Downloaded 20 times




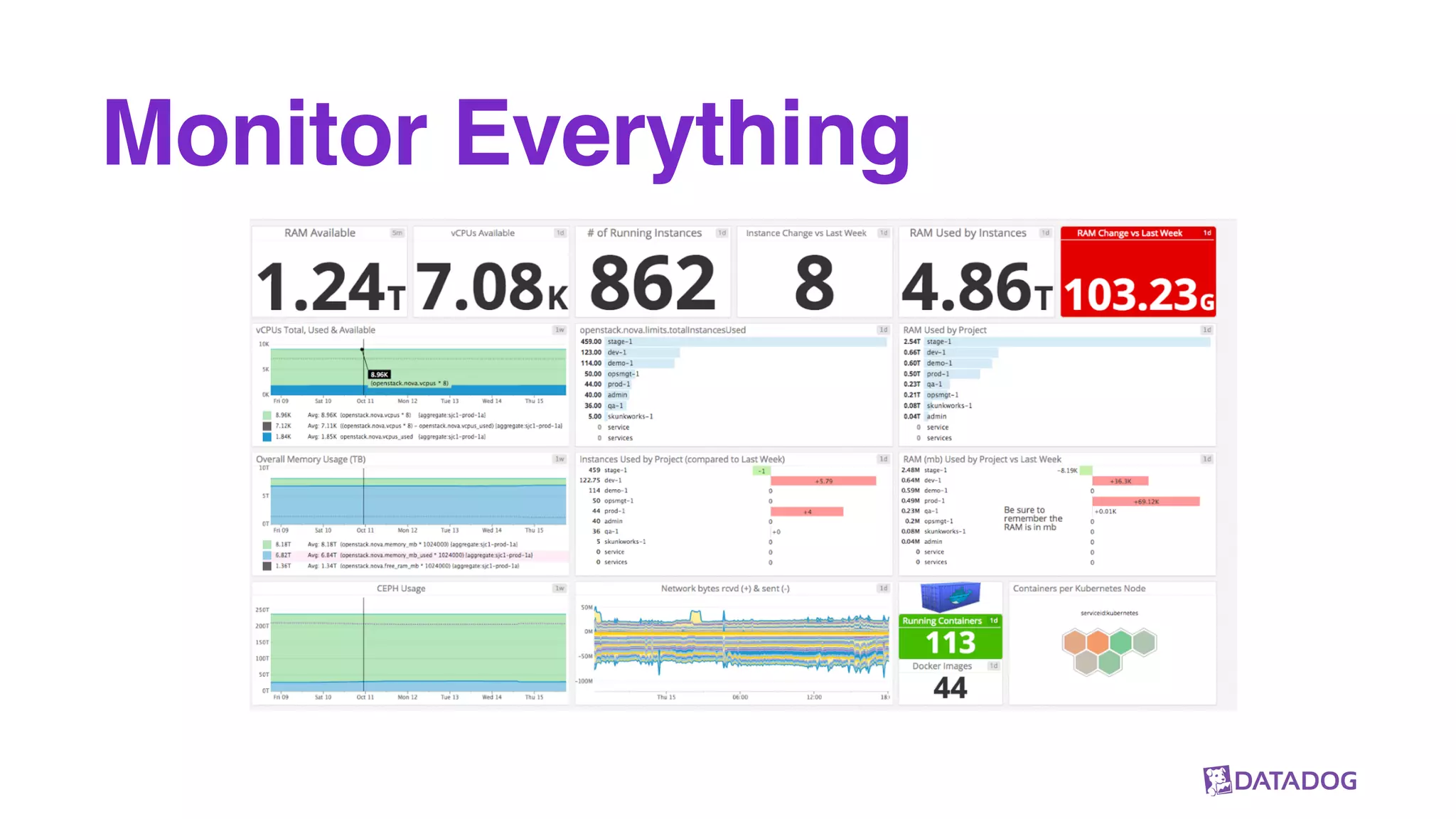
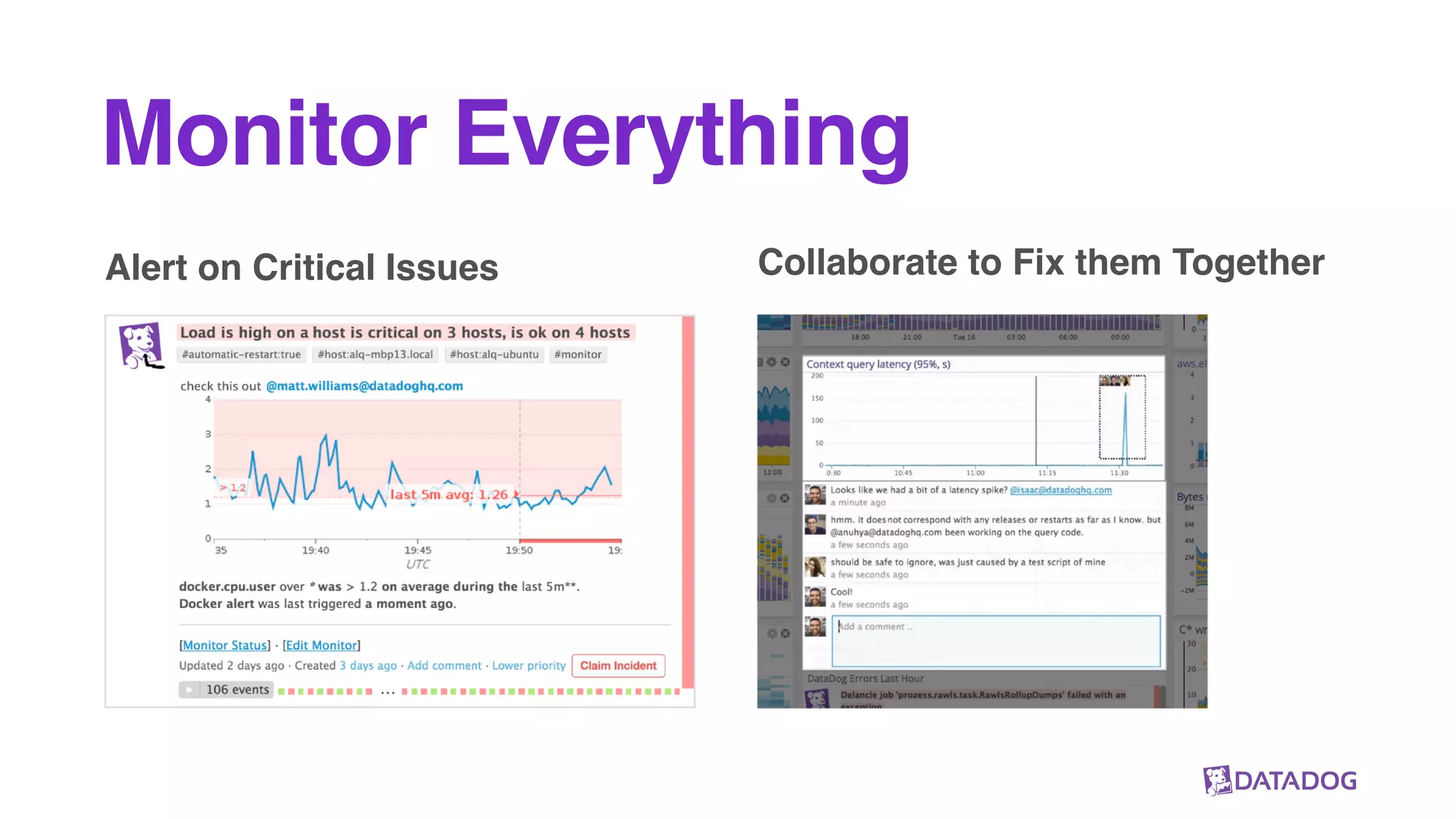

















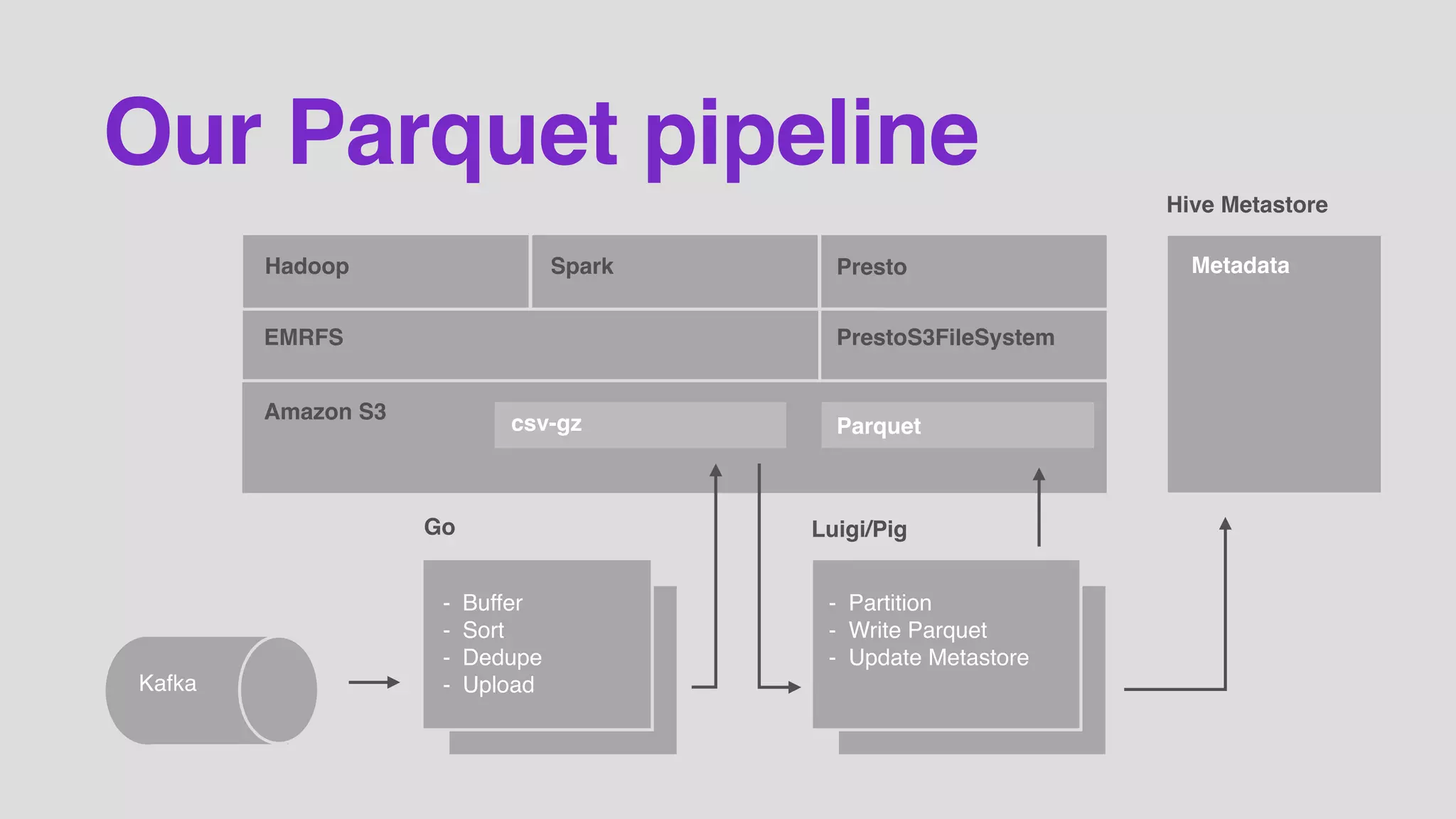



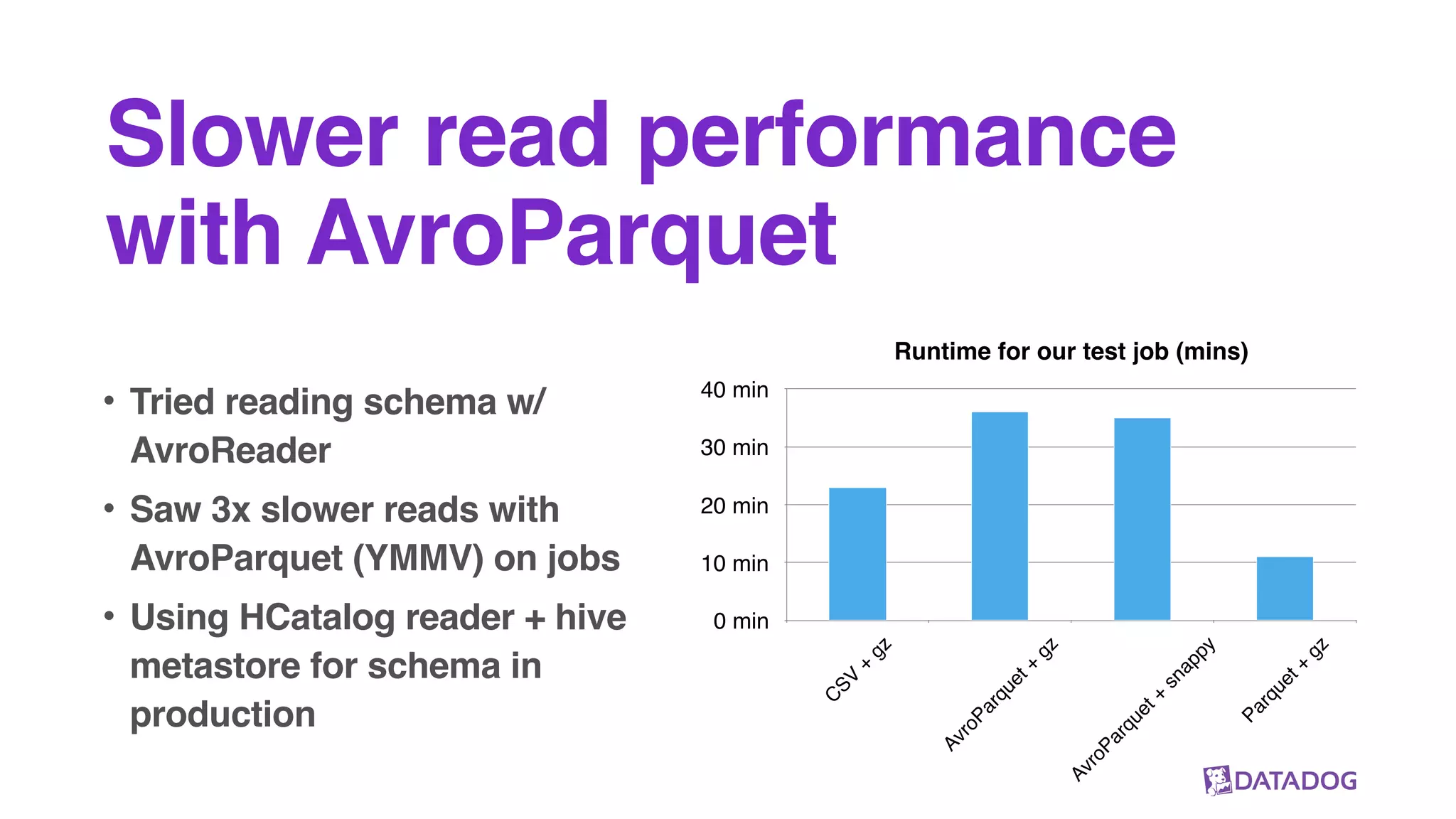



The document outlines Datadog's use of Parquet for efficiently collecting and processing vast amounts of metrics data from cloud applications. It highlights key aspects such as their data pipeline, the benefits of using Parquet, and some production insights related to storage efficiency and read performance. The discussion emphasizes the importance of separate compute and storage as well as a standard data format for optimal performance.


















































![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















