Downloaded 24 times
















![Transaction log
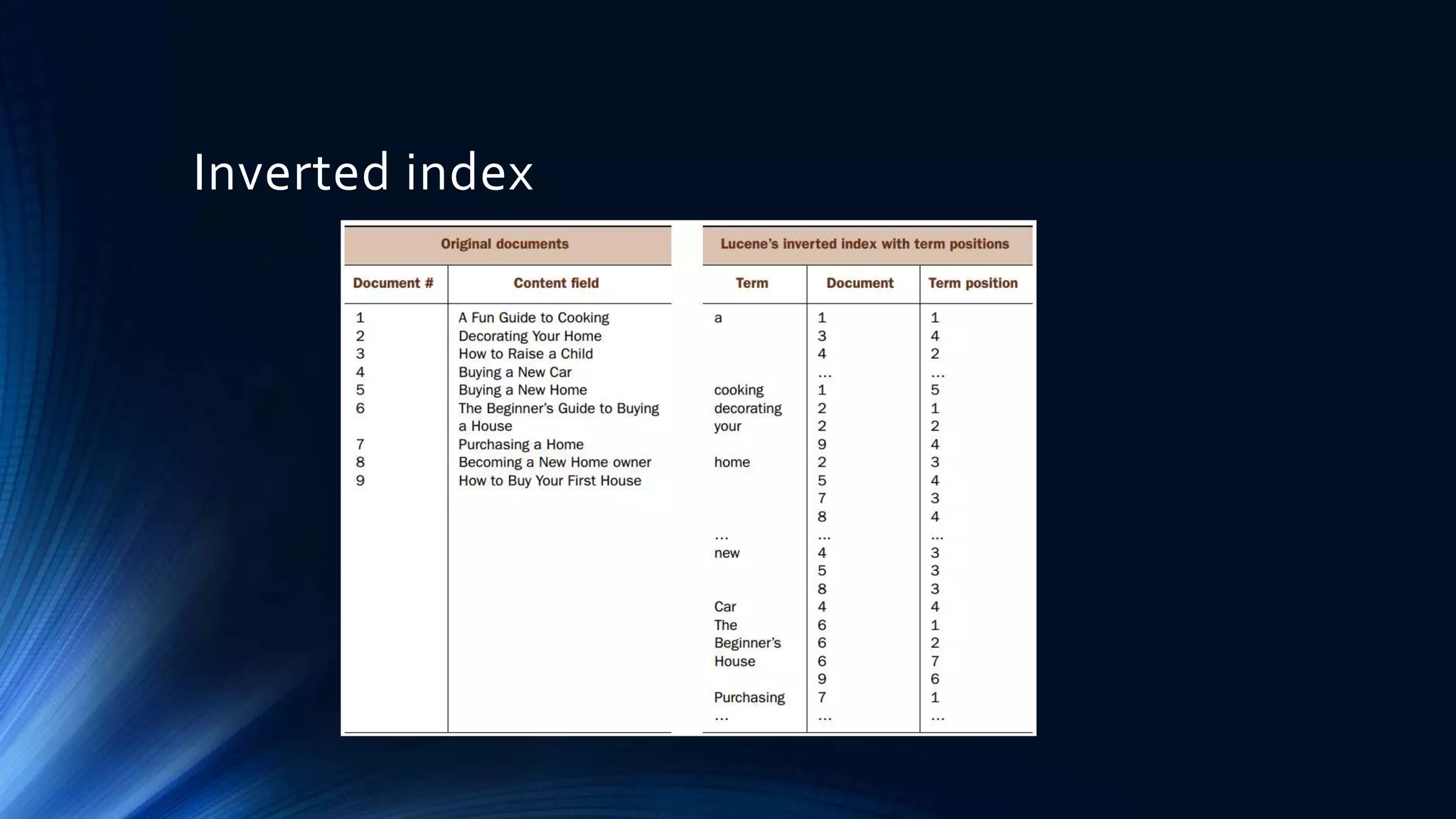
Intention:
1. recovery/durability
2. Nearly-Real-Time (NRT) update
3. Replication for Solr cloud
4. Atomic document update, in-place update (syntax is different)
5. Optimistic concurrency
Transaction log could be enabled in solrconfig.xml
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
Atomic update example:
{"id":"mydoc",
"price":{"set":99},
"popularity":{"inc":20},
"categories":{"add":["toys","games"]},
"promo_ids":{"remove":"a123x"},
