Downloaded 16 times





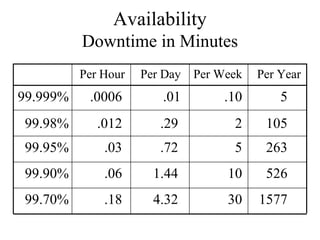
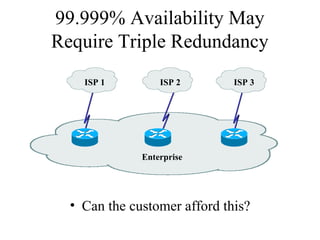



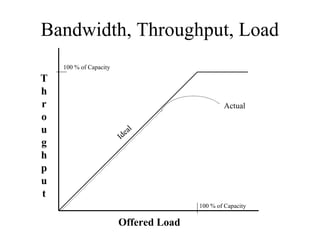






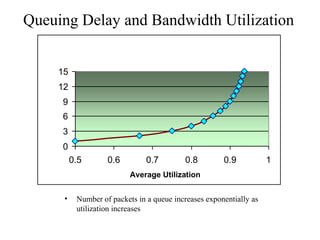









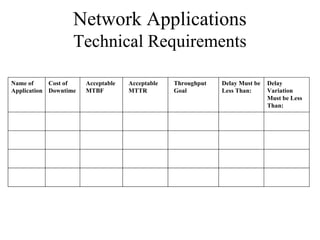




The document discusses analyzing technical goals and tradeoffs for network design. It covers goals like scalability, availability, performance, security, manageability, usability, adaptability and affordability. These goals often require tradeoffs, as improving one area may negatively impact another. The document provides details on factors like bandwidth, throughput, efficiency, delay and availability percentages to help evaluate design choices and priorities.


































































