Download as PDF, PPTX










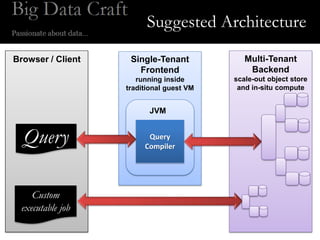
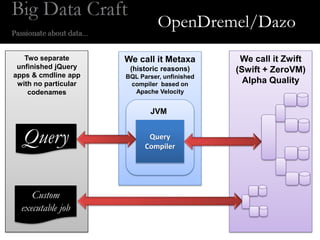







This document outlines the history and design proposals of Apache Drill from the OpenDremel team. It describes OpenDremel starting in 2010 with an initial implementation based on the Dremel paper. Over time, the design was found to be naive and was restarted with a new architecture called Dazo inspired by BigQuery. The document proposes several design tenets for Apache Drill including supporting multi-tenancy, being flexible and customizable, being efficient through the use of ZeroVM for sandboxing, and having a suggested architecture with a browser frontend and multi-tenant backend.


![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Hadoop Meetup] Yarn at Microsoft - The challenges of scale](https://cdn.slidesharecdn.com/ss_thumbnails/yarnatmicrosoft-171222065628-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Hadoop Meetup] Tensorflow on Apache Hadoop YARN - Sunil Govindan](https://cdn.slidesharecdn.com/ss_thumbnails/tensorflowonapachehadoopyarn-sunil-171222071922-thumbnail.jpg?width=640&height=640&fit=bounds)




























































