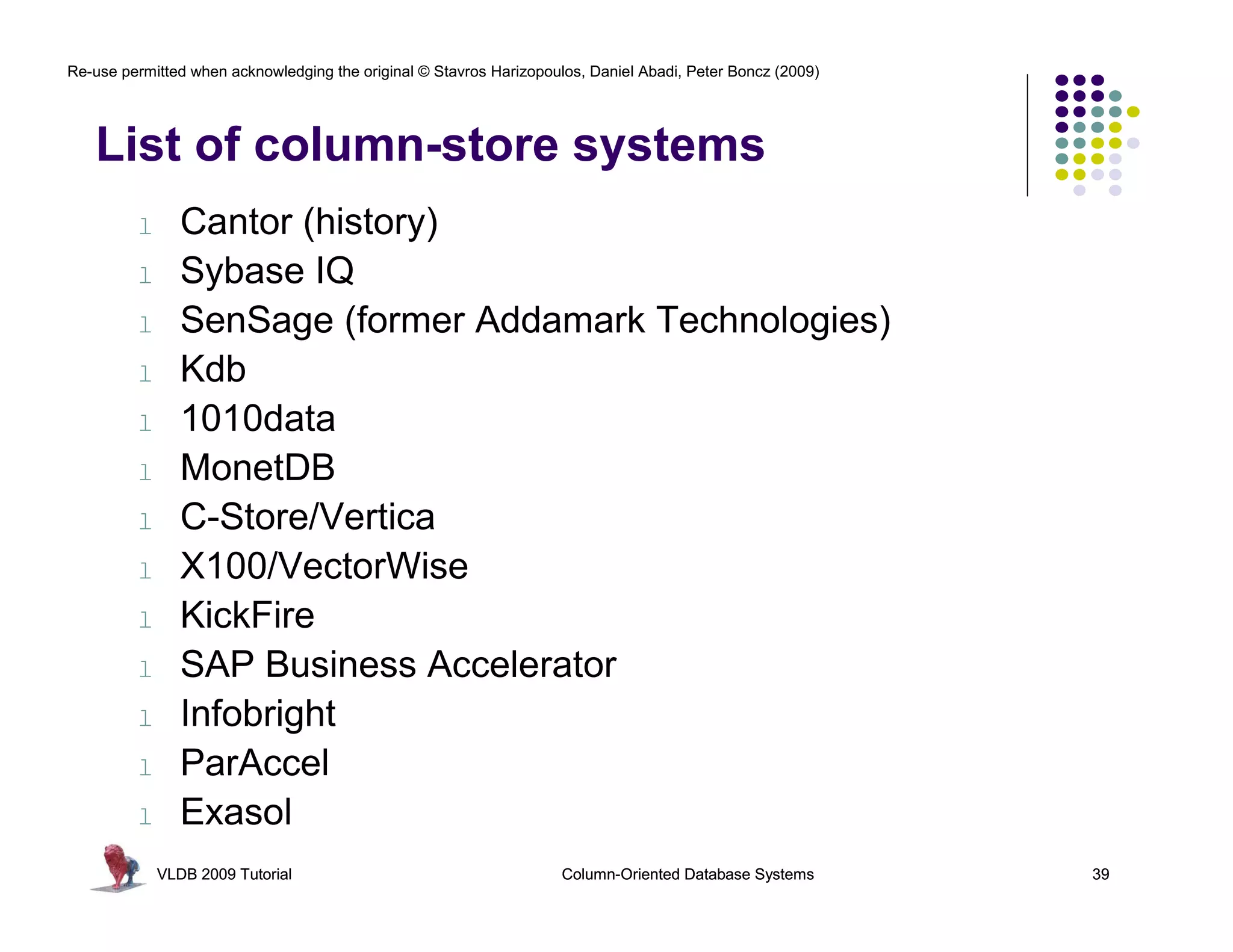
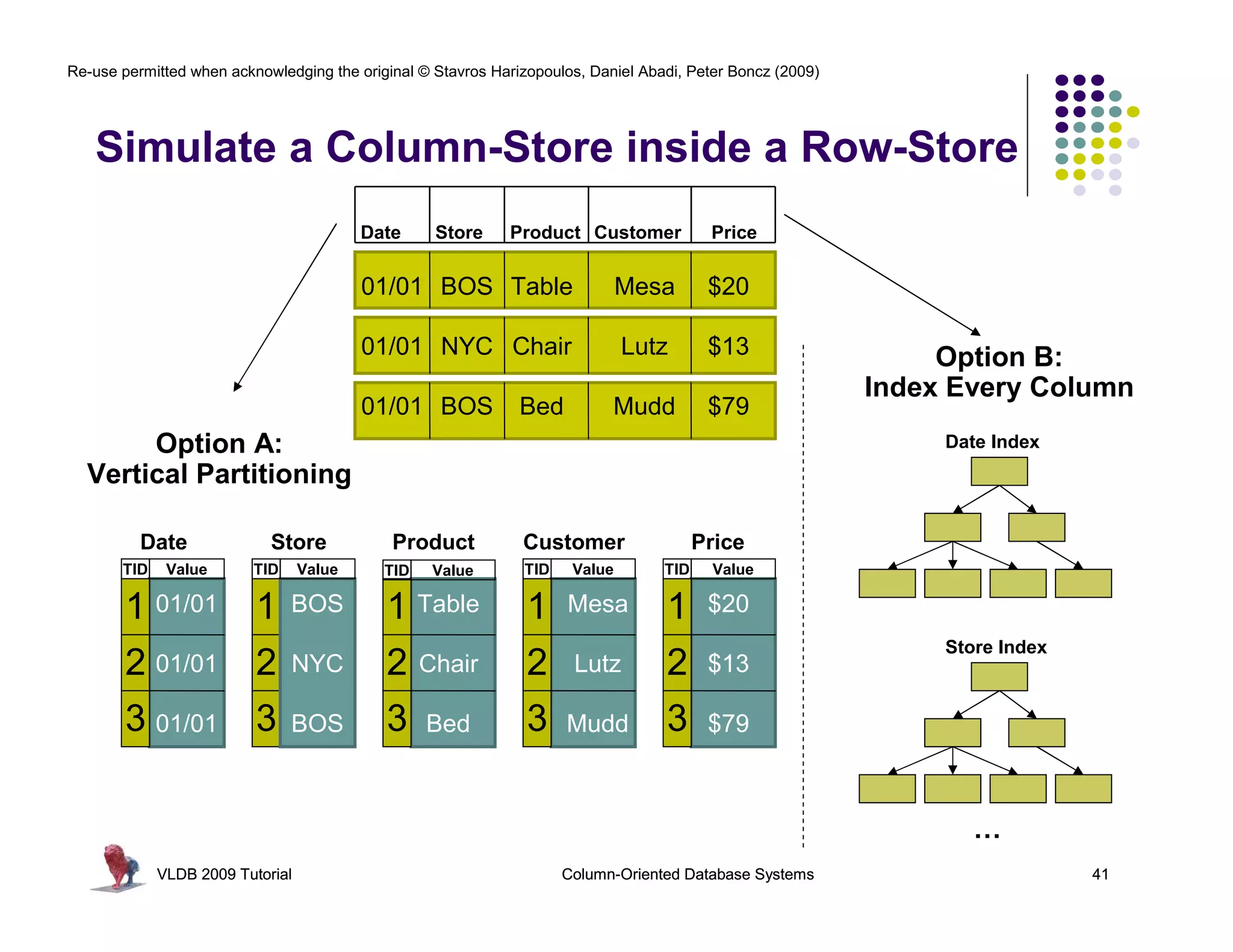
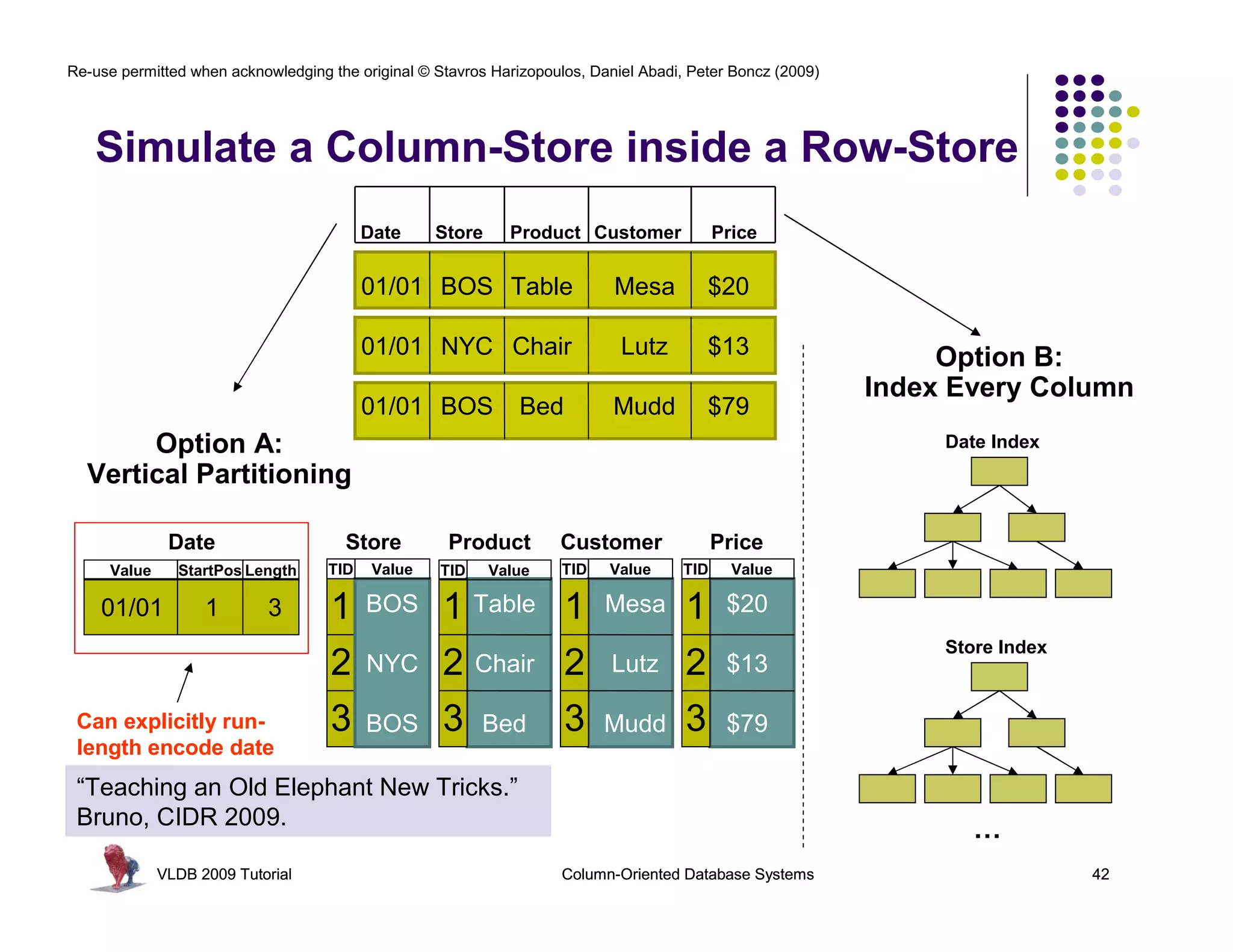
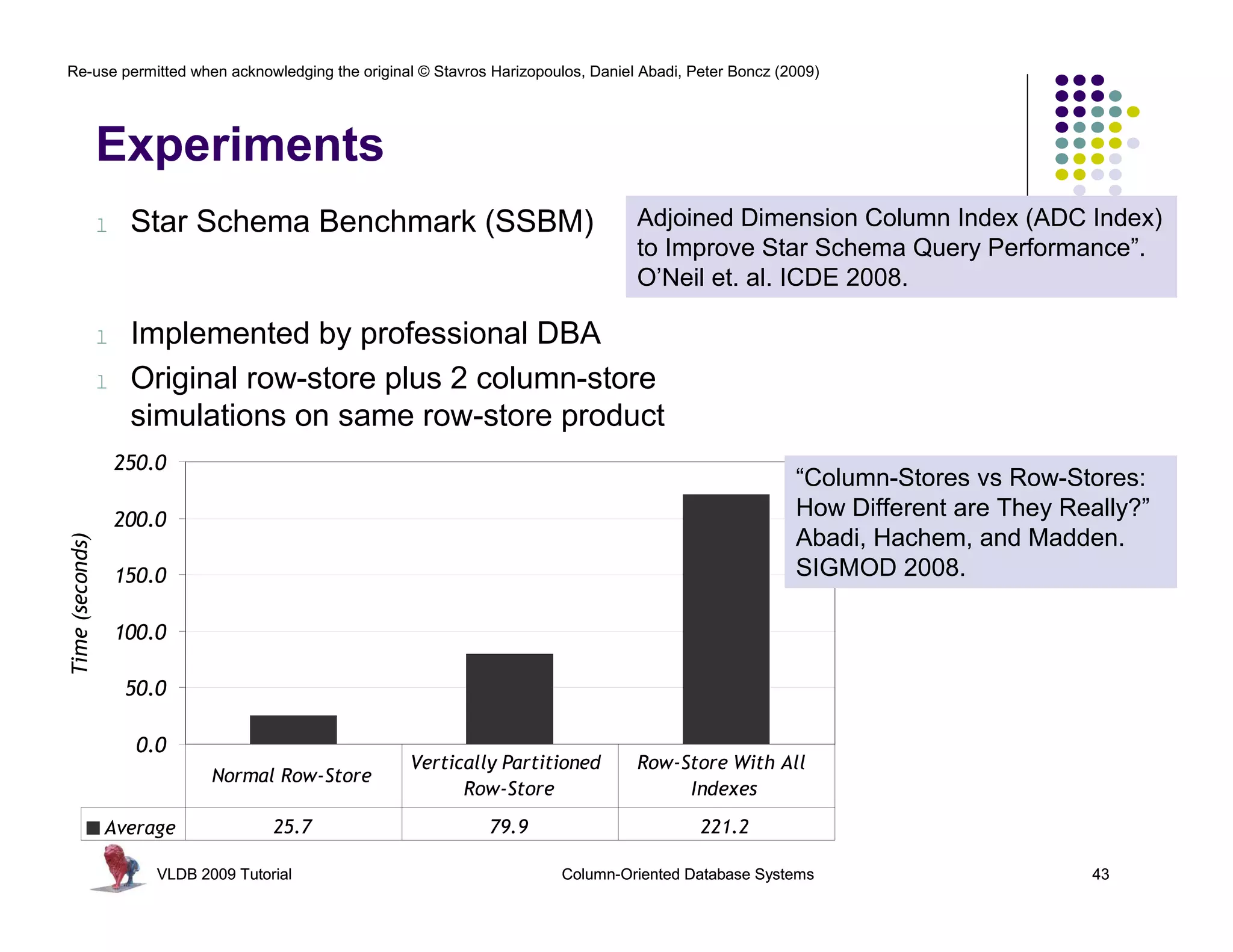
Download as PDF, PPTX







![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
From DSM to Column-stores
TOD: Time Oriented Database – Wiederhold et al.
70s -1985: "A Modular, Self-Describing Clinical Databank
System," Computers and Biomedical Research, 1975
More 1970s: Transposed files, Lorie, Batory,
Svensson.
“An overview of cantor: a new system for data analysis”
Karasalo, Svensson, SSDBM 1983
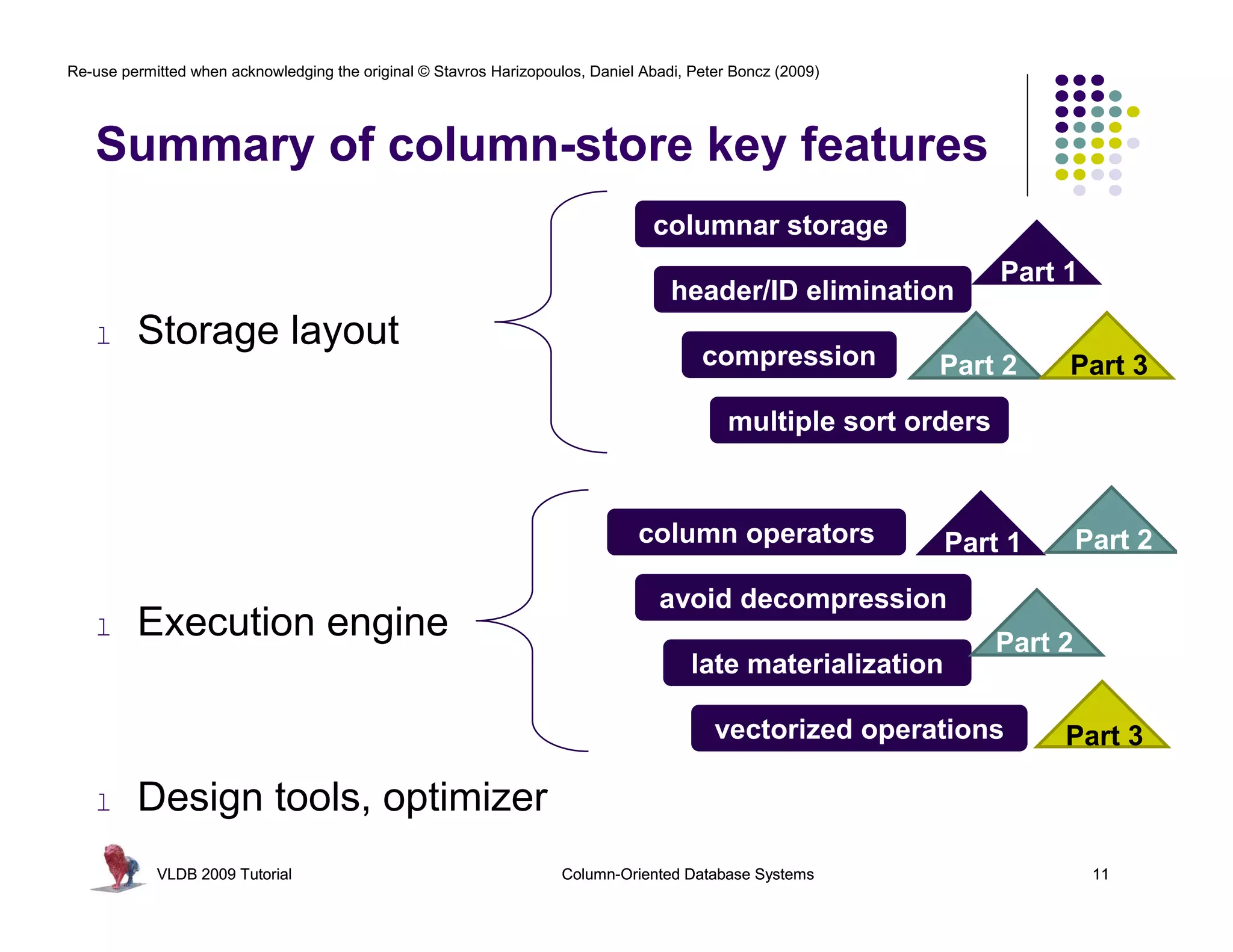
1985: DSM paper “A decomposition storage model”
Copeland and Khoshafian. SIGMOD 1985.
1990s: Commercialization through SybaseIQ
Late 90s – 2000s: Focus on main-memory performance
l DSM “on steroids” [1997 – now] CWI: MonetDB
l Hybrid DSM/NSM [2001 – 2004] Wisconsin: PAX, Fractured Mirrors
Michigan: Data Morphing CMU: Clotho
2005 – : Re-birth of read-optimized DSM as “column-store”
MIT: C-Store CWI: MonetDB/X100 10+ startups
VLDB 2009 Tutorial Column-Oriented Database Systems 13](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-13-2048.jpg)





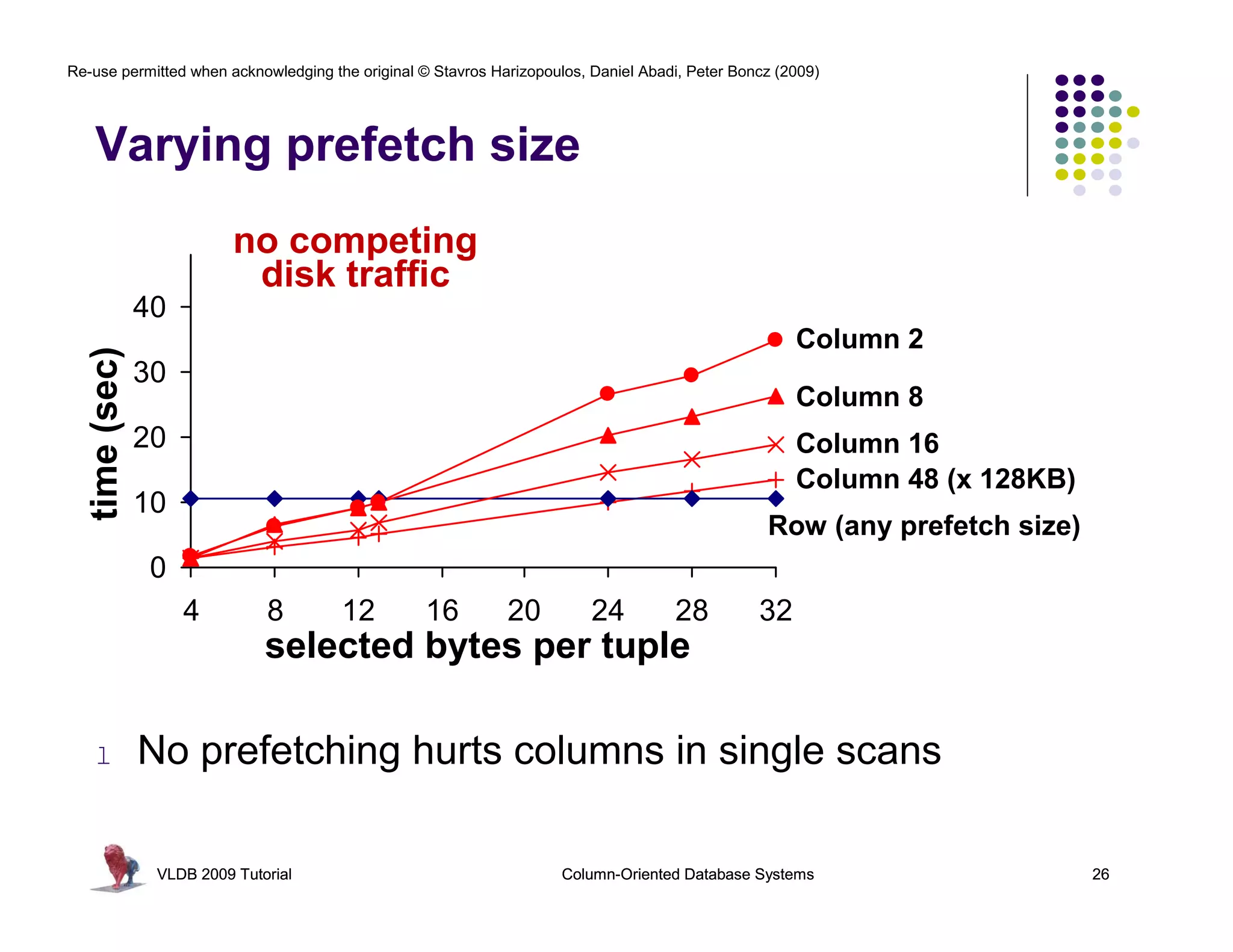
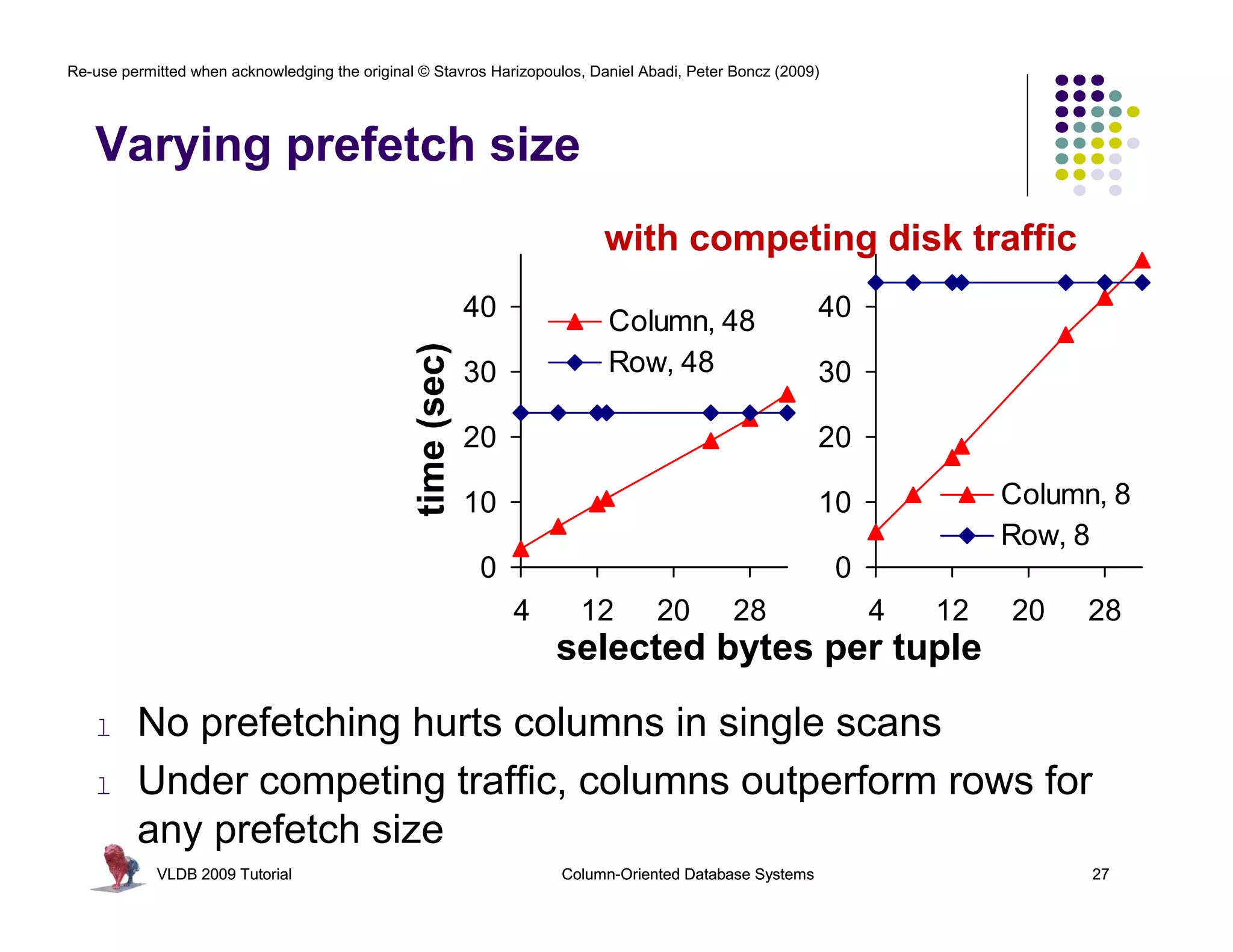
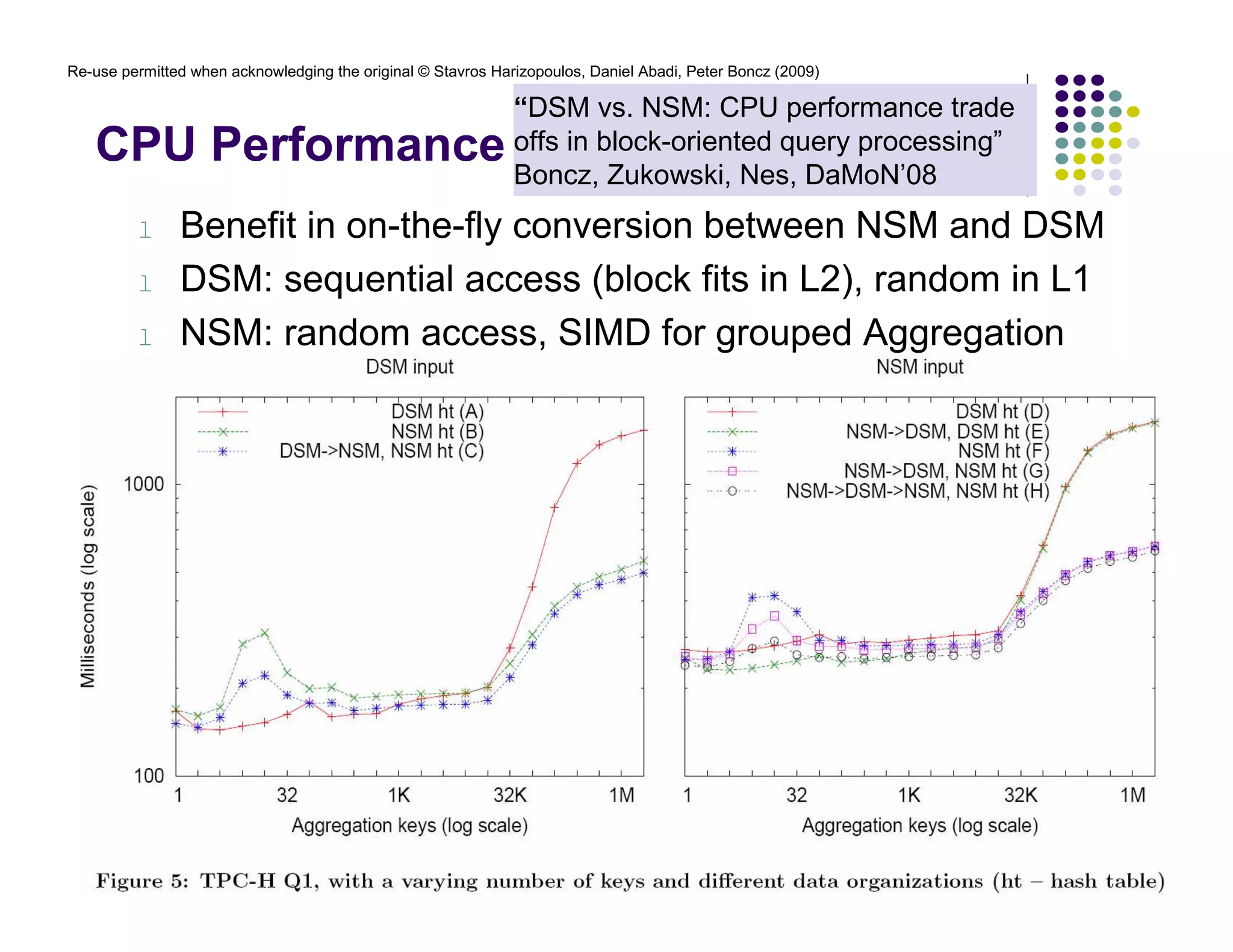

