Download to read offline



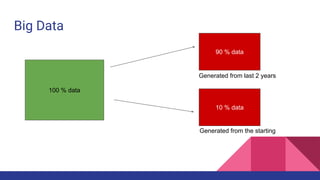

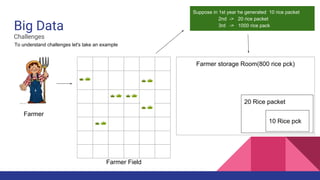

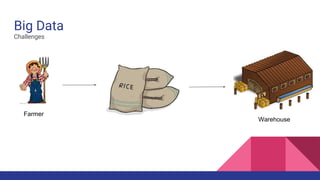
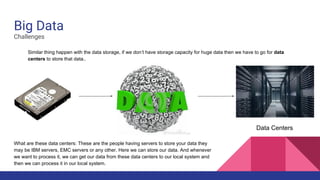















Big Data & Hadoop This document discusses big data and the Hadoop framework. It defines big data as data that is beyond storage and processing capabilities due to its huge size. Most data today is unstructured from sources like social media, sensors, and online activities. Hadoop was developed to address challenges of storing and processing this large, unstructured data across clusters of commodity servers. It uses HDFS for distributed storage and MapReduce as a processing technique to parallelize jobs across nodes for faster completion. Hadoop was created based on Google's research and allows for petabytes of data to be efficiently stored and processed.















































