








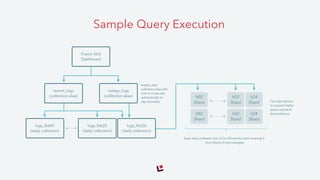

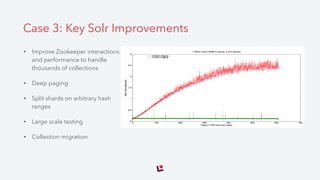



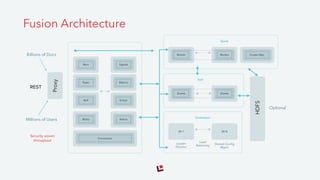




The document discusses Solr and its capabilities for large-scale search. It provides examples of how Solr has been used for compliance monitoring, web analytics, and search over consumer data and content. It also outlines the key features of Solr, such as indexing in HDFS, deployment options, and upcoming improvements to areas like security, performance, and integration with Apache Spark. Lucidworks provides commercial support for Solr and has experience implementing large-scale Solr deployments.


























































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



























