Downloaded 31 times





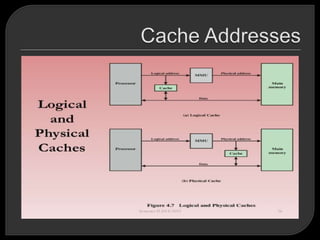
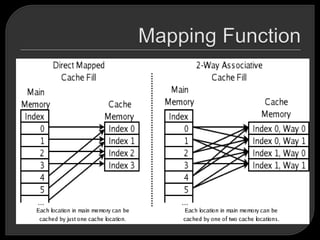




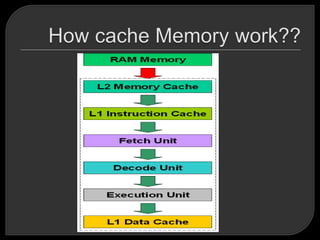


Caches are commonly used in high-performance computing to improve performance. However, high-performance computing applications often perform poorly on computer architectures that employ caches, unless the application software is specifically tuned to exploit the caches. There are several basic design elements that differentiate cache architectures, including the cache size, mapping function, replacement algorithm, write policy, line size, and number of cache levels. The replacement algorithm determines which block of data to remove from the cache when a new block needs to be added.













































![[B5]memcached scalability-bag lru-deview-100](https://cdn.slidesharecdn.com/ss_thumbnails/b5memcached-scalability-baglru-deview-100-120919013502-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









