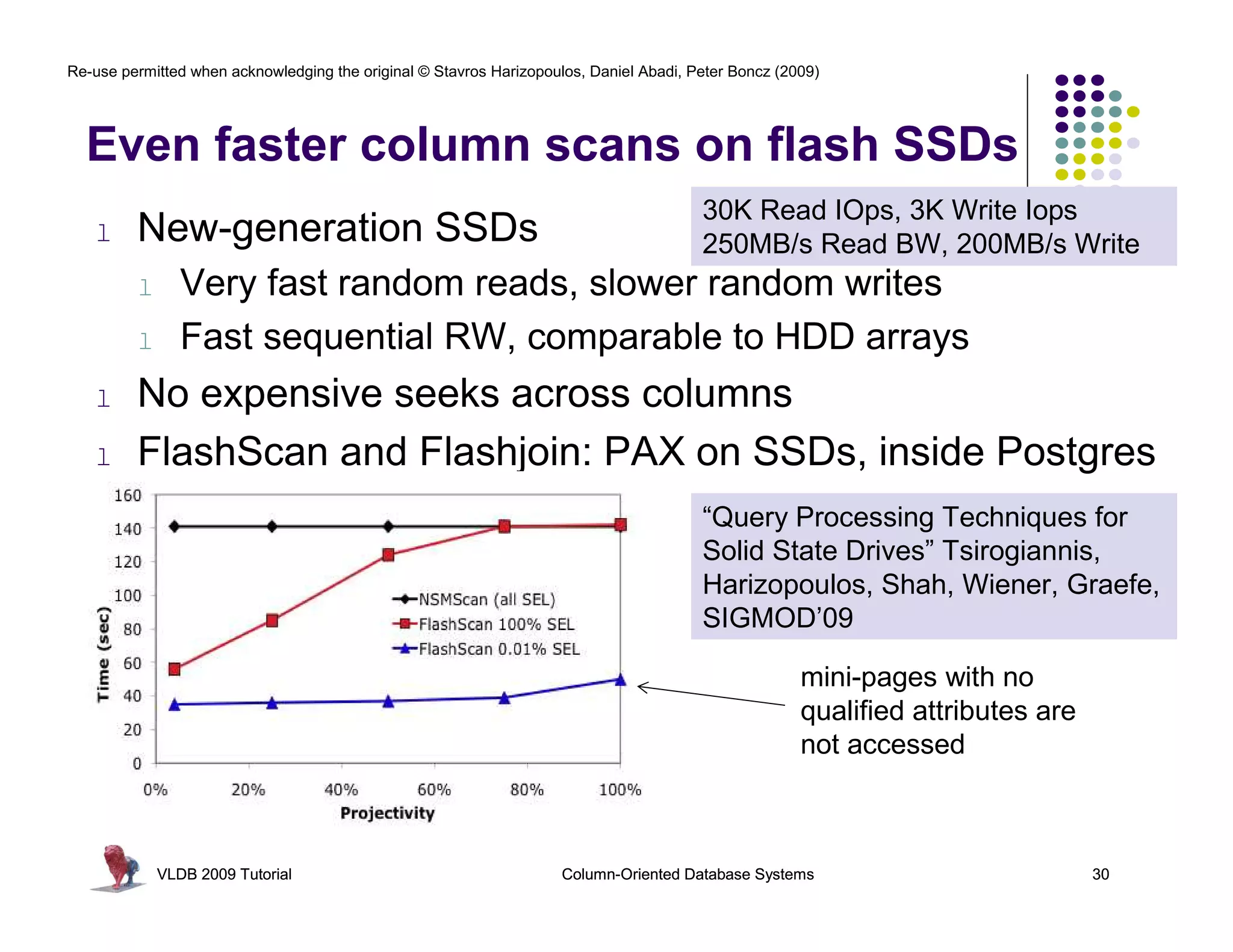












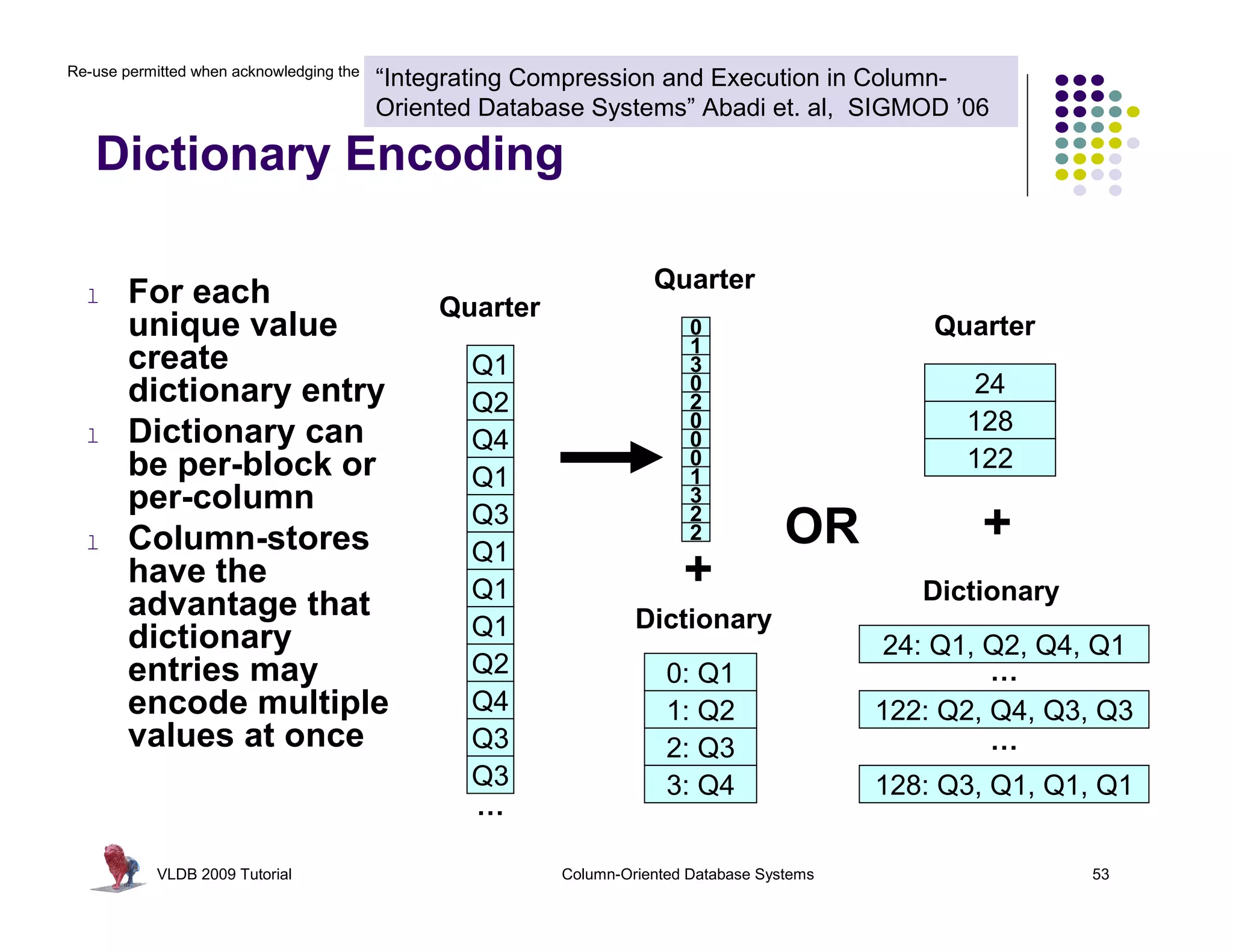
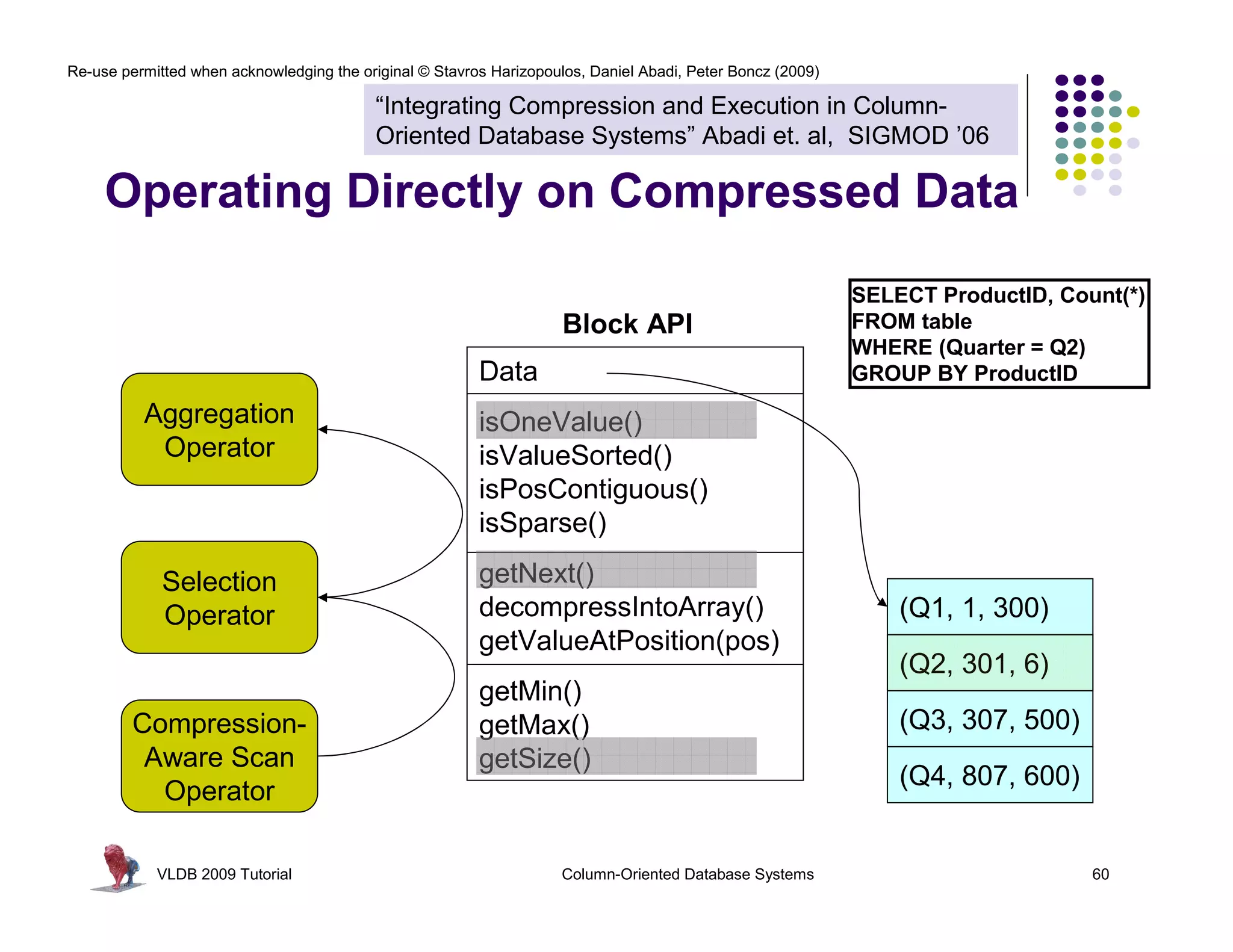
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
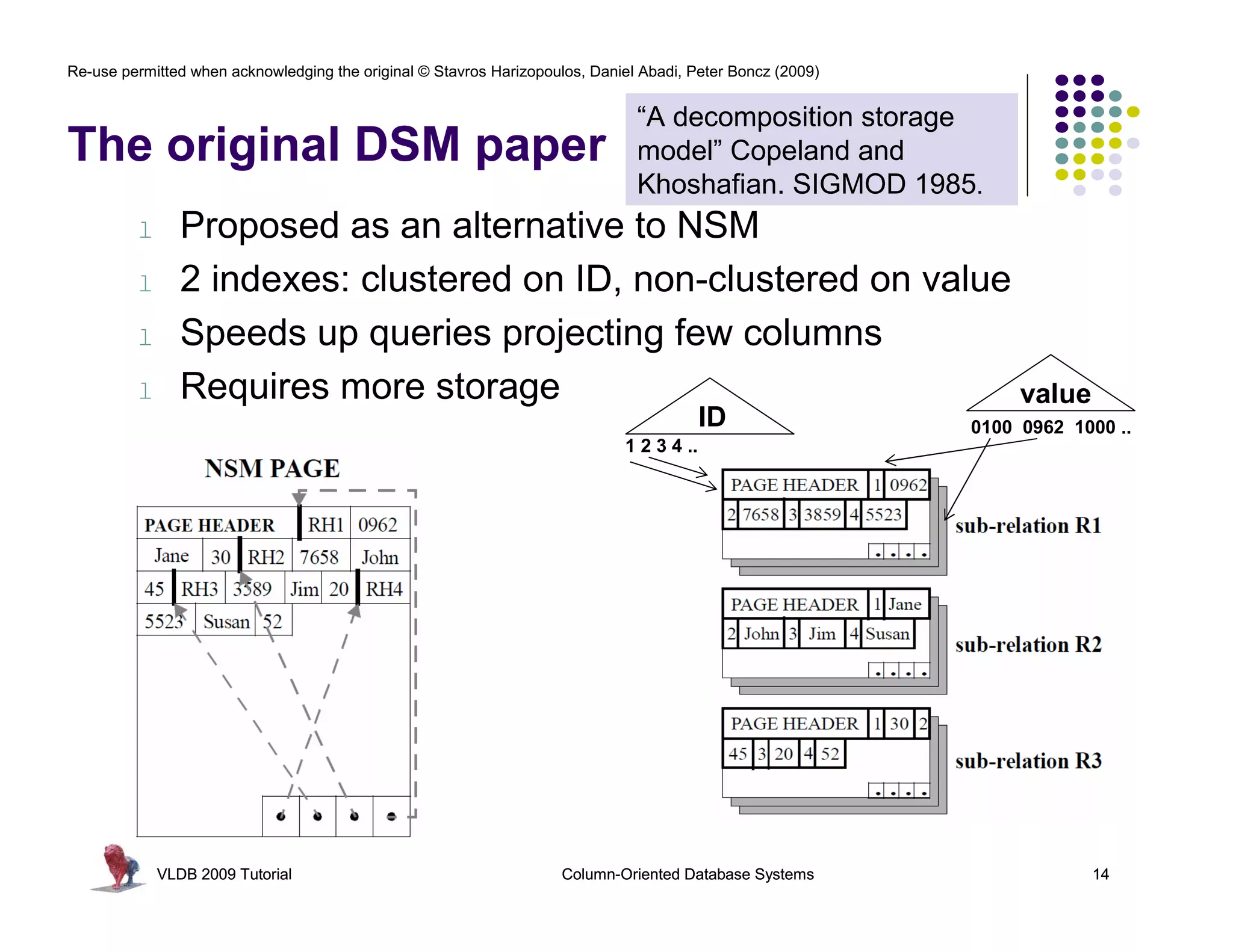
“Integrating Compression and Execution in Column-
Oriented Database Systems” Abadi et. al, SIGMOD ’06
Bit-vector Encoding
l For each unique Product ID ID: 1 ID: 2 ID: 3 …
value, v, in column
c, create bit-vector 1 1 0 0 0
b 1 1 0 0 0
l b[i] = 1 if c[i] = v 1 1 0 0 0
1 1 0 0 0
l Good for columns
1 1 0 0 0
with few unique
2 0 1 0 0
values
2 0 1 0 0
l Each bit-vector … … … … …
can be further 1 1 0 0 0
compressed if 1 1 0 0 0
sparse 2 0 1 0 0
3 0 0 1 0
… … … … …
VLDB 2009 Tutorial Column-Oriented Database Systems 52](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-52-2048.jpg)







