Downloaded 114 times











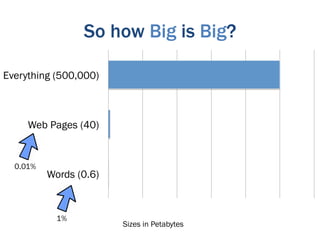



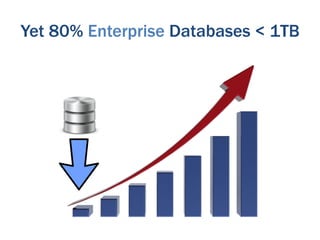


















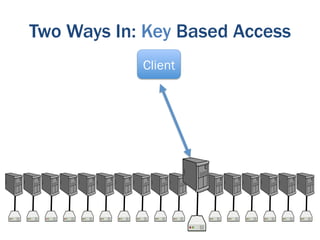
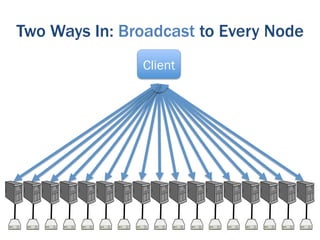





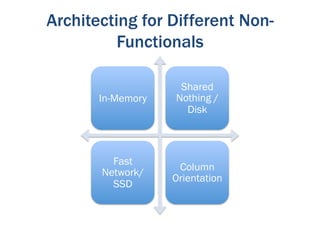

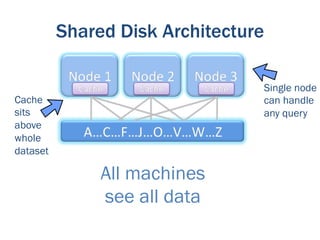
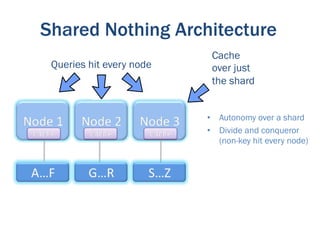


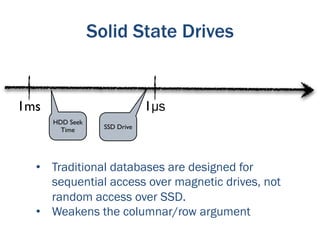
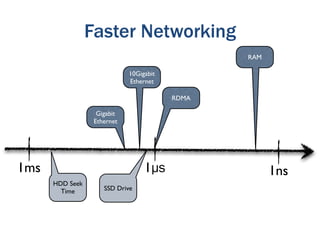






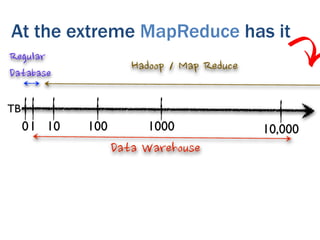
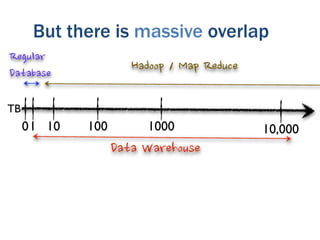





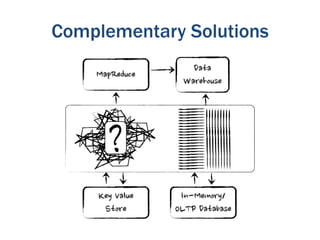






The document discusses the evolution of big data technologies and databases. It describes how early big data technologies like MapReduce took a simpler approach compared to relational databases. This led to a disruption in the database market as NoSQL systems gained popularity. However, relational databases have also advanced by leveraging new hardware and dropping some traditional constraints. Today, the technologies have converged and many vendors offer integrated suites combining relational and big data approaches. The best solution depends on the specific problem and data characteristics rather than just data size.



































































































