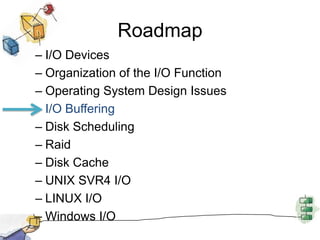
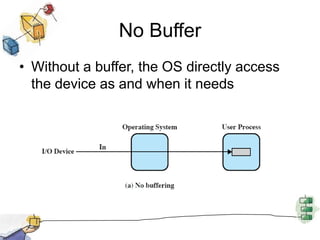
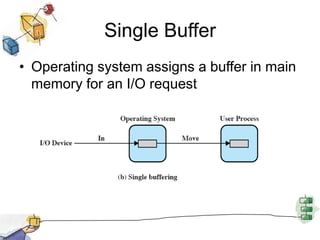
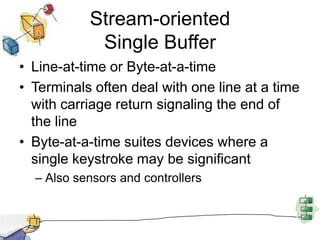
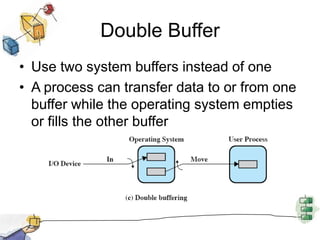
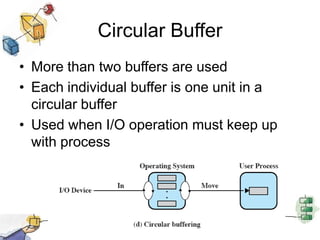
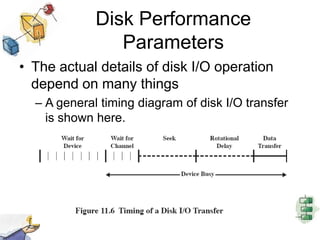
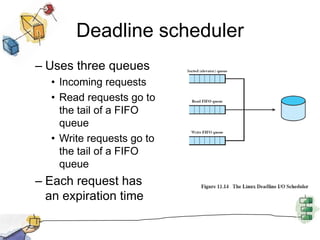
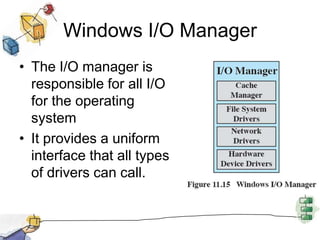
This document summarizes I/O management and disk scheduling techniques in operating systems. It covers I/O devices, how the I/O function is organized, operating system design issues regarding I/O, I/O buffering, and different disk scheduling policies like FIFO, SSTF, SCAN, C-SCAN, and others. The document provides an overview of these fundamental operating system I/O concepts in just over 3 sentences.






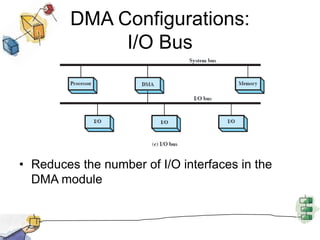



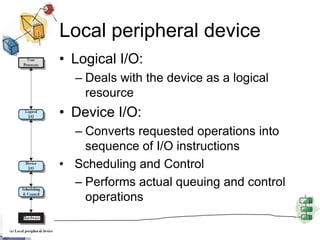

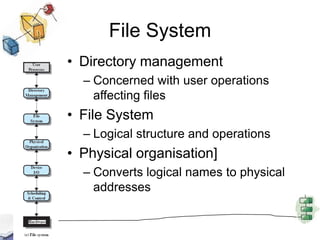

![File SystemDirectory managementConcerned with user operations affecting filesFile SystemLogical structure and operationsPhysical organisation]Converts logical names to physical addresses](https://image.slidesharecdn.com/chapter11-new-110621170038-phpapp02/85/Chapter11-new-32-320.jpg)





































![Weeks [01 02] 20100921](https://cdn.slidesharecdn.com/ss_thumbnails/weeks01-0220100921-131007221331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































