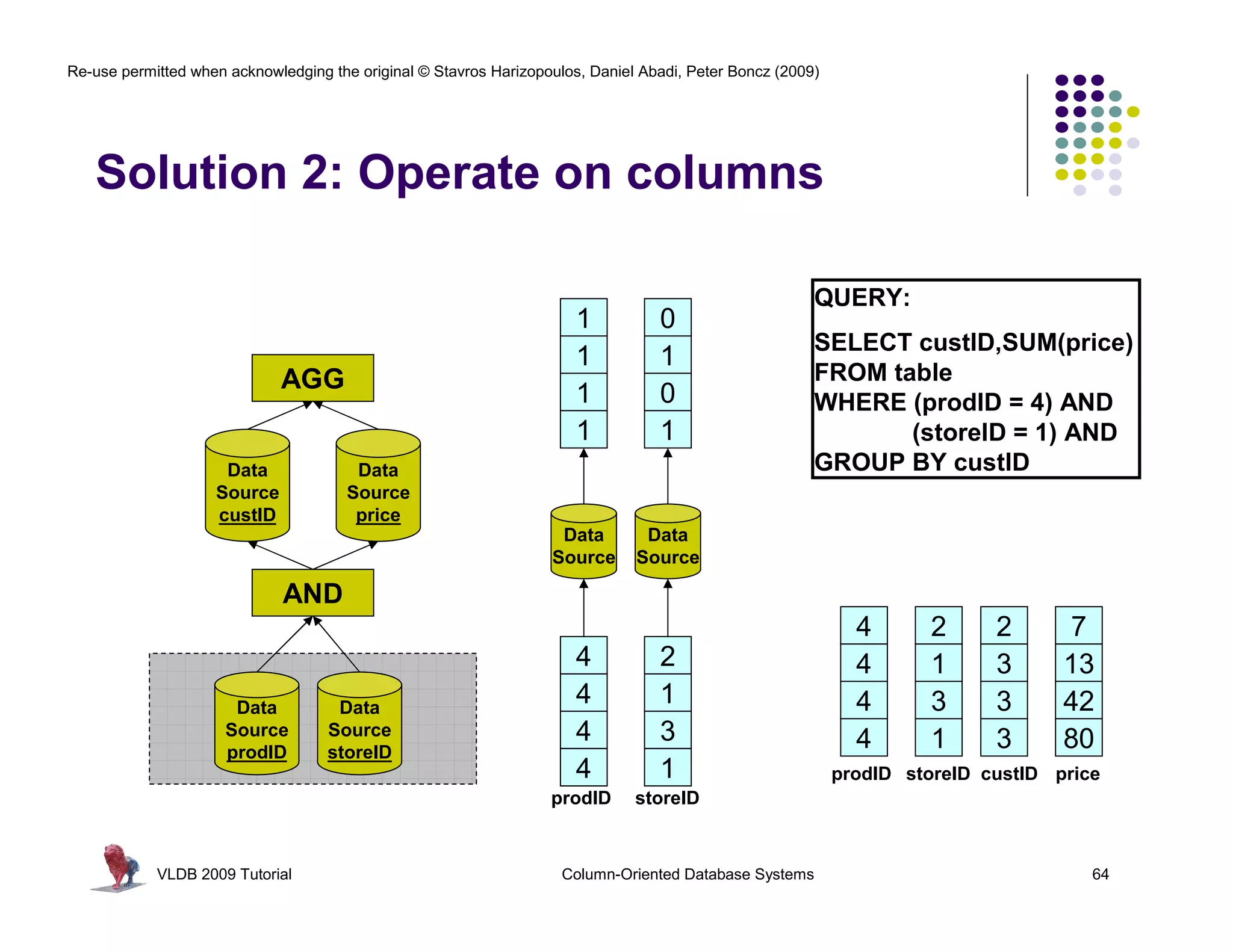
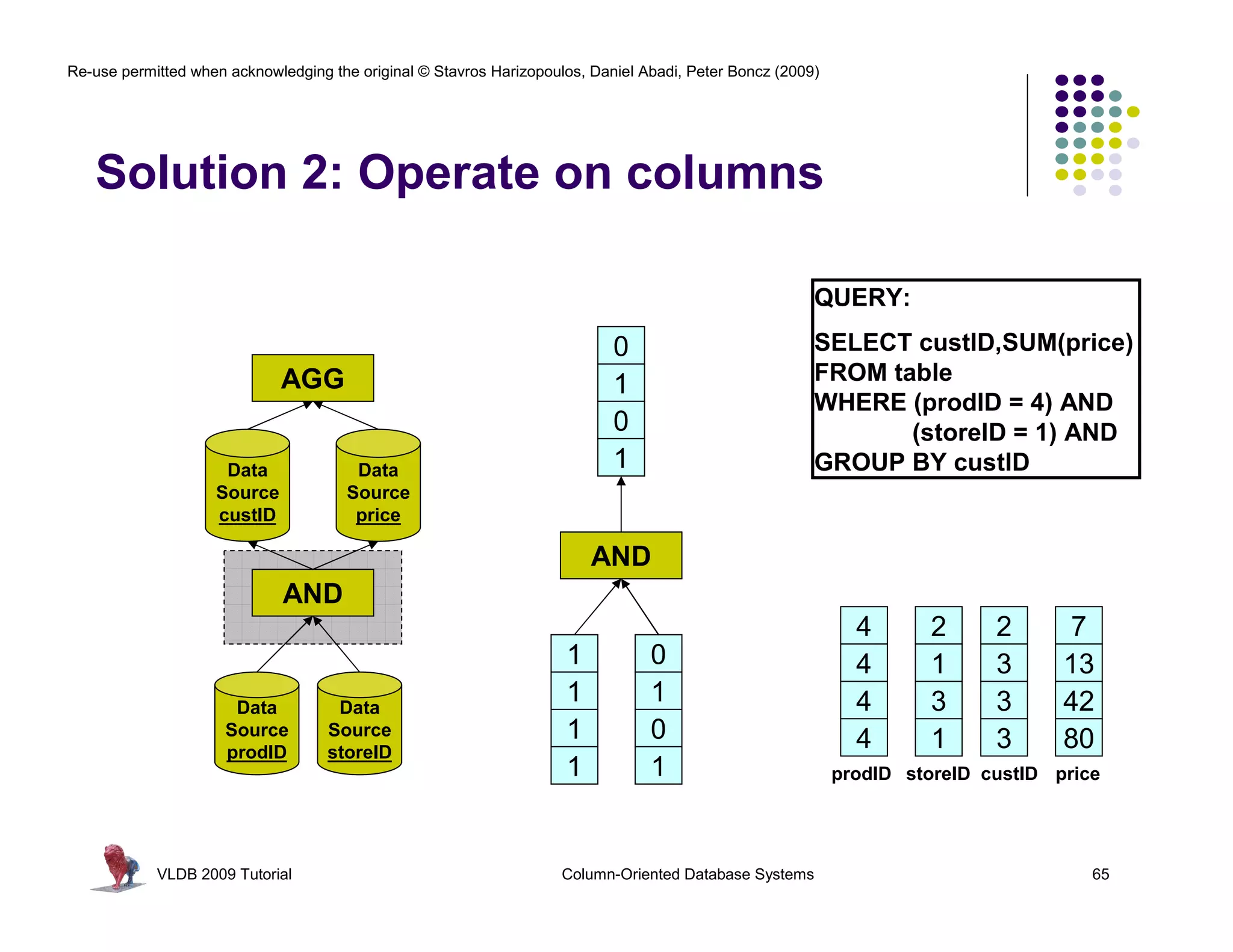
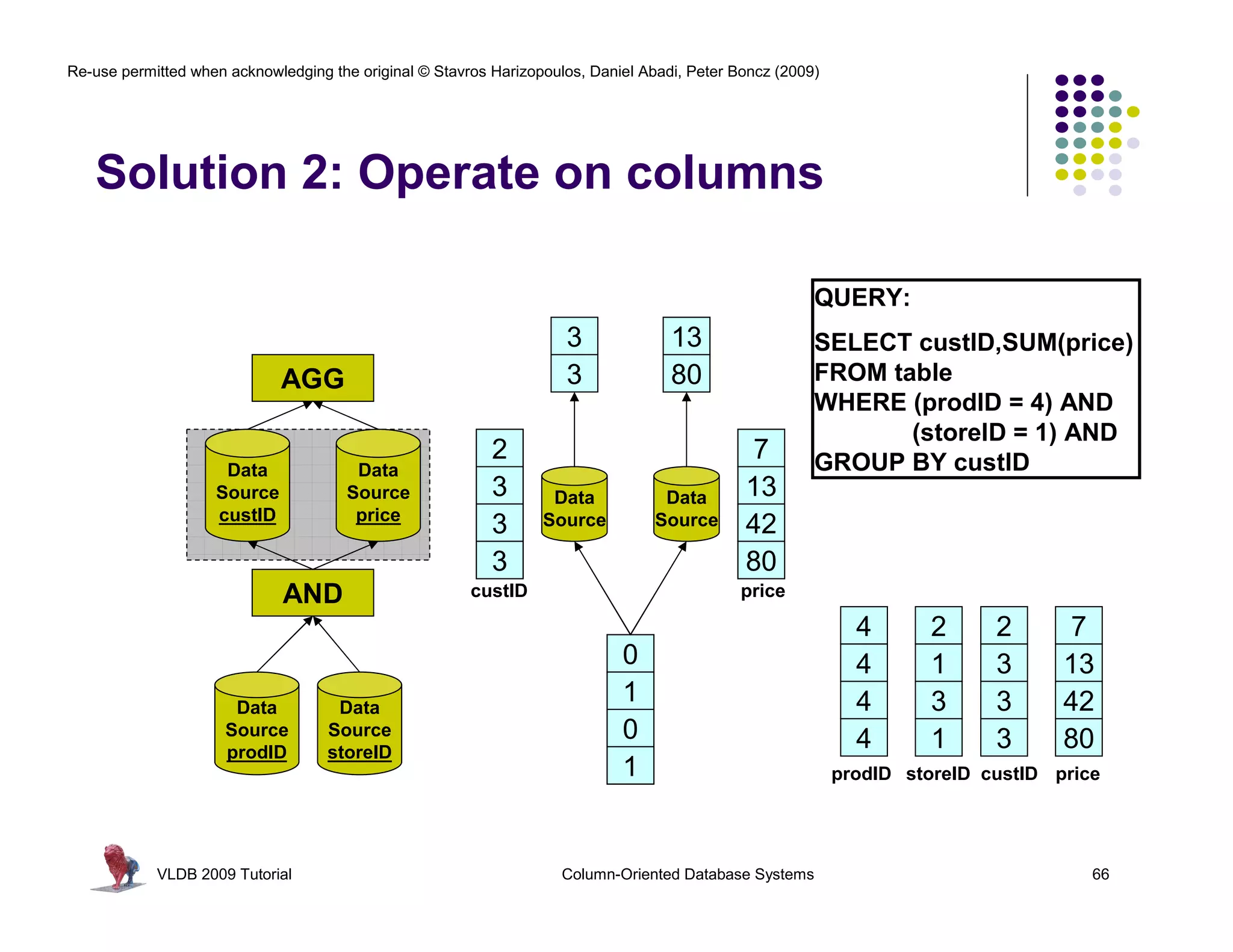
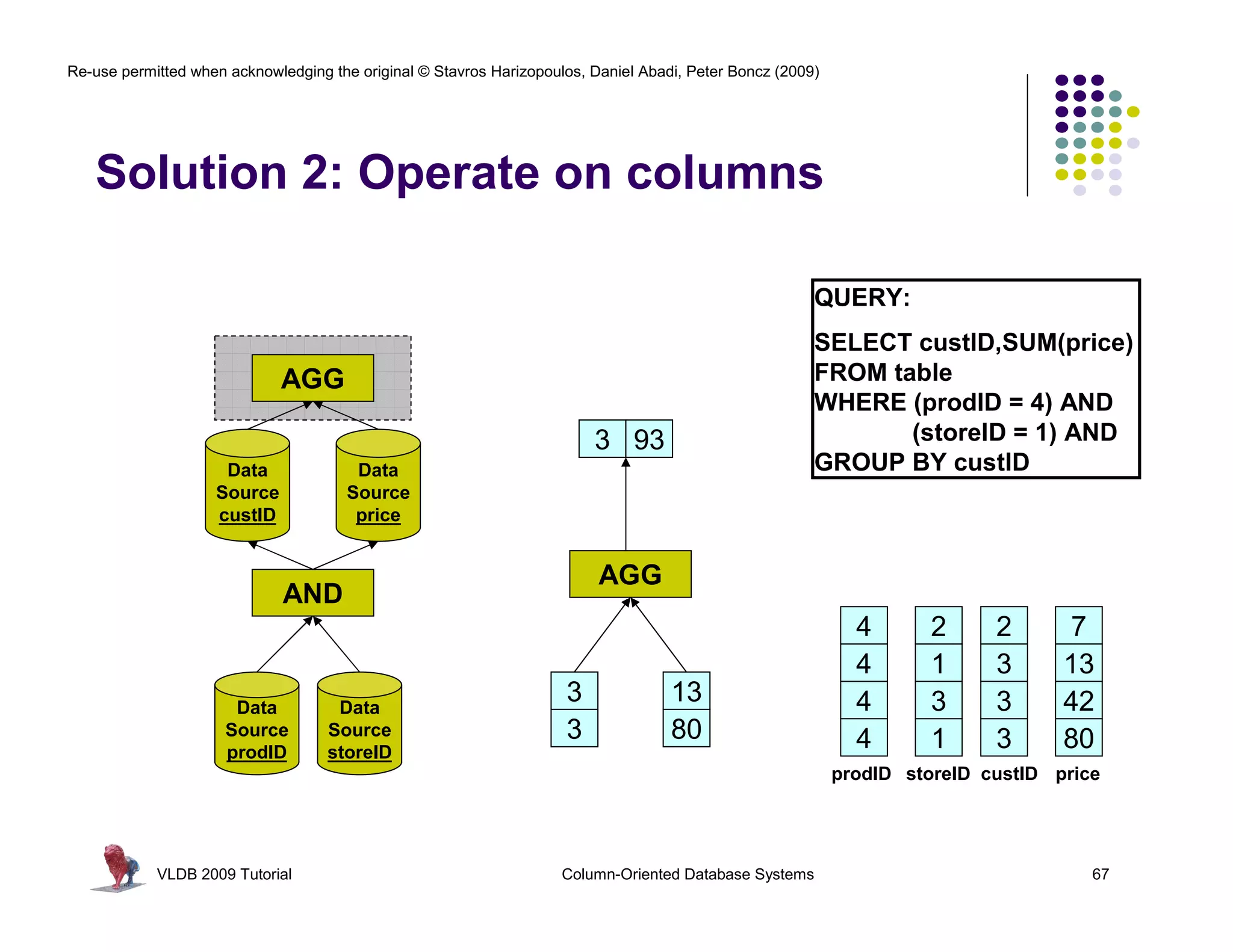
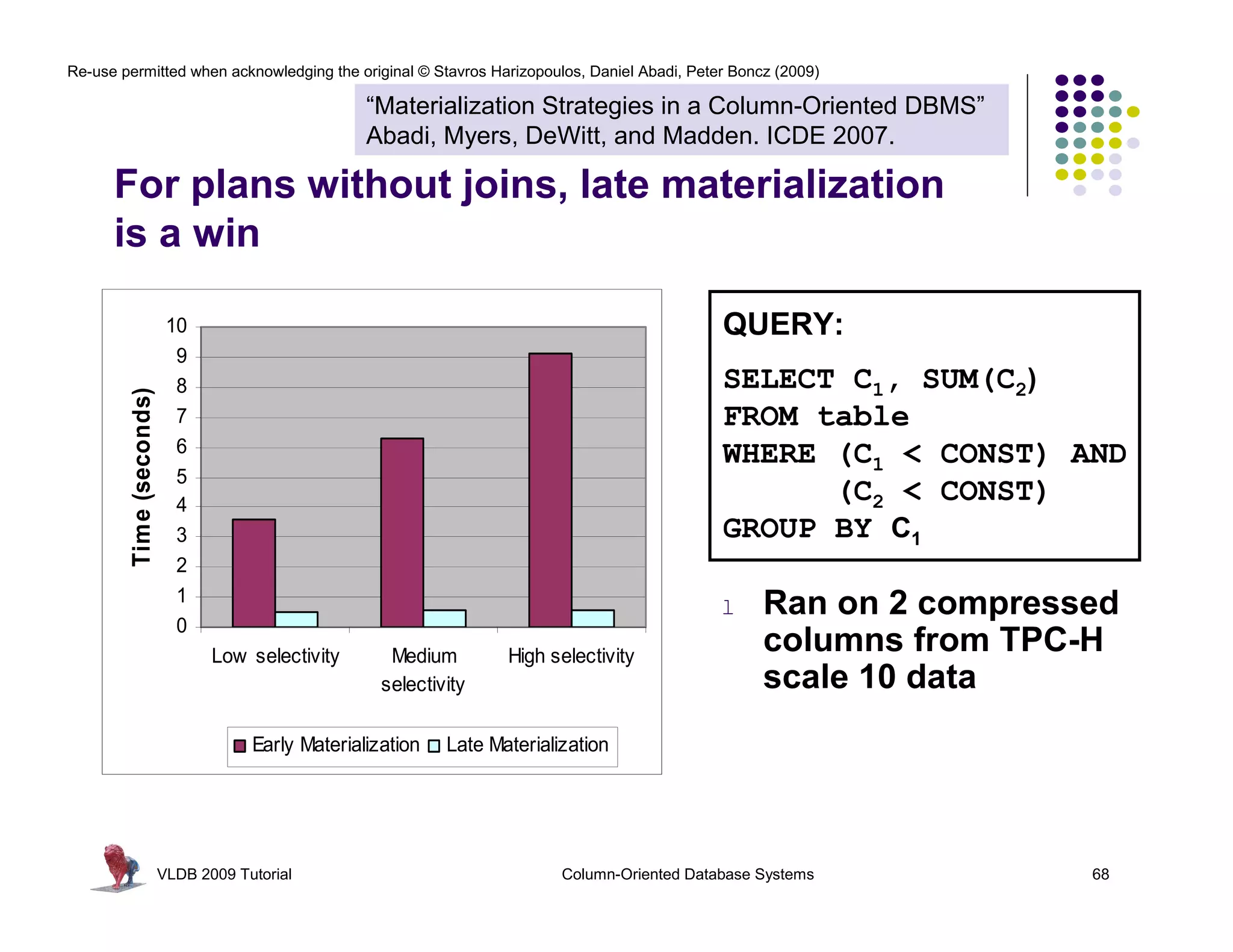
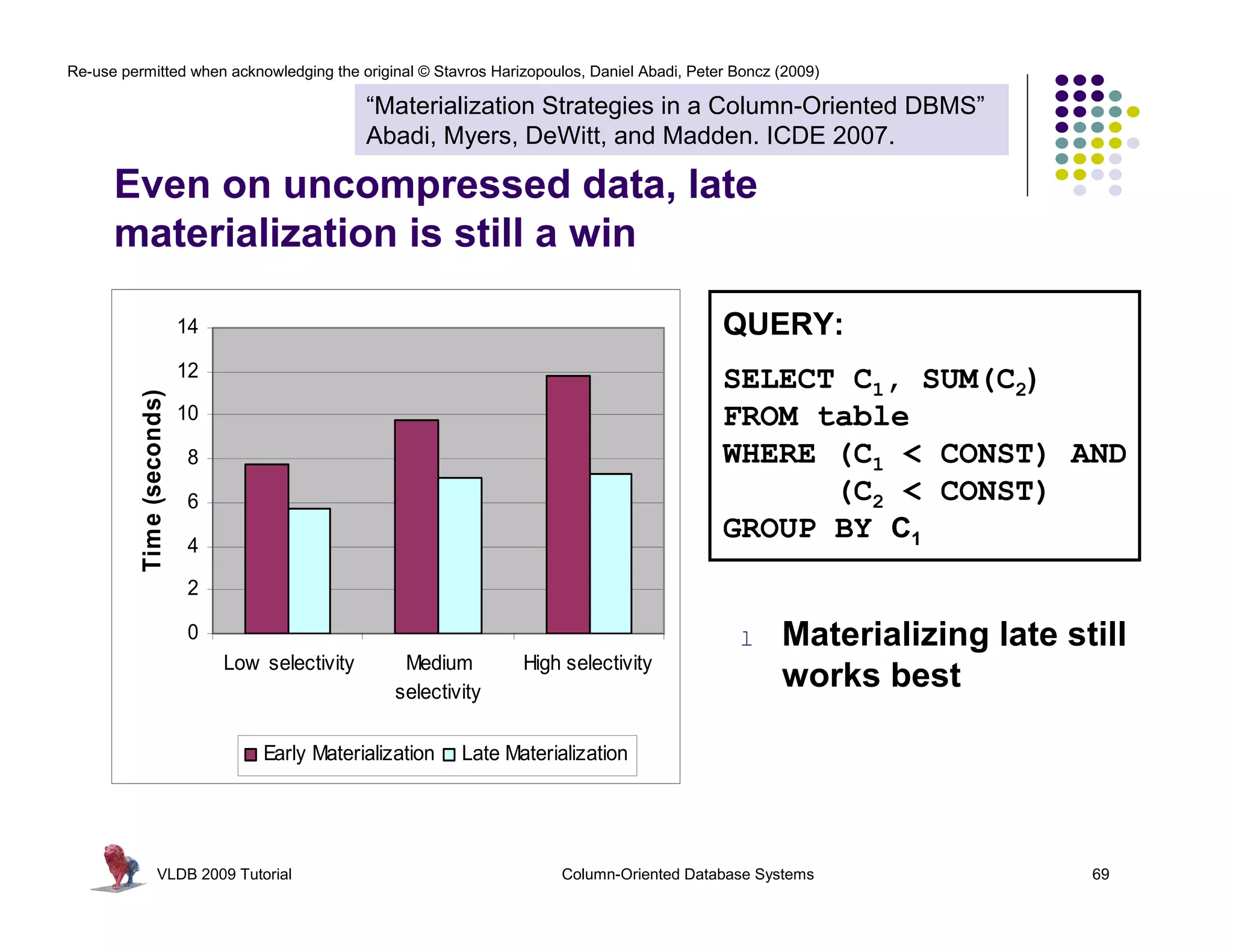
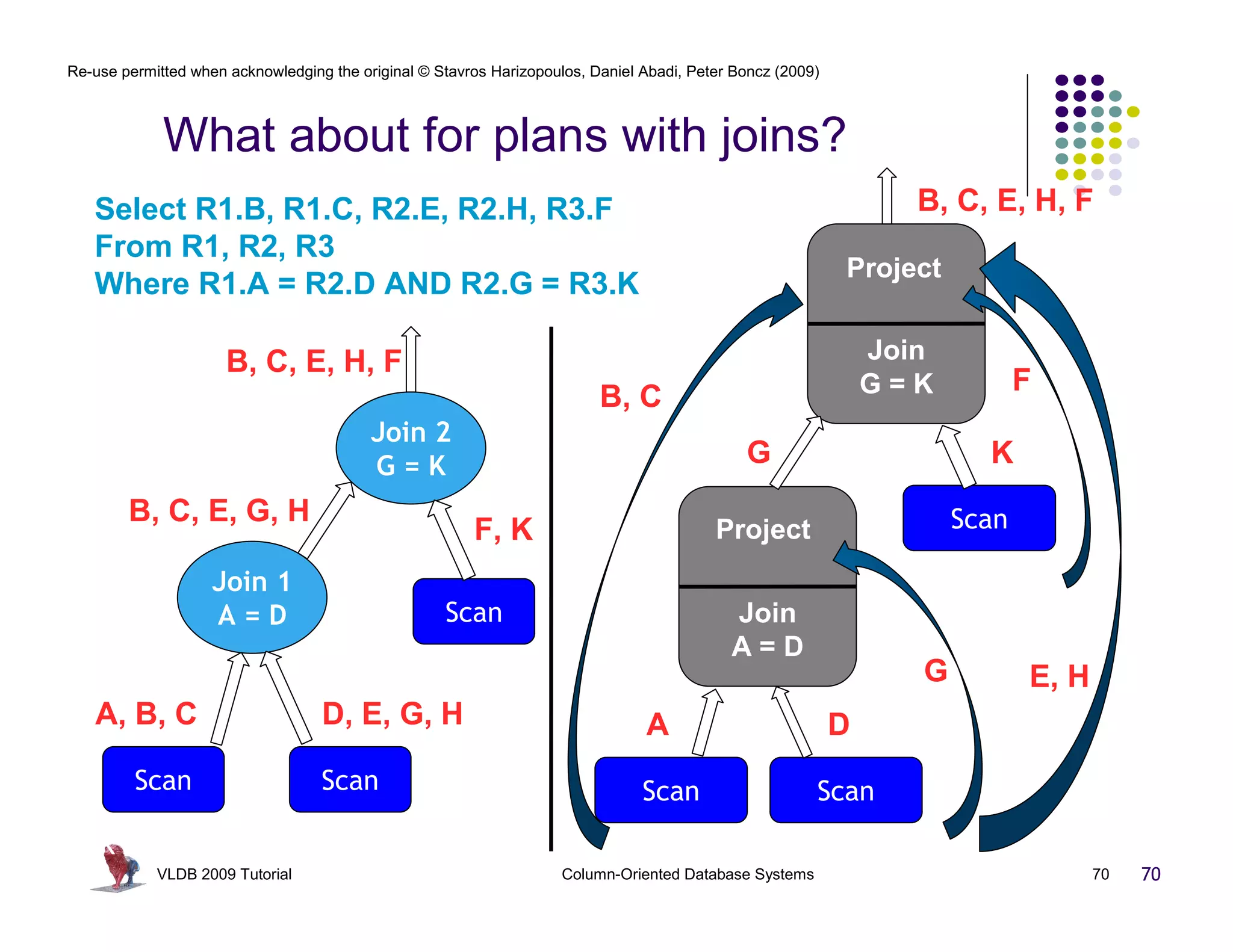

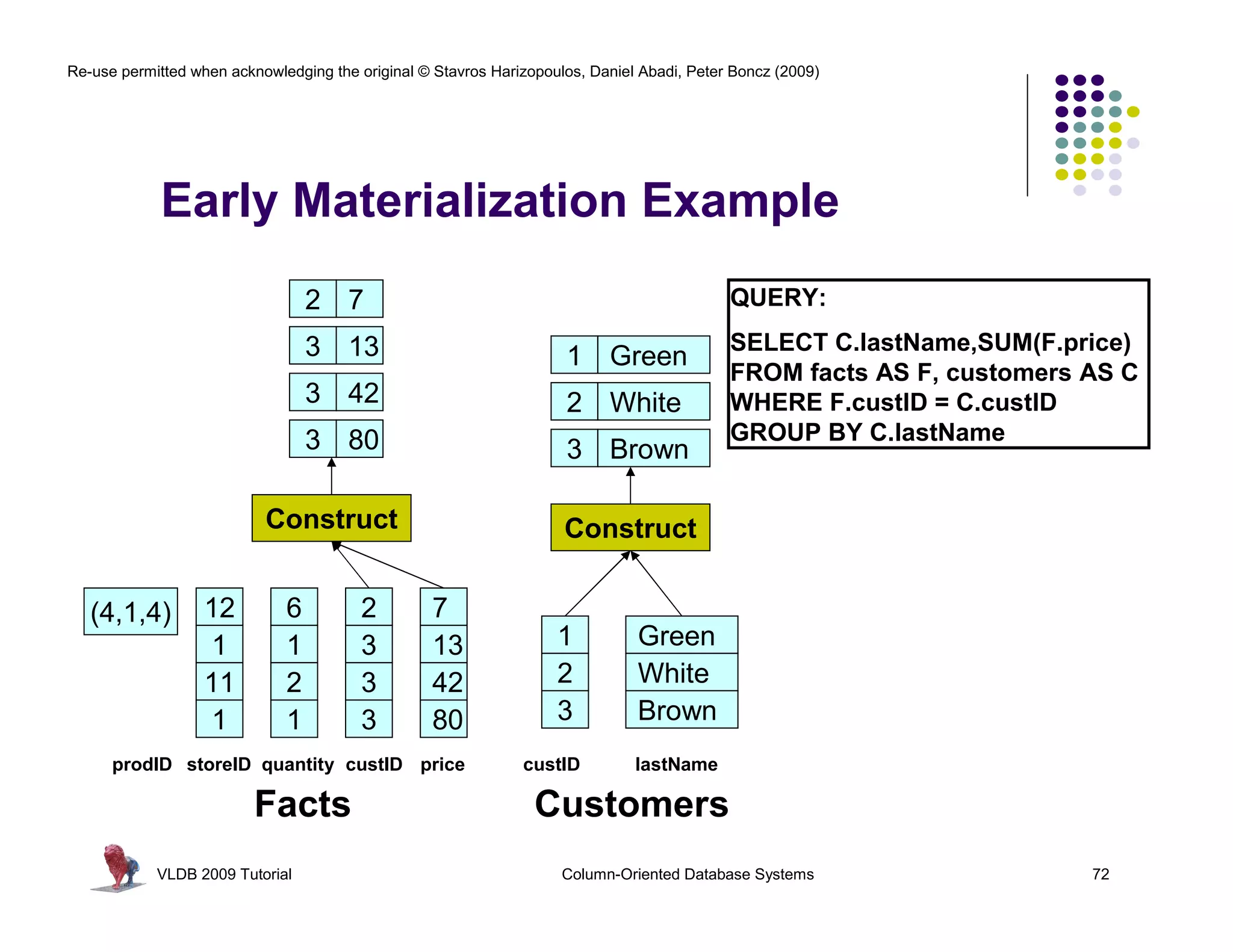
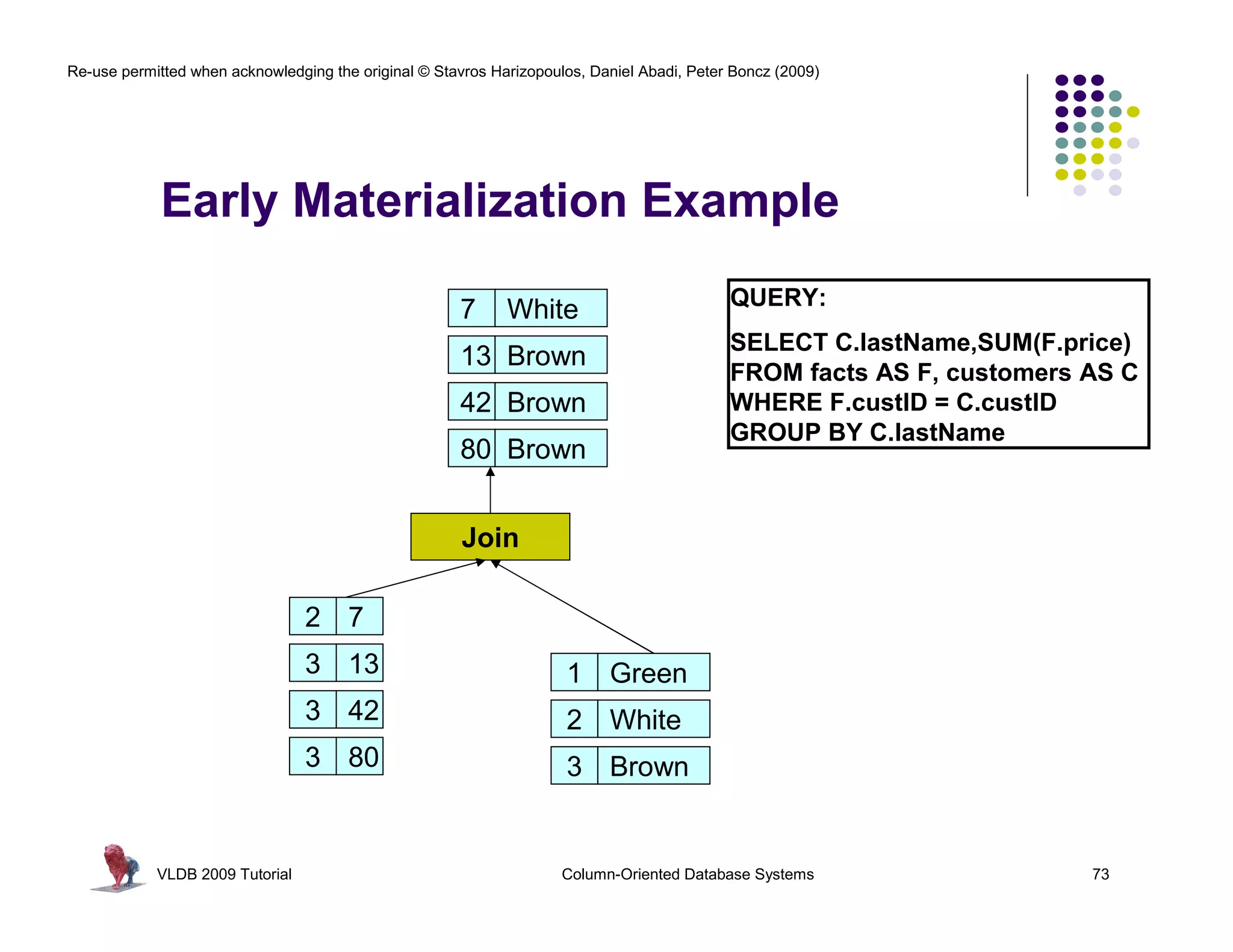
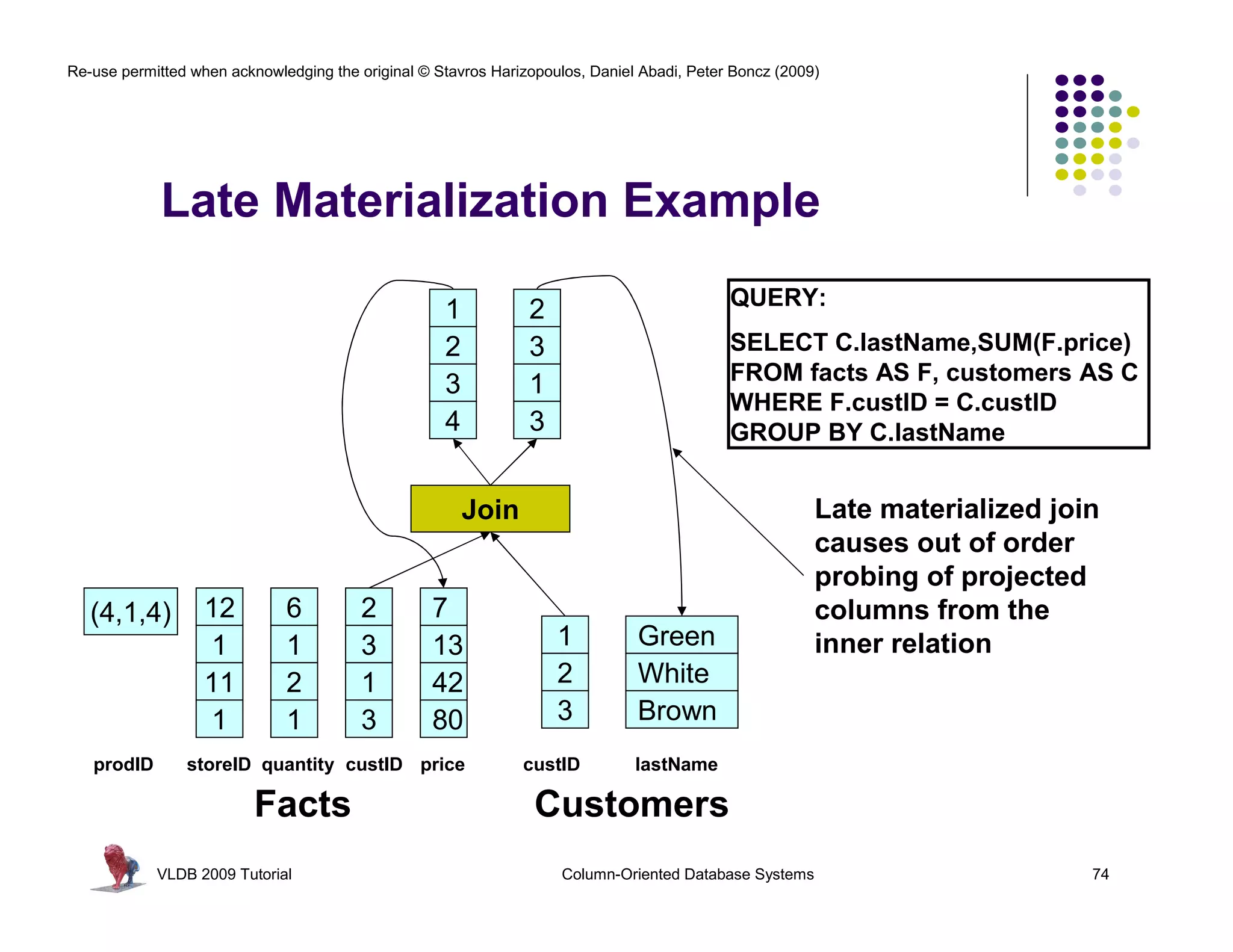


