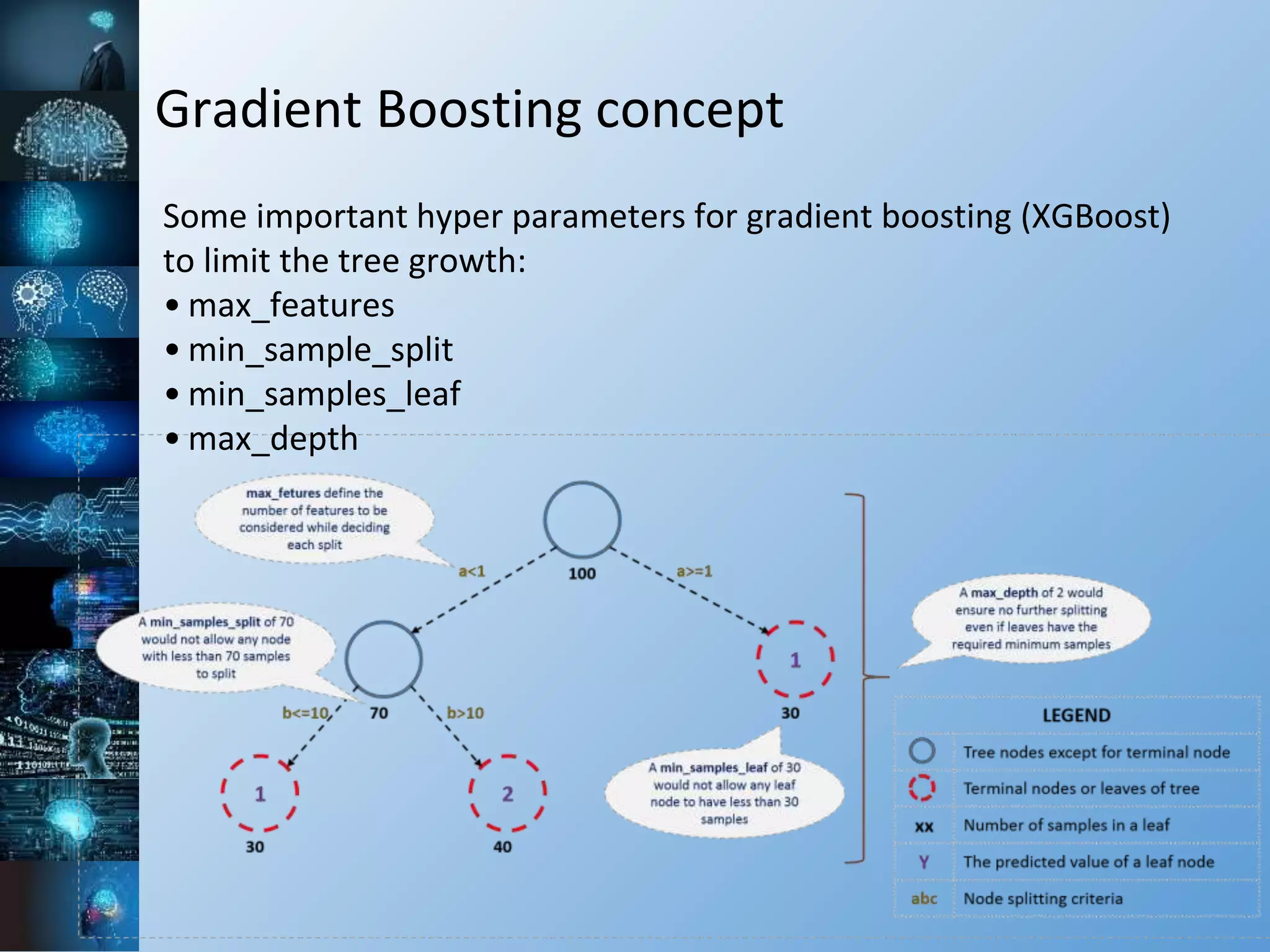
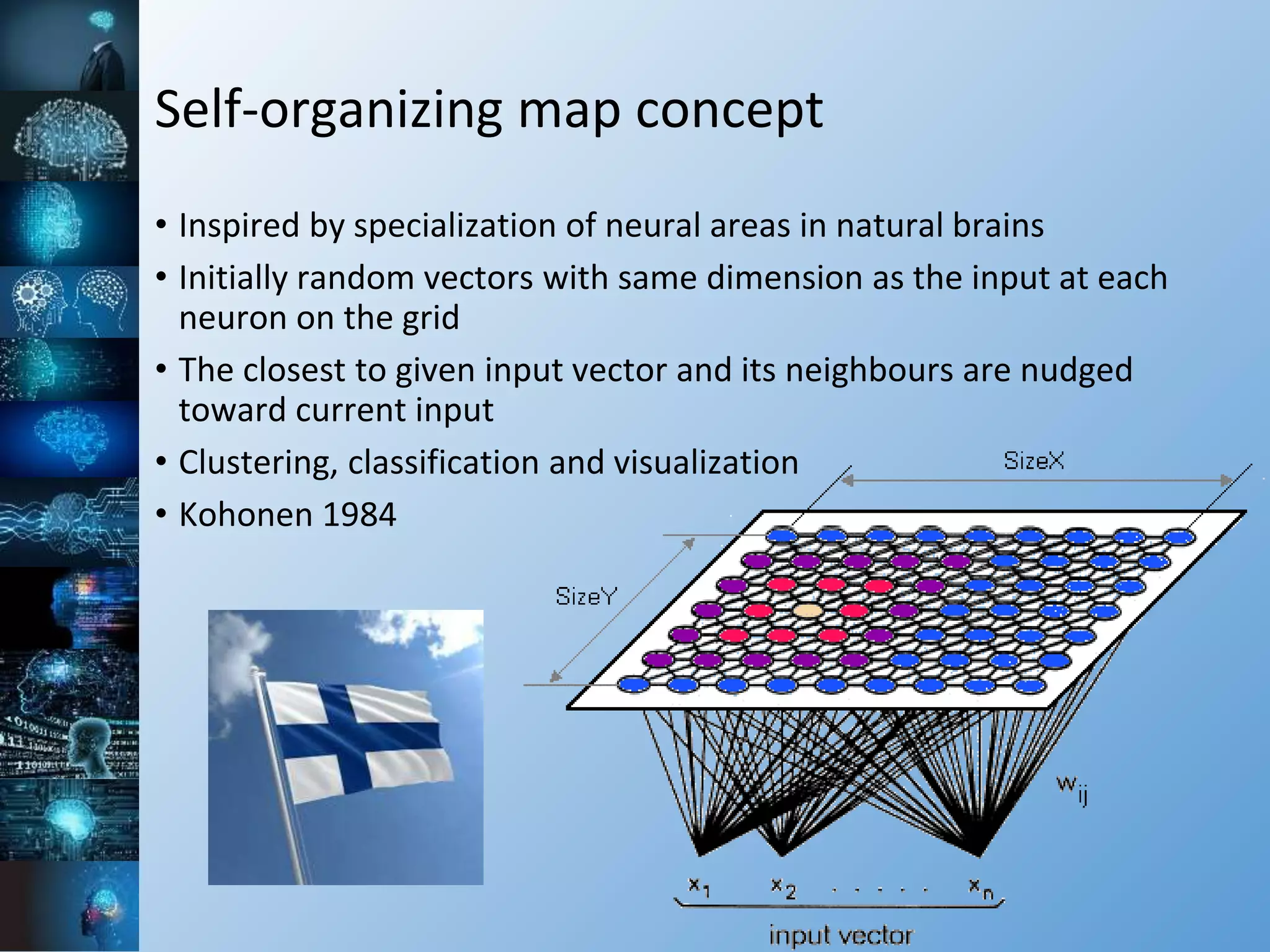
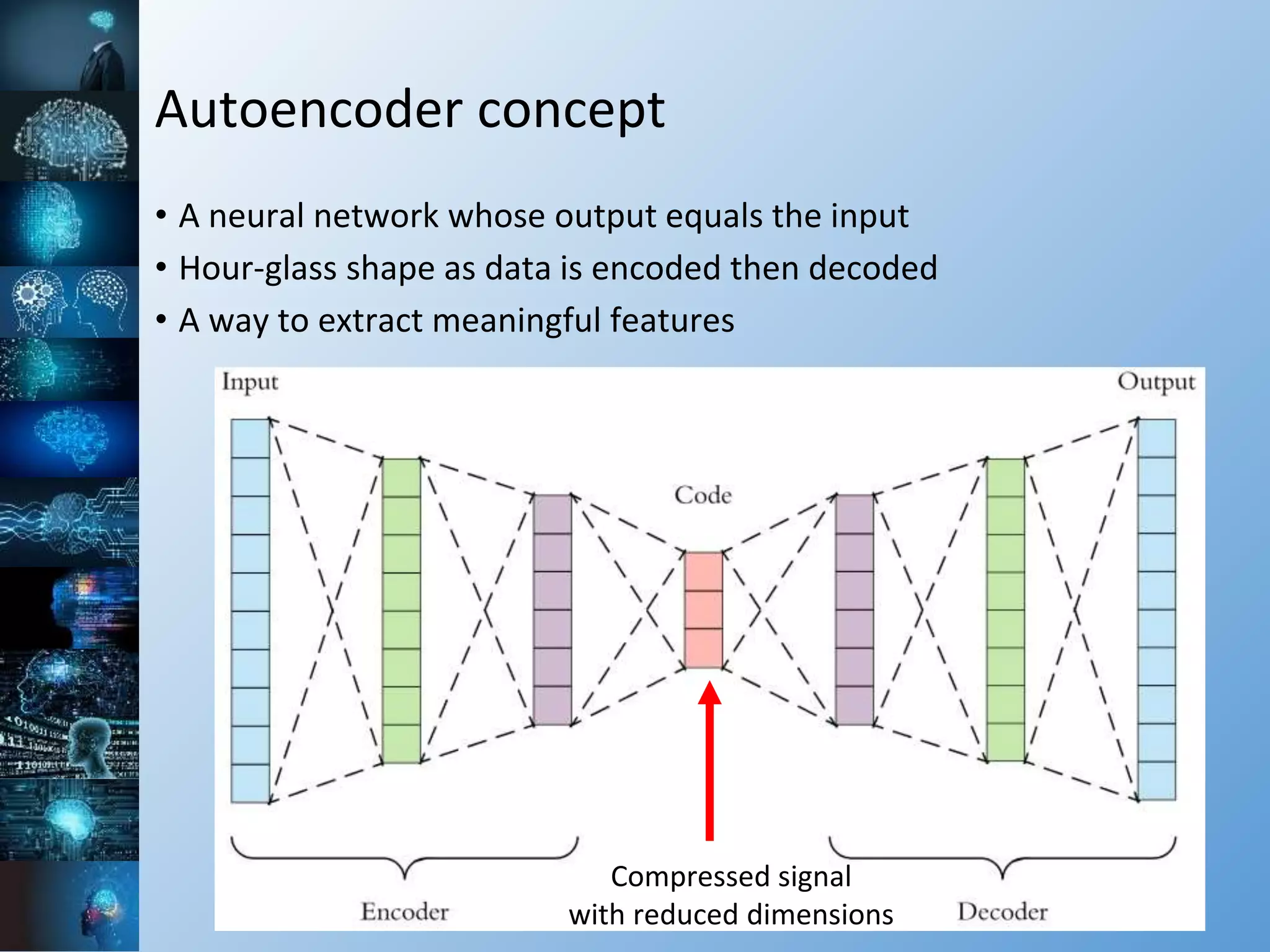
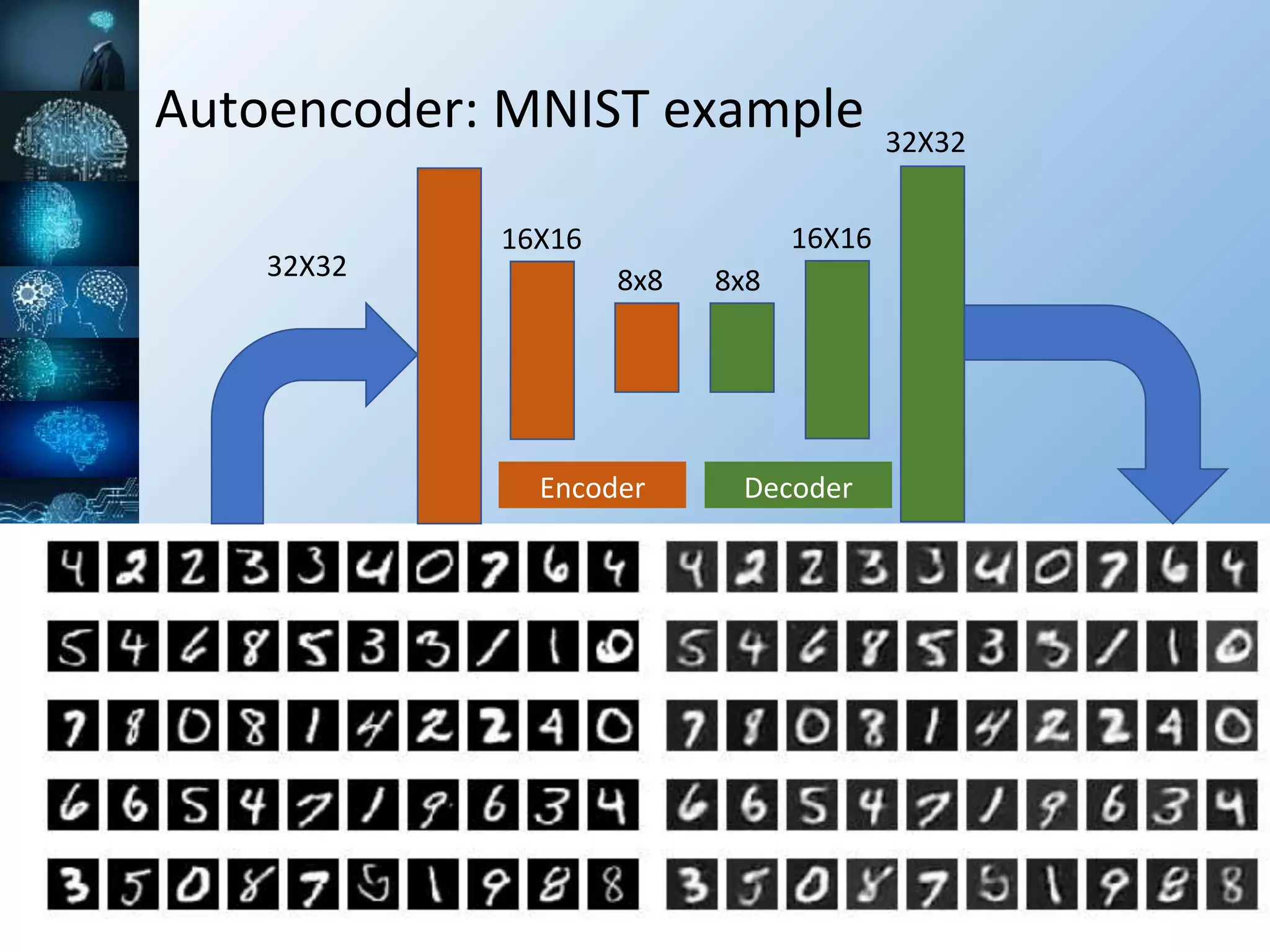
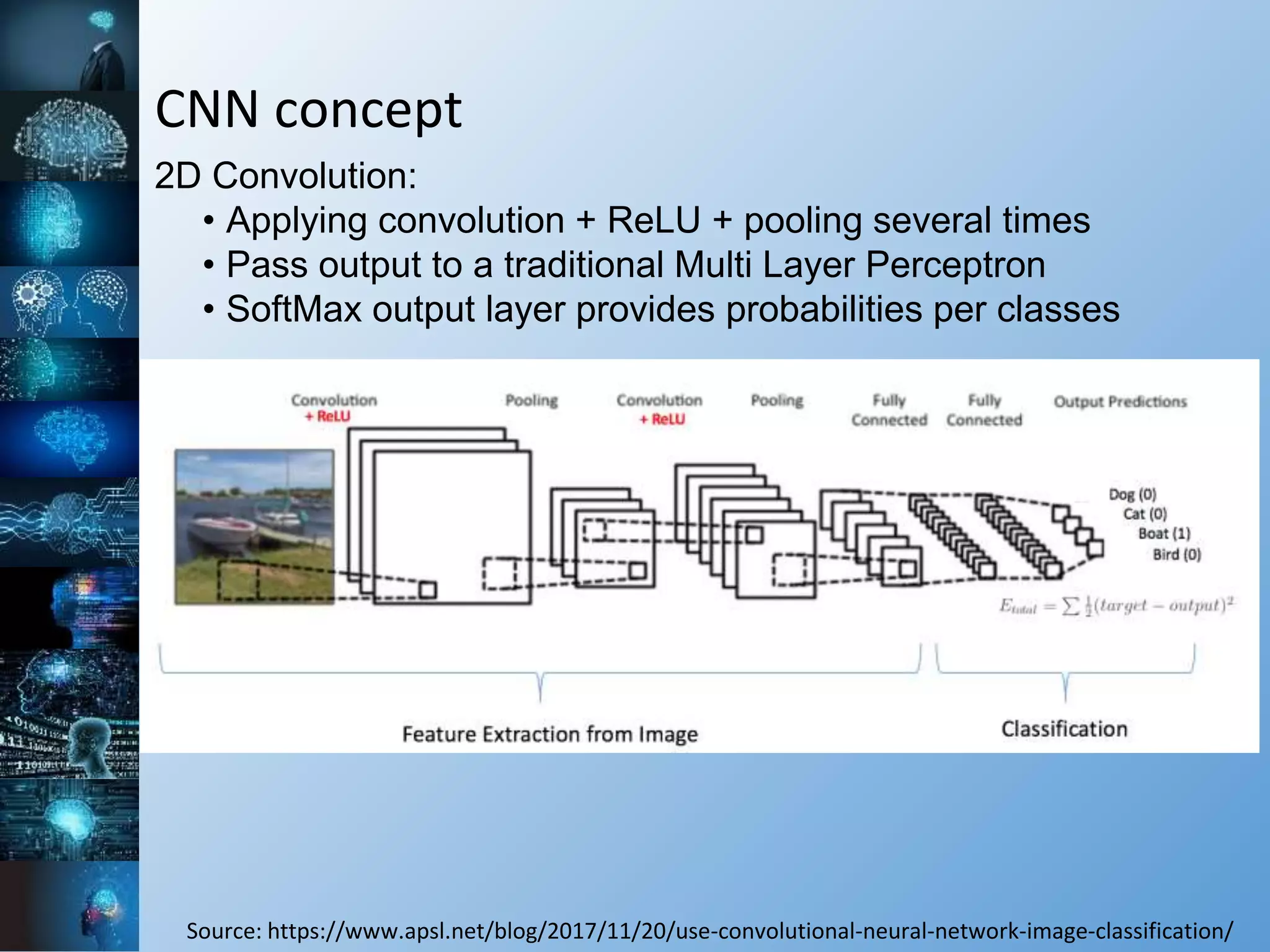
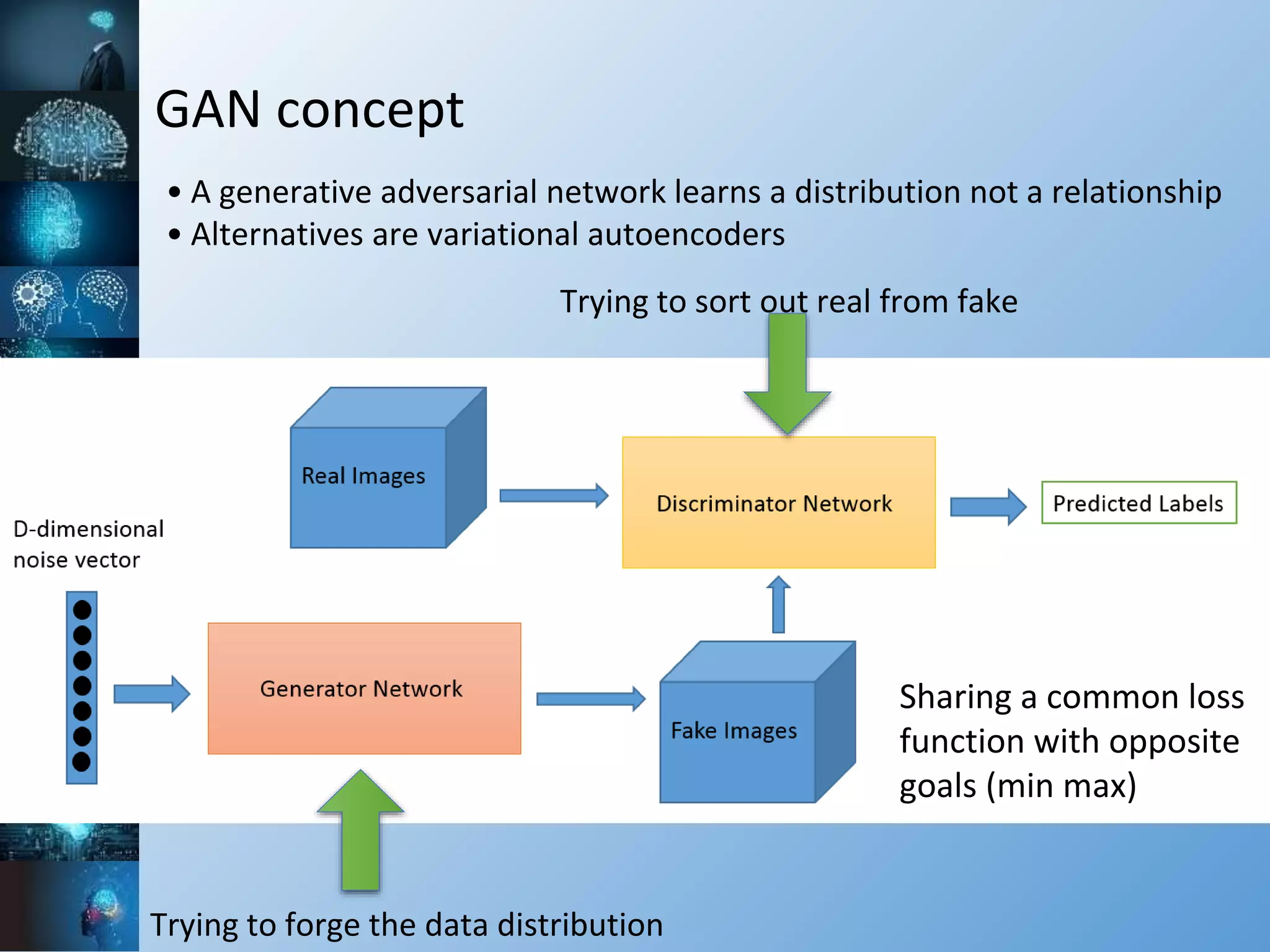
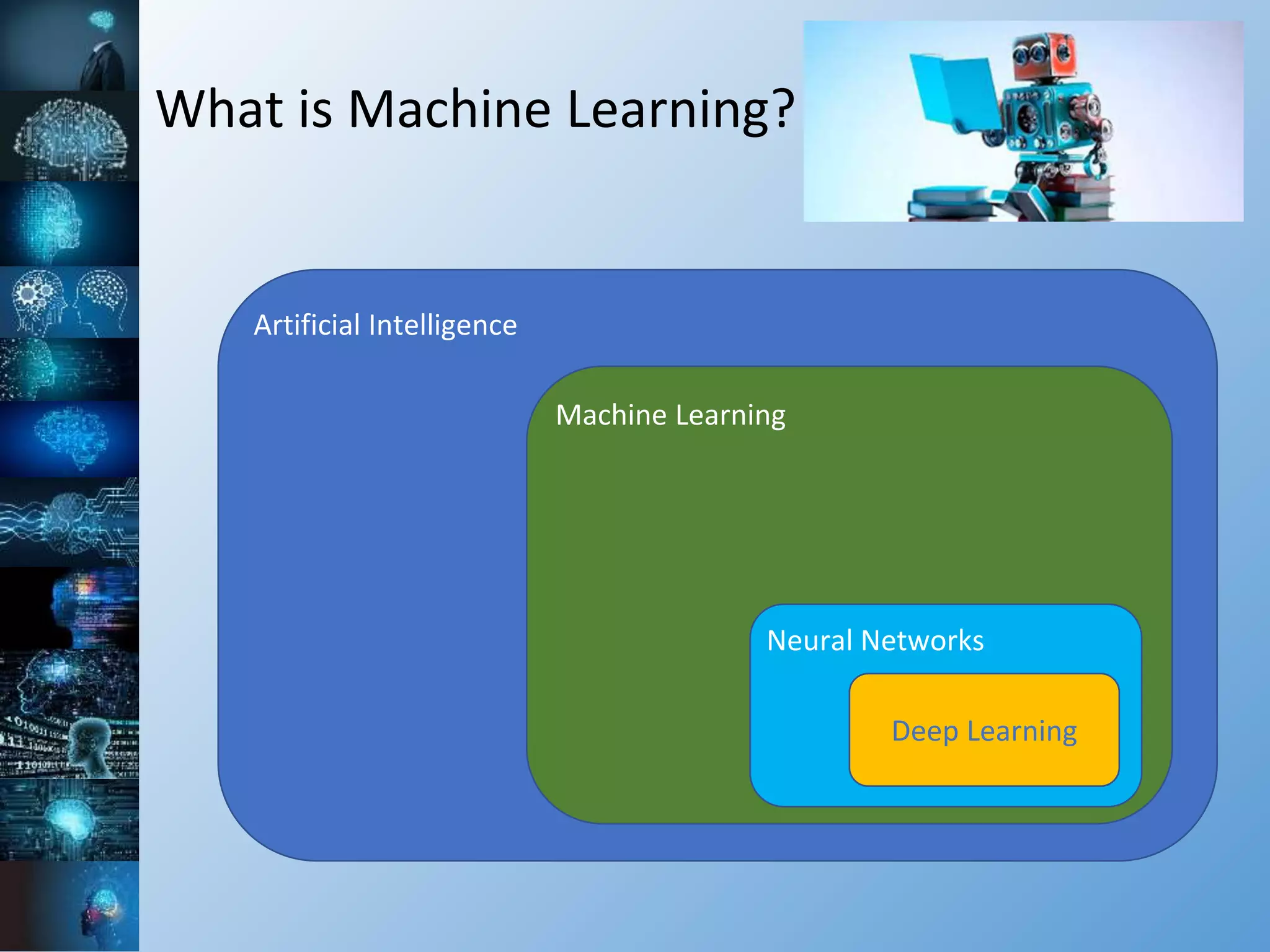
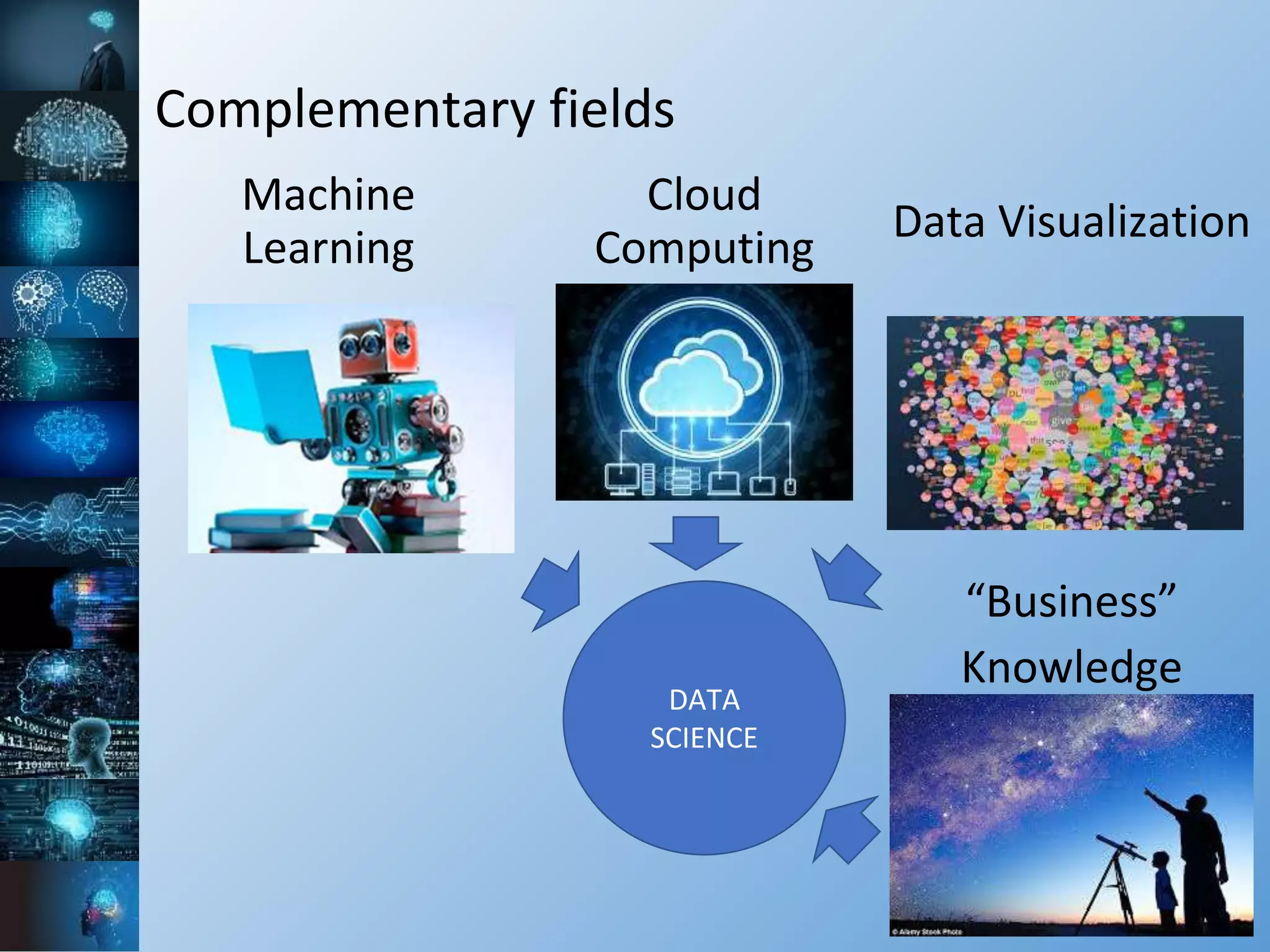
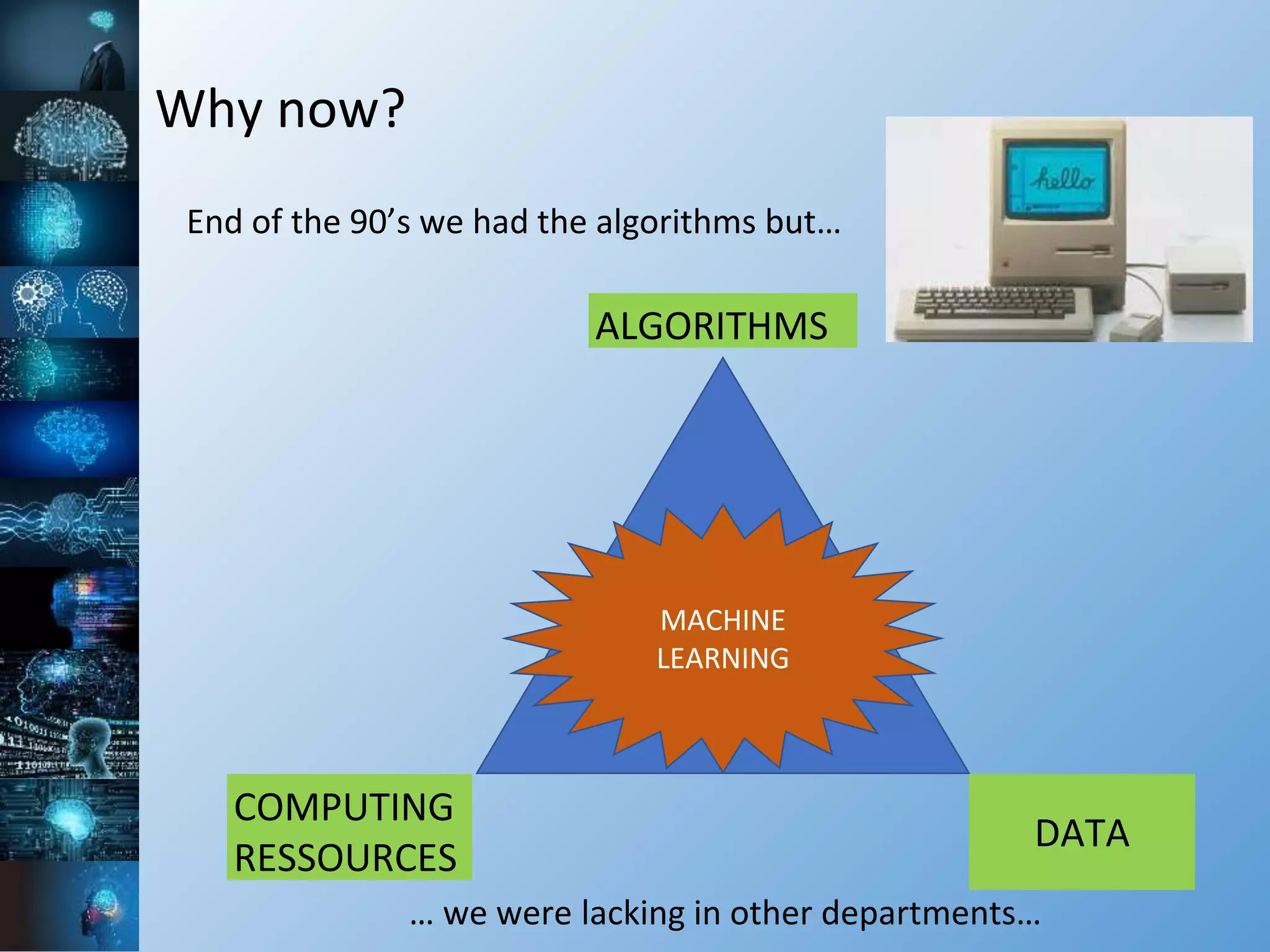
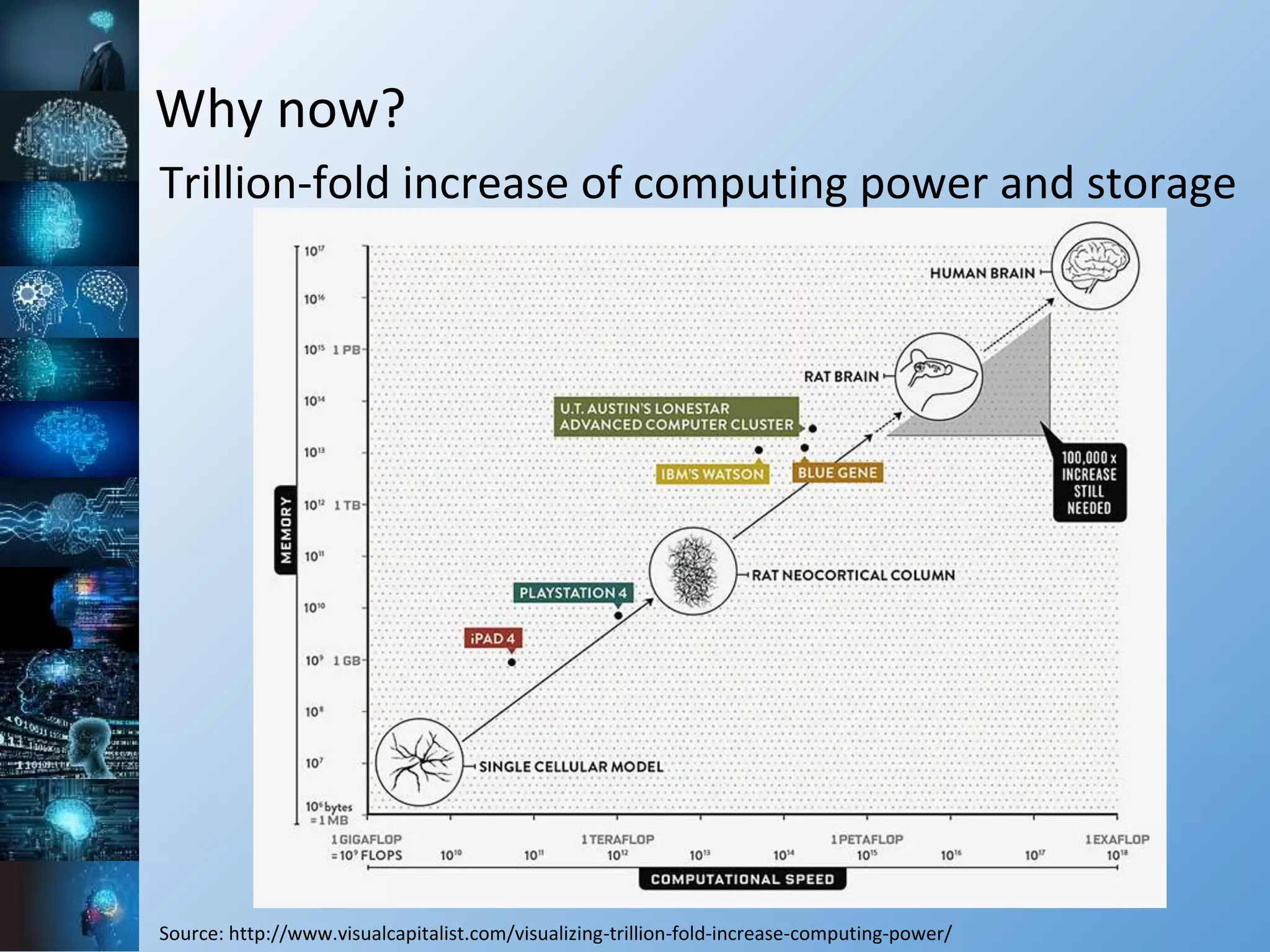
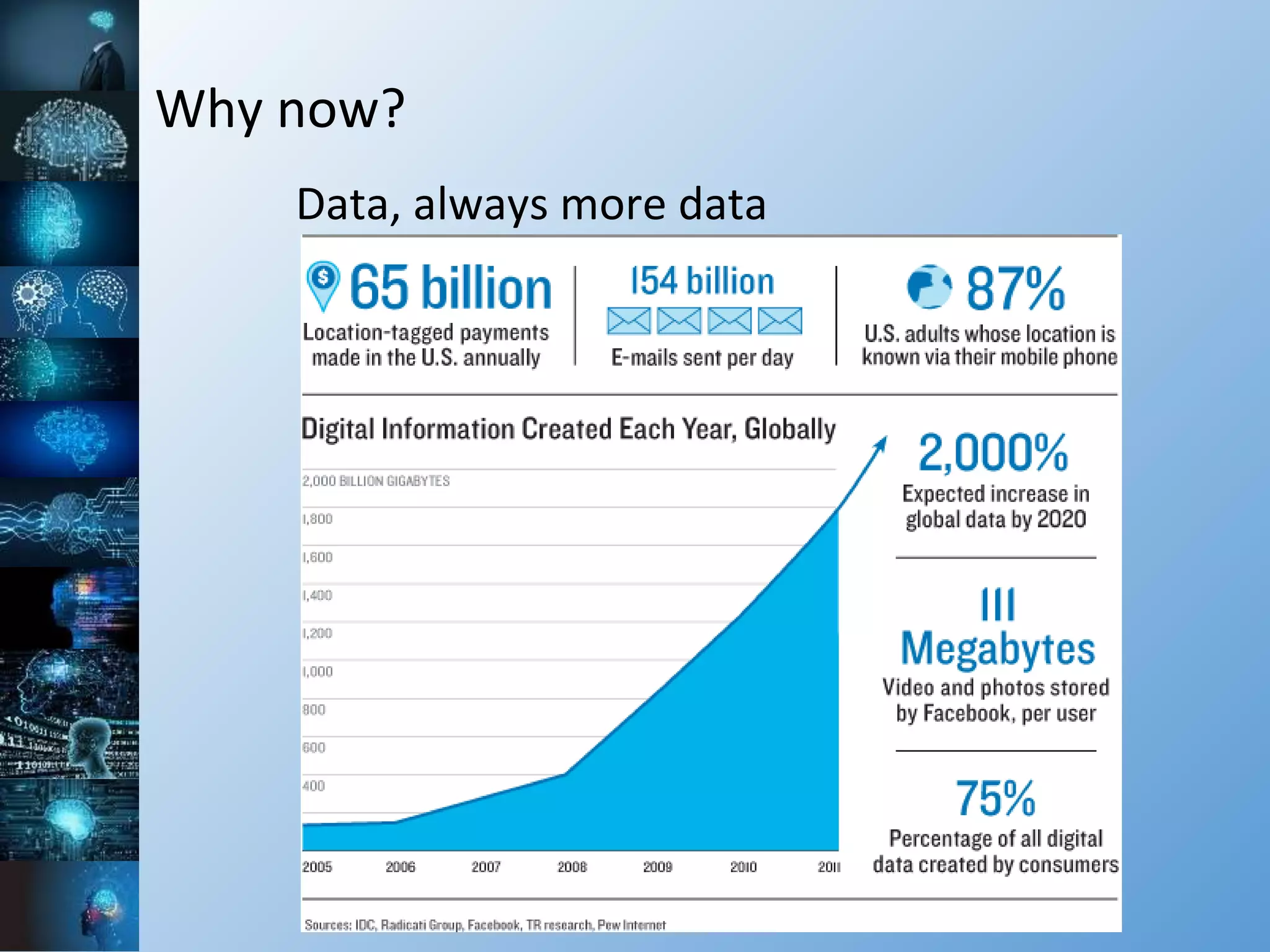
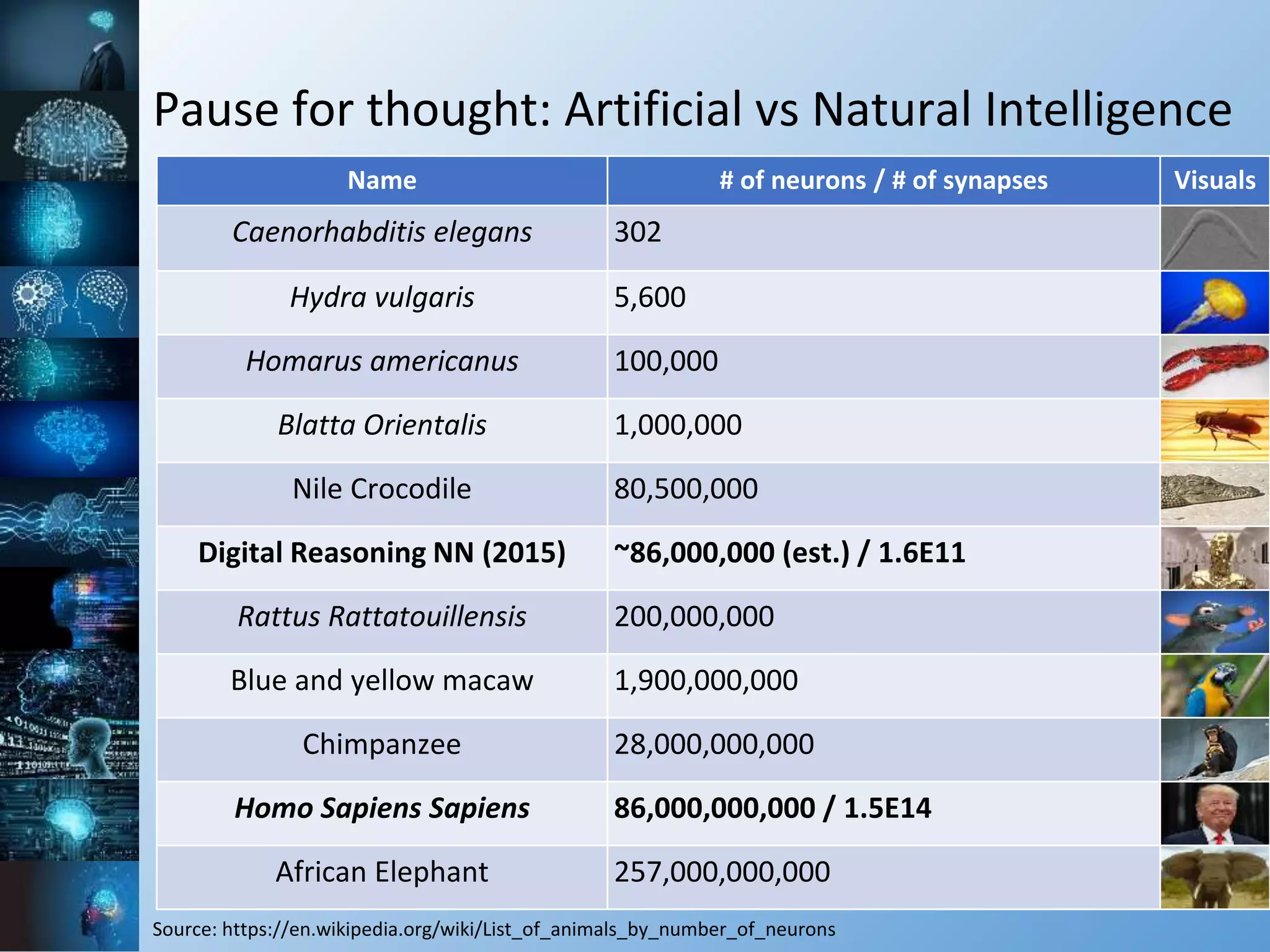
