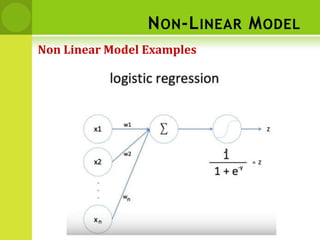
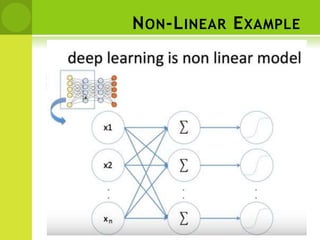
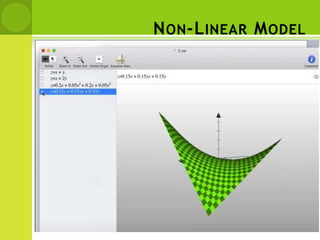
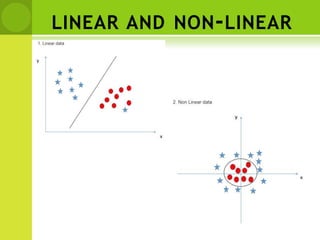
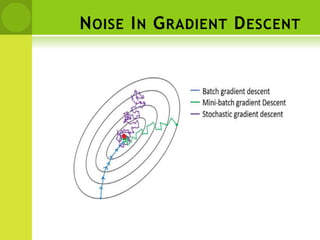
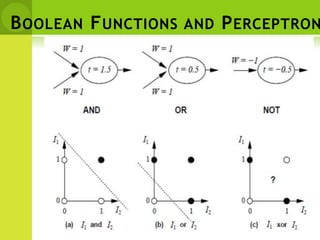
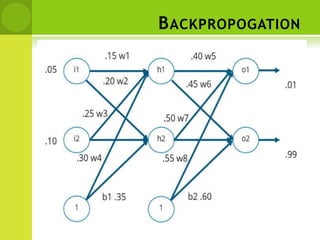
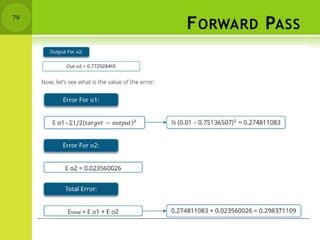
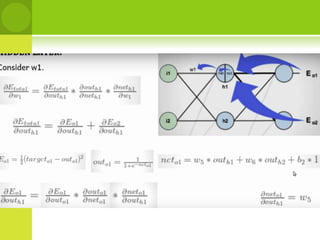
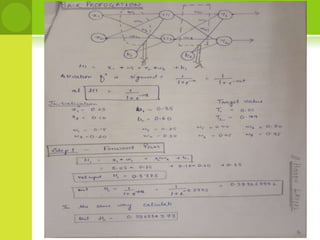
This document provides an overview of non-linear machine learning models. It introduces non-linear models and compares them to linear models. It discusses stochastic gradient descent and batch gradient descent optimization algorithms. It also covers neural networks, including model representations, activation functions, perceptrons, multi-layer perceptrons, and backpropagation. Additionally, it discusses regularization techniques to reduce overfitting, support vector machines, and K-nearest neighbors algorithms.


















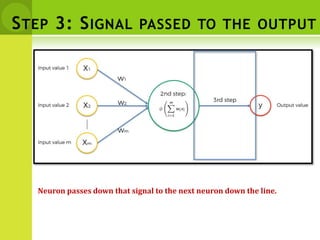
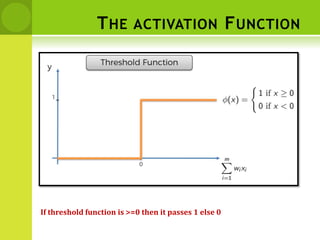
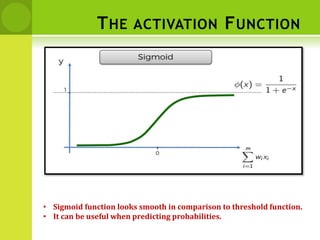
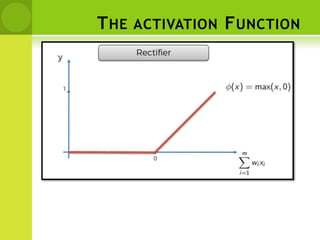





































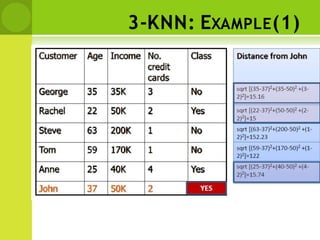
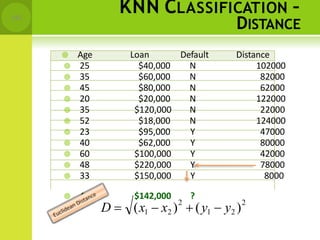
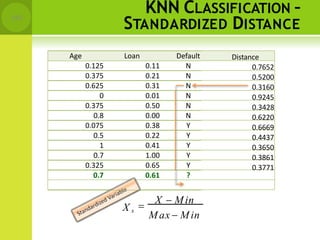
![DISTANCE BETWEEN NEIGHBORS
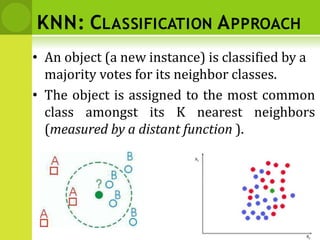
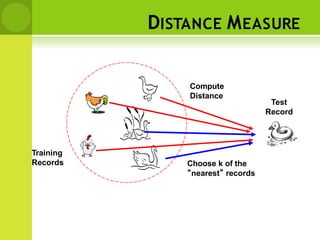
• Calculate the distance between new example
(E) and all examples in the training set.
• Euclidean distance between two examples.
– X = [x1,x2,x3,..,xn]
– Y = [y1,y2,y3,...,yn]
– The Euclidean distance between X and Y is defined as
n
D(X ,Y) (xi yi )
i1
2](https://image.slidesharecdn.com/mlmodule3nonlinearlearning-230824161646-cb32ebab/85/ML-Module-3-Non-Linear-Learning-pptx-132-320.jpg)