![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
“Column-Stores vs Row-Stores: How
Different are They Really?” Abadi,
Invisible Join Madden, and Hachem. SIGMOD 2008.
Apply “region = ‘Asia’” On Customer Table
custkey region nation …
1 ASIA CHINA … Hash Table (or bit-map)
2 ASIA INDIA … Containing Keys 1, 2 and 3
3 ASIA INDIA …
4 EUROPE FRANCE …
Apply “region = ‘Asia’” On Supplier Table
suppkey region nation …
1 ASIA RUSSIA … Hash Table (or bit-map)
2 EUROPE SPAIN … Containing Keys 1, 3
3 ASIA JAPAN …
Apply “year in [1992,1997]” On Date Table
dateid year …
01011997 1997 … Hash Table Containing
01021997 1997 … Keys 01011997, 01021997,
01031997 1997 …
and 01031997
VLDB 2009 Tutorial Column-Oriented Database Systems 77](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-77-2048.jpg)
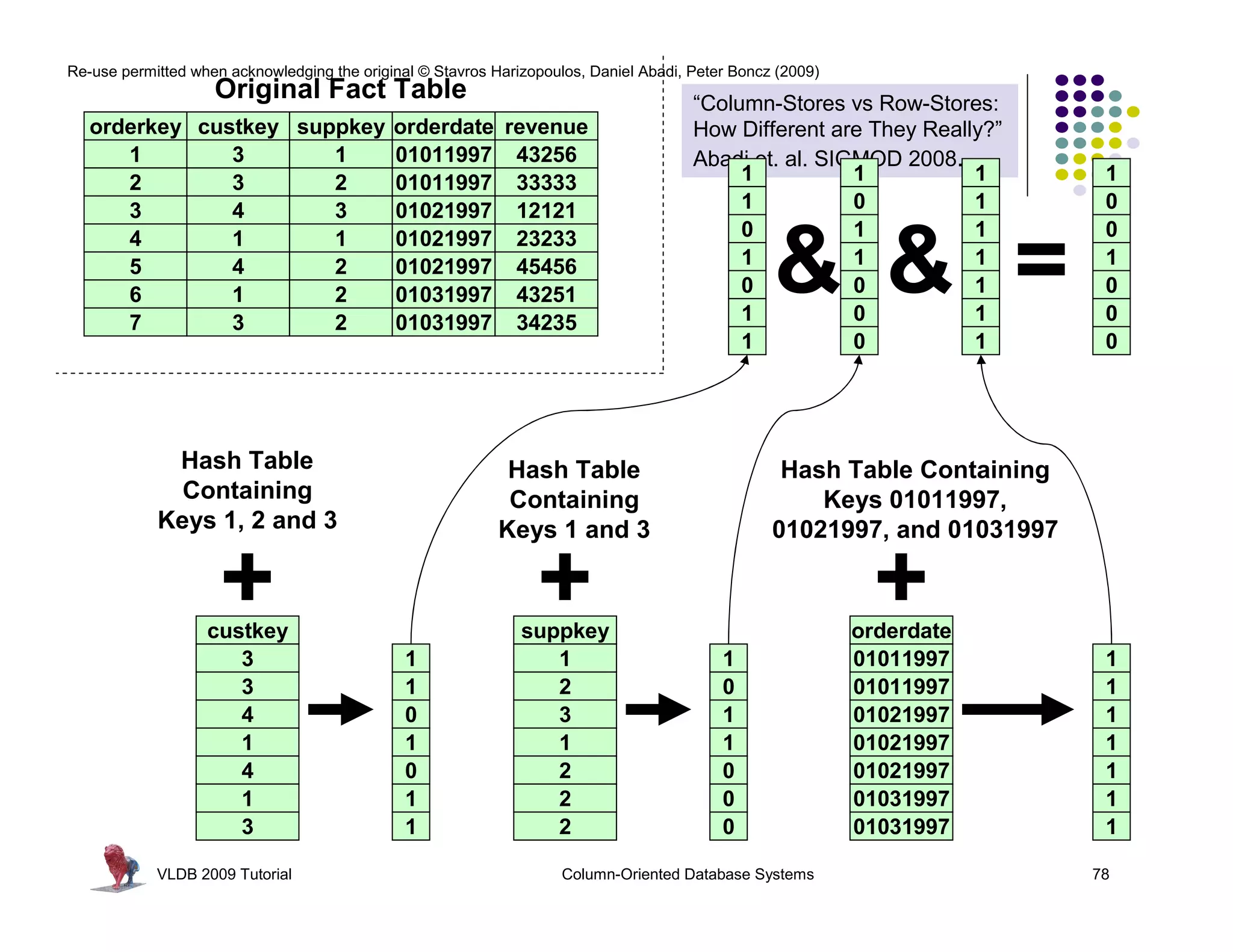
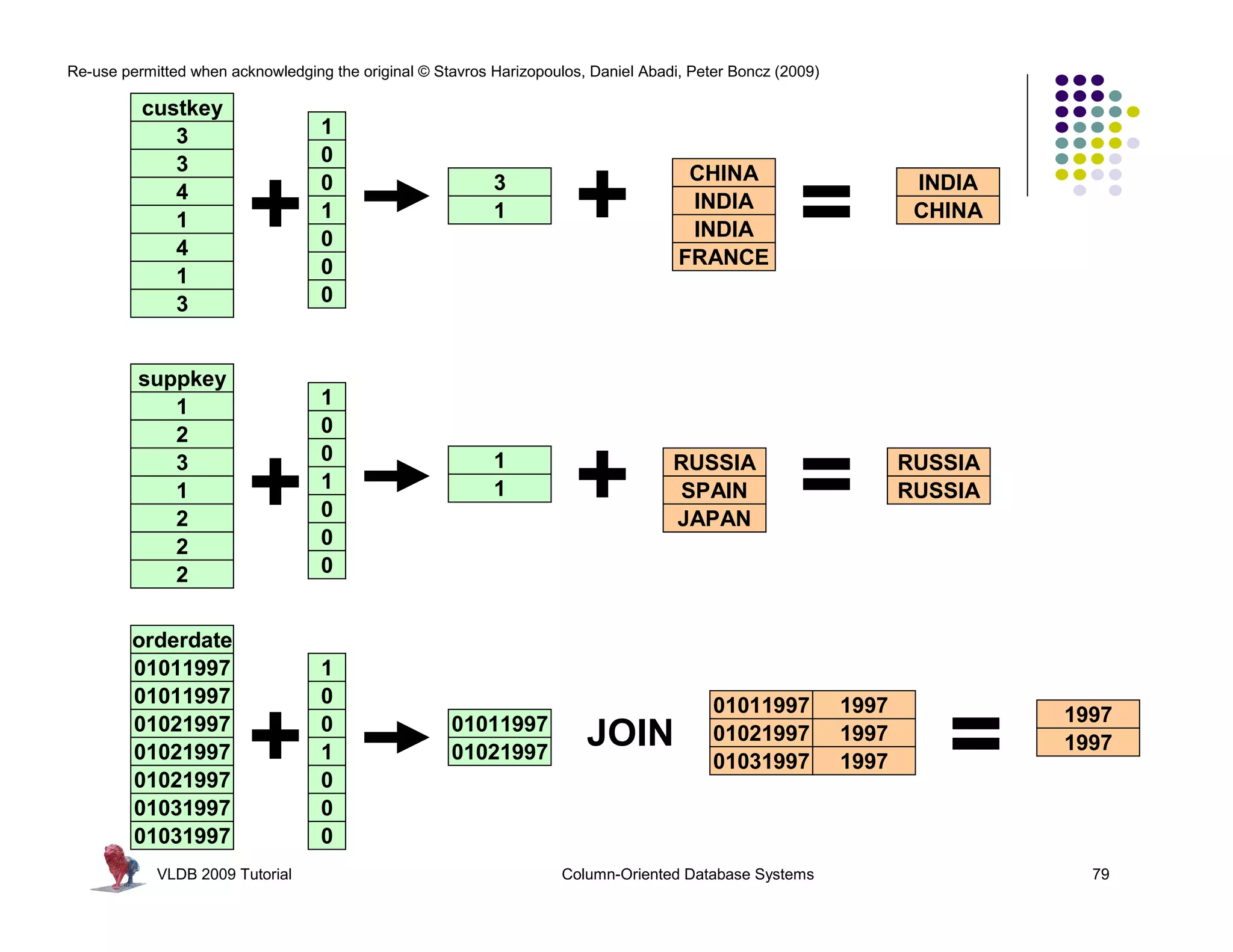
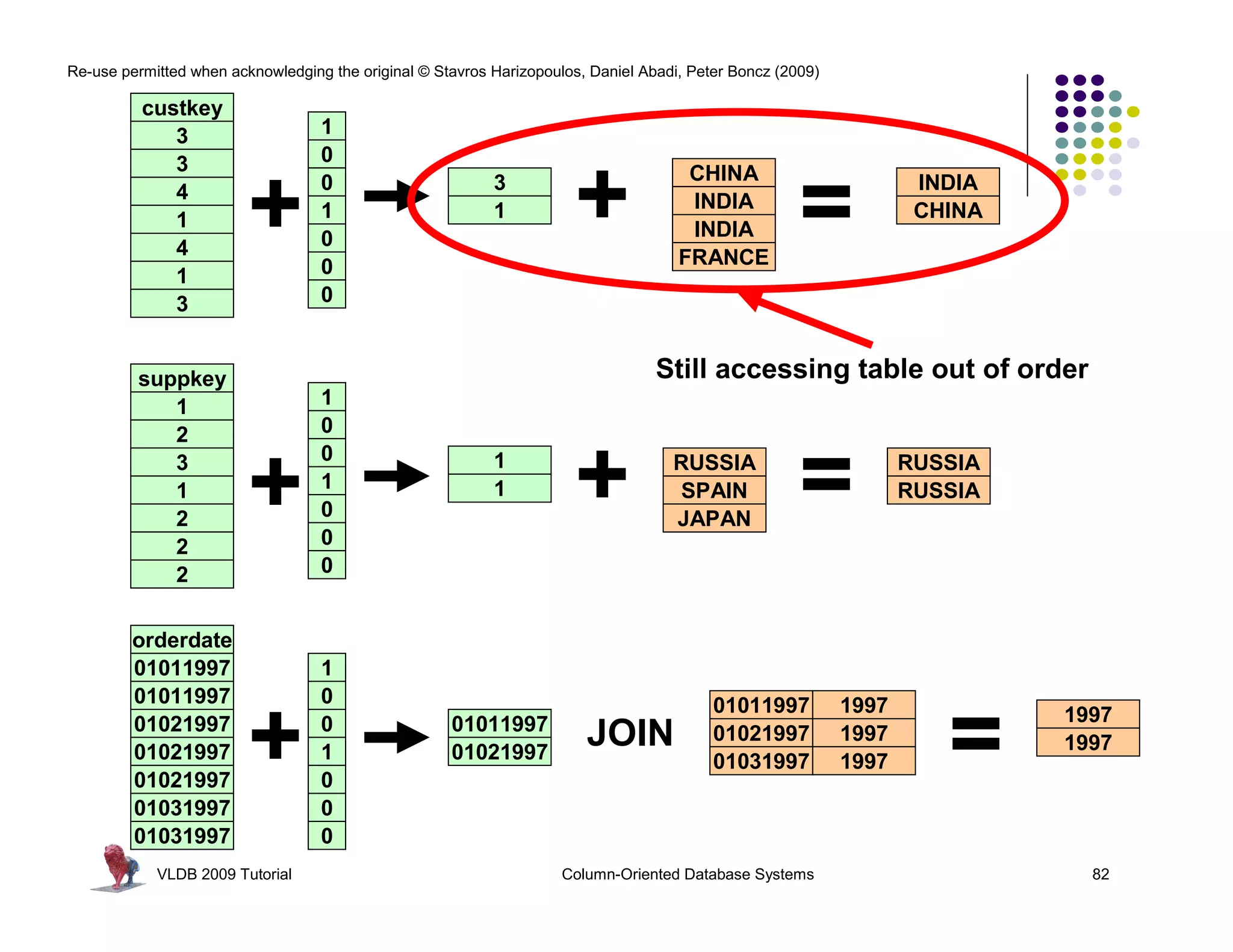
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
“Column-Stores vs Row-Stores: How
Different are They Really?” Abadi,
Madden, and Hachem. SIGMOD 2008.
Invisible Join
Apply “region = ‘Asia’” On Customer Table
custkey region nation …
1 ASIA CHINA … Hash Table (or bit-map)
2 ASIA INDIA … Containing Keys 1, 2 and 3
3 ASIA INDIA …
4 EUROPE FRANCE …
Range [1-3]
(between-predicate rewriting)
Apply “region = ‘Asia’” On Supplier Table
suppkey region nation …
1 ASIA RUSSIA … Hash Table (or bit-map)
2 EUROPE SPAIN … Containing Keys 1, 3
3 ASIA JAPAN …
Apply “year in [1992,1997]” On Date Table
dateid year …
01011997 1997 … Hash Table Containing
01021997 1997 … Keys 01011997, 01021997,
01031997 1997 …
and 01031997
VLDB 2009 Tutorial Column-Oriented Database Systems 80](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-80-2048.jpg)








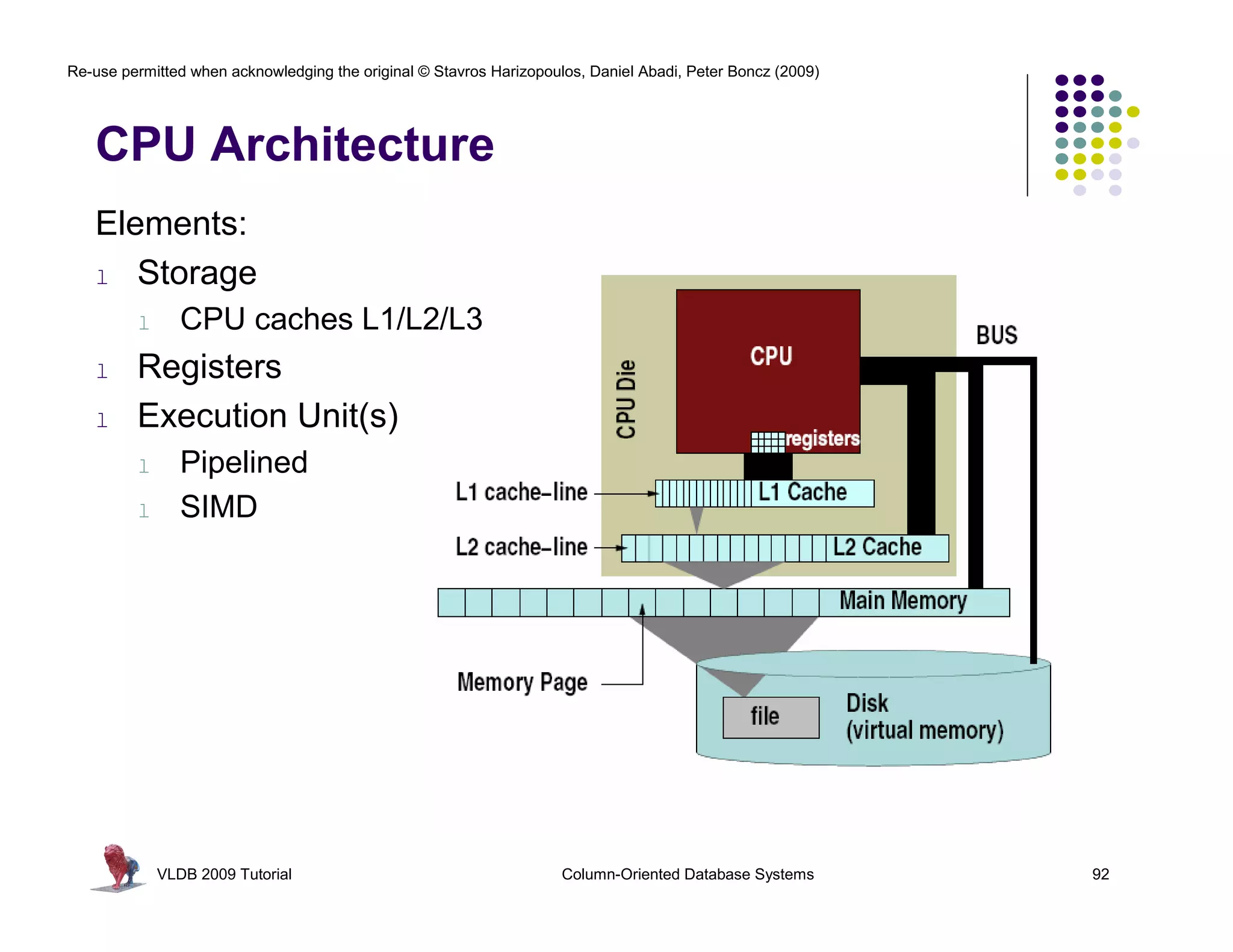

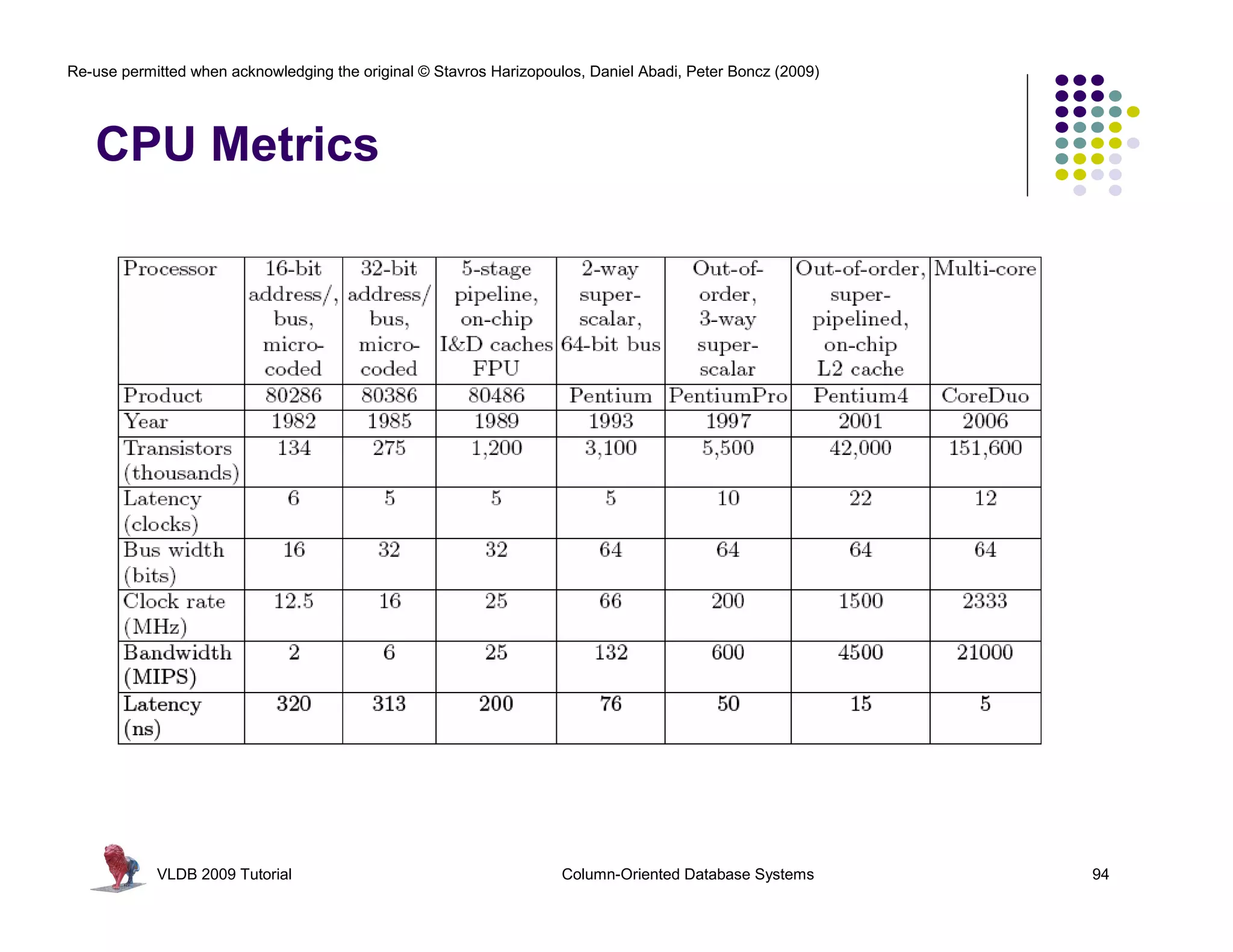
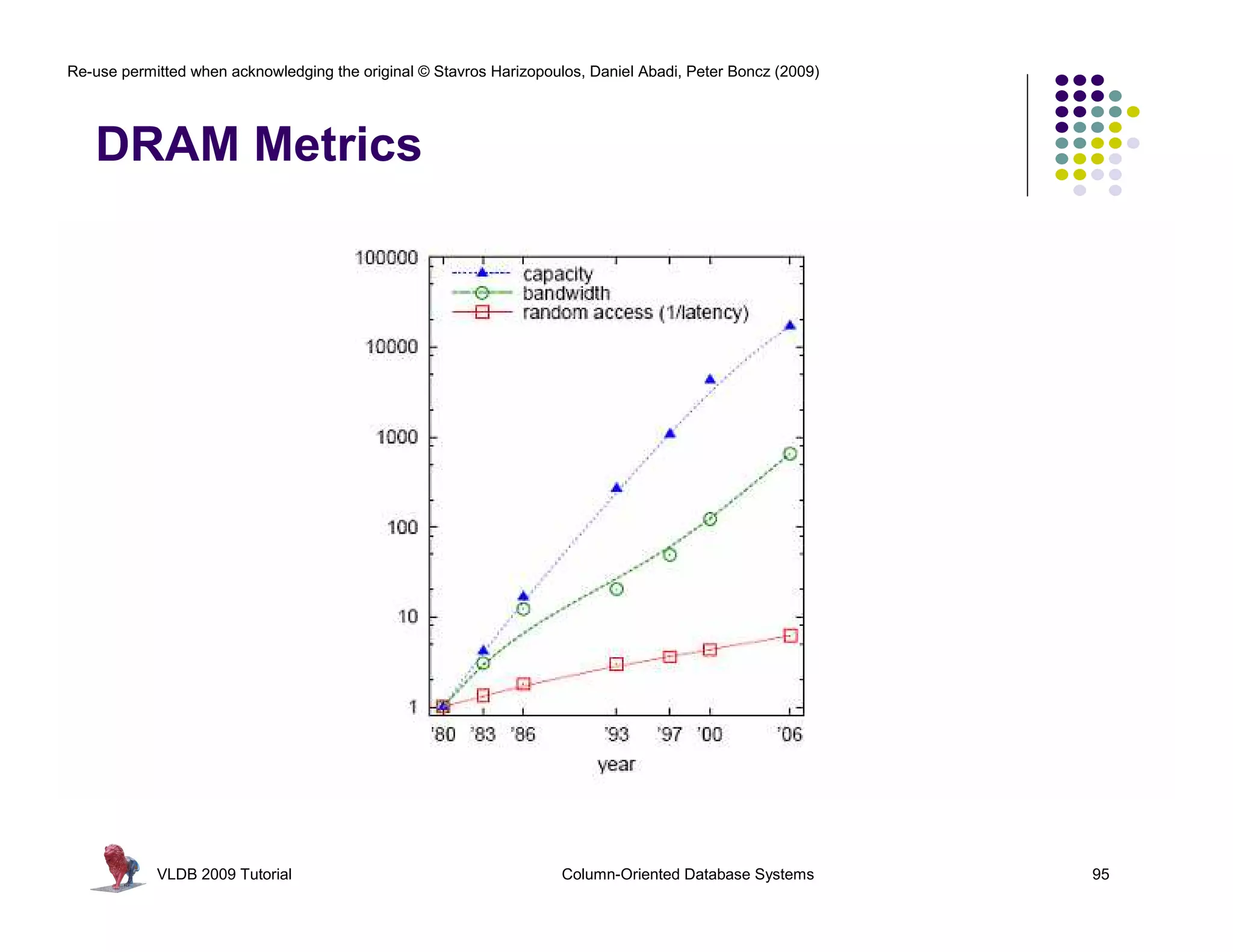
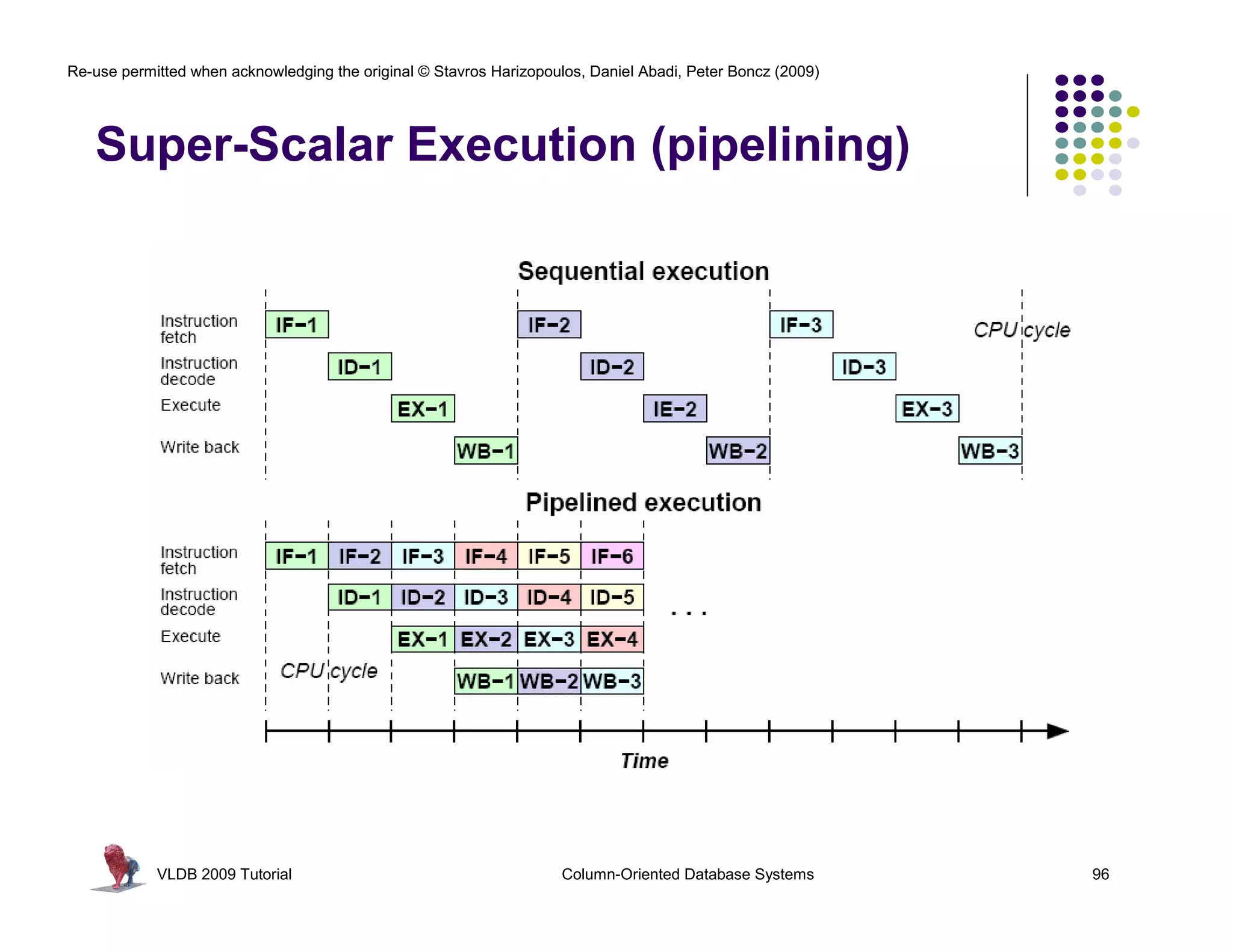