The document provides a comprehensive overview of machine learning, covering its definitions, history, and current applications, particularly in fields like astronomy. It outlines key concepts such as algorithms, neural networks, and the distinctions between machine learning and statistical modeling, as well as tools used in the field. Additionally, it highlights the growth of machine learning driven by advancements in algorithms, data availability, and computing power.
















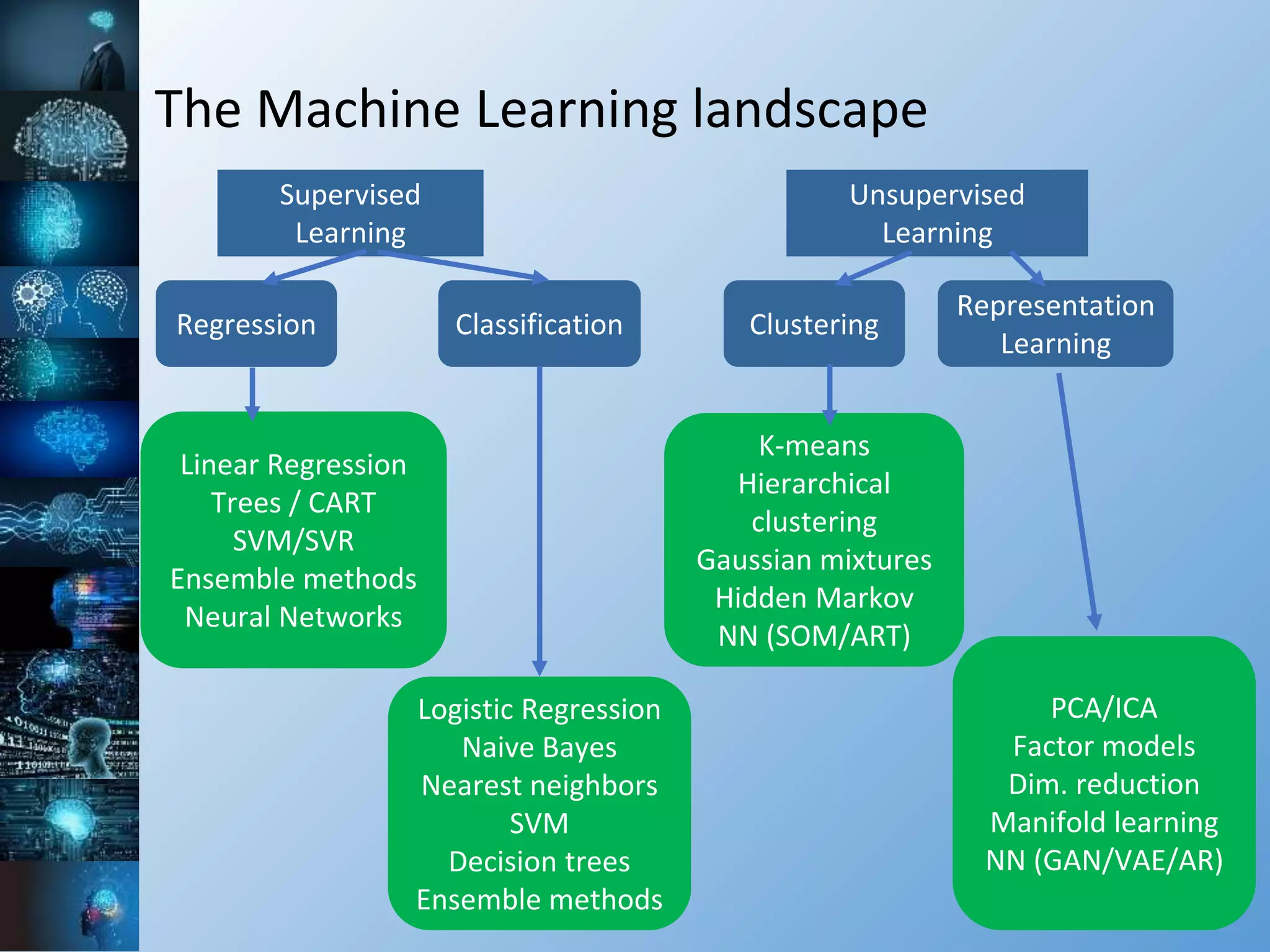
