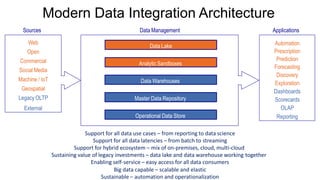
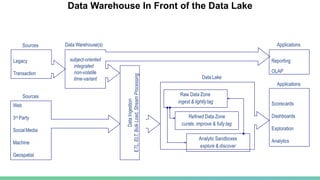
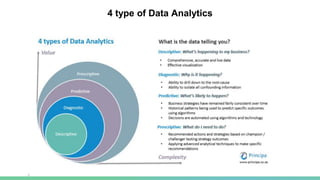
Hadoop is a Java framework for managing large datasets distributed across clusters of commodity hardware. It allows for the distributed processing of large datasets across clusters of computers using simple programming models. Hadoop features distributed storage and processing of data and is designed to scale up from single servers to thousands of machines, each offering local computation and storage. It provides reliable, scalable, and distributed computing and storage for big data applications.