"tags":{"remove":["free_to_try"," on_sale"]}
}](https://image.slidesharecdn.com/presentation2-170416153728/75/Apache-Solr-for-begginers-23-2048.jpg)

![Data modification Rest API
curl http://192.168.77.65:8983/solr/single-core/update?commit=true -H 'Content-type:application/json' -d '
[
{"id" : "3",
"internal_name":"post 2",
},
{"id" : “1",
"internal_name":"post 1",
}
]‘
Data.xml
<add>
<doc>
<field name='id'>8</field>
<field name='internal_name'>test1</field>
<doc>
<doc>
<field name='id'>9</field>
<field name='internal_name'>test6</field>
<doc>
</add>
curl -X POST 'http://192.168.77.65:8983/solr/single-core/update?commit=true&wt=json' -H 'Content-Type:text/xml' -d @data.xml
Delete.xml
<delete>
<id>11604</id>
<id>:11603</id>
</delete>
Delete_with_query.xml
<delete>
<query>id:[1 TO 85]</query>
</delete>](https://image.slidesharecdn.com/presentation2-170416153728/75/Apache-Solr-for-begginers-25-2048.jpg)





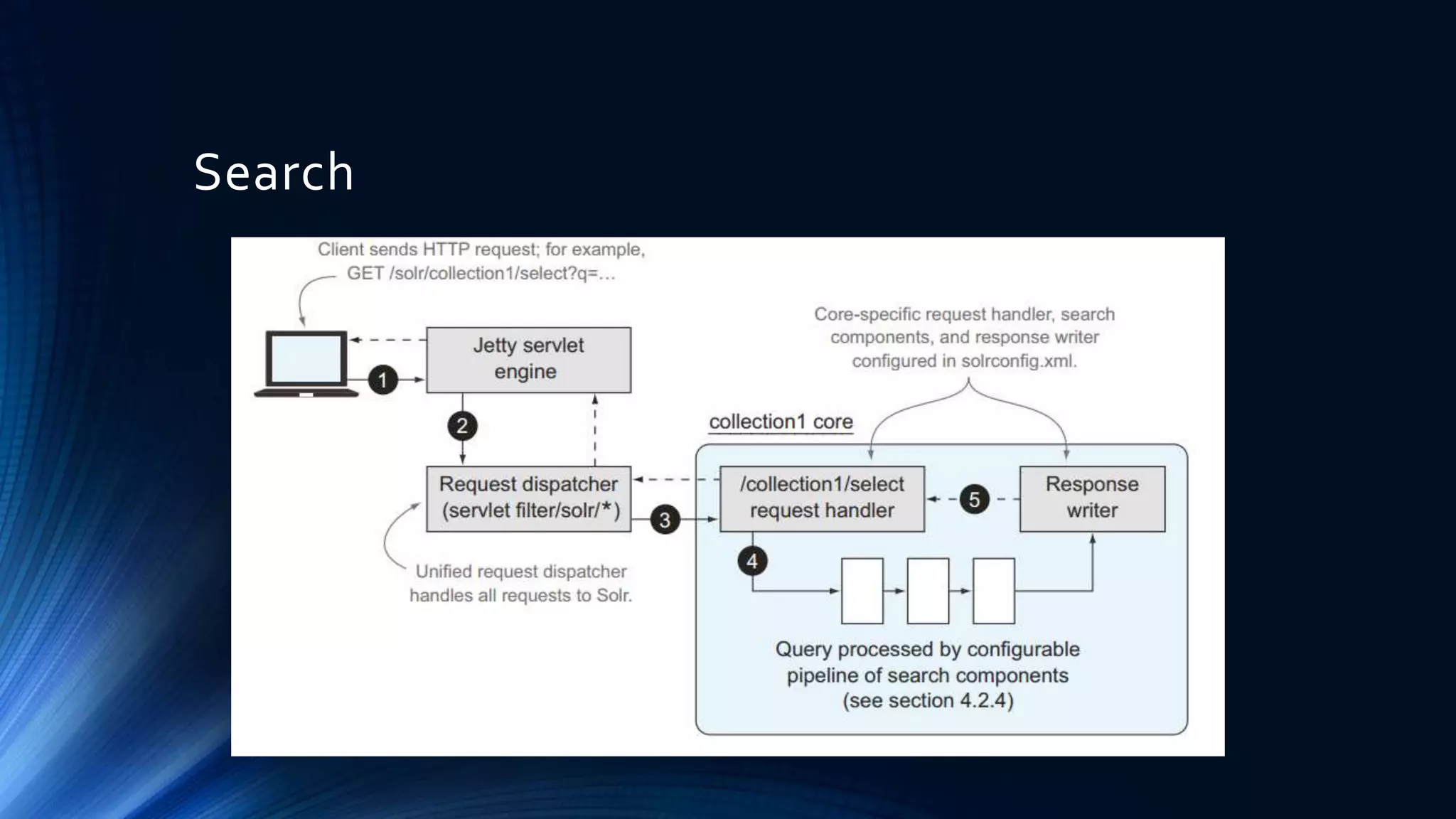
![Search typesFuzzy
Developer~ Developer~1 Developer~4
It matches developer, developers, development and etc.