![The Machine Learning landscape
Supervised
Learning
Unsupervised
Learning
Regression Classification
Learn real-
valued
function
given
(Xi , Yi)
Learn
discrete
class
function
given
(Xi , Ci)
Clustering
Representation
Learning
Learn
discrete
class
function
given
(Xi ) only
Learn
representing
function given
(Xi ) only
Rn →[1,k] Rn →[1,k] Rn → RkRn → R](https://image.slidesharecdn.com/20181126-bse2018introductiontomachinelearningvmac-181127160616/75/Big-Sky-Earth-2018-Introduction-to-machine-learning-23-2048.jpg)


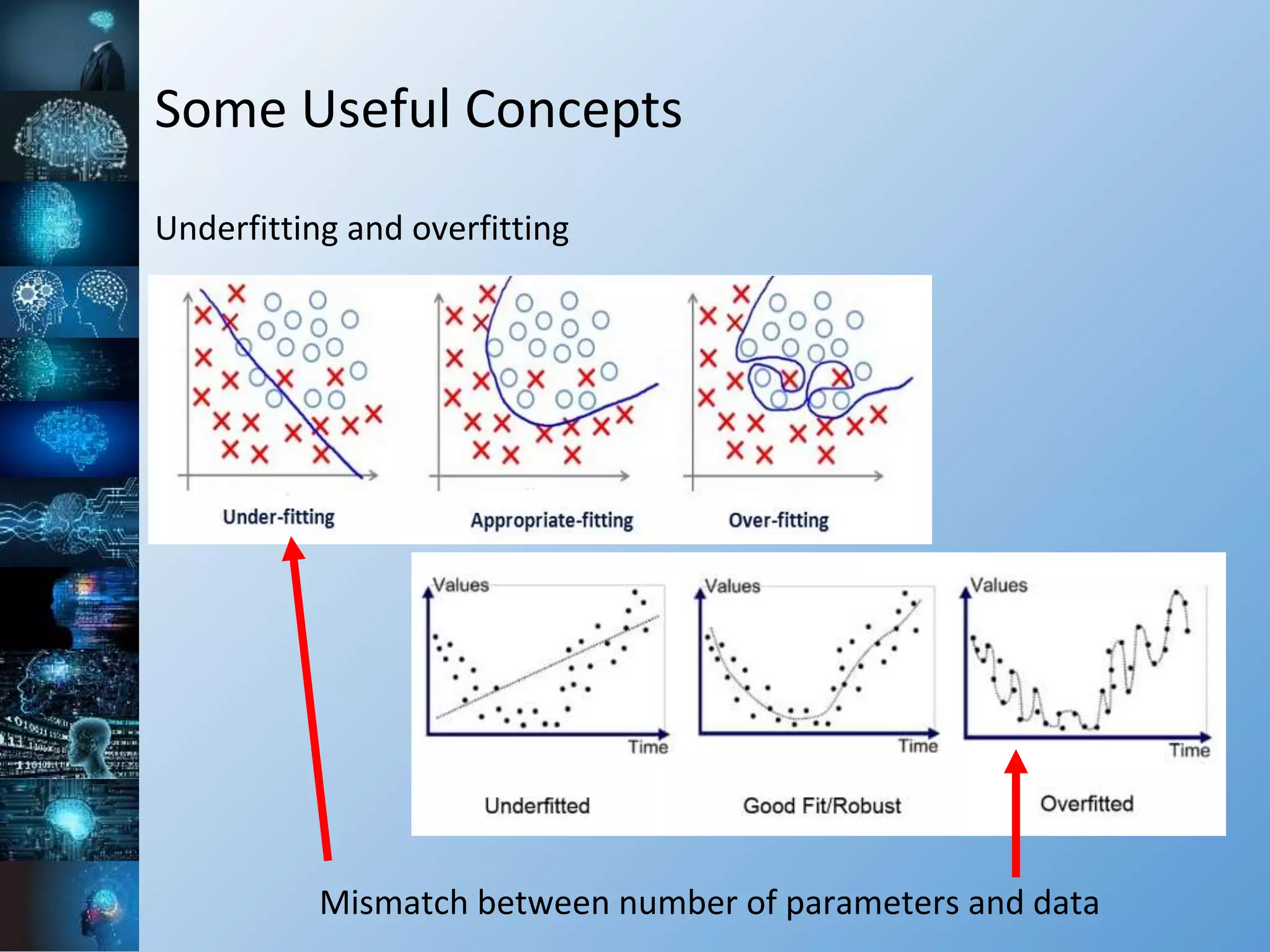
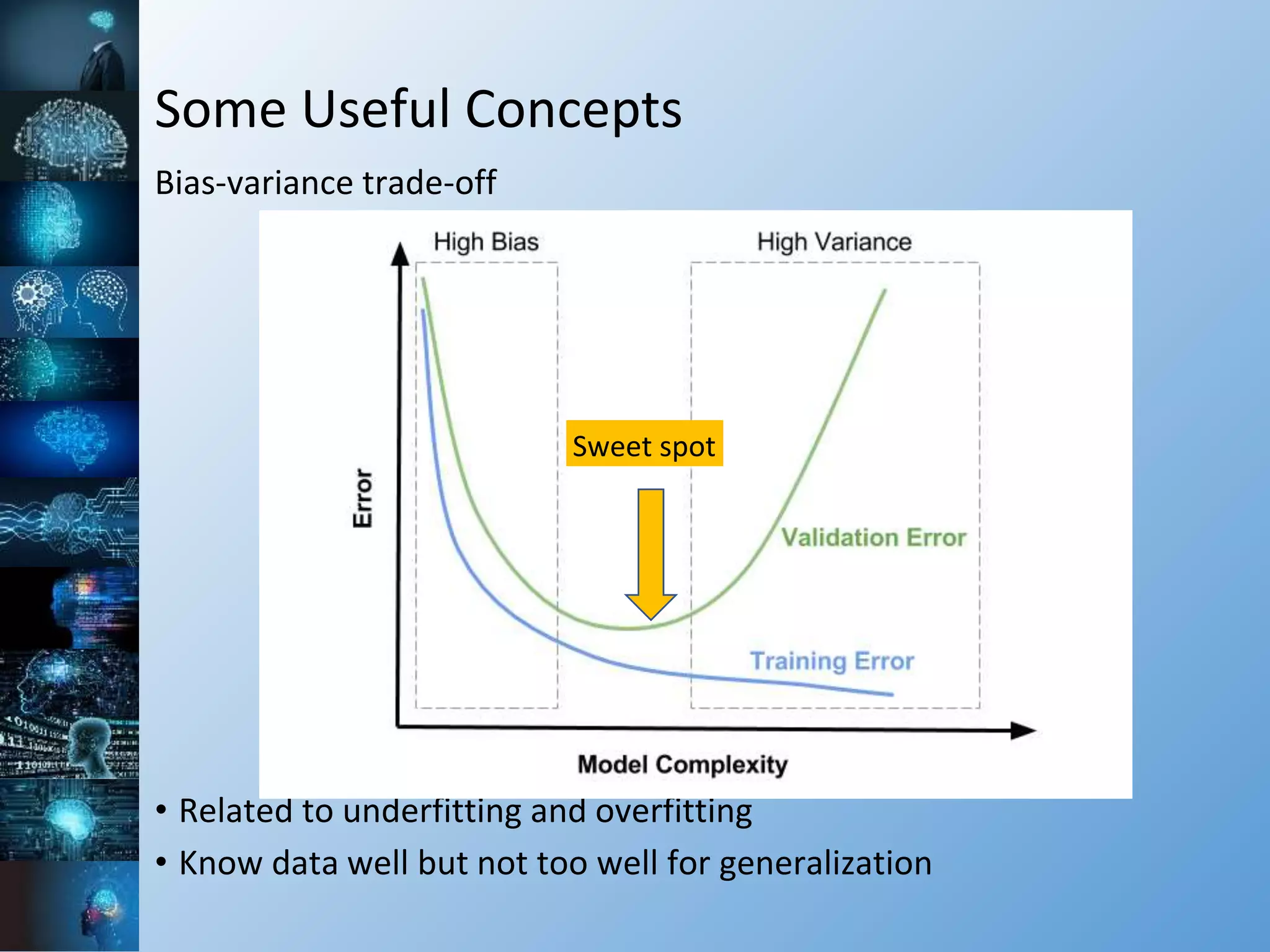

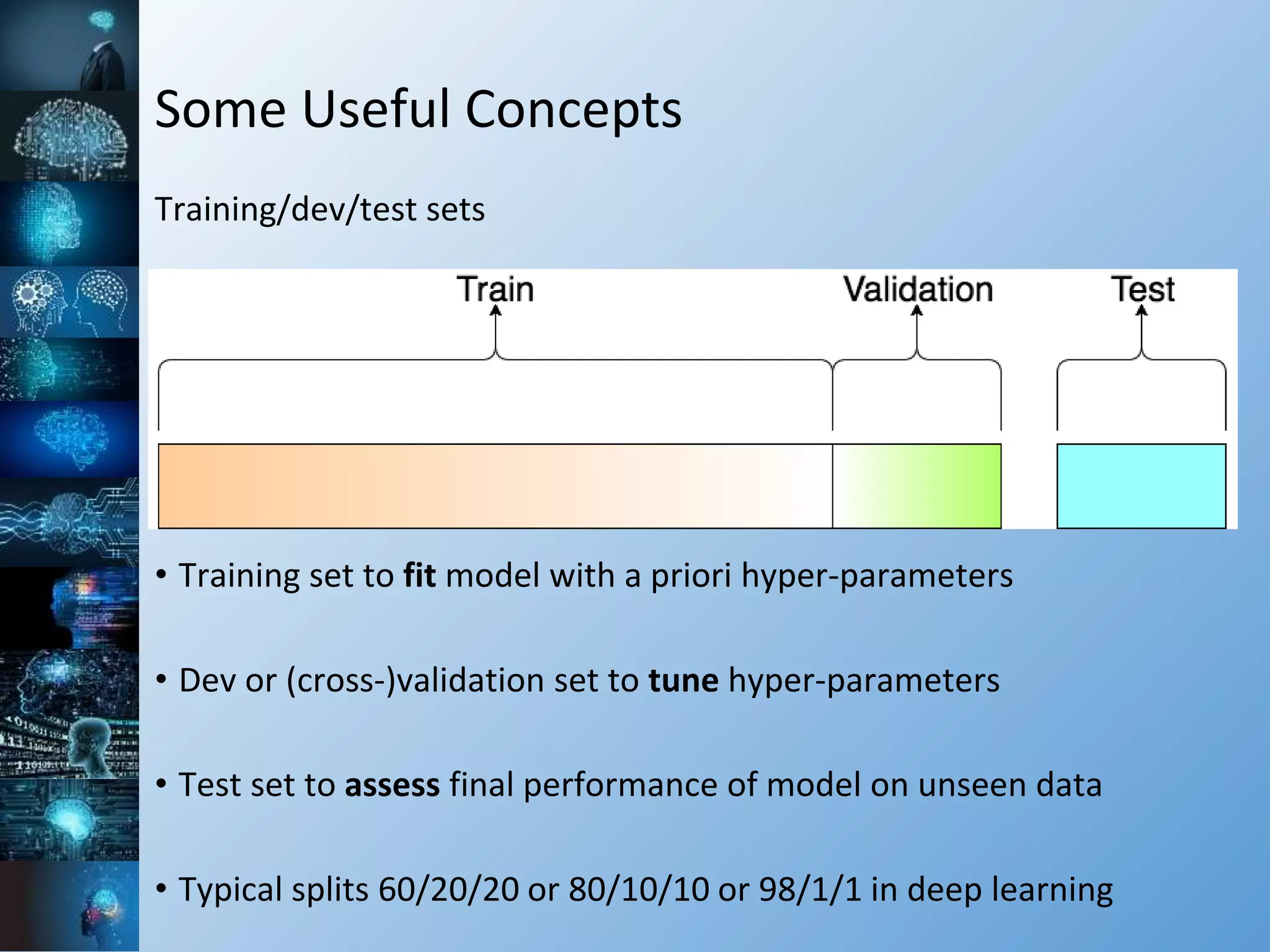
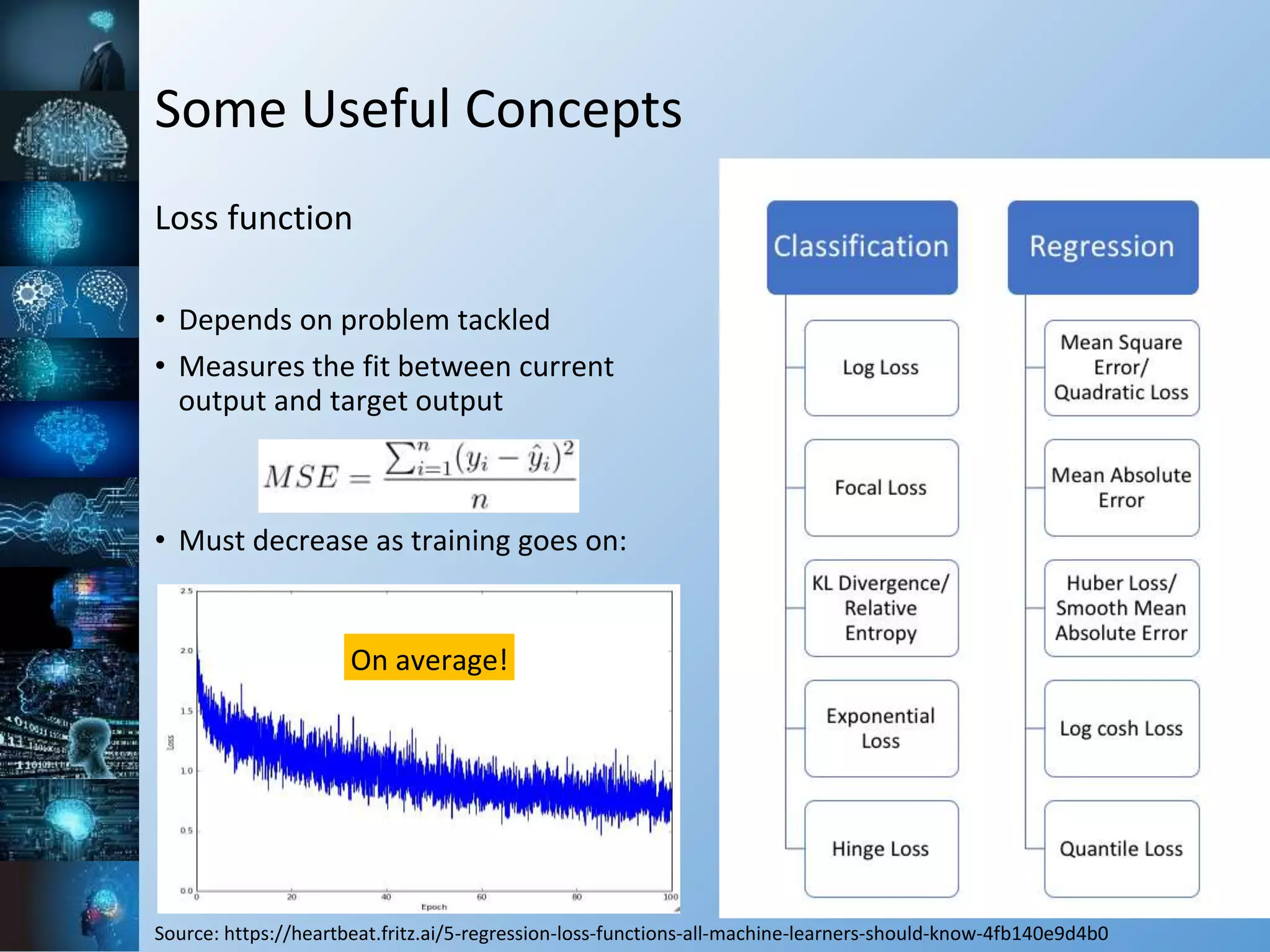
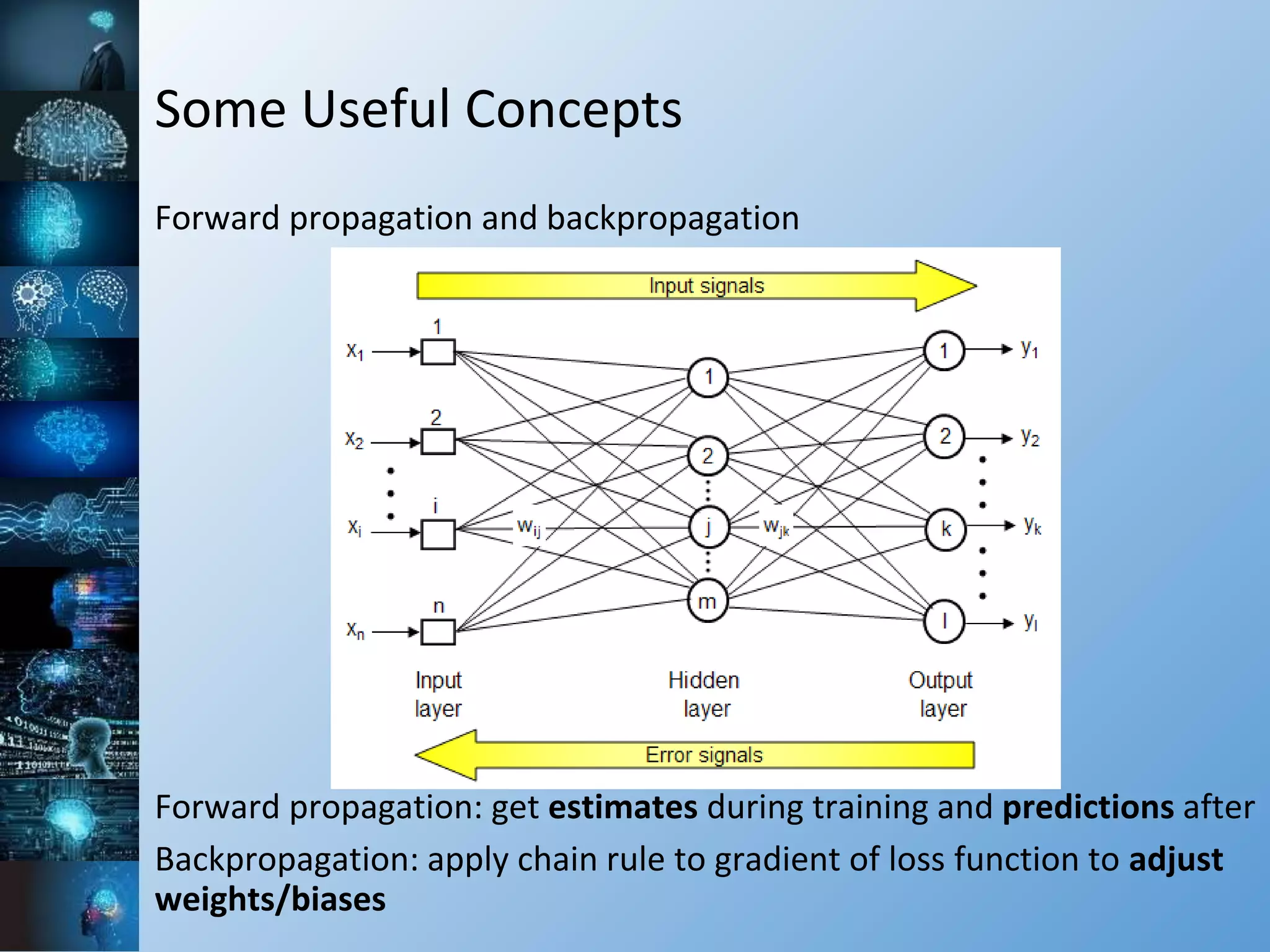
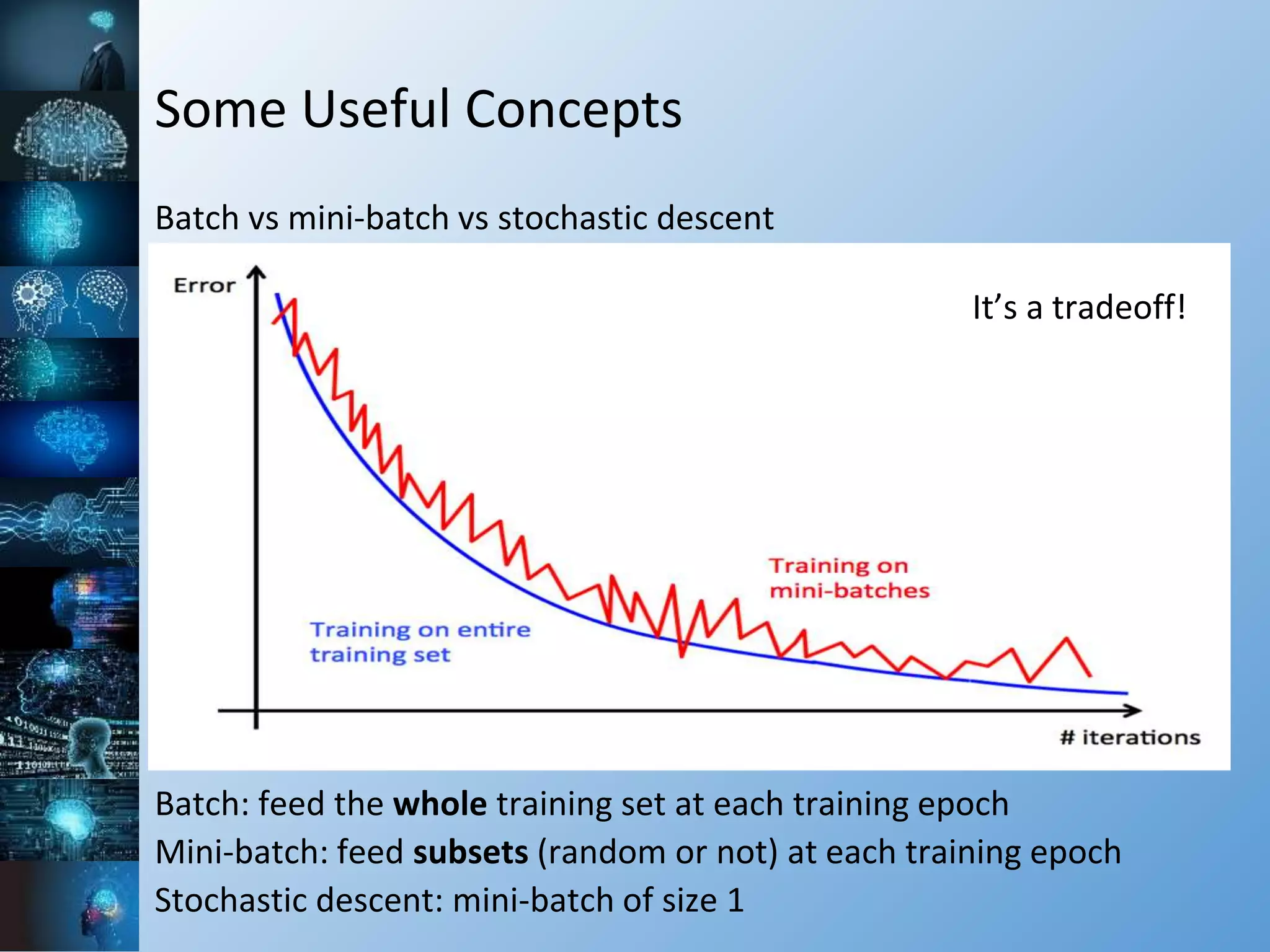
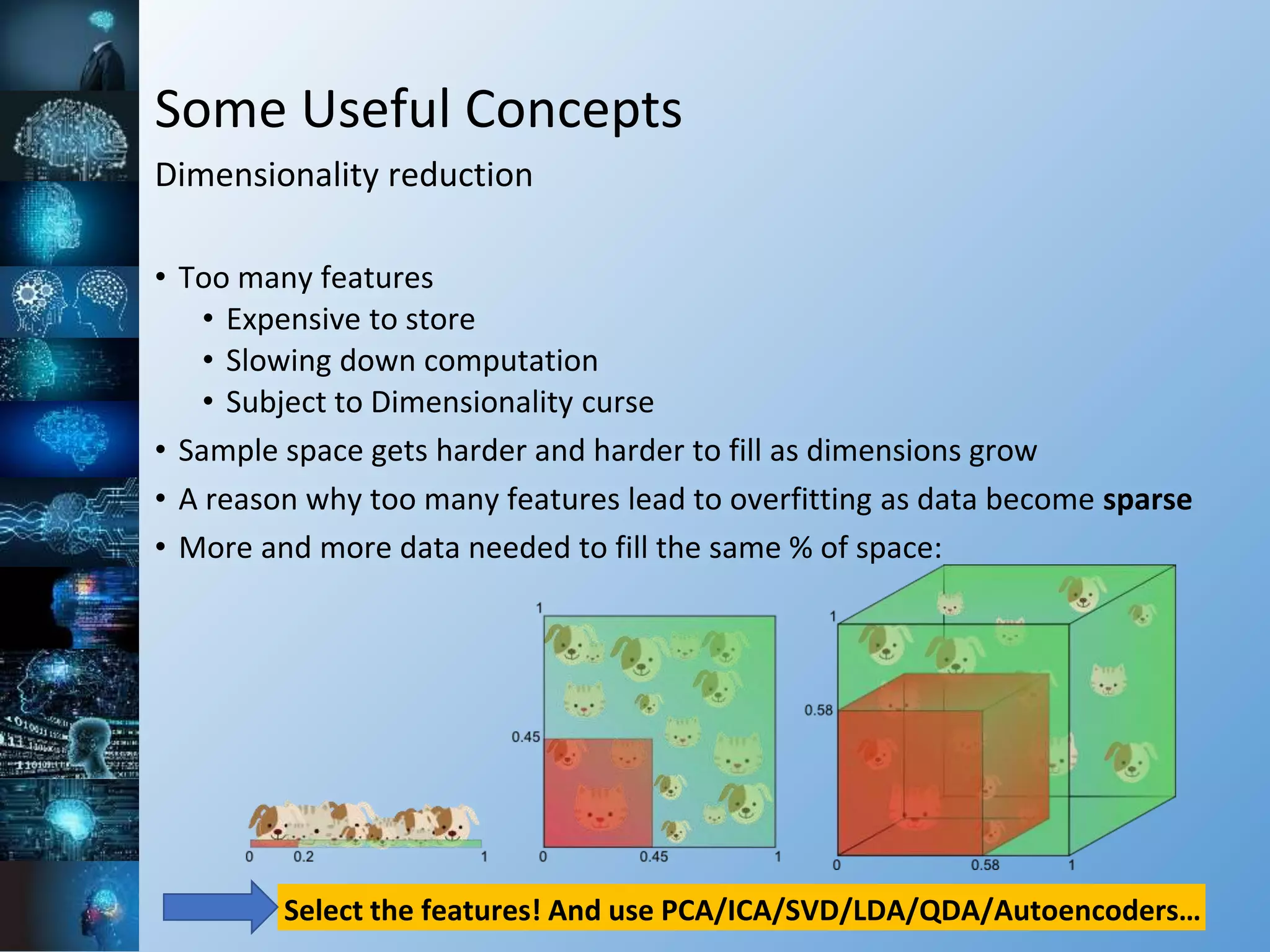


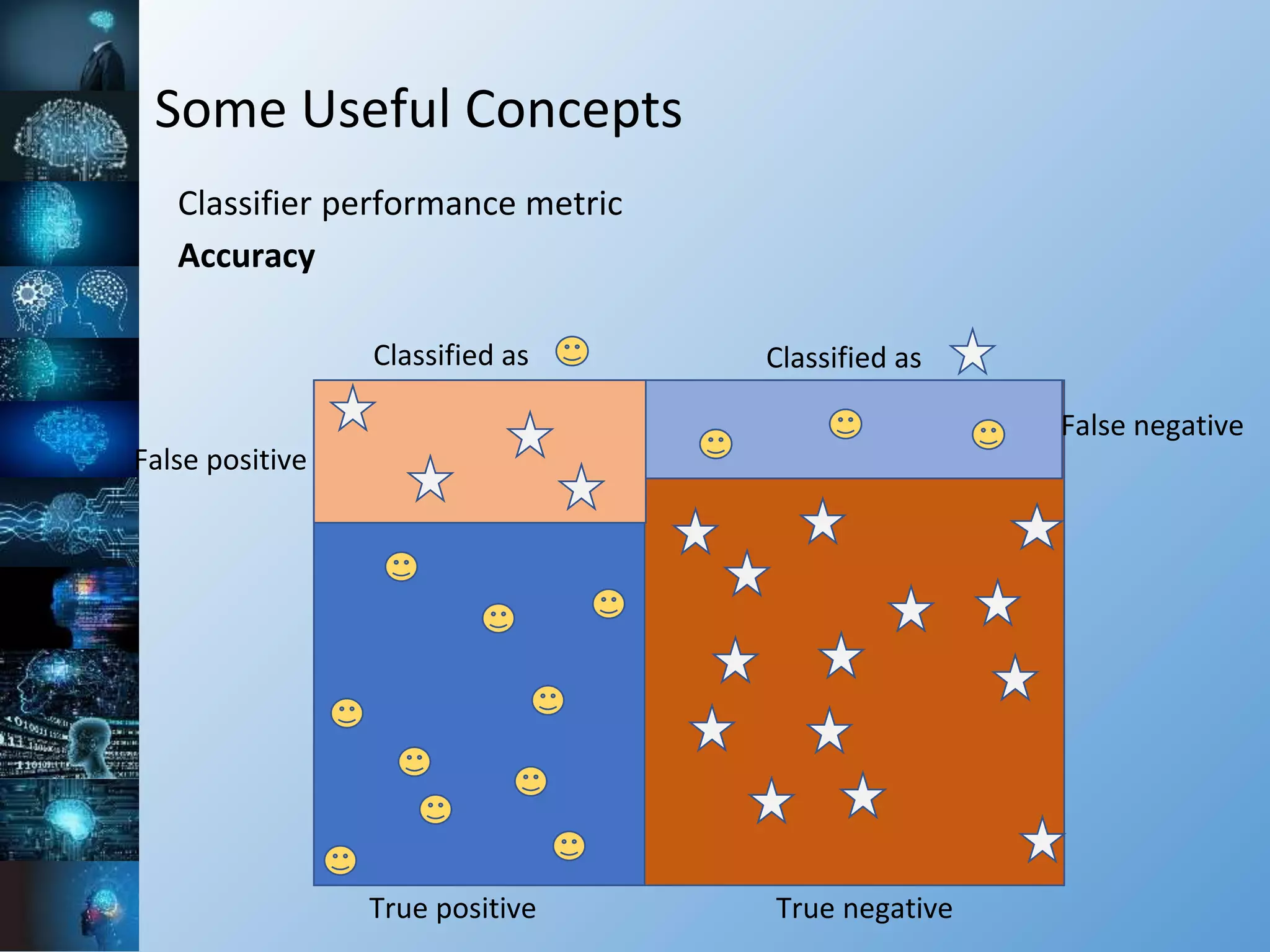
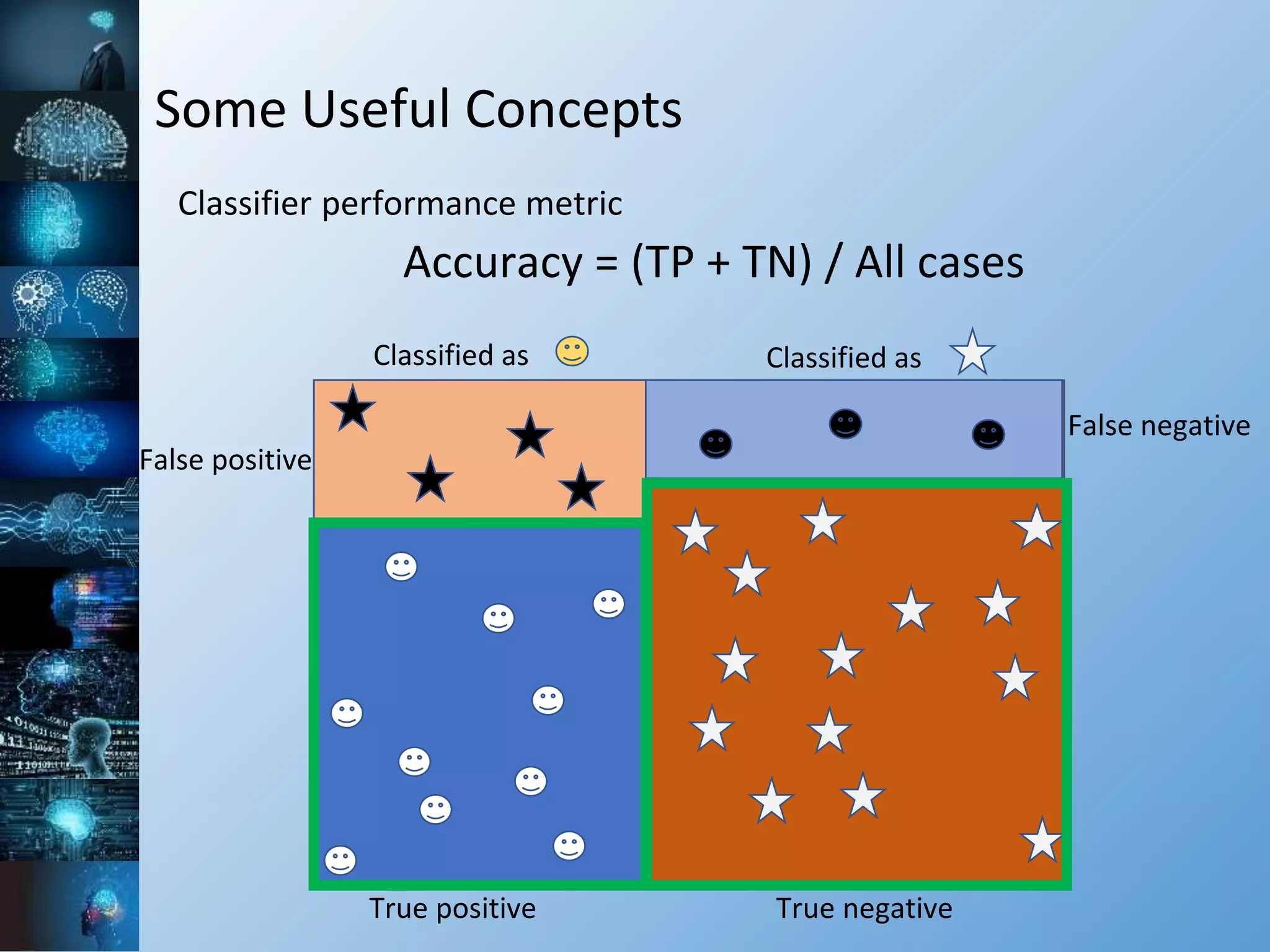

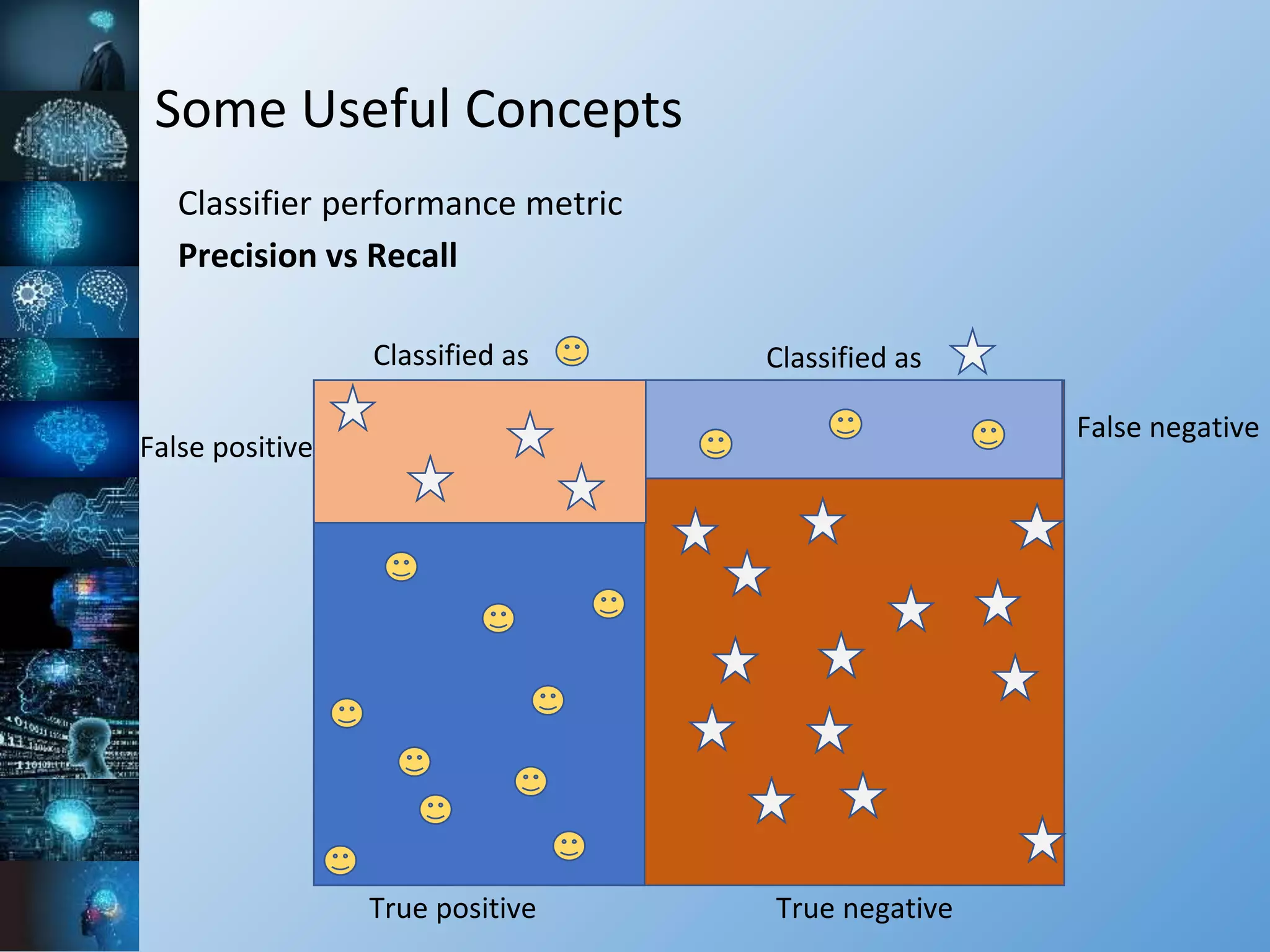
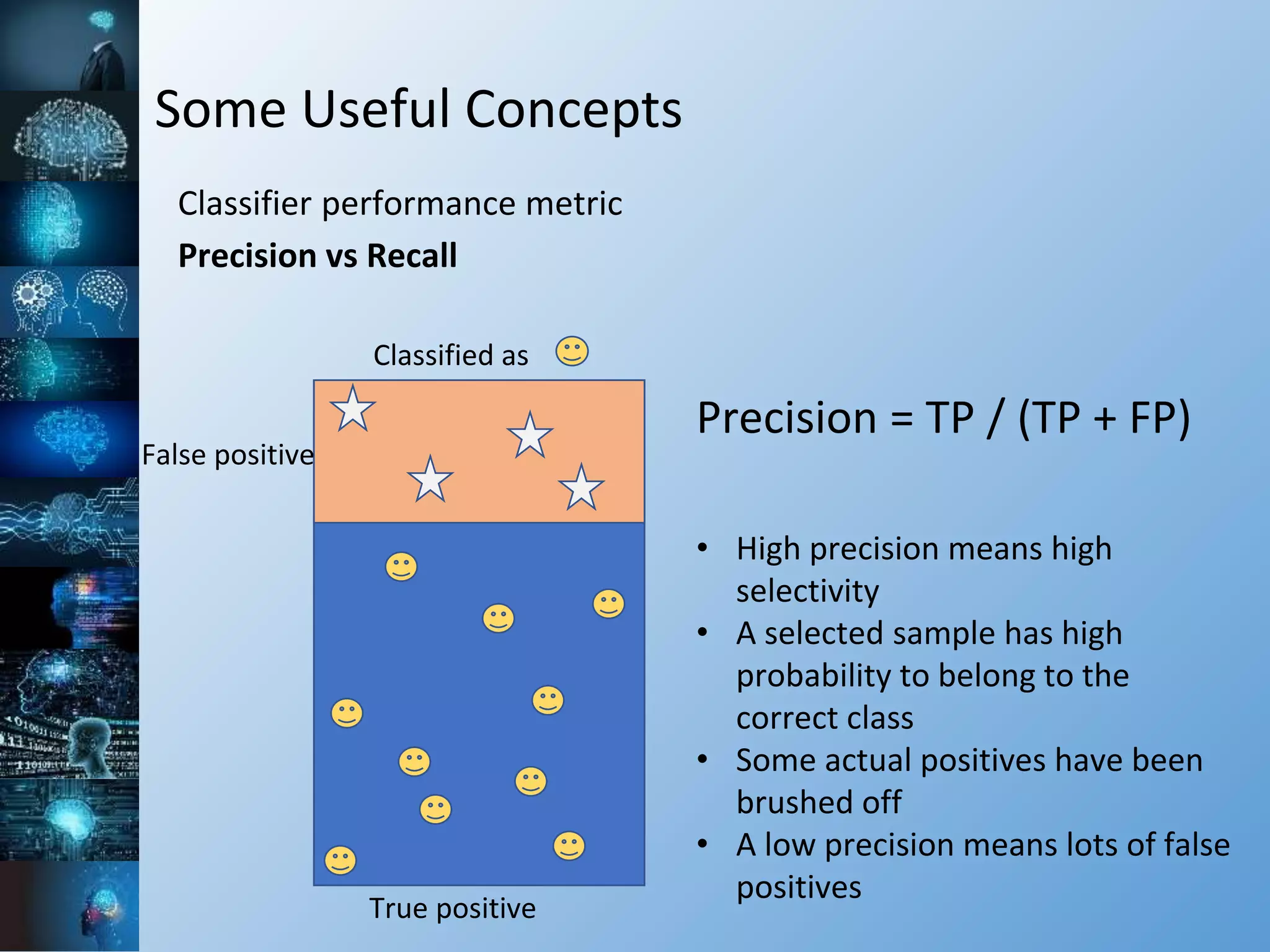
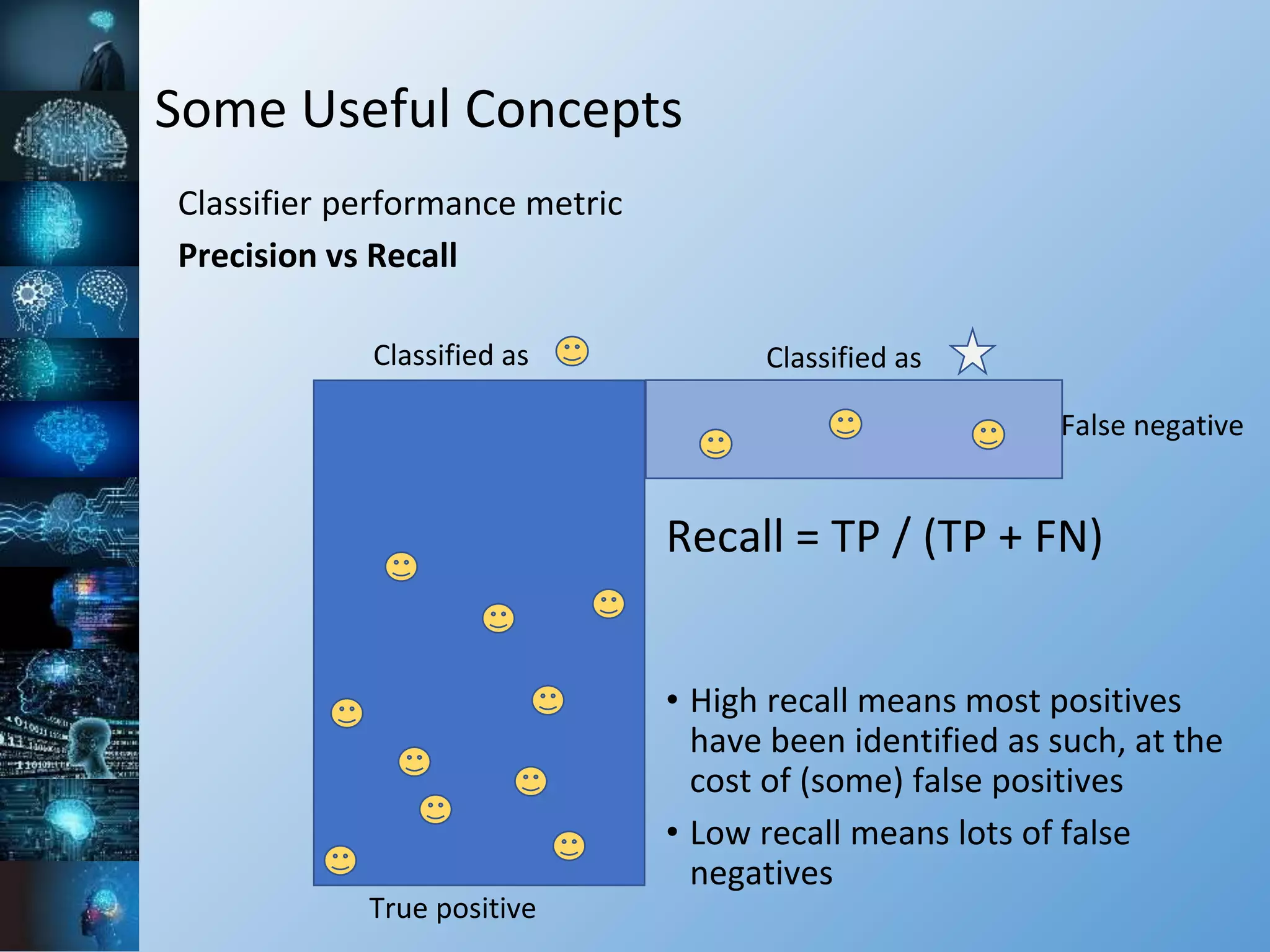

