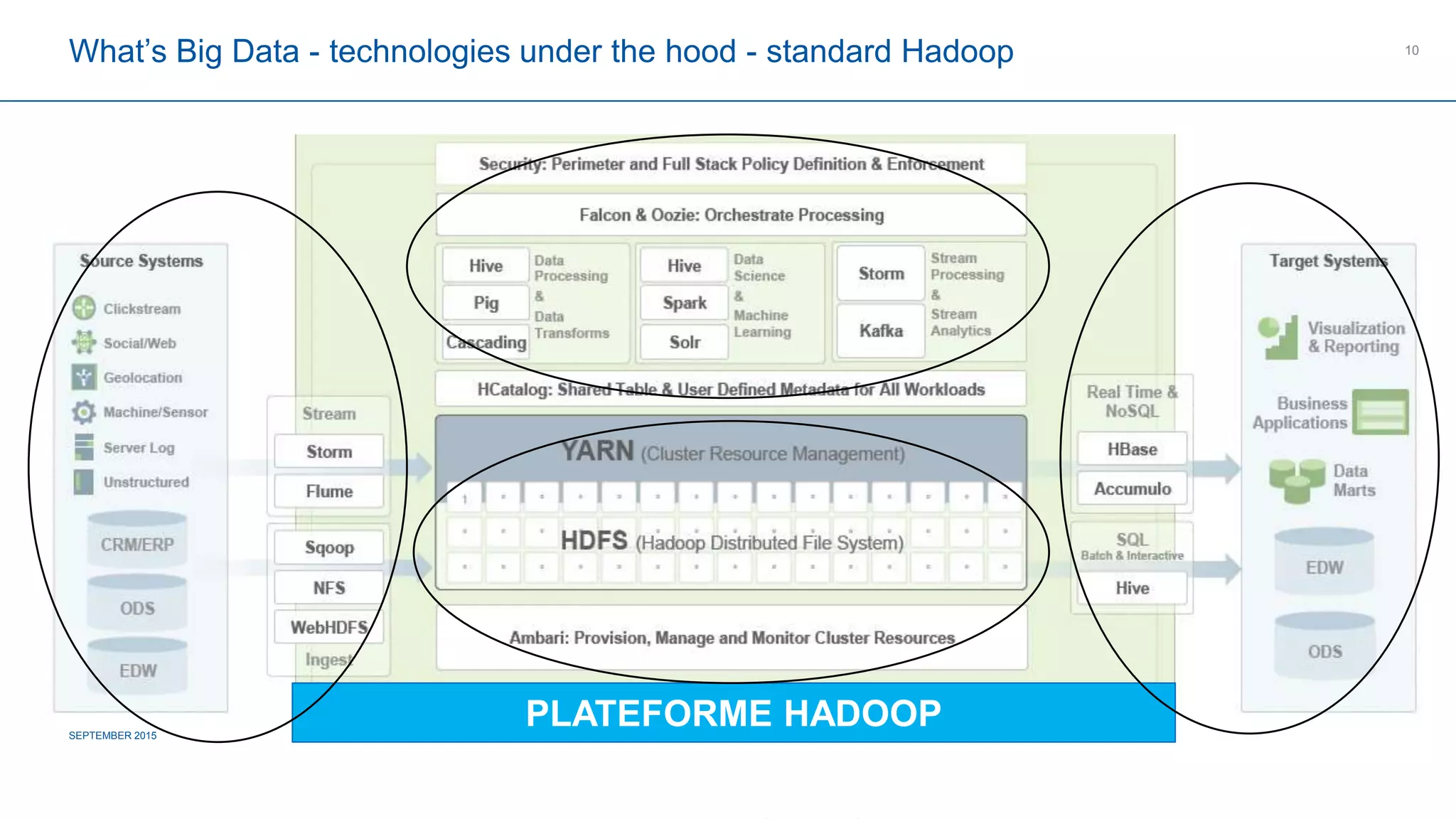
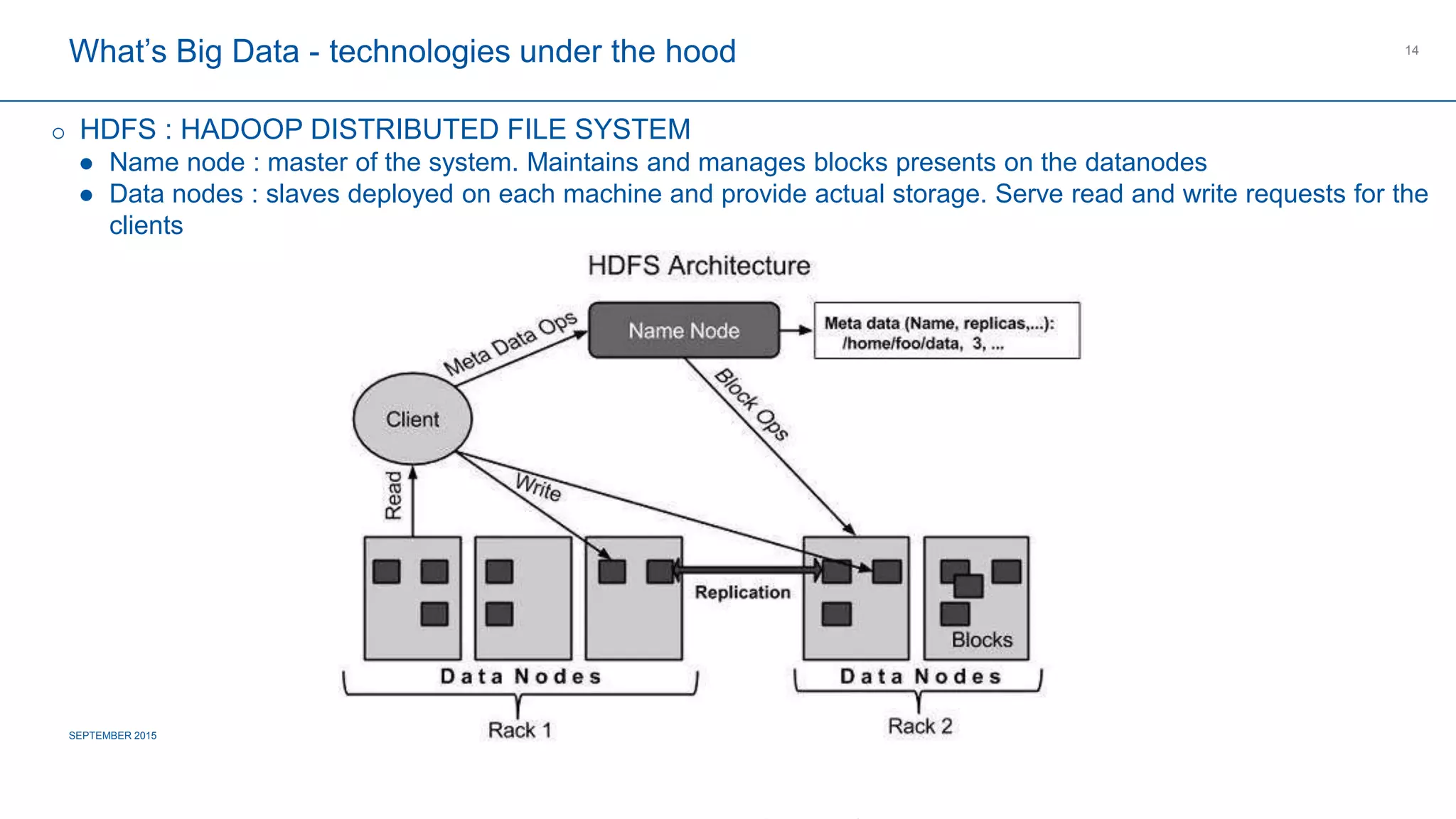
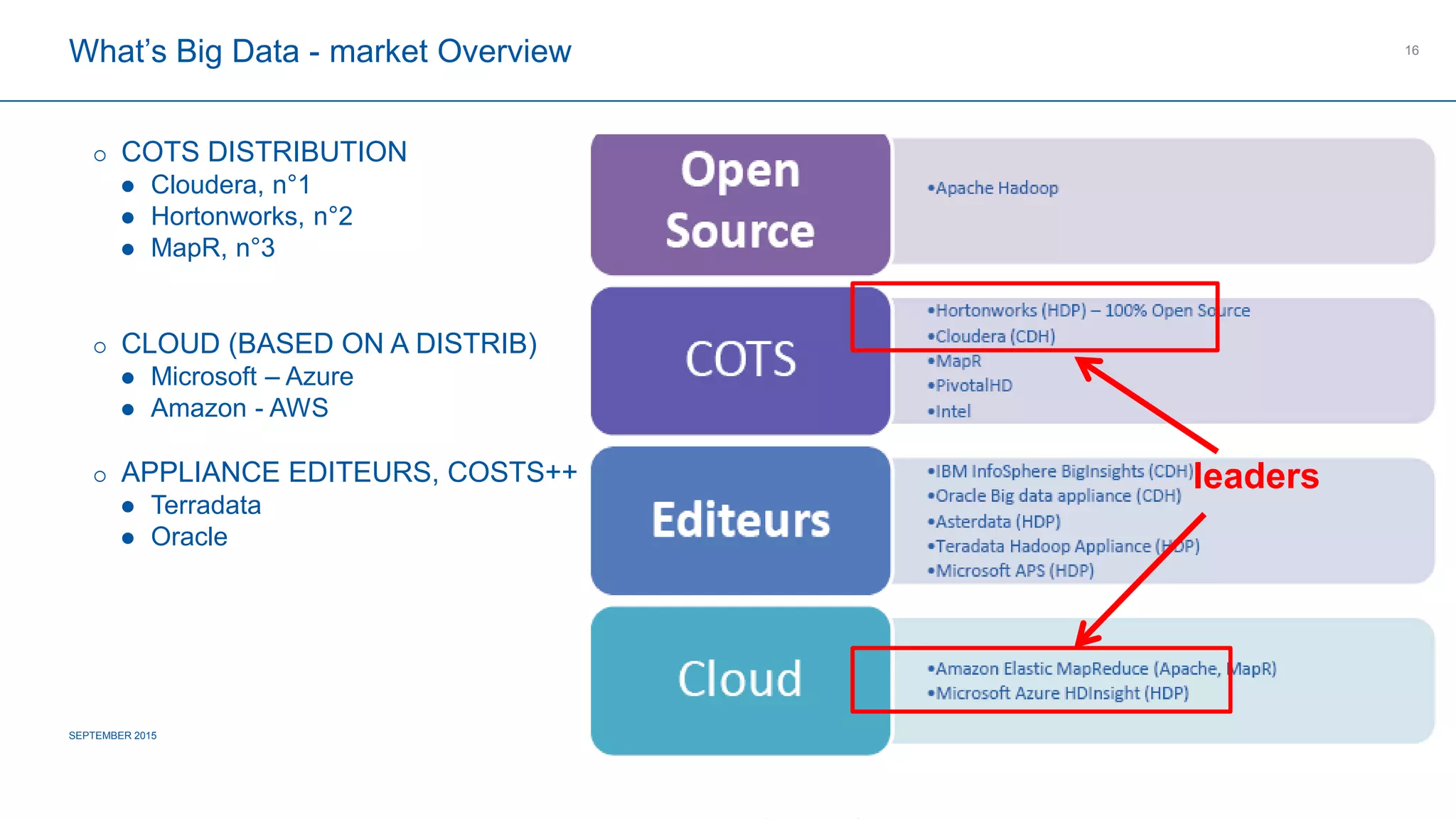
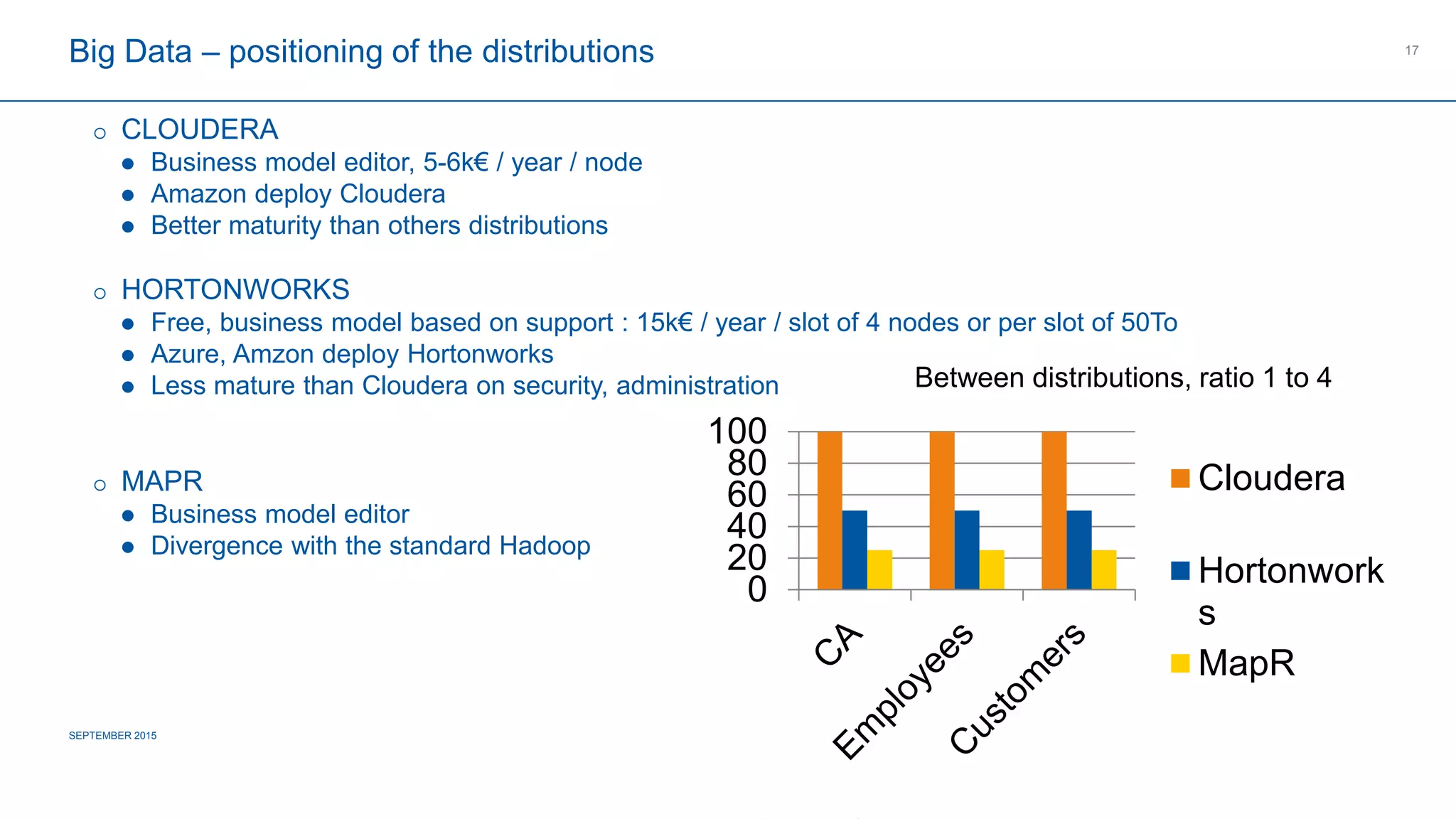
