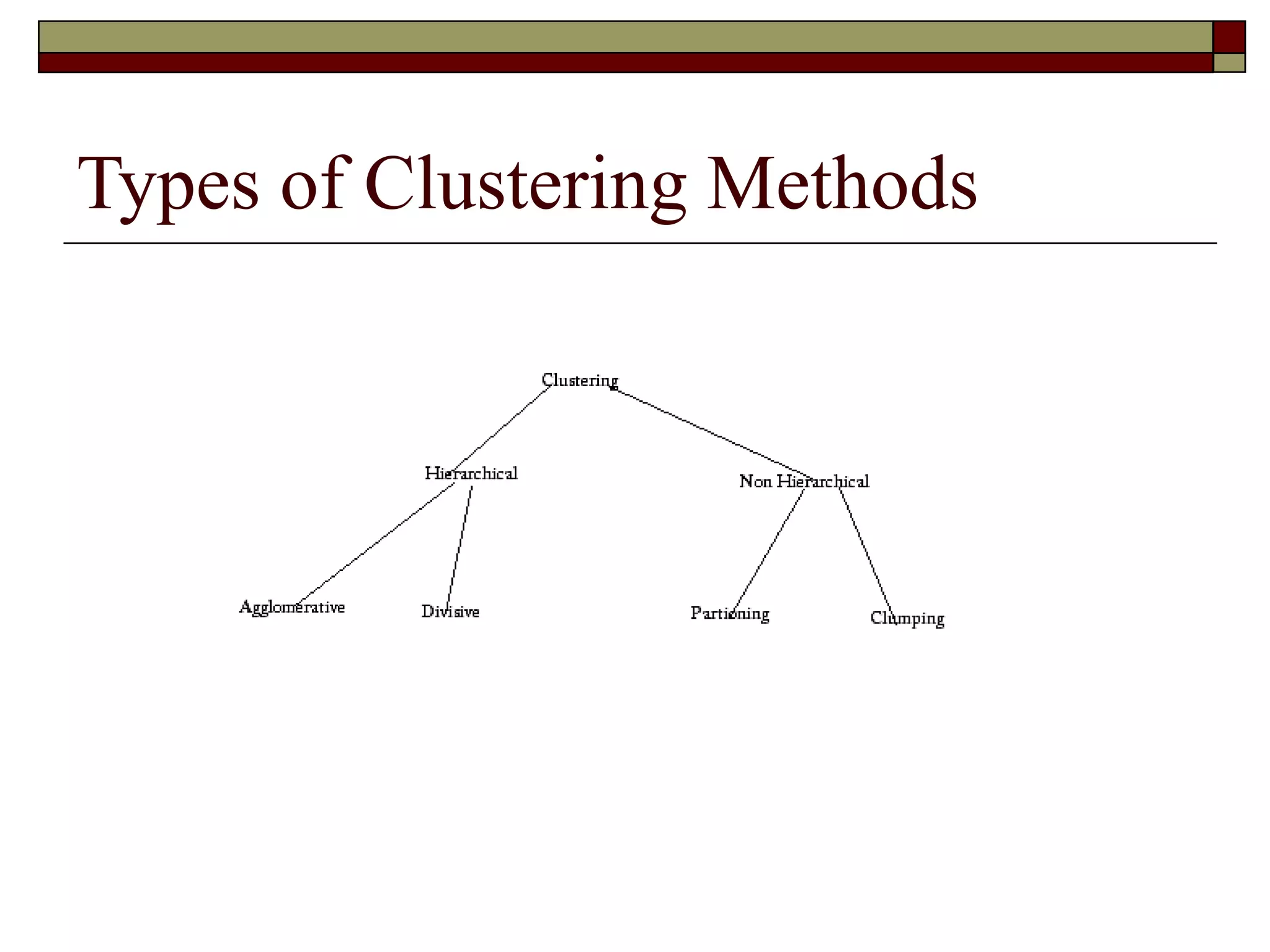
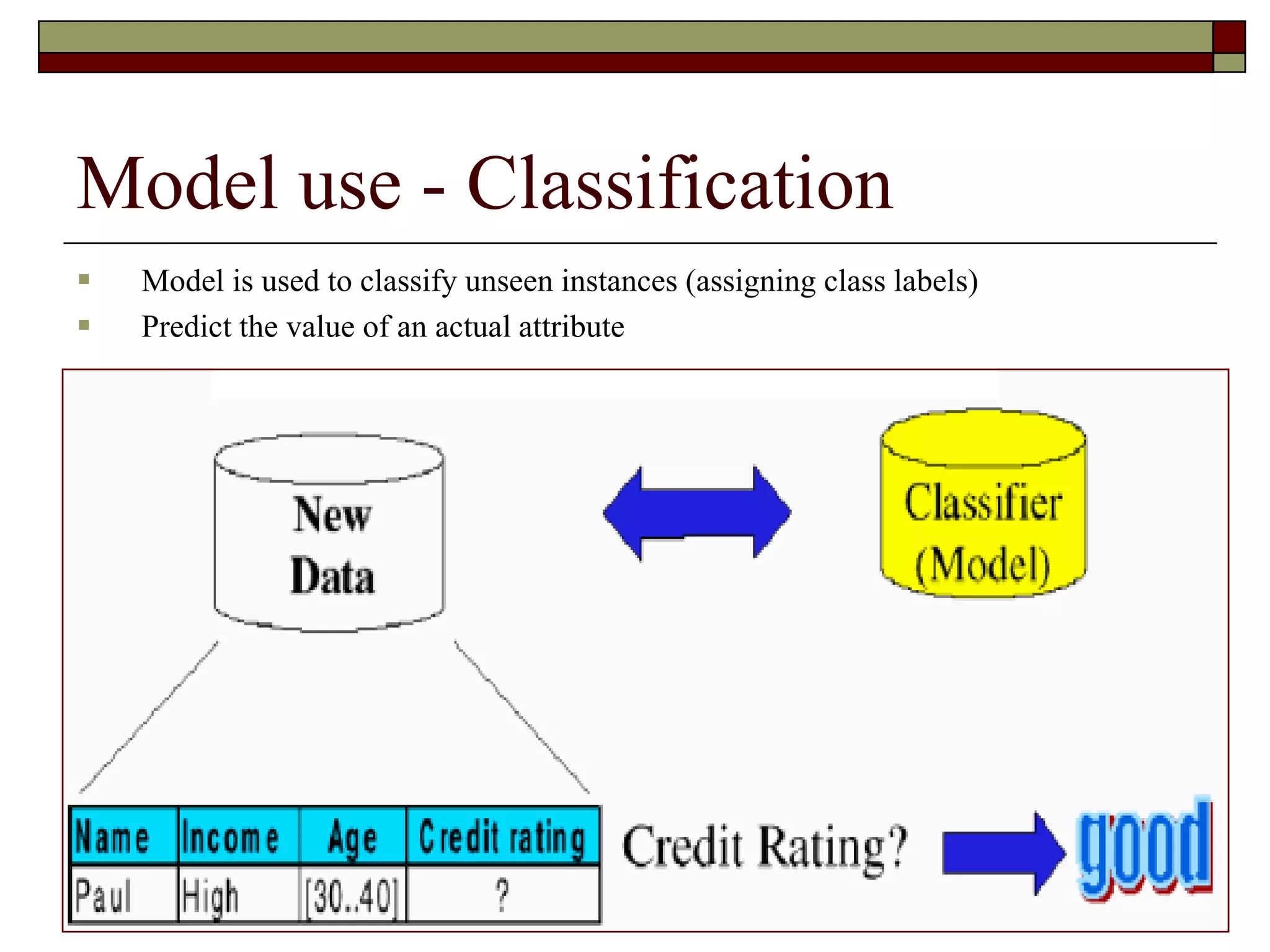
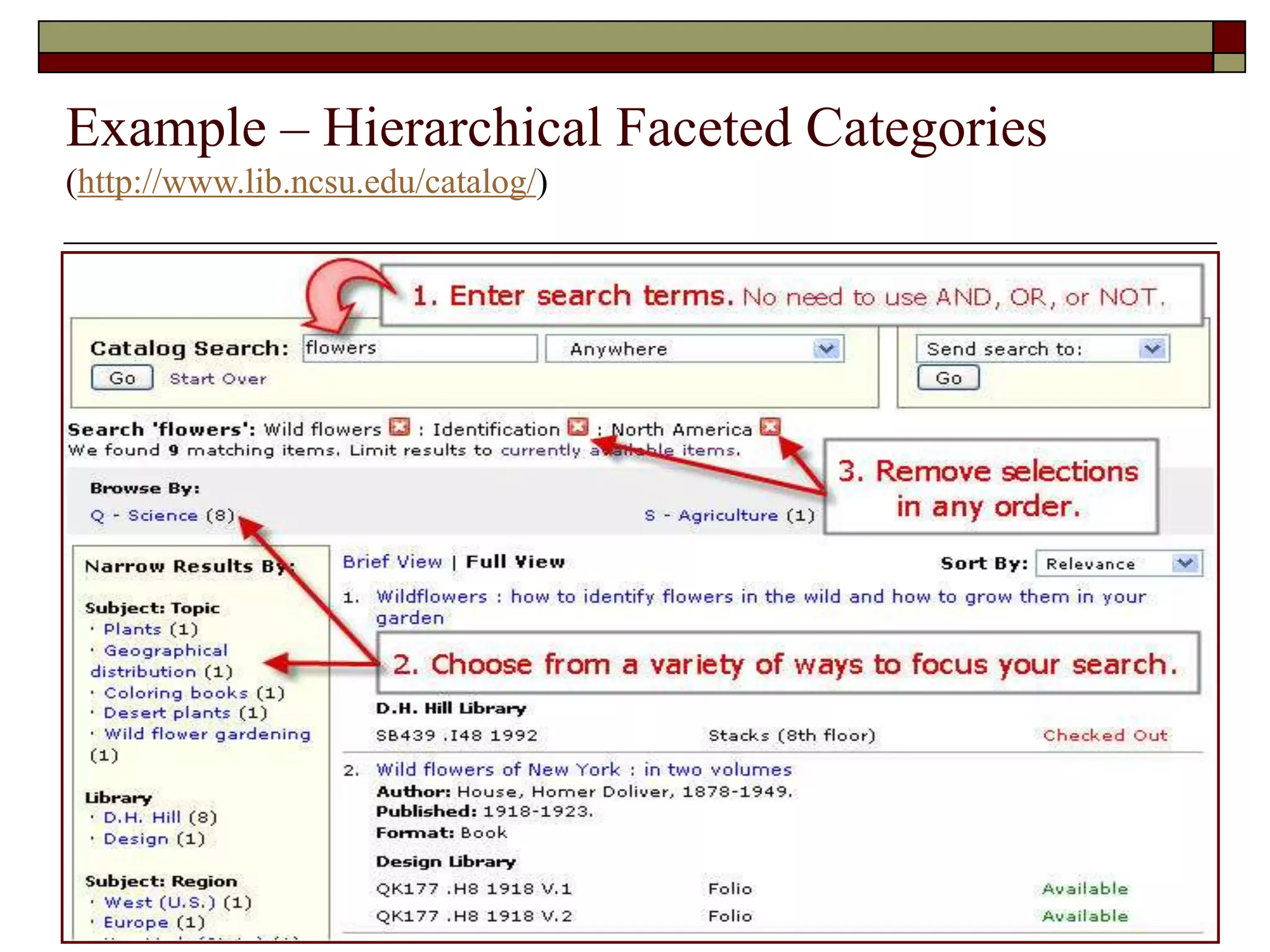
This document provides an overview of automatic clustering and classification. It discusses types of clustering like K-means clustering and applications of clustering like document retrieval. It also discusses categorization, including supervised classification algorithms. An example of clustering search from Quintura is described, showing how it allows dynamic refinement of document clusters. Challenges of clustering and classification are also summarized.