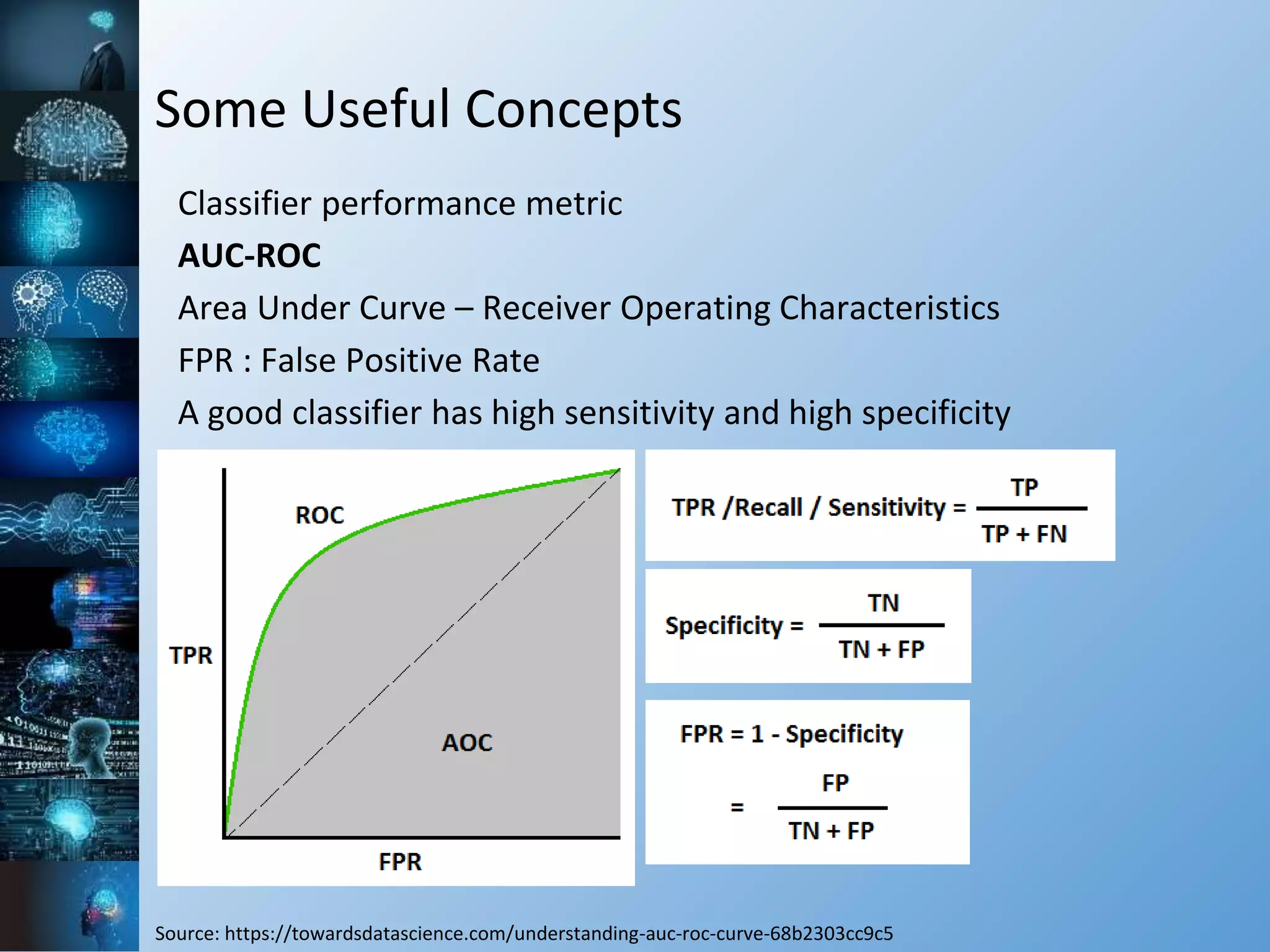
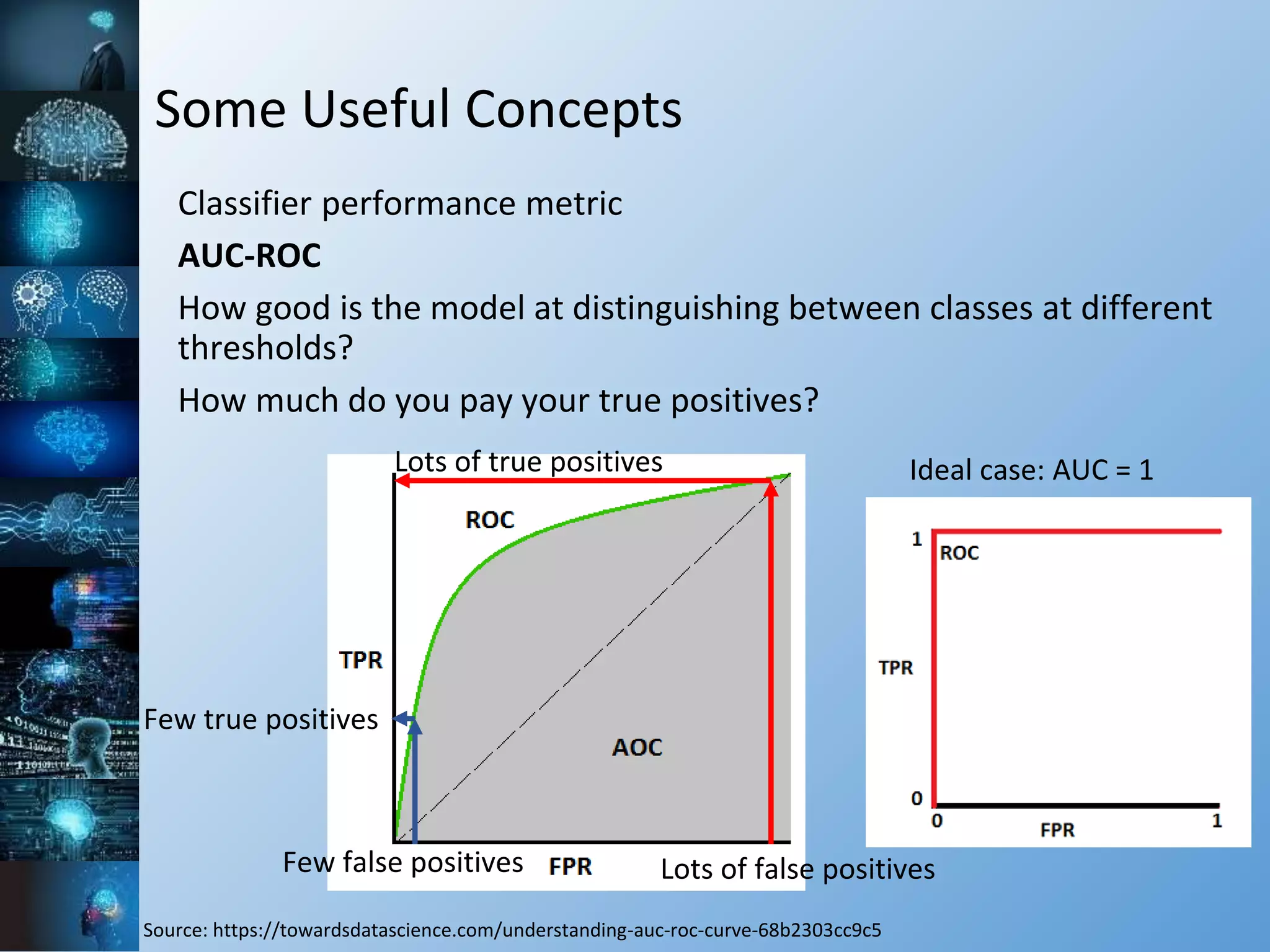
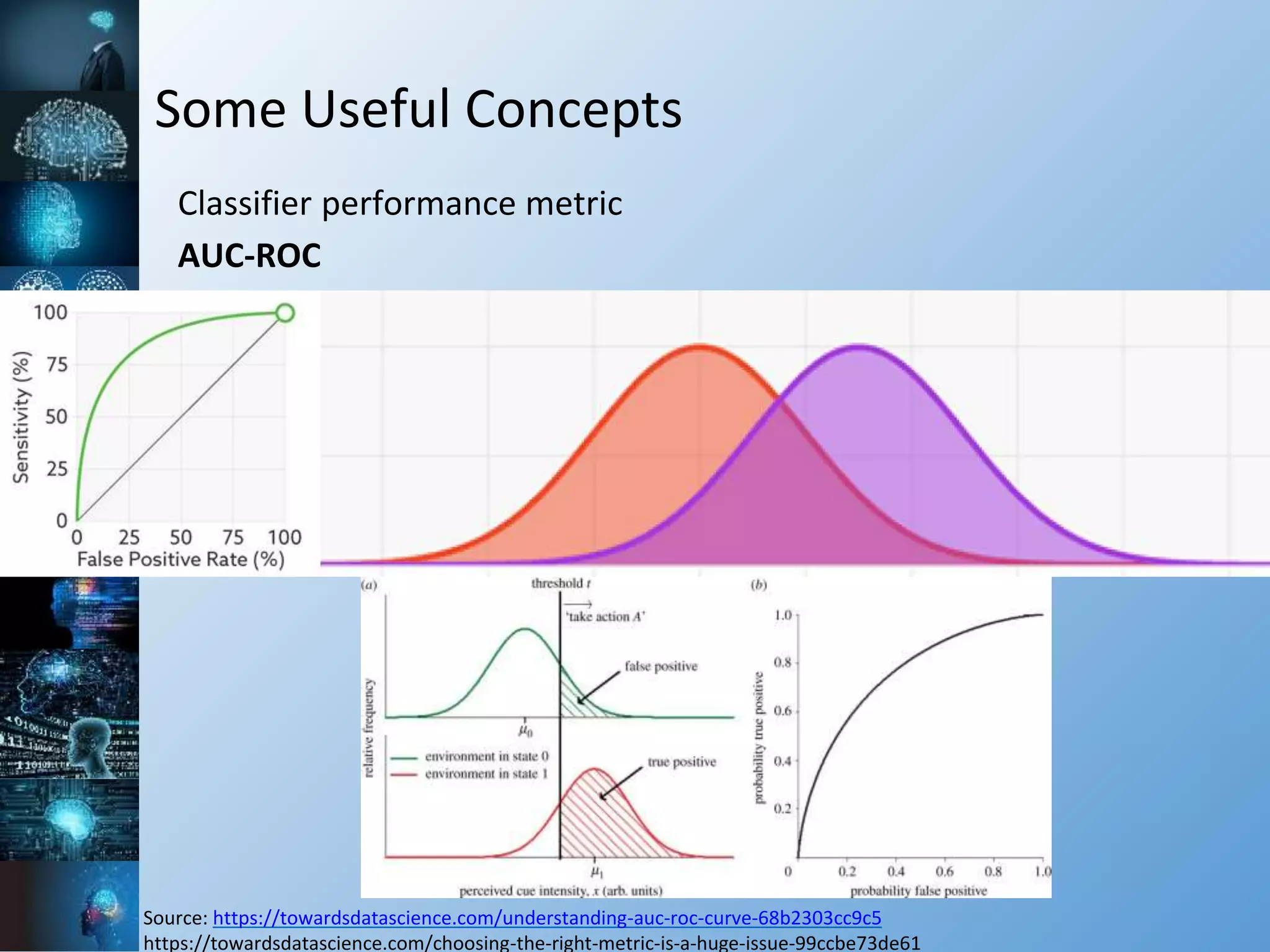

![Some Useful Concepts
Source: http://wiki.fast.ai/index.php/Log_Loss
−
1
𝑁
𝑖
𝑁
[𝑦𝑖 log 𝑝𝑖 + 1 − 𝑦𝑖 log(1 − 𝑝𝑖)]
−
1
𝑁
𝑖
𝑁
𝑐=1
𝑀
𝑦𝑖,𝑐log(𝑝𝑖,𝑐)
If more than 2 classes:GoodNot good
Classifier performance metric
Log-Loss
• Adapted to binary outputs and multi-classes data sets (if not too imbalanced)
• Punishes extreme probability values when these are