Download as PDF, PPTX




![A little teaser
PGroupedTable<K,V>::combineValues(CombineFn<K,V> combineFn,
CombineFn<K,V> reduceFn)
Crunch: CombineFns are used to represent the associative operations…
Grouped[K, +V]::reduce[U >: V](fn: (U, U) U)
Scalding: reduce with fn which must be associative and commutative…
PairRDDFunctions[K, V]::reduceByKey(fn: (V, V) => V)
Spark: Merge the values for each key using an associative reduce function…](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-6-320.jpg)








![To join or not to join?
val streams: TypedPipe[(String, String)] = _ // (track, user)
val tgp: TypedPipe[(String, String)] = _ // (track, genre)
streams
.join(tgp)
.values // (user, genre)
.group
.mapValueStream(vs => Iterator(vs.toSet)) // reducer-only](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-15-320.jpg)
![Hash join
val streams: TypedPipe[(String, String)] = _ // (track, user)
val tgp: TypedPipe[(String, String)] = _ // (track, genre)
streams
.hashJoin(tgp.forceToDisk) // tgp replicated to all mappers
.values // (user, genre)
.group
.mapValueStream(vs => Iterator(vs.toSet)) // reducer-only](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-16-320.jpg)
![CoGroup
val streams: TypedPipe[(String, String)] = _ // (track, user)
val tgp: TypedPipe[(String, String)] = _ // (track, genre)
streams
.cogroup(tgp) { case (_, users, genres) =>
users.map((_, genres.toSet))
} // (track, (user, genres))
.values // (user, genres)
.group
.reduce(_ ++ _) // map-side reduce!](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-17-320.jpg)
![CoGroup
val streams: TypedPipe[(String, String)] = _ // (track, user)
val tgp: TypedPipe[(String, String)] = _ // (track, genre)
streams
.cogroup(tgp) { case (_, users, genres) =>
users.map((_, genres.toSet))
} // (track, (user, genres))
.values // (user, genres)
.group
.sum // SetMonoid[Set[T]] from Algebird
* sum[U >:V](implicit sg: Semigroup[U])](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-18-320.jpg)
![Key-value file as distributed cache
val streams: TypedPipe[(String, String)] = _ // (gid, user)
val tgp: SparkeyManager = _ // tgp replicated to all mappers
streams
.map { case (track, user) =>
(user, tgp.get(track).split(",").toSet)
}
.group
.sum
https://github.com/spotify/sparkey
SparkeyManagerwraps DistributedCacheFile](https://image.slidesharecdn.com/bds-150818235714-lva1-app6891/85/Scala-Data-Pipelines-Spotify-19-320.jpg)





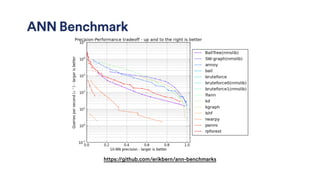


























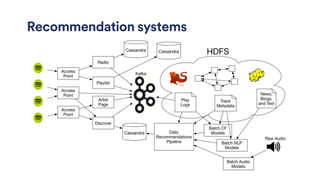
This document provides an overview of Scala data pipelines at Spotify. It discusses: - The speaker's background and Spotify's scale with over 75 million active users. - Spotify's music recommendation systems including Discover Weekly and personalized radio. - How Scala and frameworks like Scalding, Spark, and Crunch are used to build data pipelines for tasks like joins, aggregations, and machine learning algorithms. - Techniques for optimizing pipelines including distributed caching, bloom filters, and Parquet for efficient storage and querying of large datasets. - The speaker's success in migrating over 300 jobs from Python to Scala and growing the team of engineers building Scala pipelines at Spotify.












































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)




