Downloaded 114 times


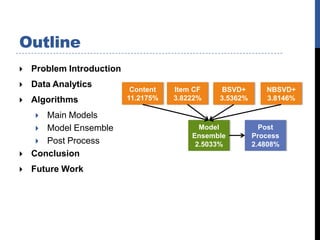











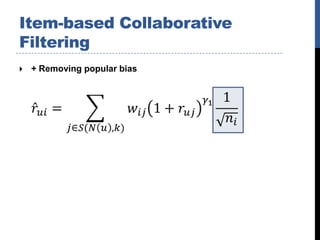
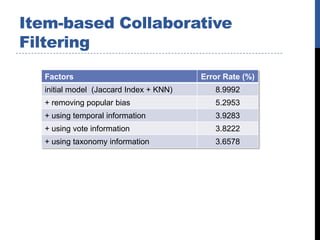



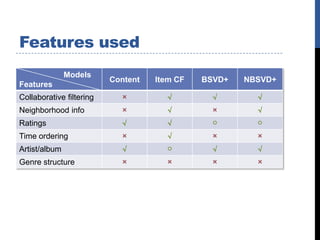


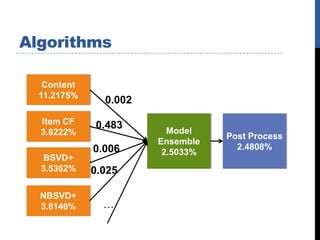




The document describes the team's solution for the KDD Cup 2011 Track 2 competition. It presents several algorithms used, including content-based modeling, item-based collaborative filtering, binary latent factor modeling, and neighborhood-based binary SVD modeling. It discusses how ensemble modeling and post-processing were used to further improve results. The best individual models achieved error rates around 3.5-3.8%, while ensemble modeling combined with post-processing reduced the final error rate to around 2.5%.

































