wrong](https://image.slidesharecdn.com/20181126-bse2018introductiontomachinelearningvmac-181127160616/75/Big-Sky-Earth-2018-Introduction-to-machine-learning-59-2048.jpg)




![Zoom on Scikit-Learn logic
1- Import model
from sklearn import svm
from sklearn.neighbors import KNeighborsClassifier
2 - Instantiate model class
clf = svm.SVC(gamma=0.001, C=100.)
knn = KNeighborsClassifier()
3 - Train with the fit() method
knn.fit(iris_X_train, iris_y_train)
4 - Make predictions with predict()
clf.predict(digits.data[-1:])
knn.predict(iris_X_test)](https://image.slidesharecdn.com/20181126-bse2018introductiontomachinelearningvmac-181127160616/75/Big-Sky-Earth-2018-Introduction-to-machine-learning-65-2048.jpg)
![Zoom on Keras logic
1- Import model class
from keras.models import Sequential
2 - Instantiate model class
model = Sequential()
3 - Add layers with the add() method specifying input_dim or input_shape
model.add(Dense(32, input_dim=784))
4 - Add activation functions
model.add(Activation('relu'))
5 - Configure training with compile(loss=,optimizer=, metrics[])
model.compile(optimizer='rmsprop', loss='binary_crossentropy’,
metrics=['accuracy'])
6 - Train with the fit() method
model.fit(data, labels, epochs=10, batch_size=32)
7- Evaluate the model performance with the evaluate() method:
score = model.evaluate(x_test, y_test, verbose=0)
8 – Make predictions with predict():
predictions = model.predict(x_test)](https://image.slidesharecdn.com/20181126-bse2018introductiontomachinelearningvmac-181127160616/75/Big-Sky-Earth-2018-Introduction-to-machine-learning-66-2048.jpg)