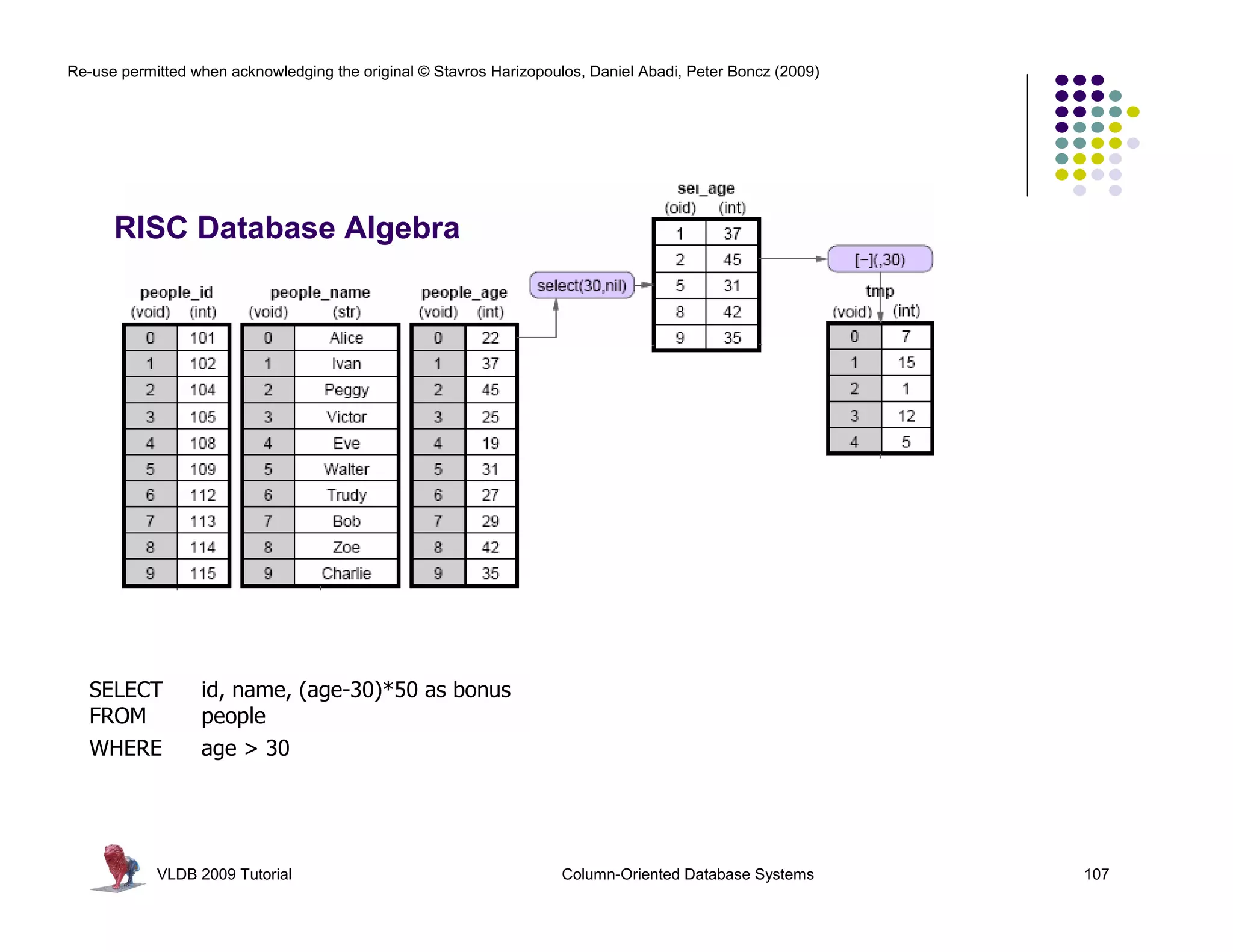
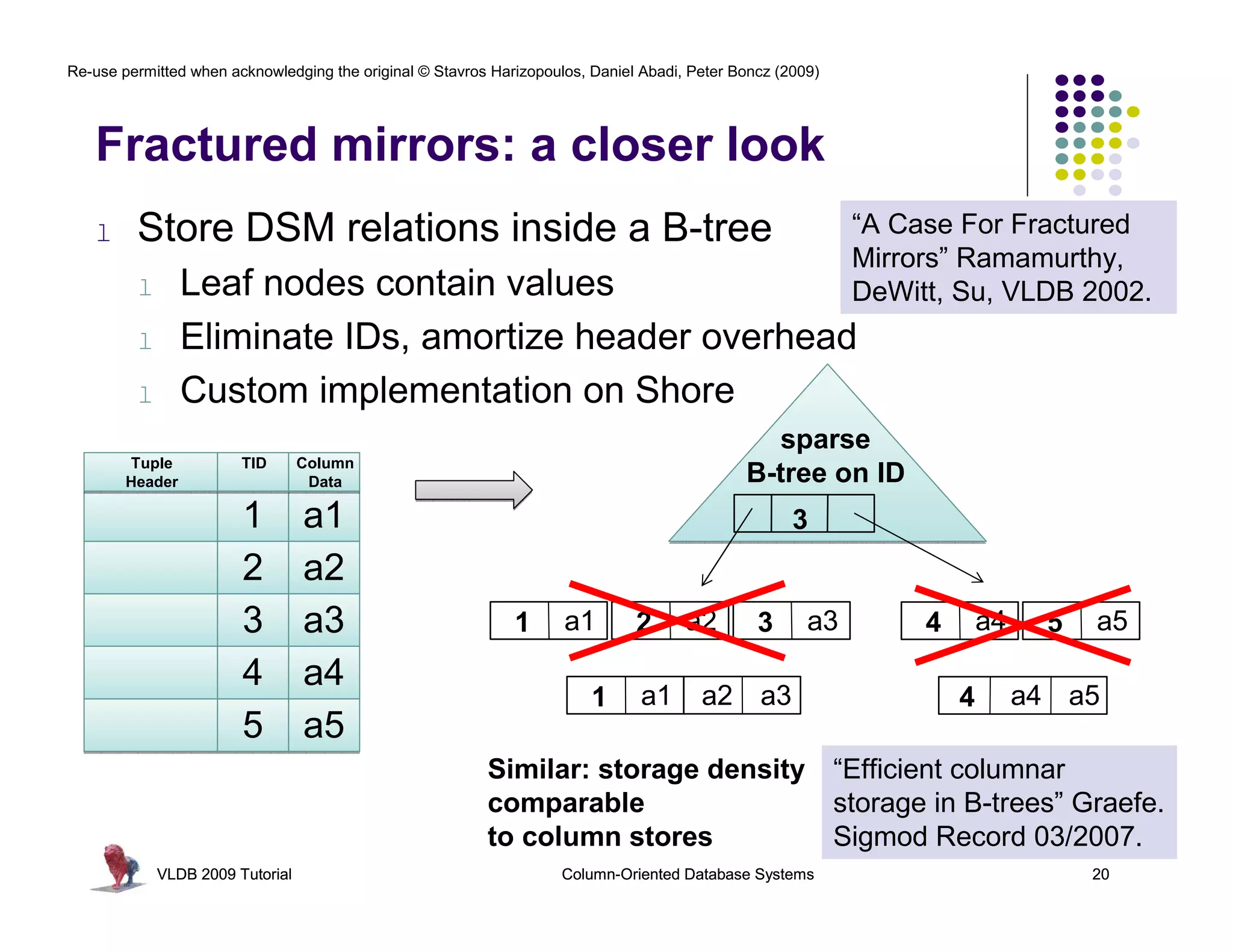
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
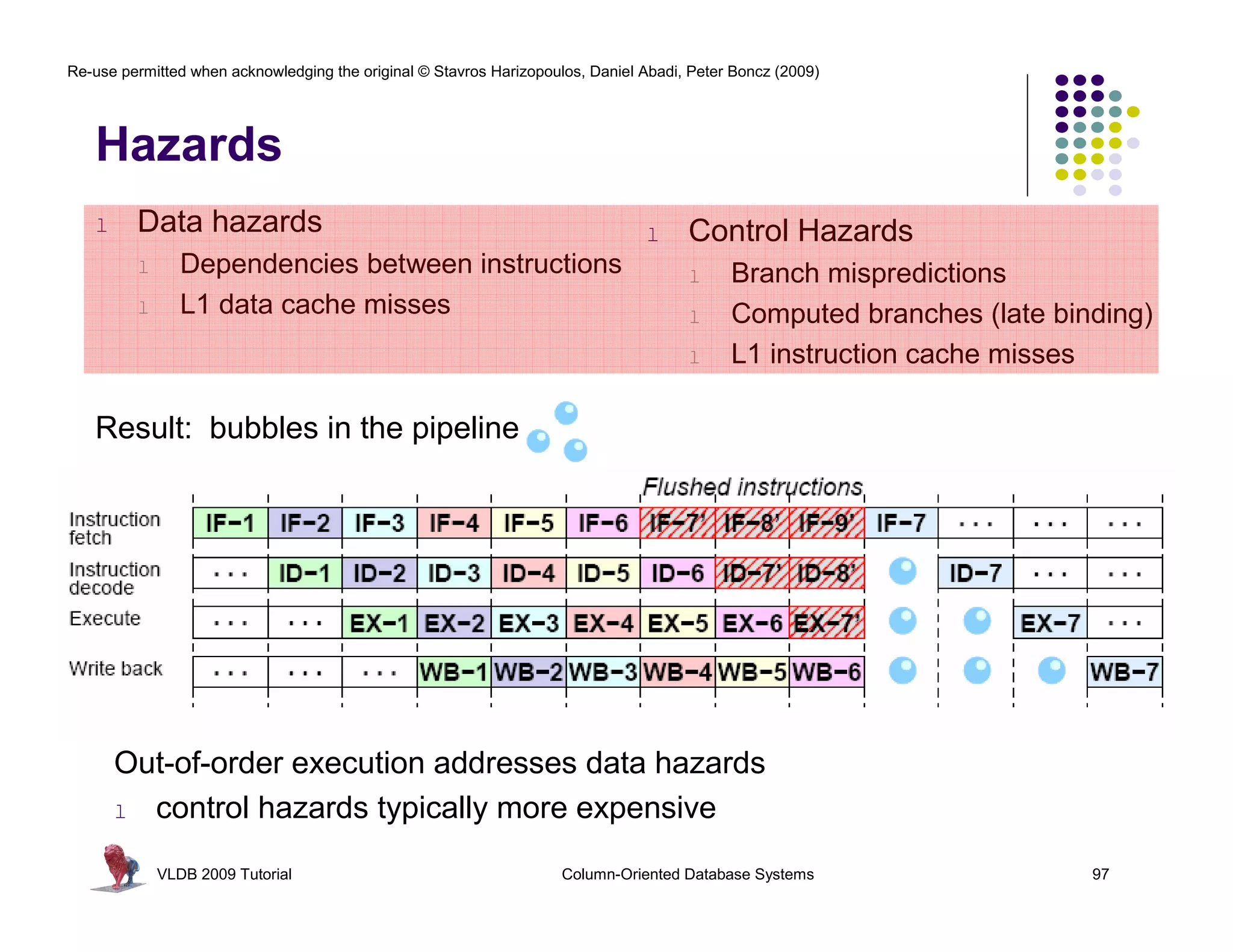
RISC Database Algebra
CPU happy? Give it “nice” code !
- few dependencies (control,data)
- CPU gets out-of-order execution
- compiler can e.g. generate SIMD
One loop for an entire column Simple, hard-
- no per-tuple interpretation
batcalc_minus_int(int* res, coded semantics
int* col,
- arrays: no record navigation
int val, in operators
- better instruction cache locality
int n)
{
for(i=0; i<n; i++) as bonus
SELECT id, name, (age-30)*50
FROM res[i] = col[i] - val;
people
} WHERE age > 30
VLDB 2009 Tutorial Column-Oriented Database Systems 108](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-108-2048.jpg)
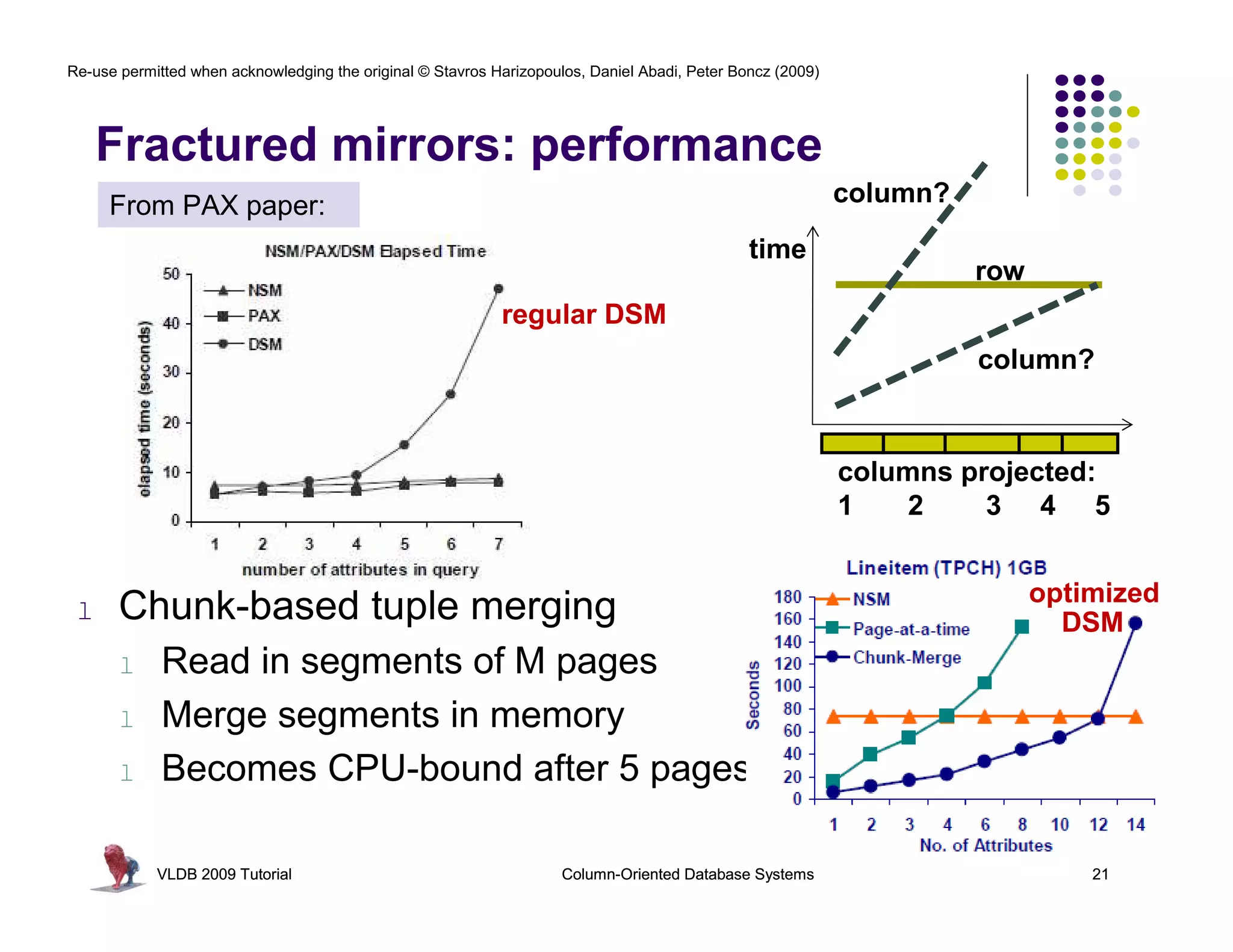
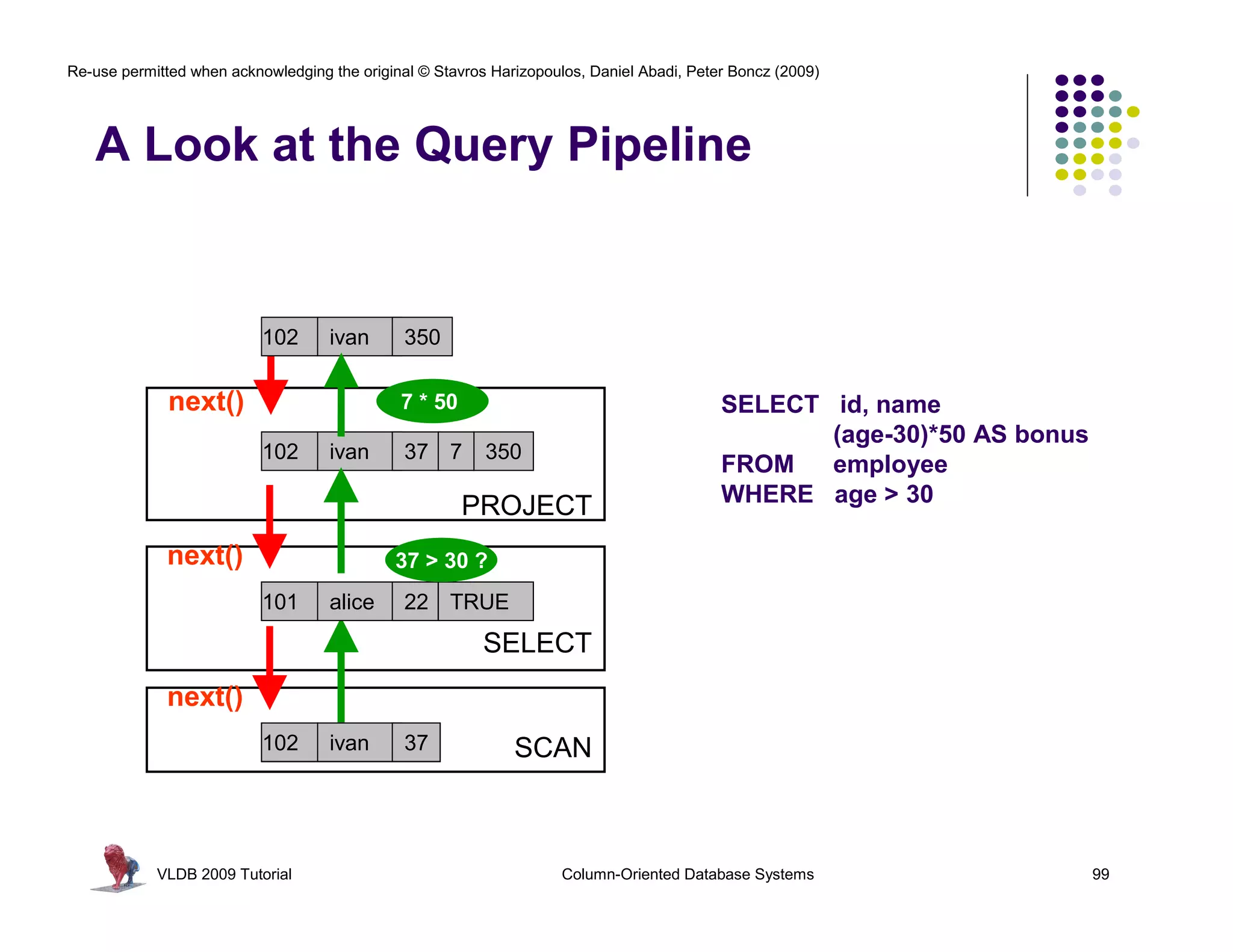
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
RISC Database Algebra
CPU happy? Give it “nice” code !
- few dependencies (control,data)
- CPU gets out-of-order execution
- compiler can e.g. generate SIMD
One loop for an entire column
- no per-tuple interpretation
batcalc_minus_int(int* res,
int* col,
- arrays: no record navigation
int val,
- better instruction cache locality
int n)
{ MATERIALIZED
for(i=0; i<n; i++) as bonus
SELECT id, name, (age-30)*50 intermediate
FROM res[i] = col[i] - val;
people
} WHERE age > 30
results
VLDB 2009 Tutorial Column-Oriented Database Systems 109](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-109-2048.jpg)