Proximity
“solr search developer”~ “solr search developer”~1
It matches: solr search developer, solr senior developer
Wildcard
Deal* Com*n C??t
Need *xed? Add ReversedWildcardFilterFactory.
Range
[1 TO25] {23 TO50} {23 TO90]](https://image.slidesharecdn.com/presentation2-170416153728/75/Apache-Solr-for-begginers-33-2048.jpg)

![Search result customization
Field list
/query?=&fl=id, genre /query?=&fl=*,score
Sort
/query?=&fl=id, name&sort=date, score desc
Paging
select?q=*:*&sort=id&fl=id&rows=5&start=5
Transformers
[docid] [shard]
Debuging
/query?=&fl=id&debug=true
Format
/query?=&fl=id&wt=json /query?=&fl=id&wt=xml](https://image.slidesharecdn.com/presentation2-170416153728/75/Apache-Solr-for-begginers-35-2048.jpg)
![Search queries examples
Parameter style
curl "http://localhost:8983/cloud/ query?q=heroy&fq=inStock:true"
JSON API
$ curl http://localhost:8983/cloud/query -d '
{
query:"hero"
"filter" : "inStock:true"
}'
Response
{
"responseHeader":{
"status":0,
"QTime":2,
"params":{
"json":"n{n query:"hero" "filter" : "inStock:true" n}"}},