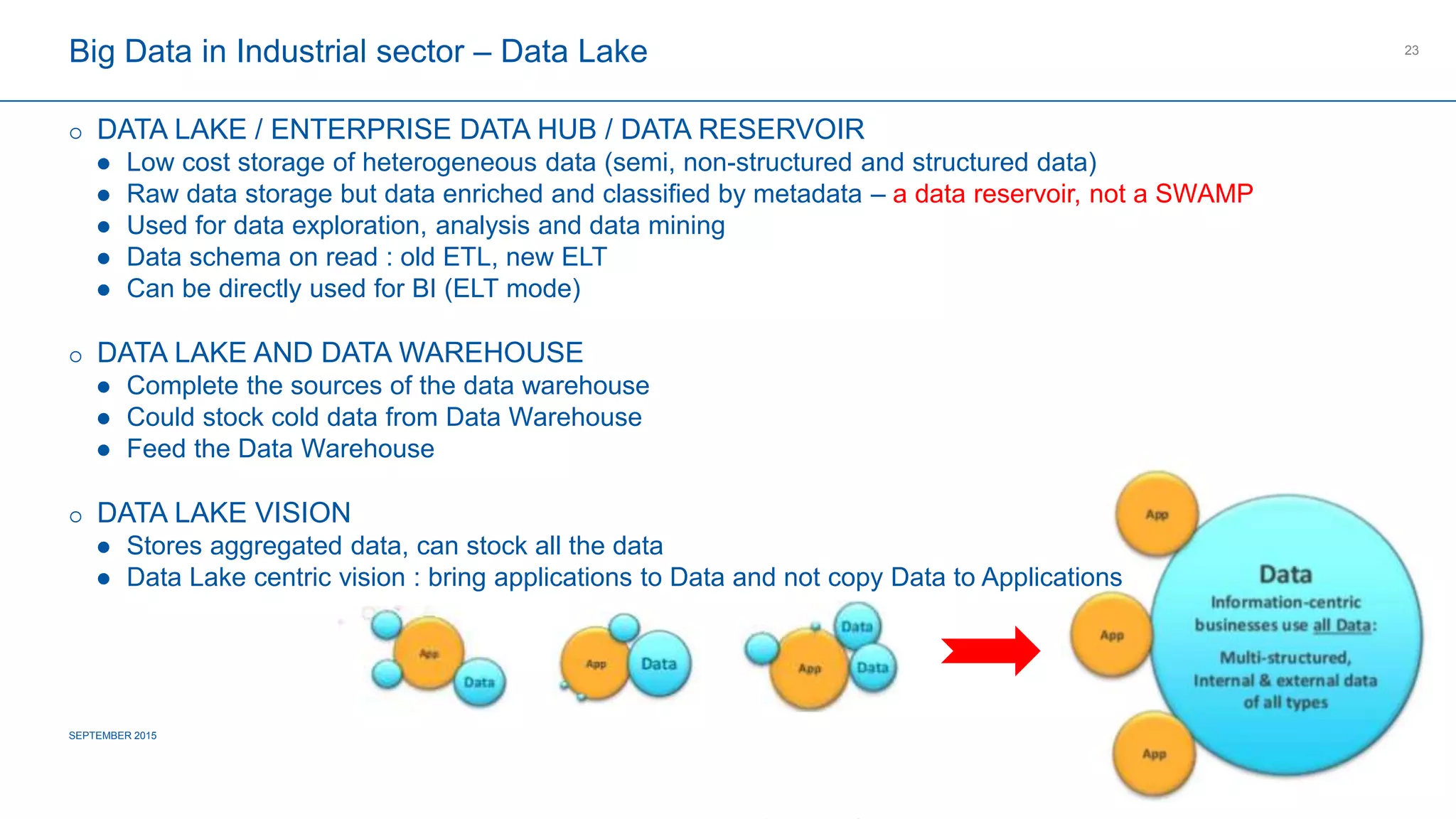
The document provides an overview of big data's definition, technologies, and industrial applications, highlighting its value in managing large volumes of diverse data. It discusses the importance of creating data lakes, using real-time data for predictive maintenance, and integrating big data with existing business intelligence strategies. Additionally, it outlines market leaders and offers insights into the future roadmap for big data implementation in various sectors.


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