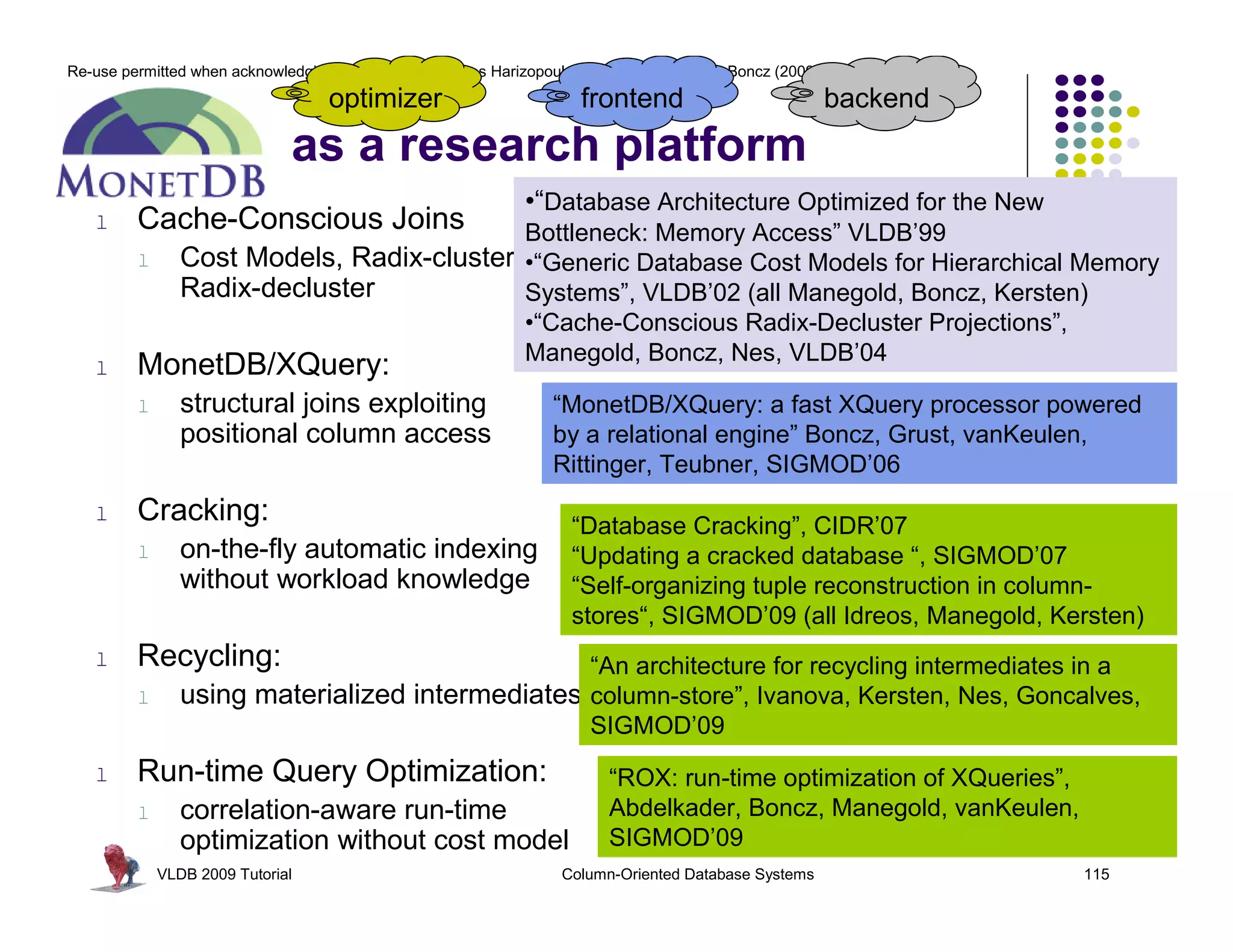


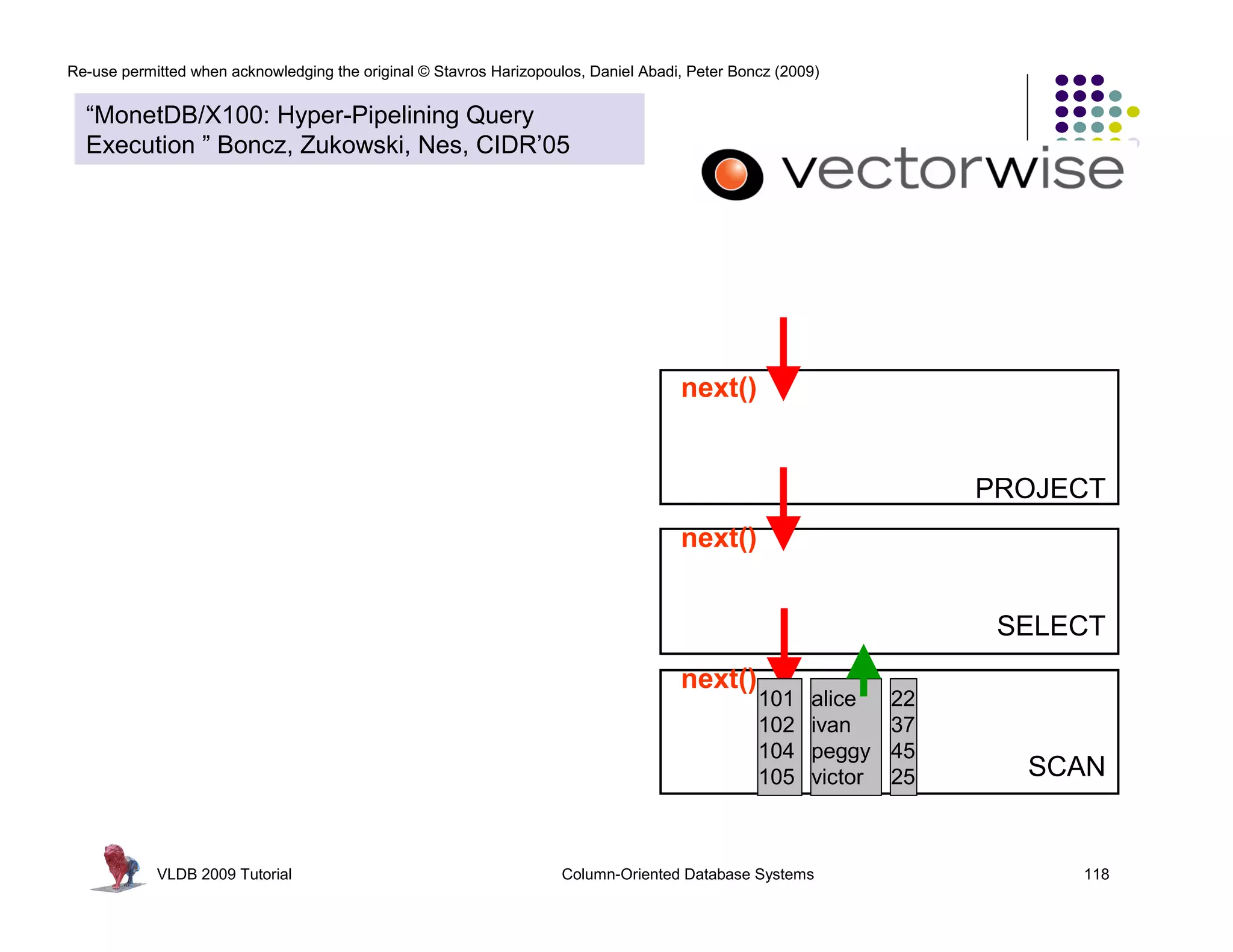
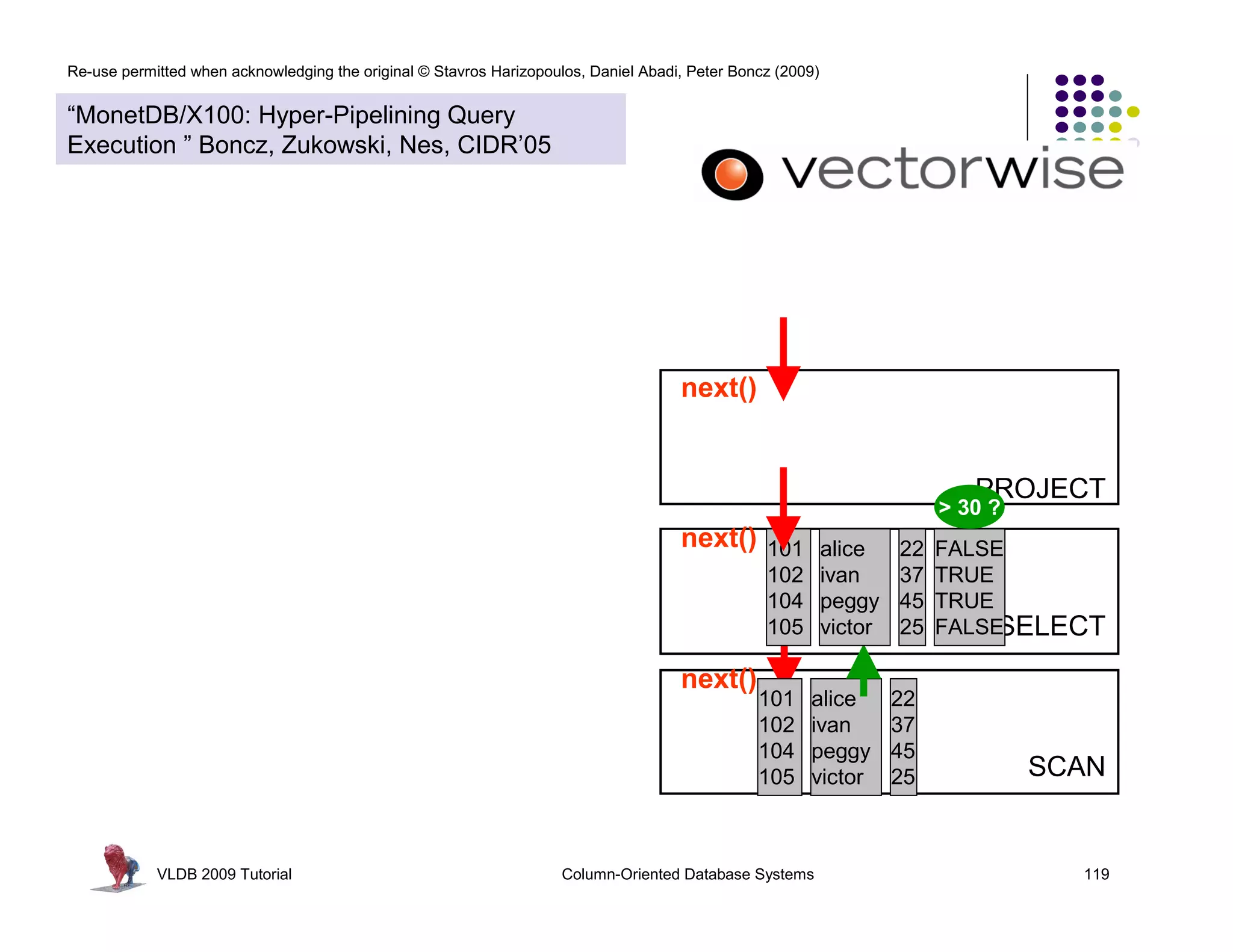
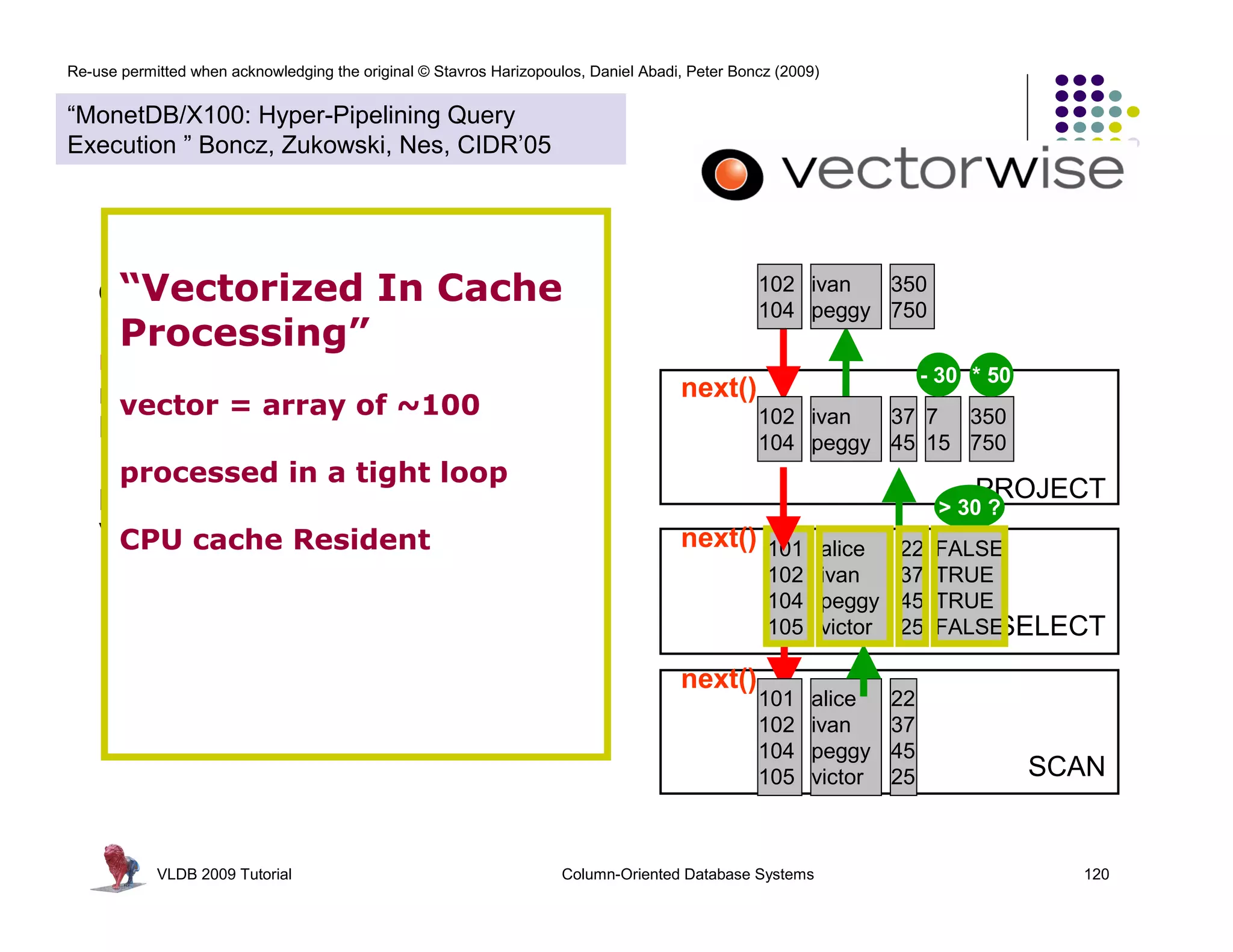
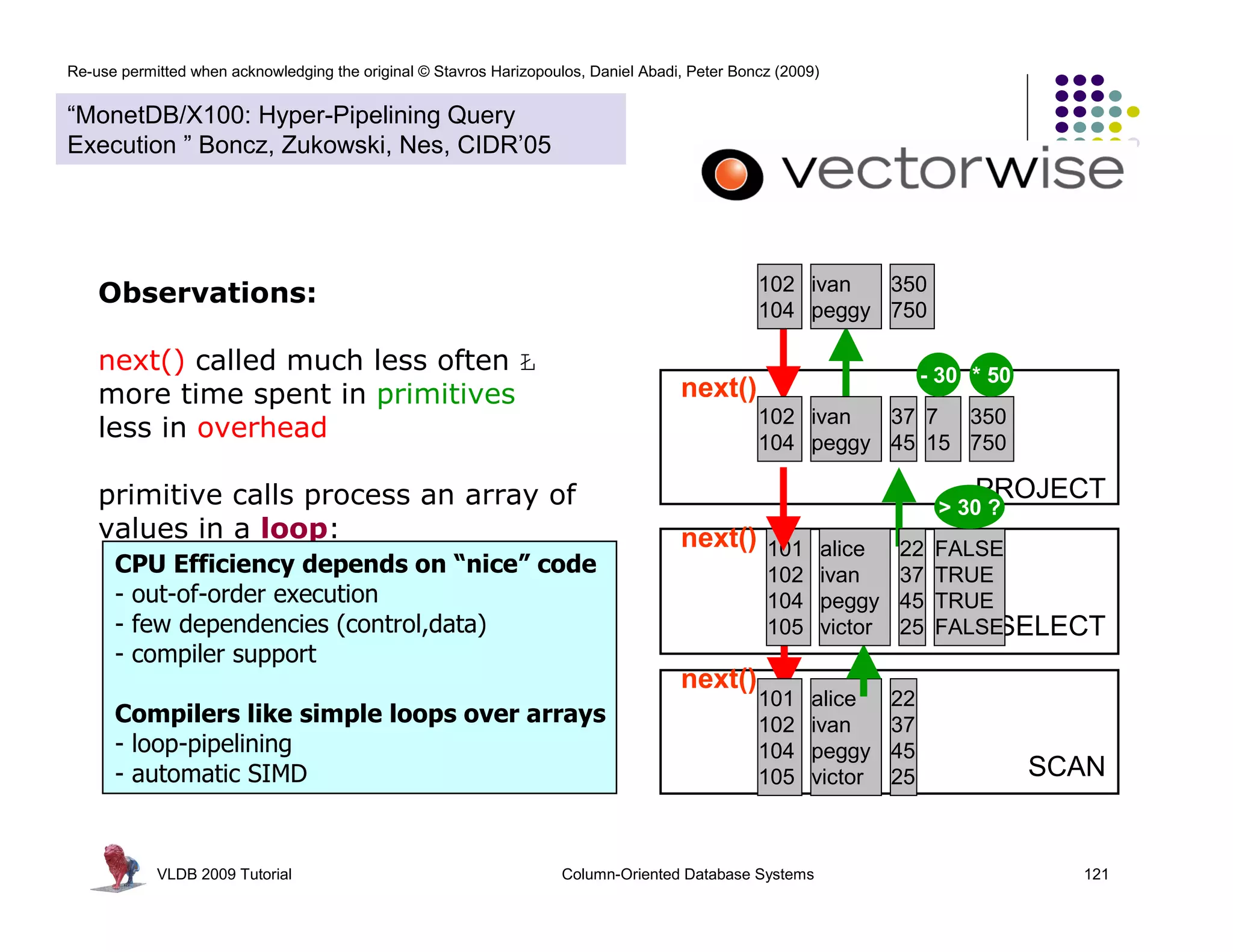
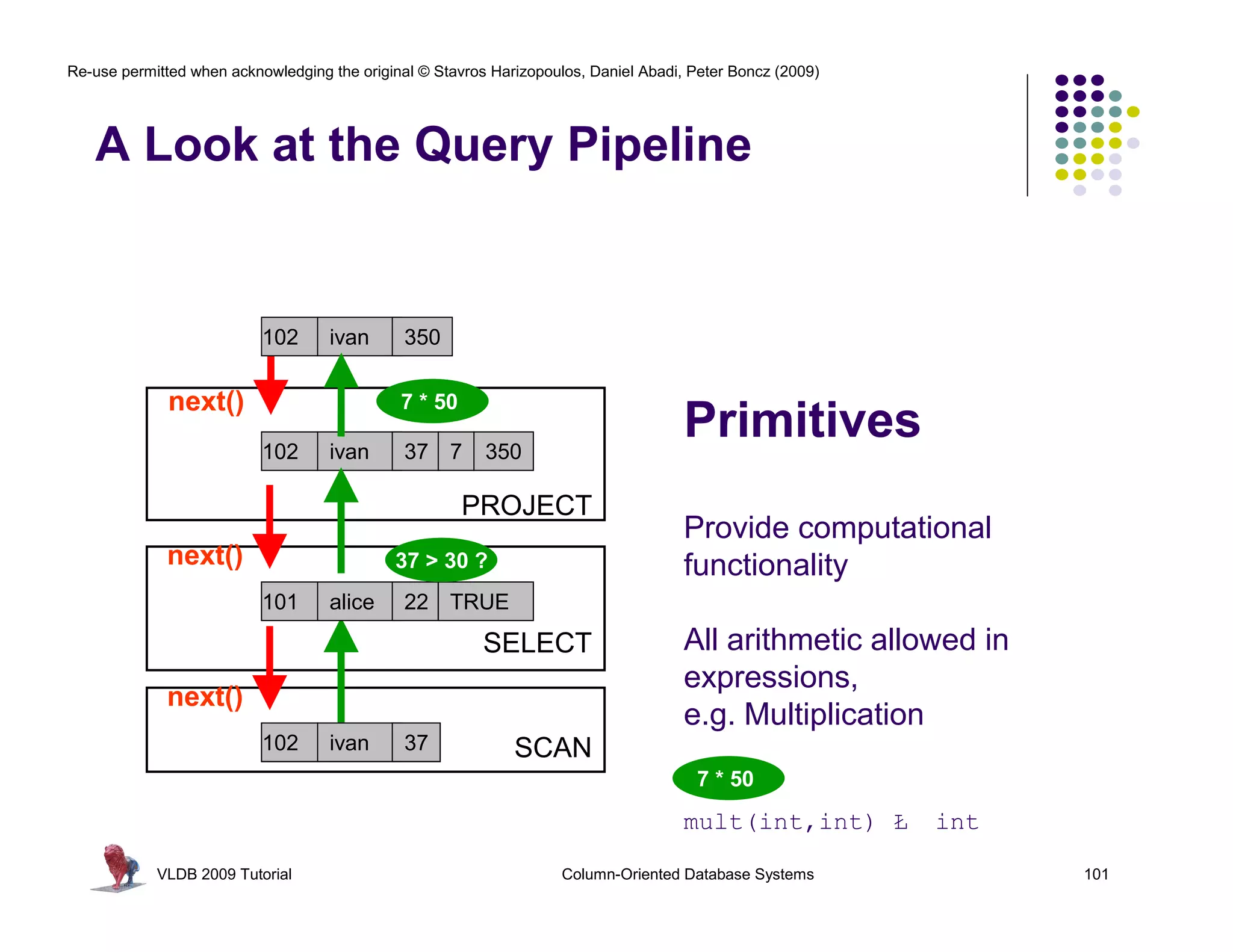
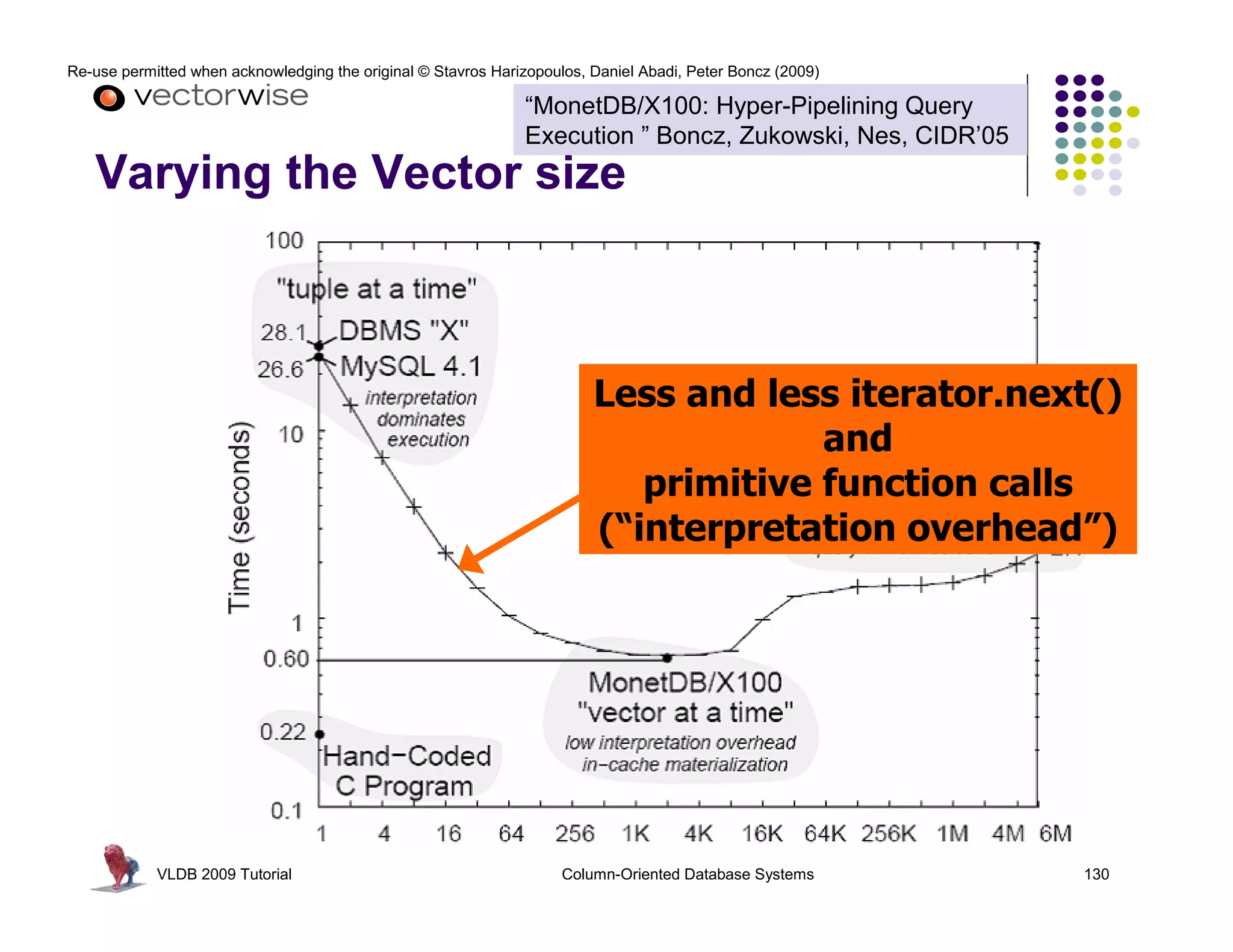
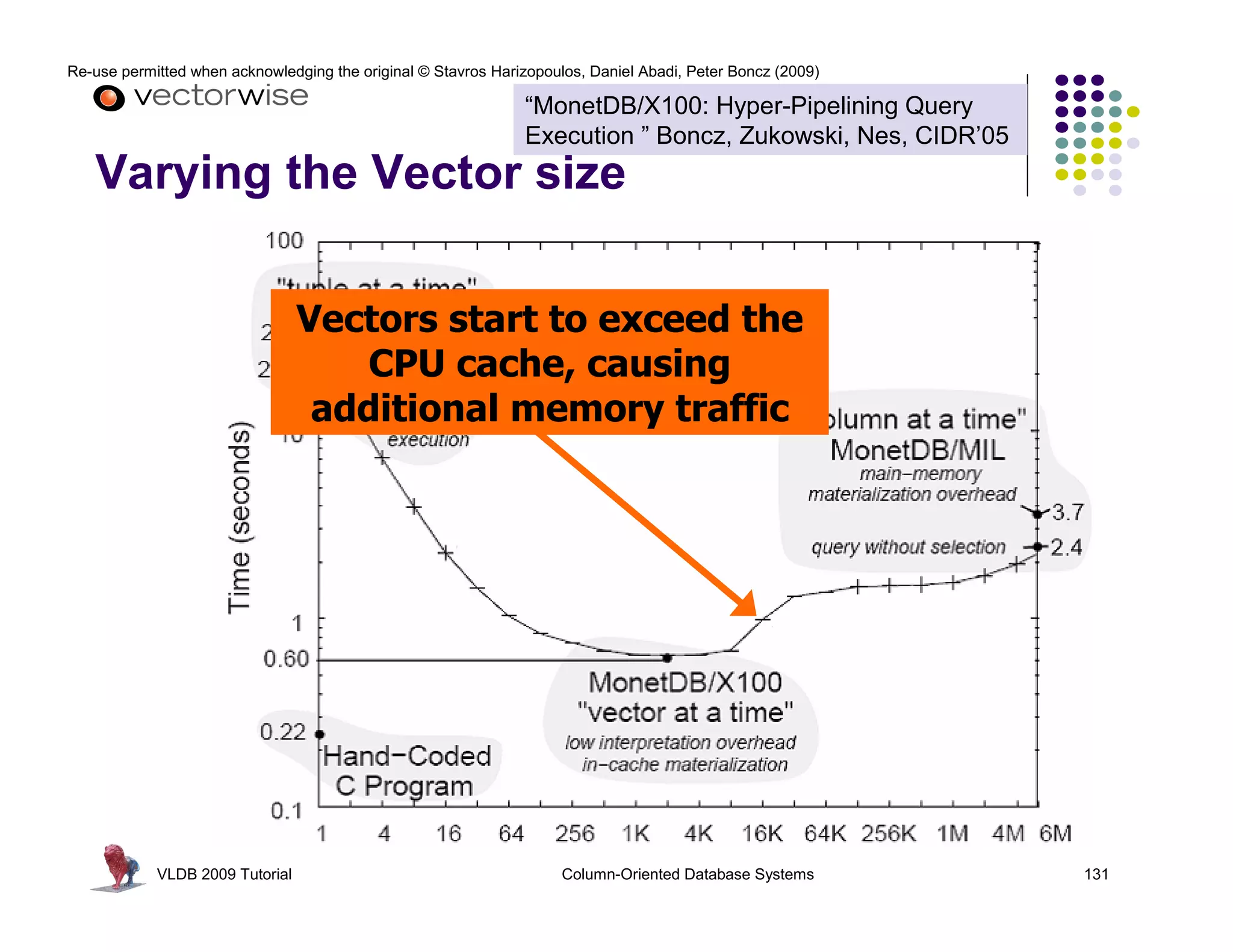
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
Observations: > 30 ?
FALSE for(i=0; i<n; i++)
next() called much less often Ł TRUE res[i] = (col[i] > x)
TRUE * 50
more time spent in primitives FALSE 350
less in overhead 750
- 30 PROJECT
primitive calls process an array of for(i=0; i<n; 30 ?
> i++)
values in a loop: 7
15 FALSE
res[i] = (col[i] - x)
CPU Efficiency depends on “nice” code TRUE
- out-of-order execution TRUE
- few dependencies (control,data) * 50 FALSESELECT
for(i=0; i<n; i++)
- compiler support
350 res[i] = (col[i] * x)
750
Compilers like simple loops over arrays
- loop-pipelining
- automatic SIMD SCAN
VLDB 2009 Tutorial Column-Oriented Database Systems 122](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-122-2048.jpg)
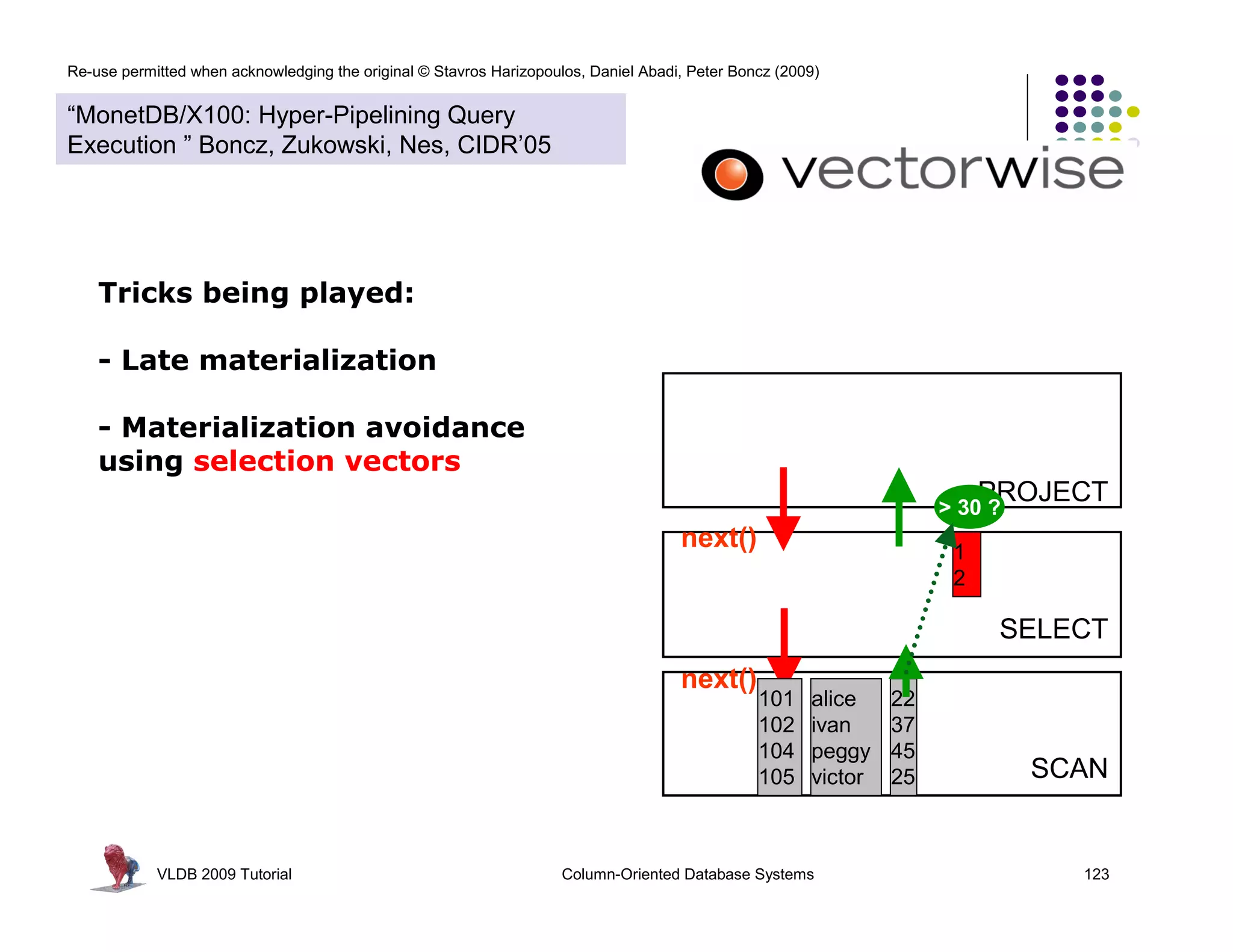
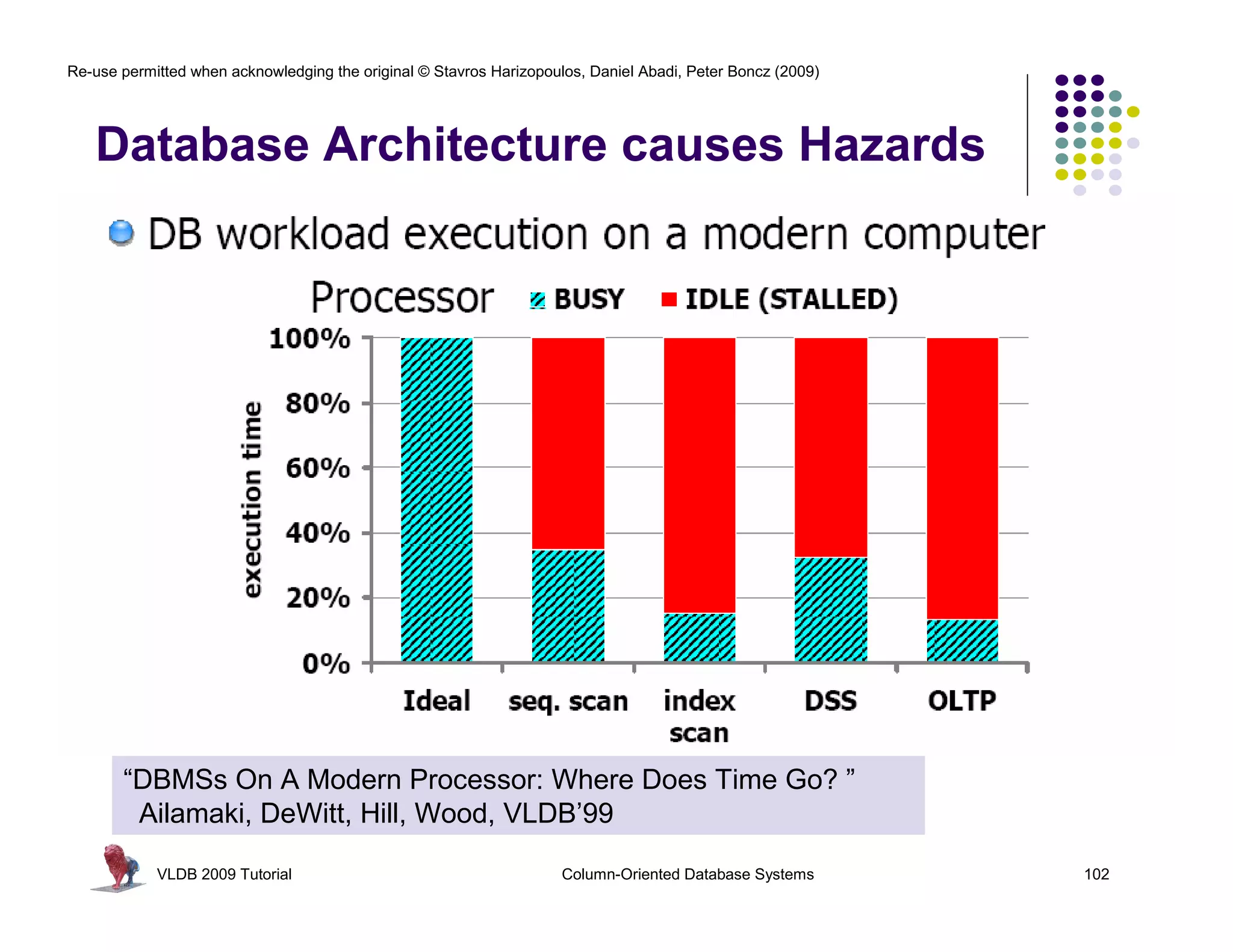
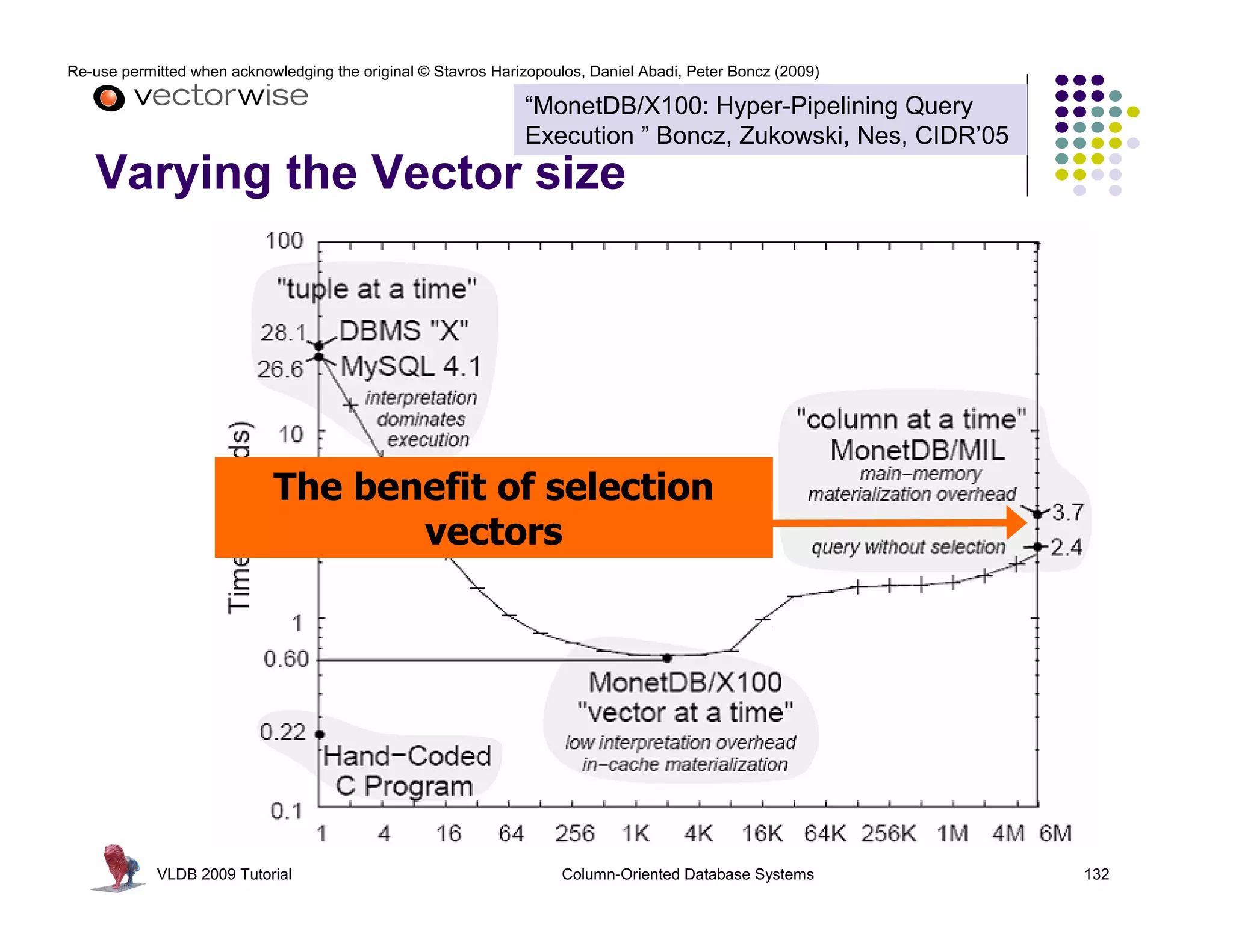
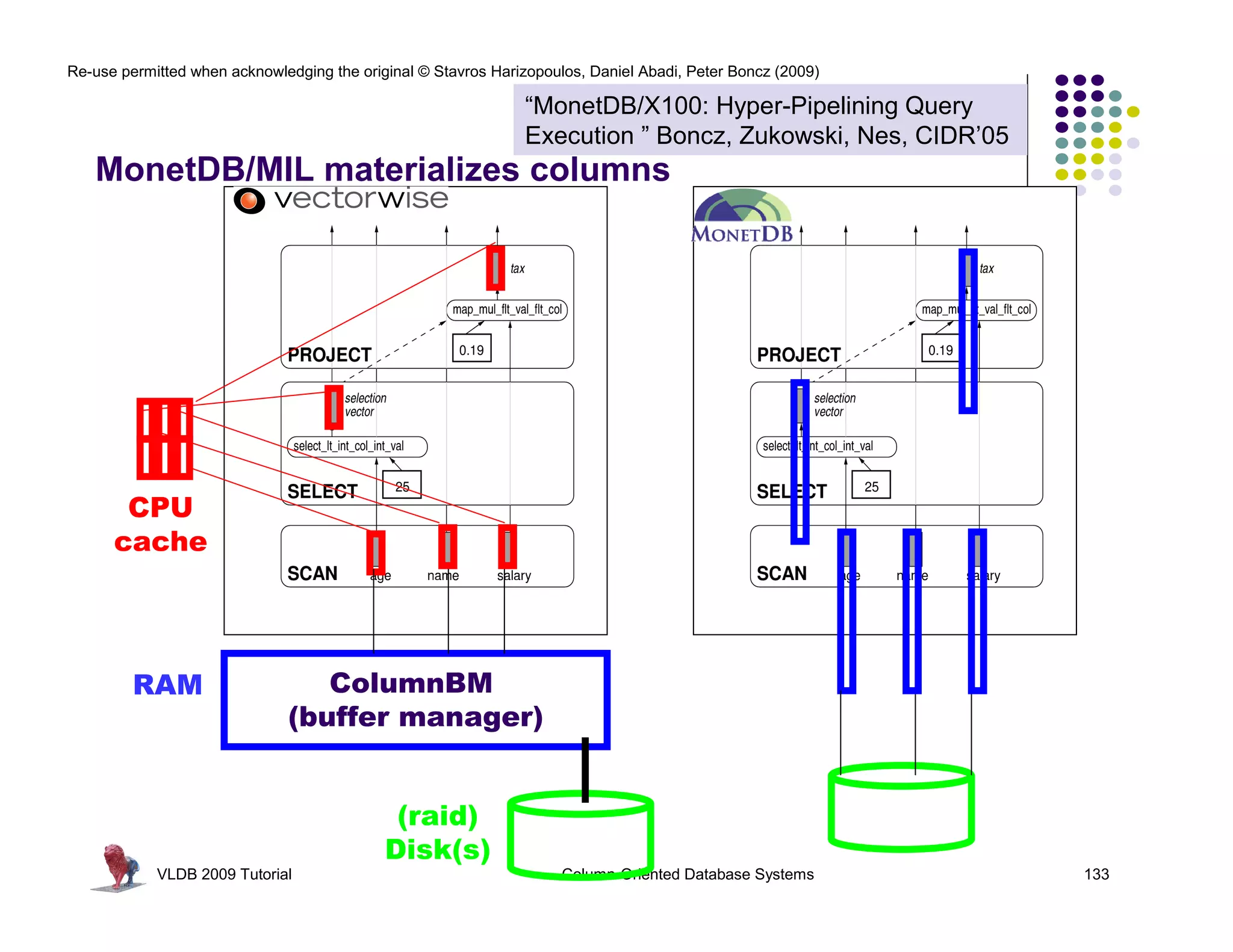
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
map_mul_flt_val_flt_col(
float *res,
int* sel,
Tricks being played:
float val,
float *col, int n)
- Late materialization - 30 * 50
next()
{
- Materialization avoidance 7 350
for(int i=0; i<n; i++) 15 750
using selection vectors
res[i] = val * col[sel[i]]; PROJECT
> 30 ?
}
next() 1
selection vectors used to reduce 2
vector copying SELECT
contain selected positions next()
101 alice 22
102 ivan 37
104 peggy 45
105 victor 25 SCAN
VLDB 2009 Tutorial Column-Oriented Database Systems 124](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-124-2048.jpg)
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
map_mul_flt_val_flt_col(
float *res,
int* sel,
Tricks being played:
float val,
float *col, int n)
- Late materialization - 30 * 50
next()
{
- Materialization avoidance 7 350
for(int i=0; i<n; i++) 15 750
using selection vectors
res[i] = val * col[sel[i]]; PROJECT
> 30 ?
}
next() 1
selection vectors used to reduce 2
vector copying SELECT
contain selected positions next()
101 alice 22
102 ivan 37
104 peggy 45
105 victor 25 SCAN
VLDB 2009 Tutorial Column-Oriented Database Systems 125](https://image.slidesharecdn.com/columnstoretutorialvldb09-100418160013-phpapp01/75/VLDB-2009-Tutorial-on-Column-Stores-125-2048.jpg)

