Downloaded 45 times



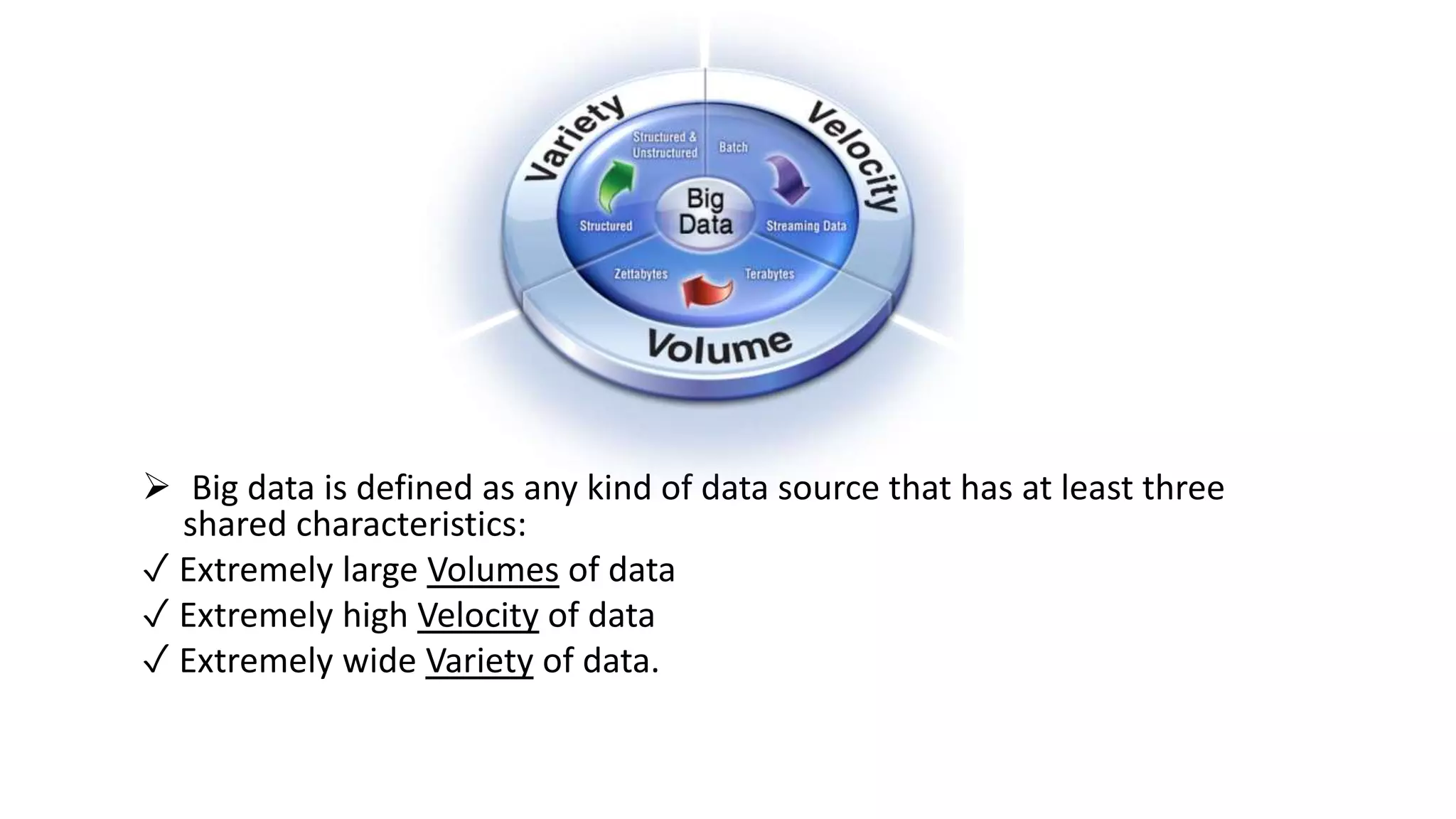




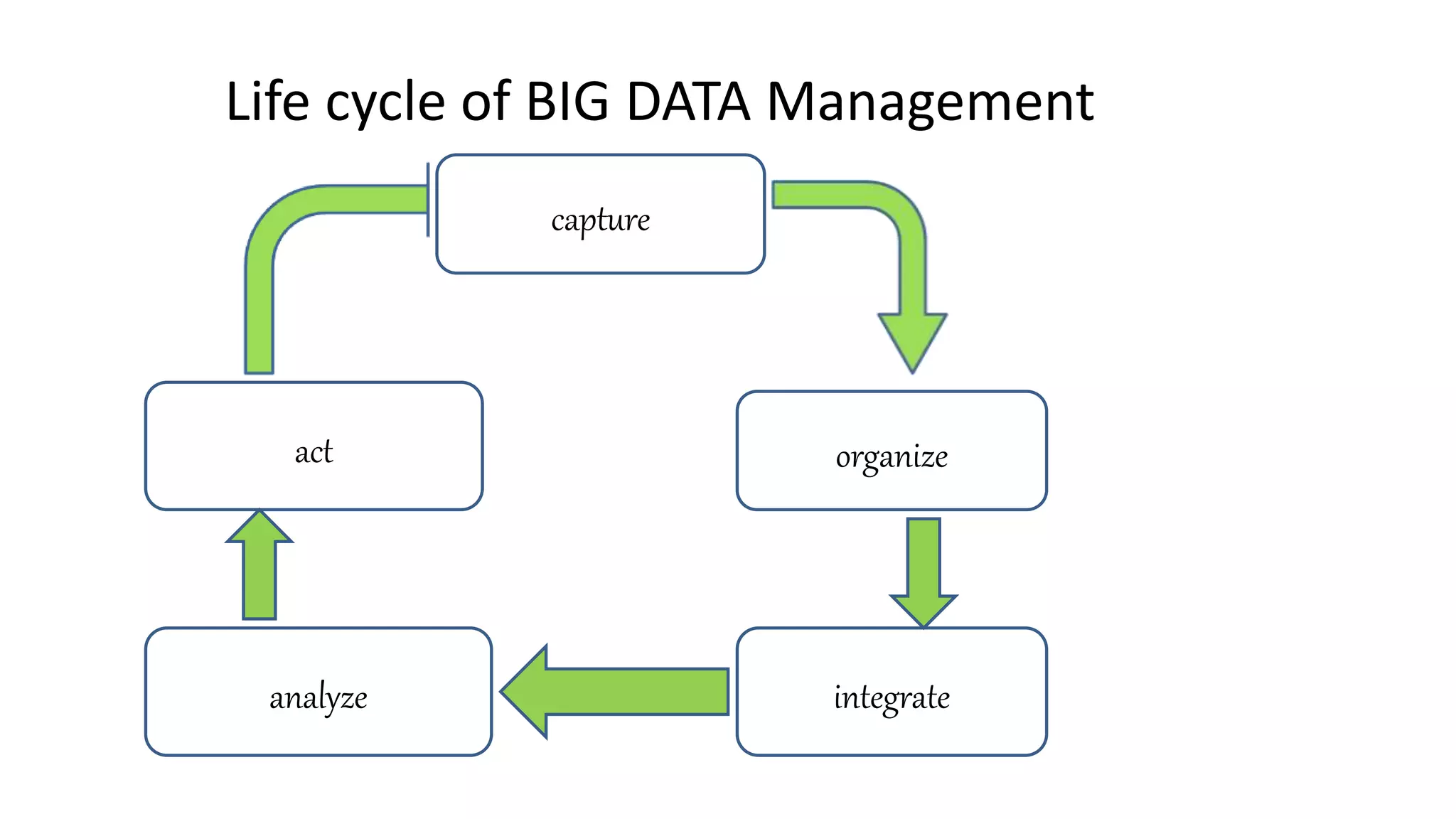













The presentation discusses big data, defined as large, complex datasets that are difficult to manage with traditional tools, characterized by high volume, velocity, and variety. It highlights the sources of big data generation, such as social media, scientific instruments, and mobile devices, as well as the importance of modern technologies like HDFS, MapReduce, Sqoop, Hive, and Pig for processing this data. The seminar also outlines the growth of data and identifies future topics including big data technology and architecture.















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








