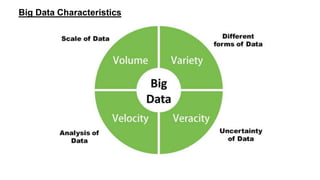
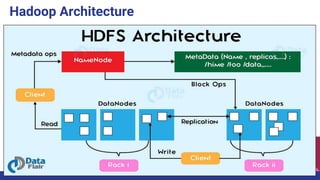
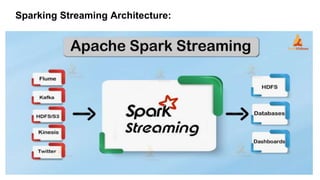
Big data refers to large volumes of structured and unstructured data that can be analyzed for insights, with applications in various fields like education, healthcare, and marketing. Key technologies include Hadoop for processing large datasets, Storm for real-time data processing, and Spark for in-memory computing. Despite challenges in data management and analysis, effective use of big data can lead to innovative solutions and advancements in machine learning.







































































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)