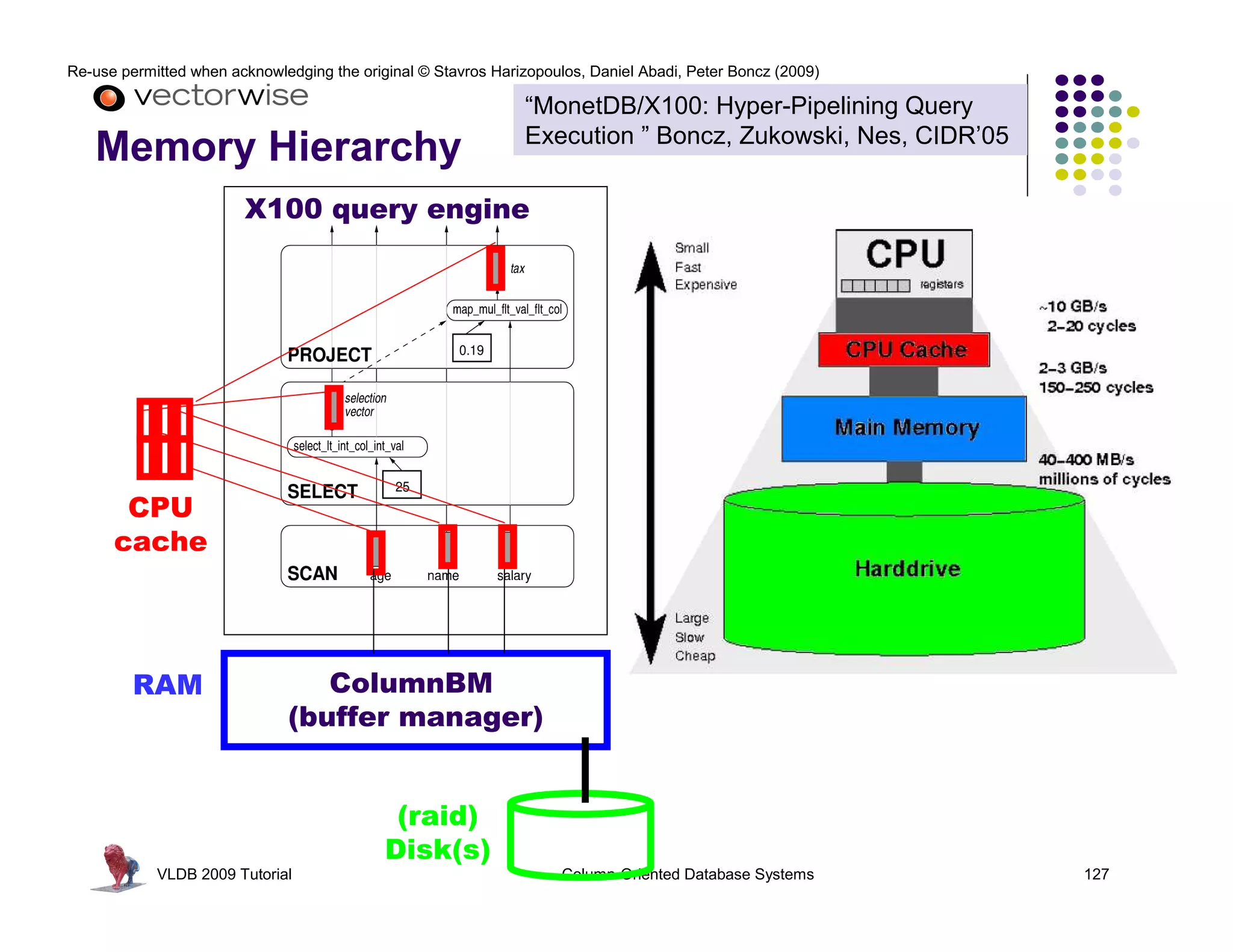
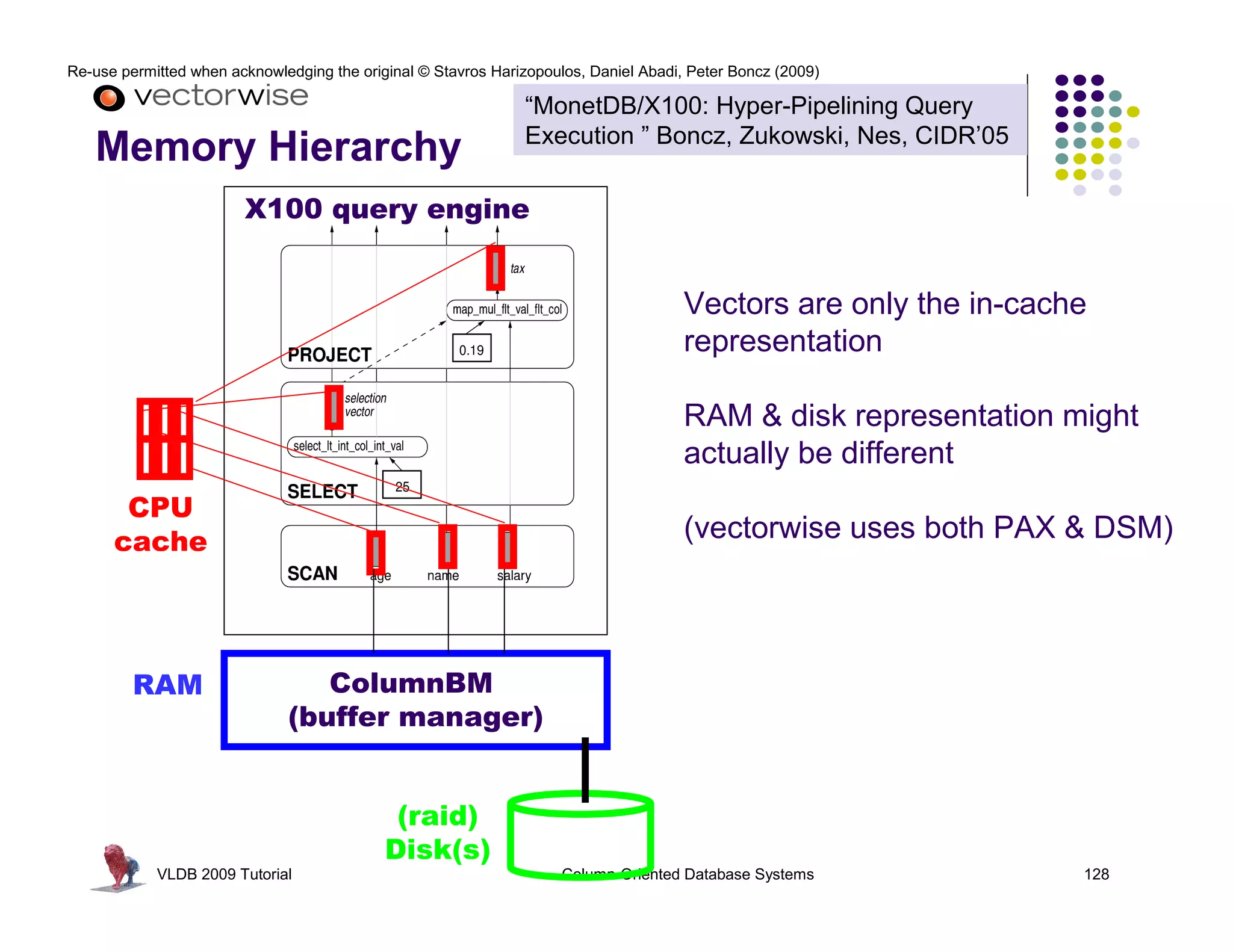
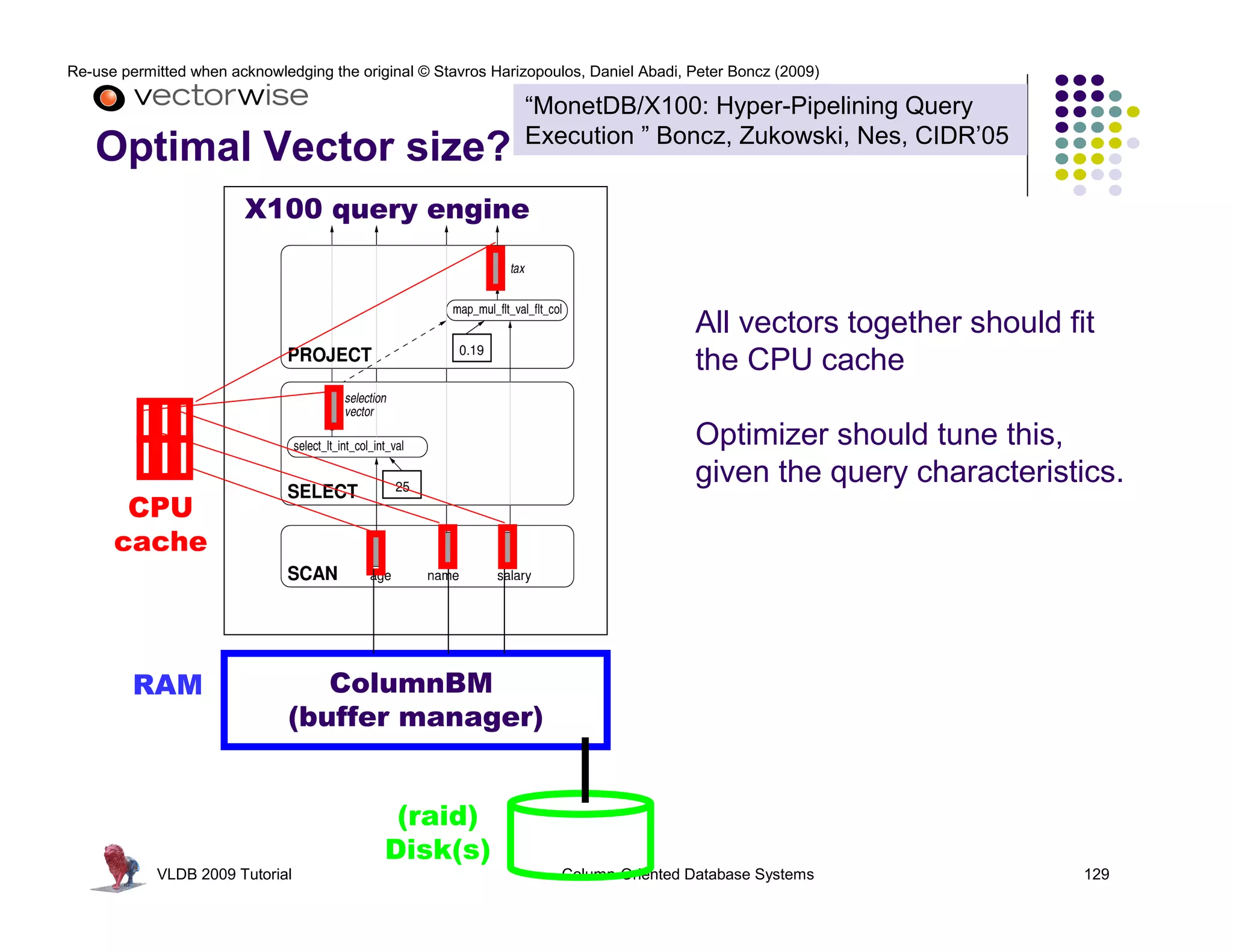









