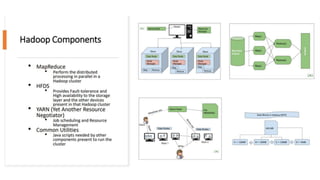
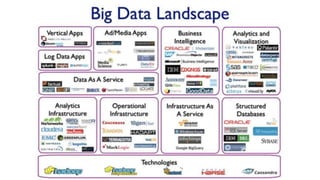
The lecture covers the characteristics and infrastructure of big data, emphasizing the need for specialized hardware and software to handle large volumes of structured and unstructured data. It highlights various tools, database types, and architectural solutions for data storage and processing, including cloud technology and NoSQL databases. Additionally, it discusses the importance of data pipelines and big data frameworks like Hadoop for scalable and efficient data analytics.