"response":{"numFound":1,"start":0,"docs":[
{
"id":"book3",
"author":"Brandon Sanderson",
"author_s":"Brandon Sanderson",
"title":["The Hero of Aages"],
"series_s":"Mistborn",
"sequence_i":3,
"genre_s":"fantasy",
"_version_":1486581355536973824
}]
}
}](https://image.slidesharecdn.com/presentation2-170416153728/75/Apache-Solr-for-begginers-36-2048.jpg)











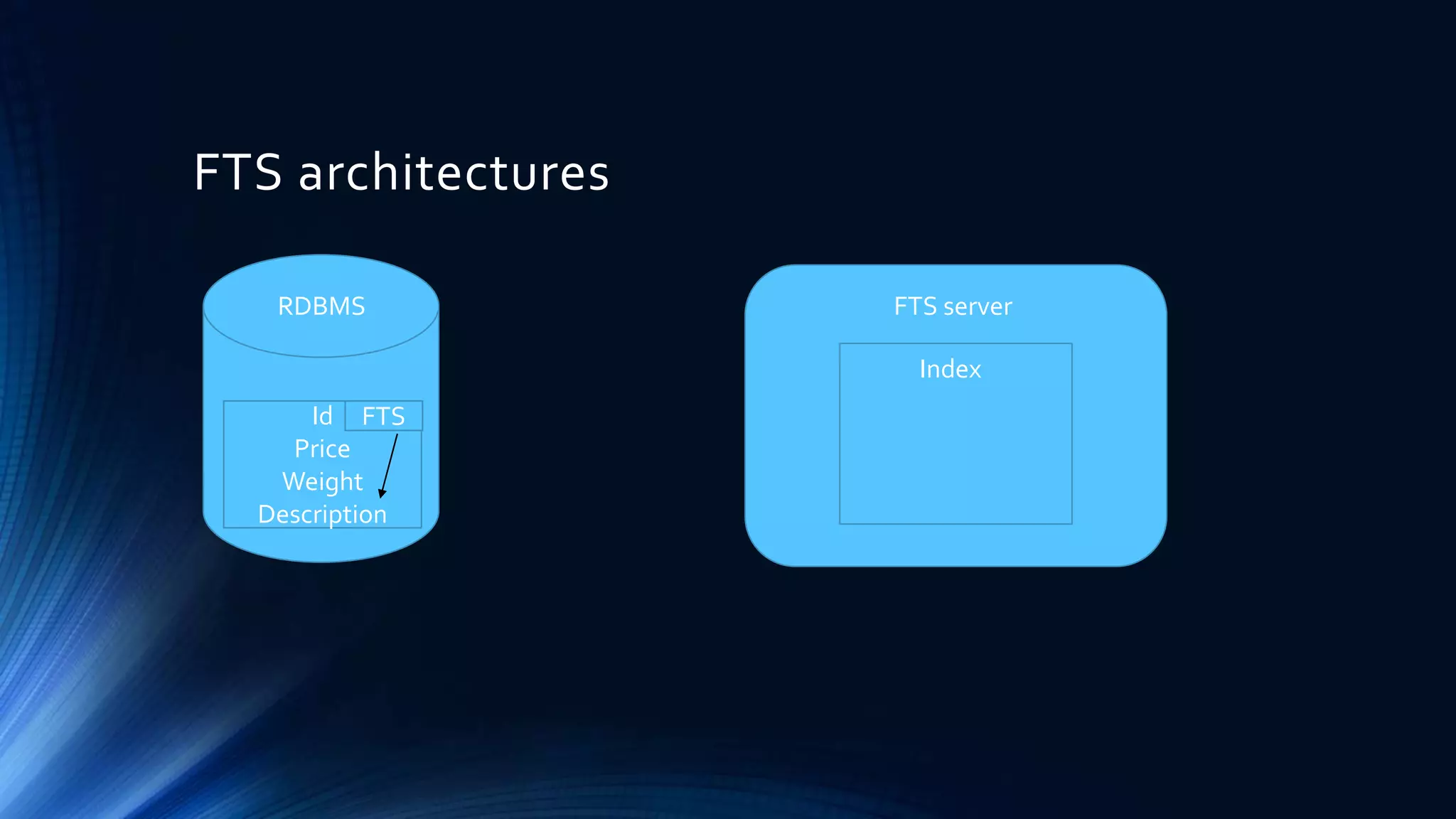
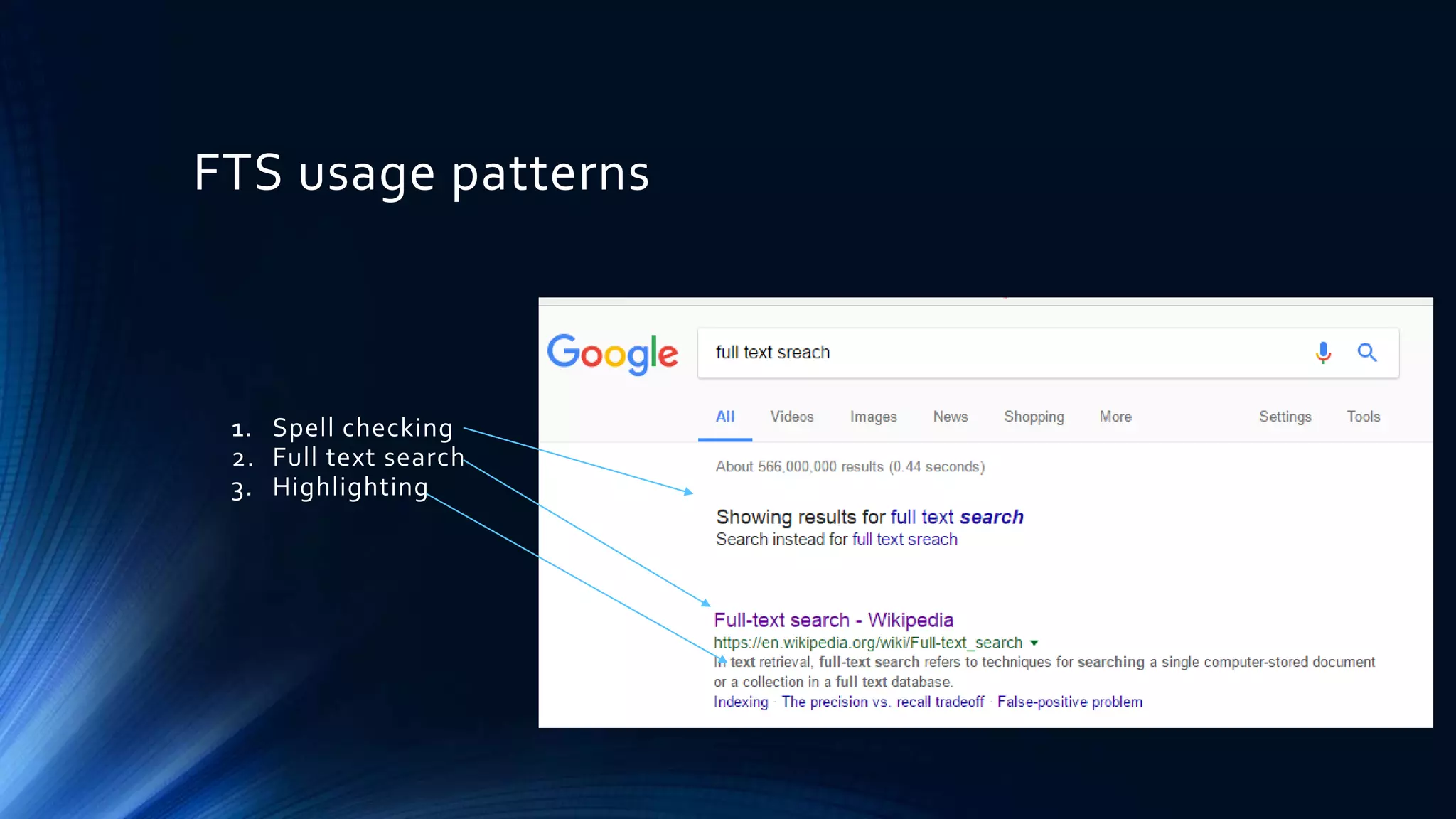
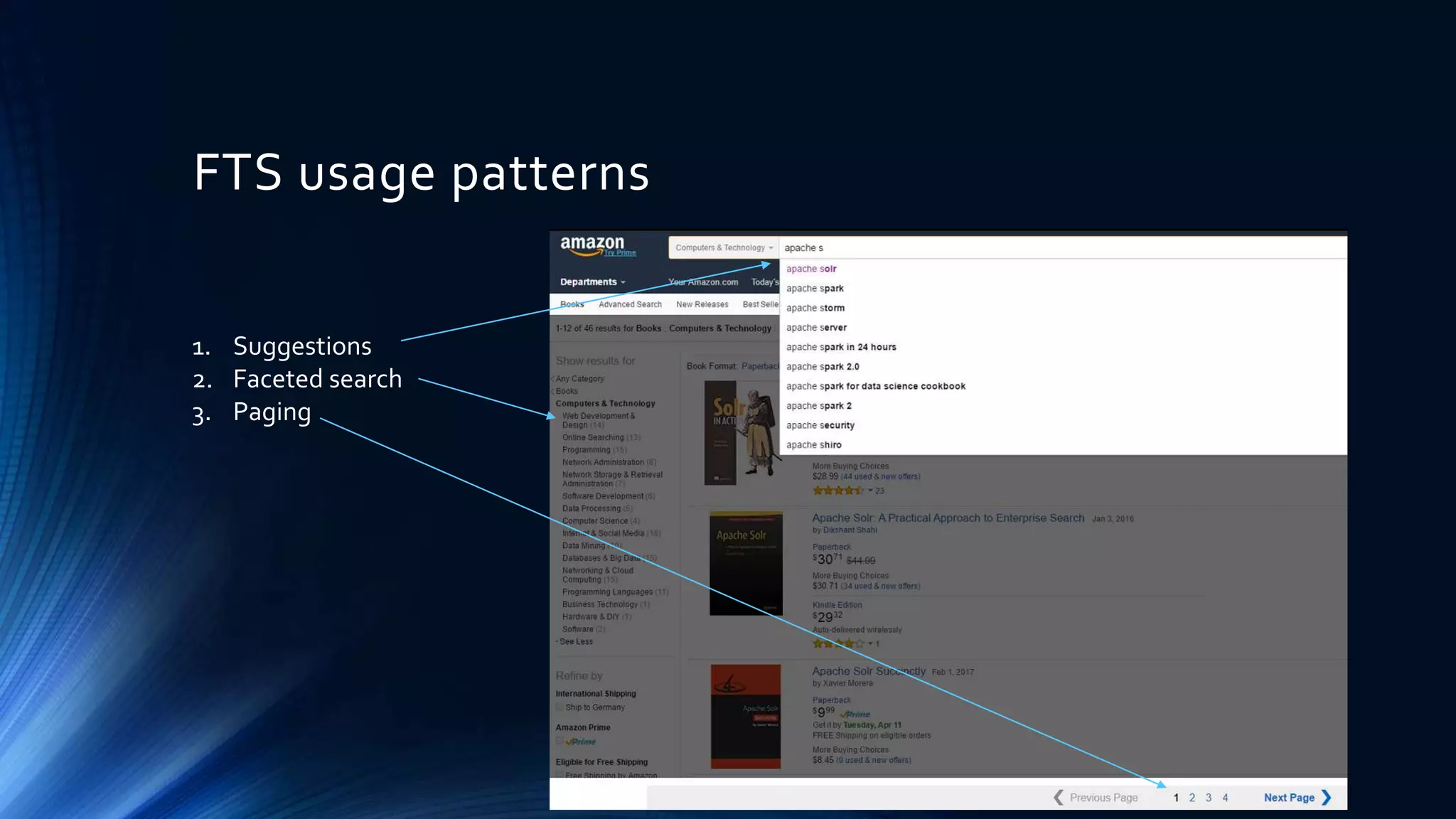
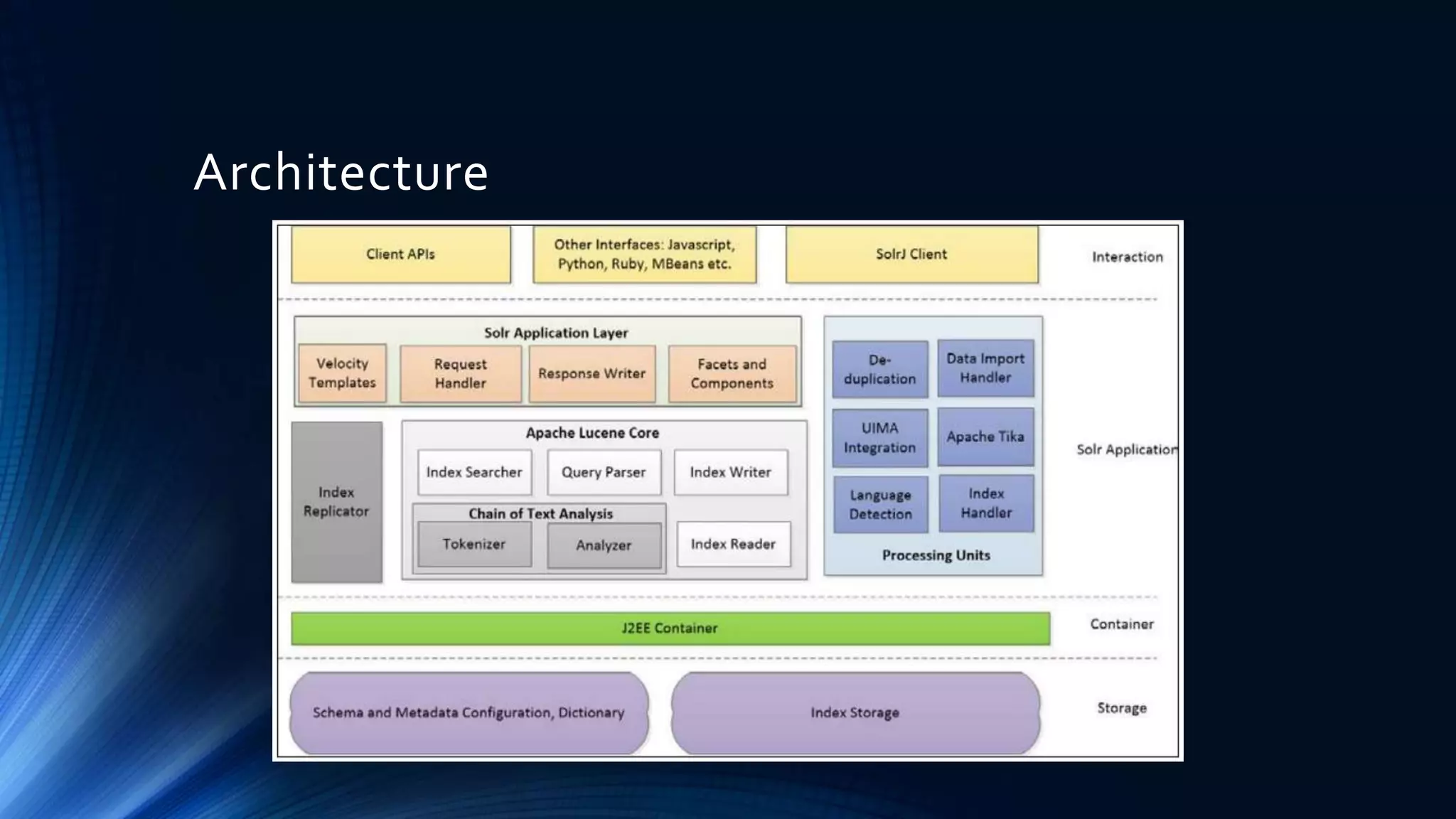
The document provides a comprehensive overview of full-text search solutions using Apache Solr, covering various aspects such as architecture, indexing strategies, and client libraries. It highlights features like spell checking, faceted search, and advanced querying capabilities along with performance tuning techniques. Additionally, it discusses data ingestion methods, text processing, and real-life applications of Solr to enhance search functionalities.



















































