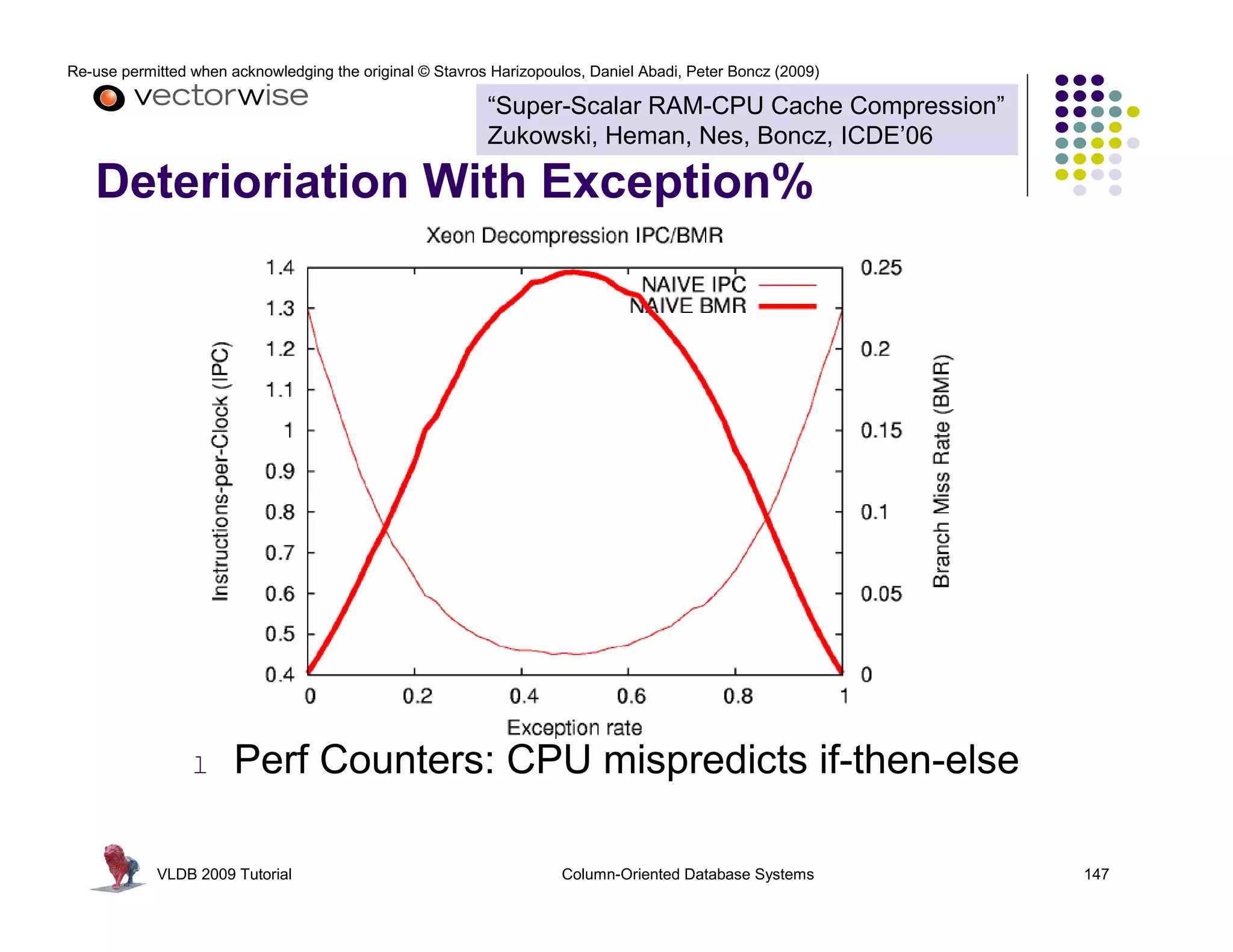

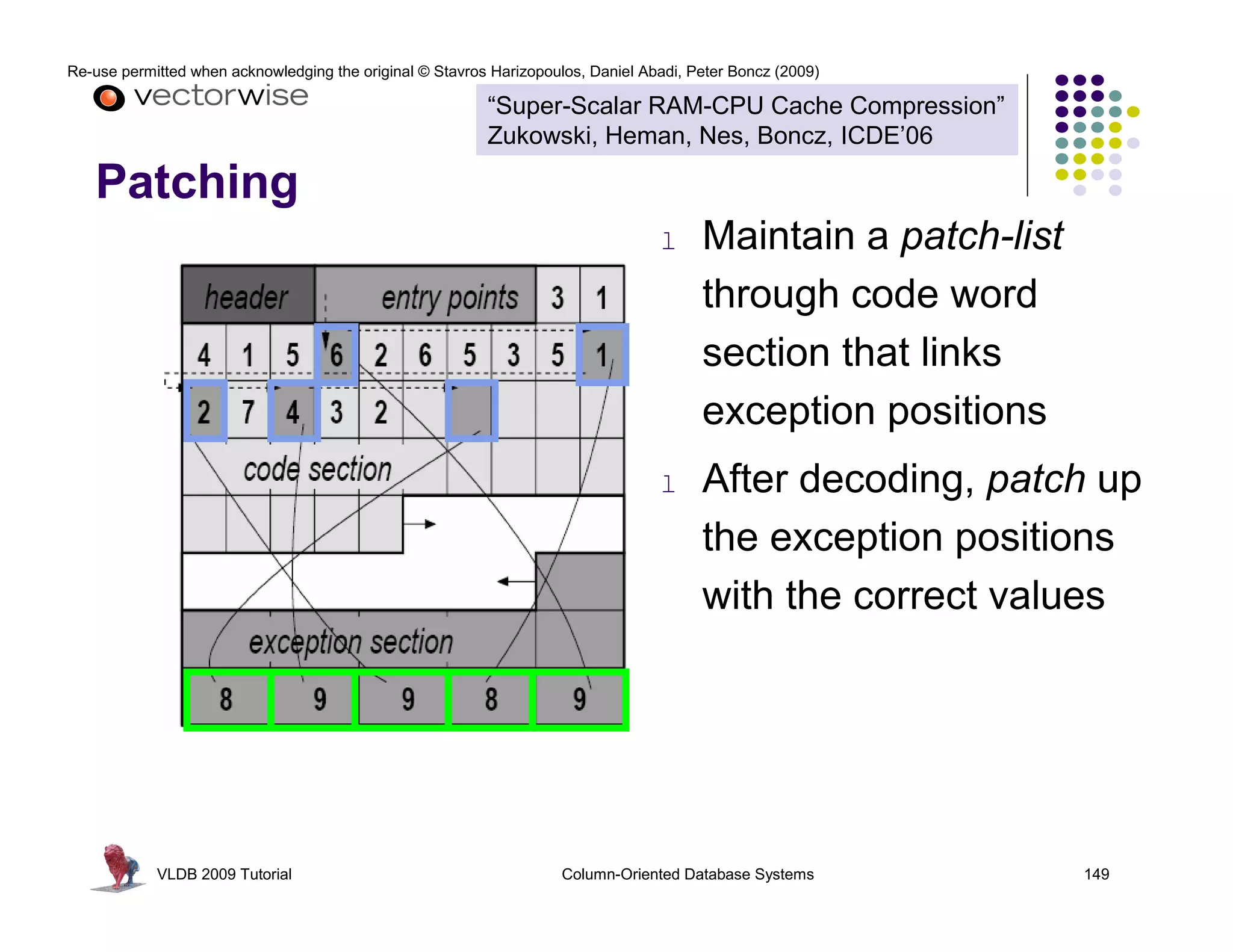


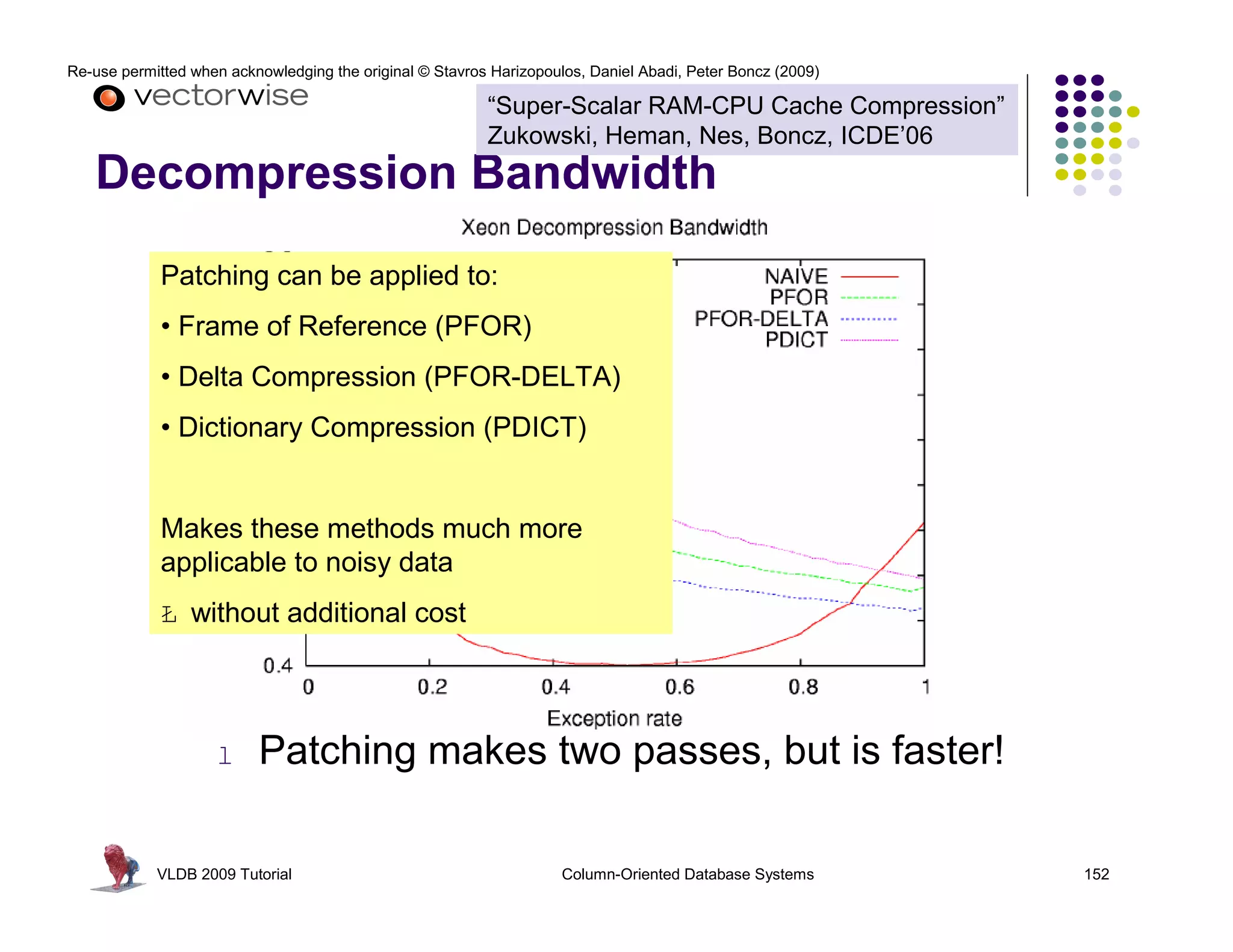










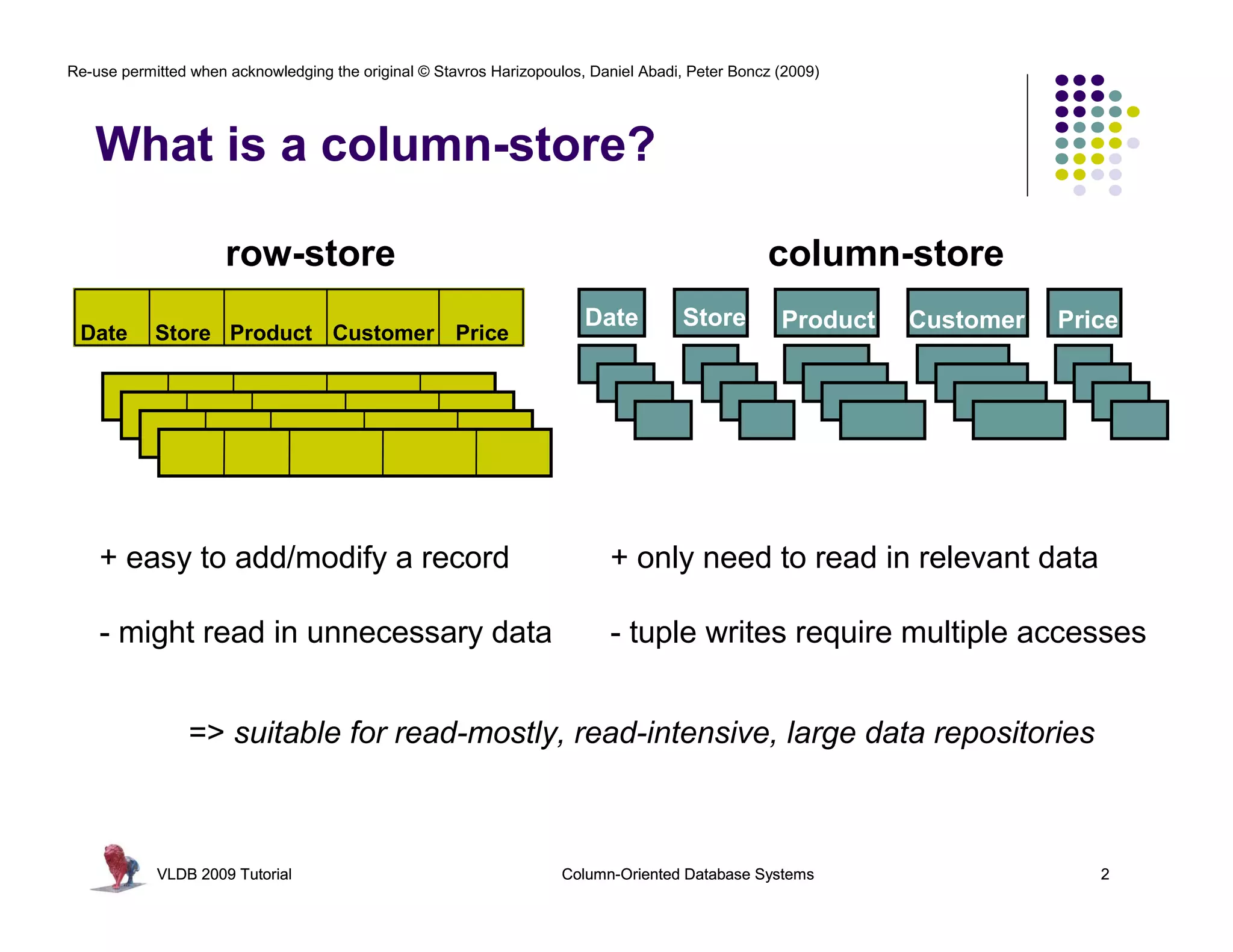
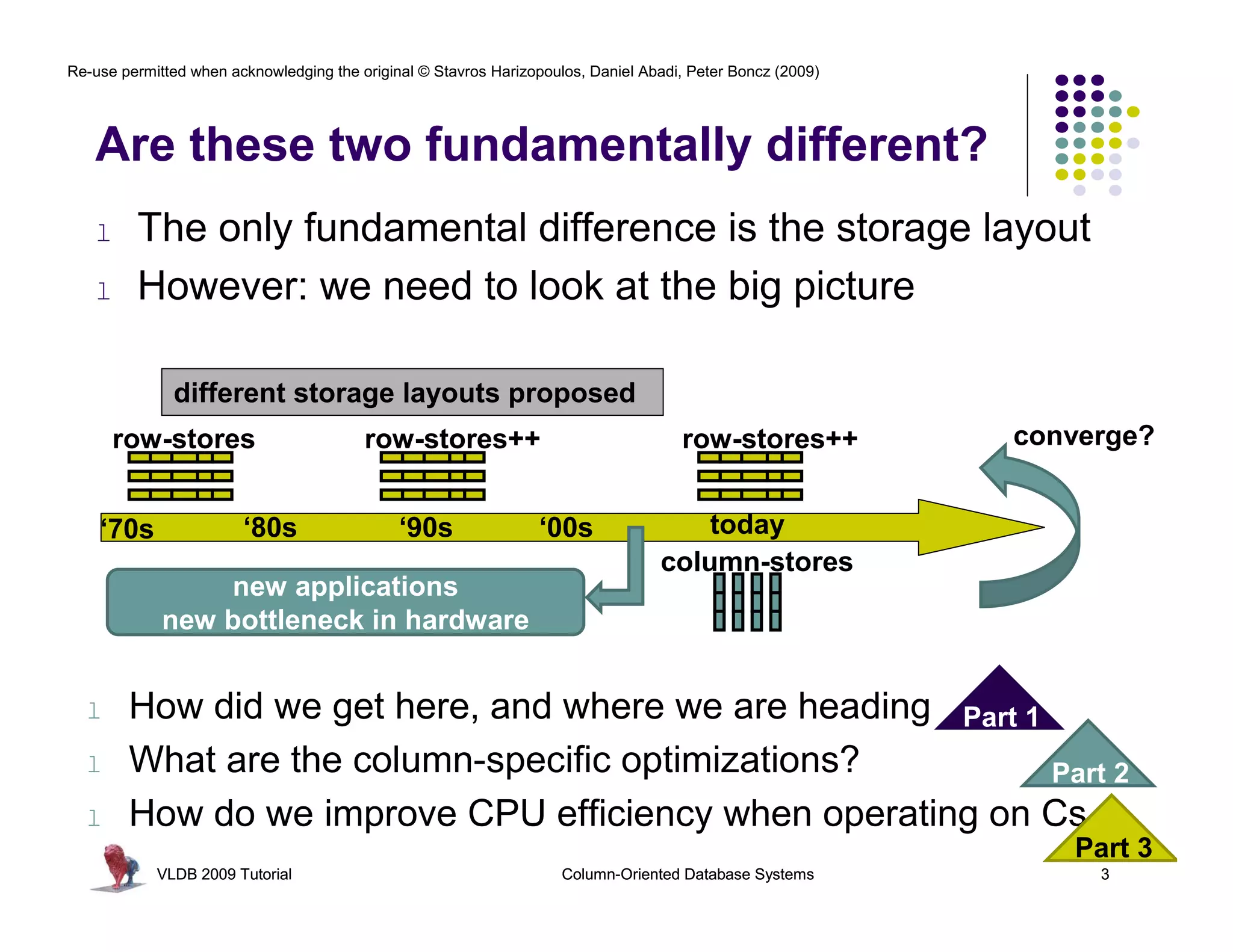
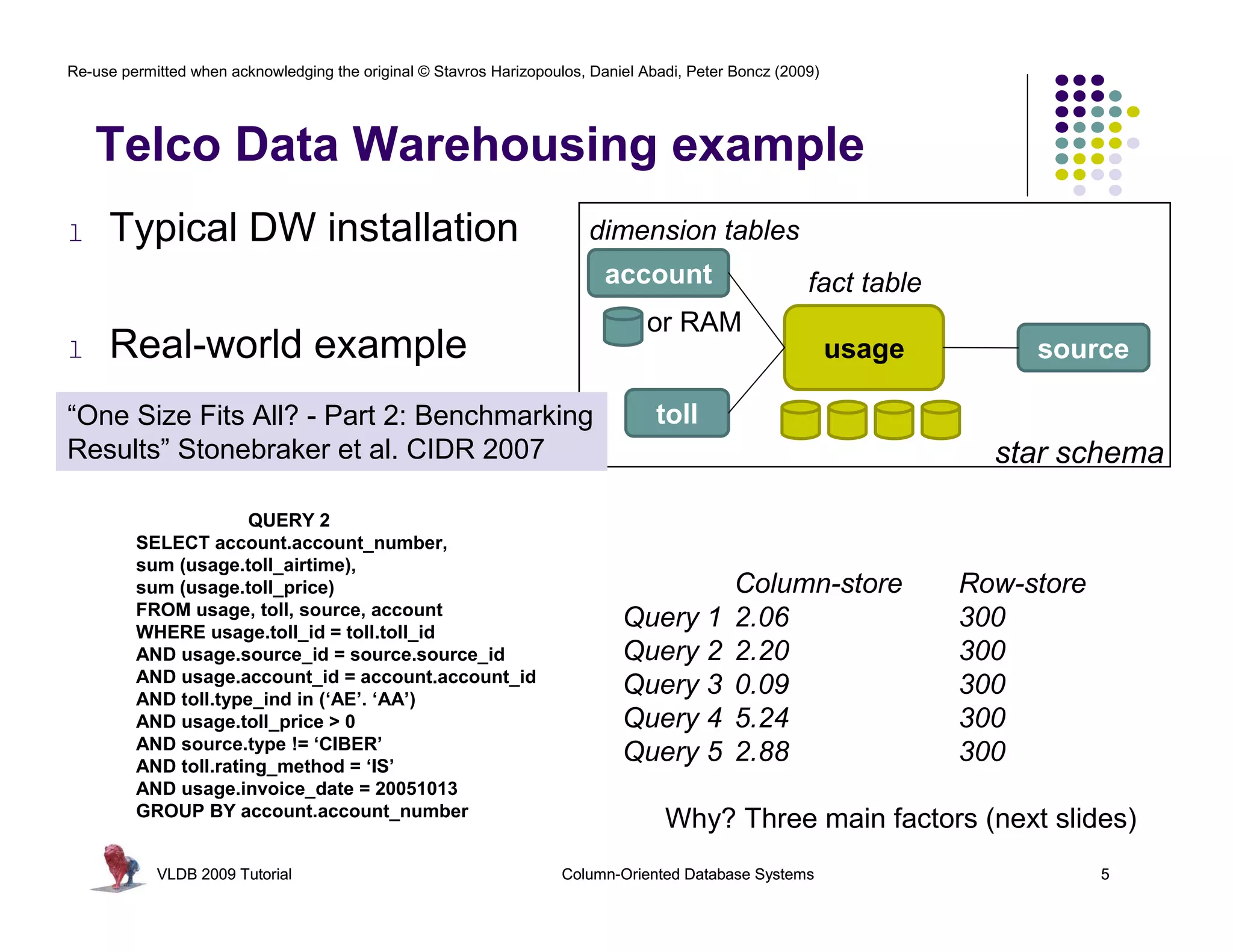
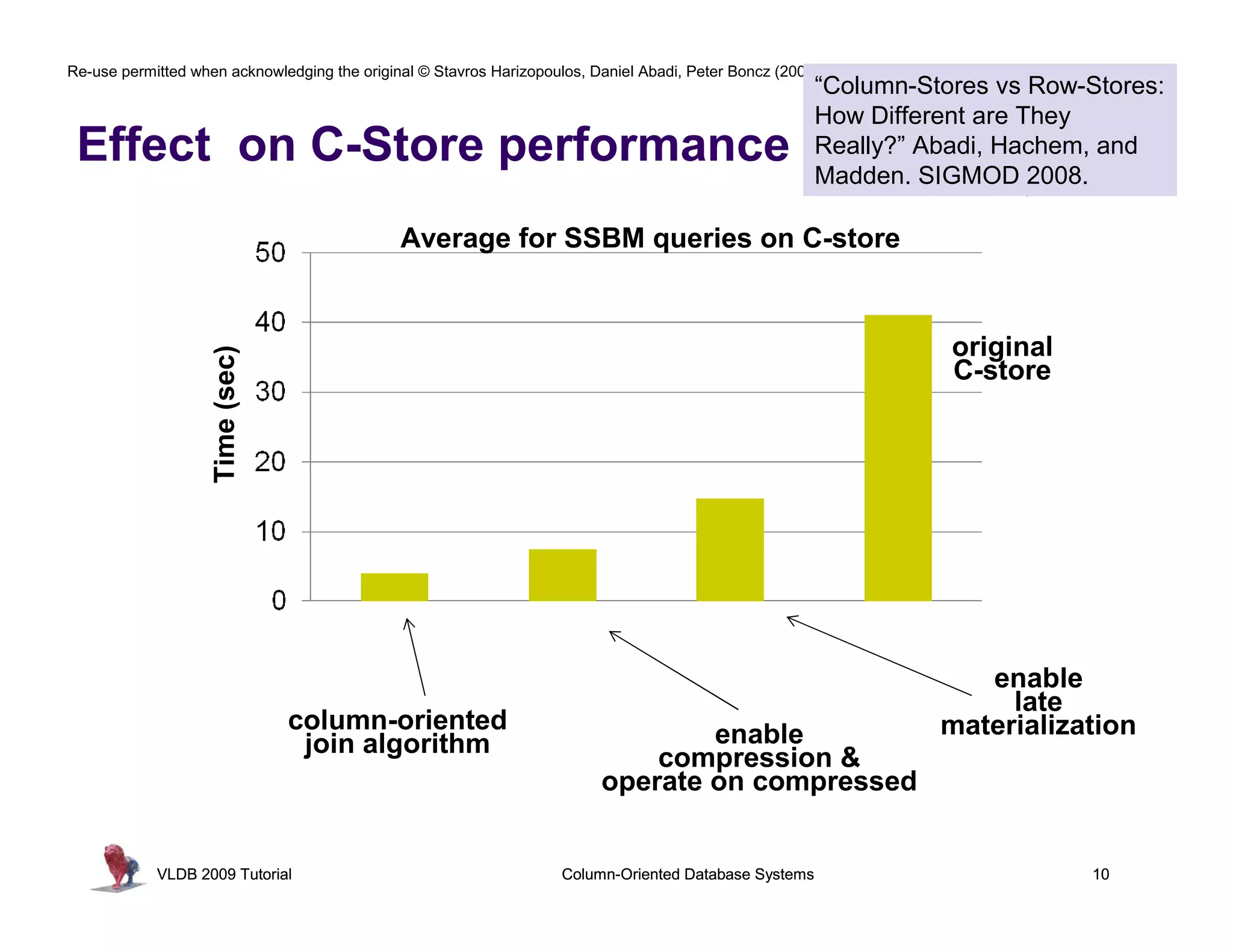
This document summarizes a tutorial on column-oriented database systems given at VLDB 2009. It discusses the evolution of column-oriented databases from early systems like DSM to current commercial systems. Key features of column-oriented databases include storing data by column rather than by row for improved read efficiency, better compression, and indexing capabilities. The tutorial outlines optimizations made possible by the columnar format like late materialization and vectorized processing. It also compares the performance of column and row storage using a telco data warehousing example.































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















